こんにちは。タケシです。
インフラエンジニアとして働きながら、スキルの幅を広げるためにプログラミングを学んでいます。
Progateなどの教材で学習するだけでは興味がそそられず、いかにもお勉強って感じでやる気が出なかったのですが、初学者でも楽しく無料でプログラミングが学べそうな動画を先日見つけました。

ホロライブで学ぶPython入門~15分でYoutubeの情報取得までやる編~
この動画では投稿主のカルロスピノ氏が、プログラミング初心者向けにPythonでYoutubeの動画情報取得をする方法を解説しています。
ブラウザ(Chrome)でPythonのコードを実行するので面倒な環境構築も不要ですし、お金もかかりません。
この記事ではカルロスピノ氏の動画を見た視聴者(私)が、動画内で紹介されている内容を実行した結果を交えつつPythonを使ってできることを紹介していきます。
この記事はこのような人向けに書いています。
・プログラミングをこれから学びたい初心者
・Pythonを学びたいけど既存の教材はとっつきにくい人
・Pythonを学びたいけどスクールに通うお金がない人
・Youtubeで情報収集するアプリを開発したい人
この記事を読むとできるようになること
・Pythonのコードを無料で実行できる環境が用意できる
・Pythonの簡単なプログラミングができるようになる
・推しのYoutuber/VTuberの情報収集ができるようになる
ブラウザ(Chrome)でPythonプログラムを実行するための環境構築
詳しい手順はカルロスピノ氏の動画内で解説されていますが、補足も兼ねてこの記事でも手順を紹介していきます。
Google Colaboratoryにアクセスする
Googleがクラウド上でPythonのプログラムを実行できる環境を無料で提供しています。
それがGoogle Colaboratoryです。以下のURLからアクセスしましょう。
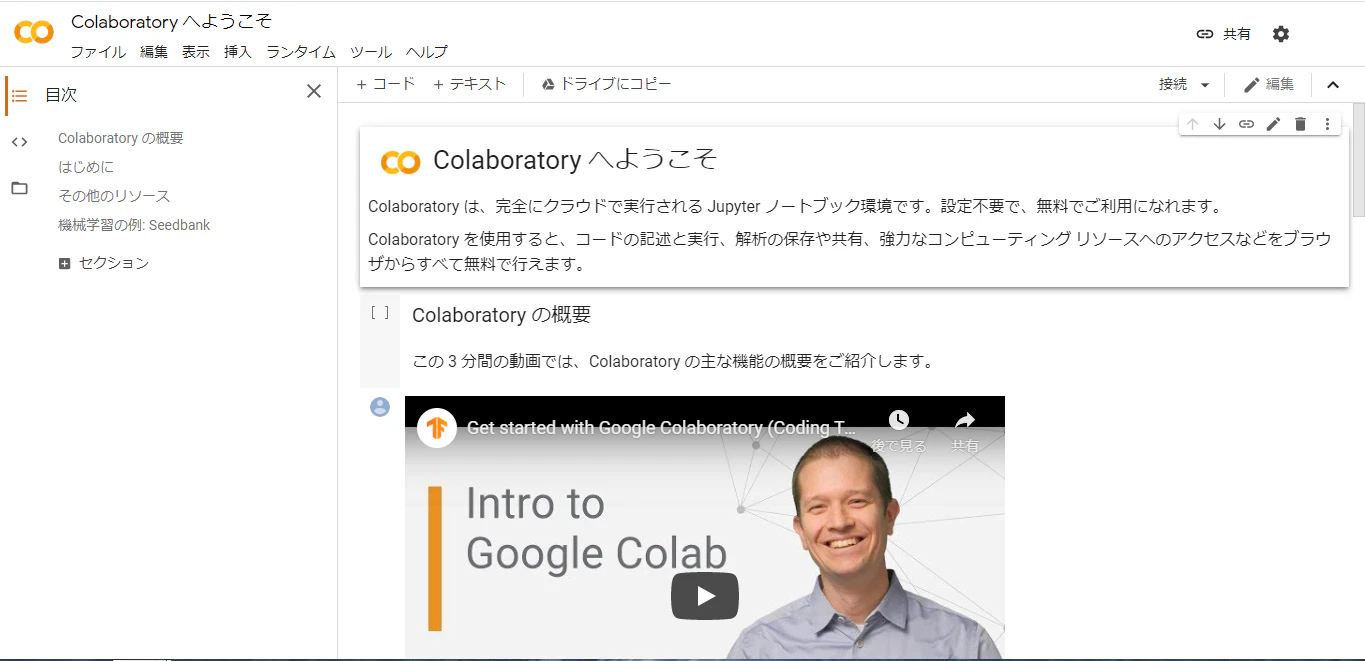
Google Colaboratoryにアクセスするとこのような画面が表示されるので左上の「ファイル」タブをクリックします。

「ノートブックを新規作成」をクリックしましょう。
※カルロスピノ氏の動画では、ノートブックの新規作成をする項目が「Python3の新しいノートブック」「Python2の新しいノートブック」になっていましたが、私がGoogle Colaboratoryにアクセスしたときには項目が「ノートブックを新規作成」に変わっていました。
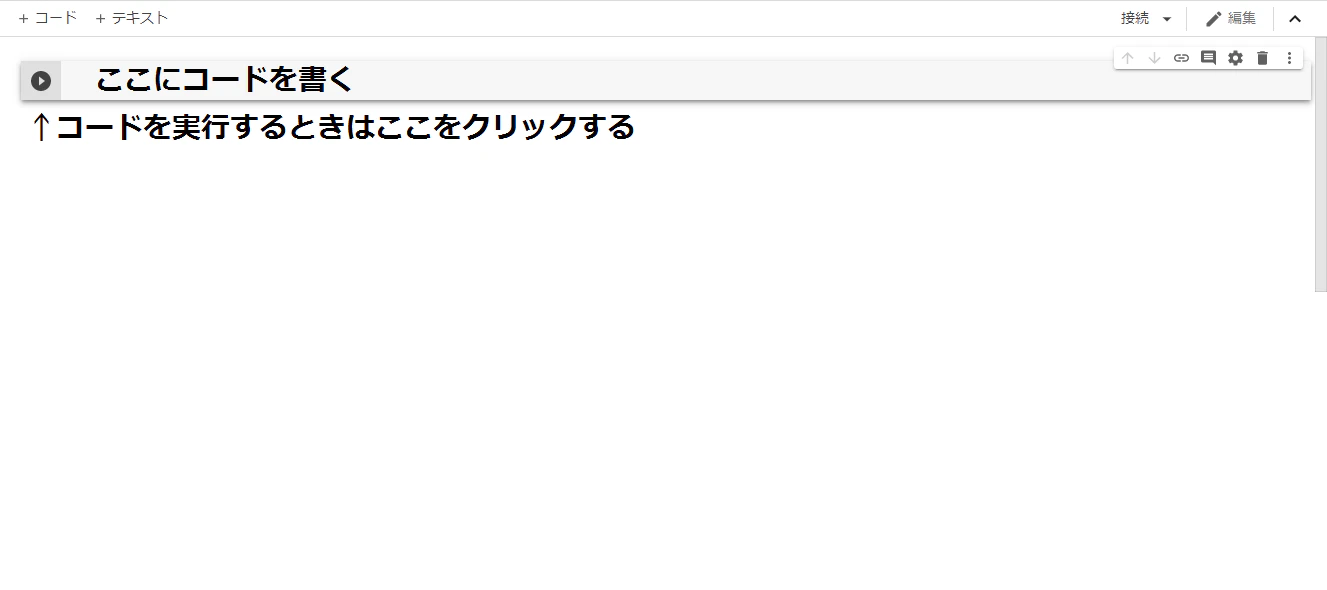
ノートブックが新規作成されると、コードが実行できる箱(セル)が表示されます。
箱(セル)内にコードを書いたのち、左端の●ボタンをクリックすると実行されます。
※セルは「+コード」タブをクリックすると追加可能。
必要な外部ライブラリの用意
カルロスピノ氏の当該動画内では、Youtubeの動画情報収集を手軽に行えるRDFを使用しています。
そのRDFで動画情報を取得する上でfeedparserという外部ライブラリを使用しているので、そのインストールとインポートを事前に行っておきましょう。
feedparserのインストール
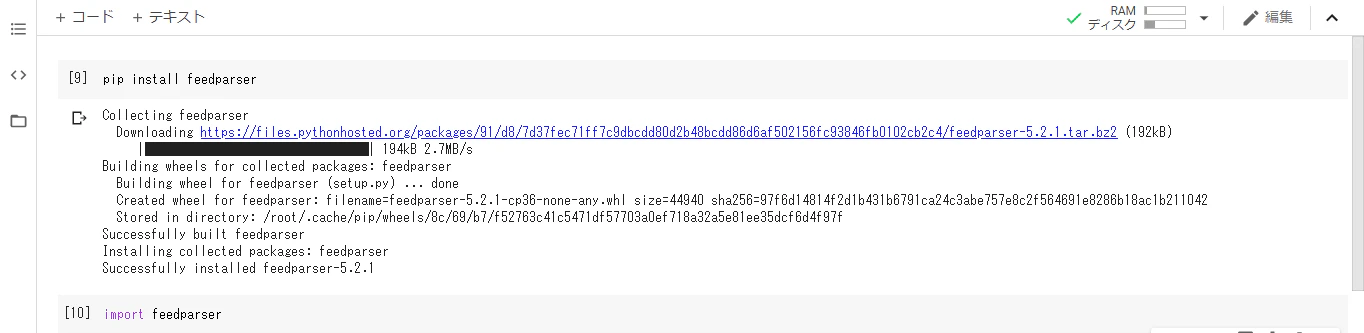
新しいセルでpip install feedparserと入力し、実行するとGoogle Colaboratoryの環境にfeedparserがインストールされます。
Collecting feedparser
Downloading https://files.pythonhosted.org/packages/91/d8/7d37fec71ff7c9dbcdd80d2b48bcdd86d6af502156fc93846fb0102cb2c4/feedparser-5.2.1.tar.bz2 (192kB)
|████████████████████████████████| 194kB 2.8MB/s
Building wheels for collected packages: feedparser
Building wheel for feedparser (setup.py) ... done
Created wheel for feedparser: filename=feedparser-5.2.1-cp36-none-any.whl size=44940 sha256=e16ce8a47aa3d1c3dd0fe4b042ecf27cdc731a2f20e05d2885cd6de37f4a268f
Stored in directory: /root/.cache/pip/wheels/8c/69/b7/f52763c41c5471df57703a0ef718a32a5e81ee35dcf6d4f97f
Successfully built feedparser
Installing collected packages: feedparser
Successfully installed feedparser-5.2.1
このような実行結果が表示されていれば成功です。
feedparserのインポート
続いて新しいセルでimport feedparserと入力し実行しましょう。
何も表示されなければ成功です。
これで任意のYoutubeチャンネルで公開されている動画の情報が収集できます。
RDFで収集できる情報
RDFで収集できる情報の一覧は、以下のコードを実行することで確認することができます。
※チャンネルIDの部分は任意のYoutuber/VTuberのチャンネルIDに置き換えてください。
rdf_url = "https://www.youtube.com/feeds/videos.xml?channel_id=チャンネルID"
document = feedparser.parse(rdf_url)
for entry in document.entries:
print(entry)
ちなみに、RDFによって私がいくつかのYoutubeチャンネルで情報収集した結果、以下のことがわかりました。
- 情報収集できるのは最新の動画15件分程度
- 公開後に非公開とした動画の情報は収集不可
- 動画の評価、コメント、スパチャの金額、同時接続数等は収集できない
Youtube RDFでにじさんじライバーの動画情報収集をしてみよう
カルロスピノ氏がほぼ日刊ホロライブというチャンネルでホロライブの切り抜き動画をUPされていますので、私はにじさんじライバーの動画情報を収集してみます。
Pythonで書いたプログラムによる基本的な情報収集方法は、カルロスピノ氏が動画内で解説されているので、ここではカルロスピノ氏のプログラムにアレンジを加えるやり方を紹介しましょう。
各ライバーのArk配信のタイトル・再生数を収集
にじさんじライバーの配信(アーカイブ)の中でも、任意のゲームタイトルの実況のみを表示する方法を紹介します。
ここでは例としてArkというゲームの実況をしていた配信(アーカイブ)のタイトル・再生数を表示してみます。
rdf_url = "https://www.youtube.com/feeds/videos.xml?channel_id=チャンネルID"
document = feedparser.parse(rdf_url)
for entry in document.entries:
if "ARK" in entry["title"] or "Ark" in entry["title"] or "アーク" in entry["title"]:
print(entry["title"]+" 再生数:"+entry["media_statistics"]["views"])
print(entry["author"])
上記のコード内のチャンネルIDの部分を、任意のライバーのチャンネルIDに変更してください。
チャンネルIDは、各ライバーのチャンネルにアクセスしたときに表示されるURLの末尾になります。
なお、ゲームタイトルは各ライバーによって表記ゆれがある(ARK,Ark,アークなど)ので、orで表記ゆれに対応しています。
本間ひまわり氏のチャンネルURL
https://www.youtube.com/channel/UC0g1AE0DOjBYnLhkgoRWN1w
一例ですが、本間ひまわり氏のチャンネルIDはUC0g1AE0DOjBYnLhkgoRWN1wになります。
#8【ARK】🐻捕獲よ~ん🐻【本間ひまわり/にじさんじ】 再生数:82420
#7【ARK】🐓おそらのおうさまテイムする🐓【本間ひまわり/叶/にじさんじ】 再生数:111207
#6【ARK】海中生物捕獲大作戦~モサほし~【本間ひまわり】 再生数:100238
#5【ARK】どうくつたんけん!!!【本間ひまわり】 再生数:111546
#4【ARK】筋肉痛バキバキザウルス【本間ひまわり】 再生数:156699
#3【ARK】38万人おめでとう!38の何かしちゃうよ~ん^^【本間ひまわり】 再生数:185975
本間ひまわり - Himawari Honma -
このようにARKの配信(アーカイブ)のタイトル・再生数が表示できます。
夜王国のスプラ配信のタイトル・再生数を収集
先ほどのコードではライバー1人1人の配信(アーカイブ)情報しか収集できません。
そこで、ライバーのユニット単位で特定の配信に関する情報収集をしたいときのコードを紹介します。
例として、夜王国それぞれのスプラトゥーン配信のタイトル・再生数を収集してみましょう。
night_kingdom = ["UC6wvdADTJ88OfIbJYIpAaDA", "UCuvk5PilcvDECU7dDZhQiEw", "UC1QgXt46-GEvtNjEC1paHnw"]
for channel_id in night_kingdom:
rdf_url = "https://www.youtube.com/feeds/videos.xml?channel_id=" + channel_id
document = feedparser.parse(rdf_url)
for entry in document.entries:
if "スプラ" in entry["title"]:
print(entry["title"]+" 再生数:"+entry["media_statistics"]["views"])
print(entry["author"]+"\n")
night_kingdomという配列に要素として不破氏、白雪氏、グウェル氏のチャンネルIDが入っています。
【スプラトゥーン2】ありがとうございました【にじさんじ】 再生数:64893
【#にじさんじスプラ杯】スプラが大好きです。今度は嘘じゃないっす【にじさんじ】 再生数:101978
【スプラトゥーン2】最後の練習...見てるか谷沢...【にじさんじ】 再生数:56815
【スプラトゥーン2】イカ杯メンツで前夜祭だあああああああああ【にじさんじ】 再生数:49194
【スプラトゥーン2】何故だが涙がこぼれる...今日は最後の練習だ【にじさんじ】 再生数:117751
【スプラトゥーン2】深夜1時!?いいから練習だぁ!!!!!!【にじさんじ】 再生数:56281
【スプラトゥーン2】夜王国で戦争!?いいから脳死だぁ!!!!!!【にじさんじ】 再生数:52810
【スプラトゥーン2】大会までもう時間ないってマジ??【にじさんじ】 再生数:64277
【スプラトゥーン2】俺の回線なんか重いよ【にじさんじ】 再生数:54743
【スプラトゥーン2】プラべでイカ杯の全ステ全ルールで遊ぶぞ!!【にじさんじ】 再生数:52664
【スプラトゥーン2】エスコート??俺が姫になるんだよ!!!!!【にじさんじ】 再生数:71476
【スプラトゥーン2】後輩ちゃんと地獄のリグマが始まります【にじさんじ】 再生数:64756
【スプラトゥーン2】ぜっっっっったいに脳死しないガチマッチ【にじさんじ】 再生数:55901
不破 湊 / Fuwa Minato【にじさんじ】
【#にじさんじスプラ杯】大会本番!!意外に強いらCチーム【白雪 巴/にじさんじ】 再生数:22140
【スプラトゥーン2】試合目前!!白雪ボム強化意識【白雪 巴/にじさんじ】 再生数:12360
【スプラトゥーン2】意外に強いらしいチームCの本番前日練習【白雪 巴/にじさんじ】 再生数:9868
【スプラトゥーン2】夜王国で銃撃訓練【白雪 巴/にじさんじ】 再生数:13229
【スプラトゥーン2】深夜の͡͡コソ練。ランク20いくまで耐久【白雪 巴/にじさんじ】 再生数:21462
【スプラトゥーン2】お姉さんとイカプレイしない?【白雪 巴/にじさんじ】 再生数:13949
白雪 巴/Shirayuki Tomoe【にじさんじ】
【Splatoon2】 #にじさんじスプラ杯 本戦【黛灰/夜見れな/フミ/グウェル・オス・ガール】 再生数:14572
【Splatoon2】ガチ練習試合 GチームとIチーム #にじさんじスプラ杯【黛灰/夜見れな/フミ/グウェル・オス・ガール/イブラヒム/フレン・E・ルスタリオ/鷹宮リオン/天宮こころ】 再生数:17937
【Splatoon 2】夜王国スプラ【不破湊/白雪巴/グウェル・オス・ガール/にじさんじ】 再生数:16813
【Splatoon 2】#にじさんじスプラ杯 Gチーム練習会【フミ/黛灰/夜見れな/グウェル・オス・ガール/にじさんじ】 再生数:71870
グウェル・オス・ガール / Gwelu Os Gar 【にじさんじ】
コードを実行した結果、夜王国のチャンネルでそれぞれ行われたスプラトゥーン配信のタイトル・再生数が収集できました。
グウェル氏のアーカイブのサムネイルを収集しダウンロード
カルロスピノ氏の動画内では、アーカイブのサムネイルを一括保存する方法が紹介されています。
そこで解説されているコードに対するコメントで
for文でインデックスを取りたいならenumerate関数を使うといいですよ。
とありましたので、enumerate関数を使った一括保存のコードを書いてみました。
※下記コードを実行する前にimport requestsを実行する必要があります。
for index, entry in enumerate(document.entries):
url = entry["media_thumbnail"][0]["url"]
response = requests.get(url)
image = response.content
file_name = "Gwelu"+str(index)+".jpg"
with open(file_name, "wb") as image_file:
image_file.write(image)
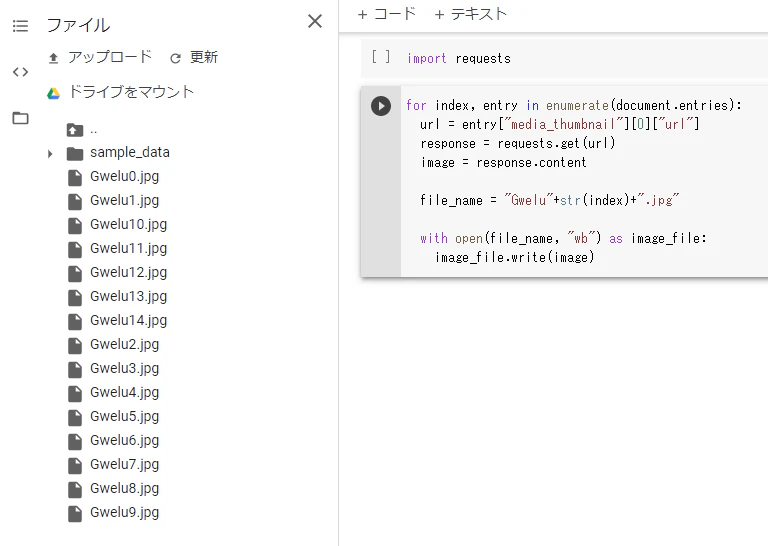
グウェル氏の直近のアーカイブ15件分のサムネイルをクラウド上に保存できました。
Pythonでできるようになること
Google Colaboratory + RDFでは出来ることも限られていますが、Pythonでのプログラミングによってカルロス氏作成のopipi.netで公開されているグラフやTwitter Botの作成ができるようになるとのこと。
今後、Youtube APIの使い方講座なども動画として投稿されるそうなので、気になった方はチャンネル登録しておくといいでしょう。
▼未経験からのエンジニア転職支援ブログ書いてます
https://webengineer-tenshoku.com/