データの取得の仕方 1
製造業の品質管理とWebサイトの配信品質管理の違い
前回は、Webパフォーマンスが
- 表示速度 ― WebブラウザでWebページが表示される速度
- 可用性 − WebブラウザでWebサイトにアクセスした際に、エラーや遅延がなくアクセスできる率
の2つから成り立つことを書きました。
製造業の品質管理の場合は、目標値は非常に明確です。
例えば、1mの鉄パイプを作るとなれば、目標値は1mです。完成品をチェックして、1mかどうか、1mより長い・短い場合は、許容誤差の範疇(例えば±0.5mm)かどうかをチェックすれば、事は済みます。
しかし、Webサイトの配信品質管理は、そうはいきません。ユーザによって、「完成品」であるWebページが出来上がる環境がそれぞれに異なるからです。
さて、この表示速度と可用性は、どこで計測すると妥当なのでしょうか?
- Webサーバ (First Mile)
- ISP (Middle MileよりLast Mile寄り)
- エンドユーザの端末 (Last Mile)
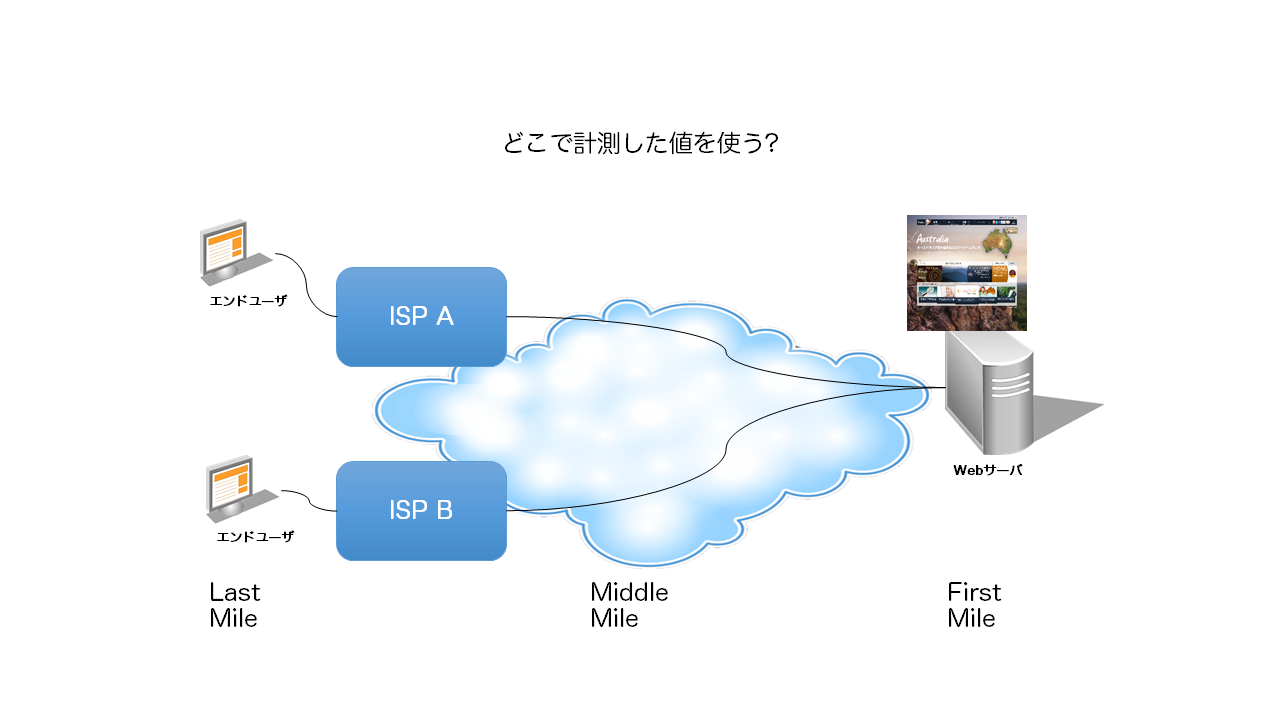
エンドユーザの端末で計測するにしても、以下の要素が異なります。
- 使っている端末~デスクトップPC、ノートPC、タブレット、スマートフォン
- 使っている回線~光回線、ADSL、ケーブルTV回線、携帯回線、Wi-Fi
- 使っているブラウザ~IE、Firefox、Chrome、Safari
- 使っているAddon
- 同時起動しているアプリケーション
- 使っている時間帯
- 使っている場所
全てを調査すべきなのでしょうか?
それとも、どれかの組み合わせに基準を置くべきなのでしょうか?
データの取得
まずは、統計分析におけるデータの取得の仕方について、見てみましょう。
日本では、データの取り方は重要です。
データを全て取るか、標本(サンプル)で取るかで分かれます。
- 全数調査(Census)
- 標本調査(Sample Survey)
全数調査
全数調査とは、母集団全体を全て調査します。
母集団全体を調査する事は、殆どの場合において、時間とコストの観点で合理的ではありません。
全数調査は理想的に見えるかもしれませんが、逆に不注意を齎すことが知られています。
また、調査件数より、調査設計の方が遥かに重要です。
調査設計に問題がある場合、全数調査をしたとしても、そのデータは役に立たないでしょう。
母集団とは、Wikipediaの記載では、調査対象のとなる数値,属性等の源泉となる集合全体
と記載されています。
標本(サンプル)の集合を母集団と呼んでいる方が、たまにいらっしゃいますが、それは違うので注意して下さい。
英語では、populationとuniverseという二つの言葉に対して、日本語訳は、どちらも「母集団」になっています。
- population
- 調査対象や研究対象となる要素の集合体
- universe
- 要素を含む対象自体の集合
例えば、Webサイトパフォーマンスの場合、Webサイトへの全てのアクセスに対する端末上の「表示開始時間」を調査対象とするのであれば、それがpopulationです。
その全てのアクセスの表示開始時間を調べた端末は、マシンスペック、OSのバージョン、ブラウザのバージョン、メーカー名、回線種別など、数多くの要素から成り立っています。これらを含んだ端末の集合がuniverseです。
標本調査
標本調査とは、母集団の一部分について「欲しい情報」を調べることです。
その母集団から取り出した「一部分」を標本(サンプル)と呼びます。
その標本の数値データを基にして、その標本(サンプル)が属する母集団について予想される数値を求めることを「外挿」と言います。
このやり方で気を付けなくてはいけないのが、偏り(バイアス)です。
日本語で、「バイアス」と書くと、一般的には、「認知バイアス」の意味で捉えられる事が多いので注意して下さい。
(もちろん、「認知バイアス」も避けるべきものなのですが)
偏りを避けなければ、調査データの信頼性が失われます。
偏りを避ける対策として一般的なのは、標本(サンプル)を選び出す際にランダム化する事です。(無作為性の組み込み)
よく使われるのが、単純無作為抽出法(SRS: Simple Random Sampling)で、確率的な現象を用いて、母集団に含まれている個体が同じ確率として標本として選ばれるようにする抽出方法です。
研究デザインの分類
研究は、実験か、観察かで、大きく二つに分かれます。
- 実験研究(Experiment)
- 観察研究(Observational Study)
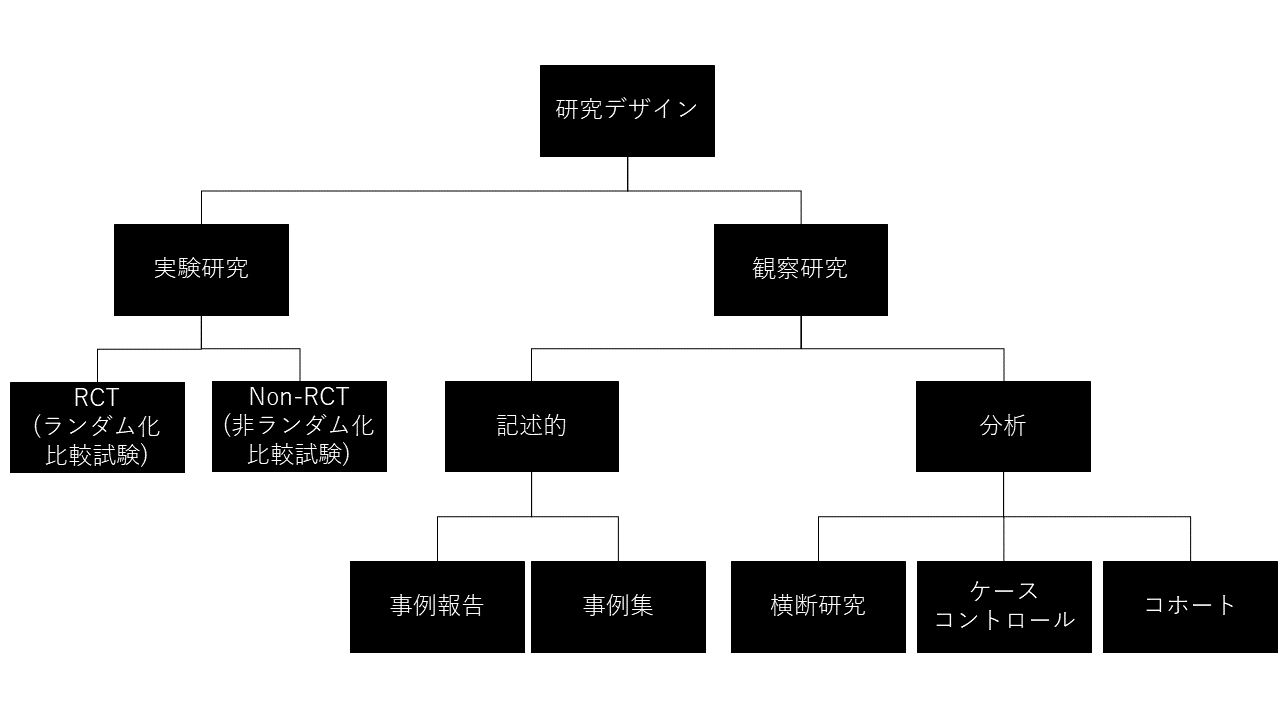
実験研究
実験は、調査対象を分けて、原因となる要素(因子と言います)を制御して(介入といいます)調査を行うことです。
つまり、調査する側が、調査対象に対して関与します。それを「実験設計」とか「実験計画」と言います。
具体的には、以下の要素が考慮されます。
- コントロール(Control)
- 変化を加える対象と、加えない対象、双方のグループが同条件となるようにする。
- ブロック化(Blocking)
- 調べる要因以外の全ての要因を可能な限り取り除くこと。(少なくする・一定にする)
- 無作為化(Randomization)
- 変化を加える際に、その対象をランダムにすることで、未知及び制御不可な因子を取り扱う。また、偏りのない標本抽出をすること。
- 繰り返し(Replication)
- 処置を対象に対して十分な回数繰り返す。偶然によるバラつきを少なくするため。
- 一般化可能性(Generalizability)
- 様々な設定下でも実験を繰り返せる可能性を確保する。
観察研究
観測は、対象を分けて、因子の制御をして比較するのが難しい場合に行われます。
例えば、煙草の影響を調べるために、健康な喫煙したことのない男女を200名集めて、その内の100名には煙草を毎日3箱吸わせて、残りの100名は吸わないように指示するというのは倫理的に困難です。
このような場合には、毎日3箱の煙草を吸っていると吸わない人をそれぞれ100名ずつ集めて、それぞれについて健康状態を追跡調査するのが妥当です。
因子を制御する(介入する)ことが出来ない場合は、対象を観察・観測して、因子のある・なしで分けた方が妥当です。これを観察研究、もしくは観測と言います。
標本調査は、観察研究の一部と言えます。
証拠としてのレベル
実験データと観察データは、どの程度まで、統計分析の証拠として使えるのでしょうか?
それを詳細に解説しているのが、米国の保険社会福祉省(Department of Health and Human Services)が運営するNational Guideline Clearinghouseが公開しているDepressionというページです。
Depressionとは、測量における俯角という意味です。
俯角とは、観測者のいる平面と、水平線下にある被観測物との角度を指します。
何故、俯角というタイトルかというと、俯角があると、人間の認知にズレを生み、正しく認知できないからです。
俯角が齎す認知バイアスについては、立命館大学人間科学研究所の所長を勤められた、松田隆夫先生の「仰角および俯角の知覚」を読まれると、面白いです。
証拠のレベル
| レベル | データの取り方 | 証拠の種別 |
|---|---|---|
| 1++ | 実験 | 質の高いメタ・アナリシス、ランダム化比較試験(RCT)のシステマチック・レビュー、偏りのリスクが非常に低いランダム化比較試験 |
| 1+ | 実験 | 良く実施されたメタ・アナリシス、ランダム化比較のシステマチック・レビュー、偏りのリスクが低いランダム化比較試験 |
| 1- | 実験 | メタ・アナリシス、ランダム化比較試験のシステマチック・レビュー、偏りのリスクが高いランダム化比較試験 |
| 2++ | 観察 | 質の高いケース・コントロールやコホート研究のシステマチックレビュー。交絡因子や偏りのリスクが非常に低く、関係が因果である確率が高い、質の高いケース・コントロールやコホート研究 |
| 2+ | 観察 | 良く実施された、交絡因子や偏りのリスクが低く、関係が因果である確率がほどほどのケース・コントロールやコホート研究 |
| 2- | 観察 | 交絡因子や偏りのリスクが高く、関係が因果ではない確率がかなり高いケース・コントロールやコホート研究 |
| 3 | 実験でも観察でもない | 分析的な研究ではないもの。例えば、事例報告、事例集 |
| 4 | 実験でも観察でもない | 専門家の意見 |
この表で注目して欲しいのは、以下の点です。
- 専門家の意見は、証拠としては、最もレベルが低い。
- 事例報告や、事例集の方が、専門家の意見より証拠のレベルが高い。
- 実験の方が観察より証拠のレベルが高い
誰か、専門家が言うことより、実際の事象や、分析データの方が遥かに証拠としてレベルが高いのです。
因果関係を証明できるのは「実験」のみ
さて、この四つのデータの取得の仕方で、因果関係を示すことが出来るのは、どれでしょうか?
それは、実験です。
実験は、因子に介入してデータを取得することが可能だからです。
「これが原因であろう」という因子を特定し、それ以外の因子について値を固定にすることによって、原因となる因子の値を変化させて結果を確認することで、因果関係が証明できるのです。
Webパフォーマンスの場合は、大きなカテゴリで因子を分けると以下のとおりです。
- サーバ処理要因
- ネットワーク処理要因
- ブラウザ処理要因
品質管理では「実験」を用いる
品質管理においては、製品の品質の改善、生産性の向上などを目的としています。
その最適条件を探るために、無尽蔵の時間とお金が使えるわけではありません。
改善効率も、エンジニアの技術力の一つの要素ですし、企業の競争力の要素の一つなのです。
確実に改善するという「結果」を出すためには、「急がば回れ」で、統計的データに基づいた多くの情報を効率よく得る必要があります。
そのデータ収集に関する統計学的方法が「実験計画法」です。
実験計画法は、「現代統計学の父」、ロナルド・エイルマー・フィッシャー(1890年2月17日 – 1962年7月29日)によって開発されました。

Sir R・A・Fisher
フィッシャーの開発した実験計画法は、品質管理だけでなく、農事試験、工業統計、臨床試験、官能試験、市場調査研究、パネルデータ分析など、幅広い分野で使われています。
Webパフォーマンスの表示速度や、操作可能時間、ダウンロード時間を結果系特性値と言います。それを統計学の分析では目的変数と言います。
この値を改善するために、オブジェクト数やファイル容量、HTML、CSS、JavaScriptのコード、ネットワーク設定、ハードウェア設定などの原因系特性値を変えるわけです。これを統計学の分析では説明変数と言います。
原因系特性値がどのように結果系特性値へ影響を及ぼすのか、その因果的効果を検討するためには、観察データではできません。意図的な原因系特性値の変更、つまり「介入」していないからです。また介入の結果は、一意な数値としても現れません。必ず結果の数値には、バラつきが生じます。
変化を加えた原因系特性値以外を固定化するのは、根本的に不可能だからです。
ラプラスの魔(Laplace's demon)というのをご存じでしょうか?
フランスの数学者、ピエール=シモン・ラプラスが以下のように著書の中で書いています。
もしもある瞬間における全ての物質の力学的状態と力を知ることができ、かつもしもそれらのデータを解析できるだけの能力の知性が存在するとすれば、この知性にとっては、不確実なことは何もなくなり、その目には未来も(過去同様に)全て見えているであろう。
— 『確率の解析的理論』1812年
実際のところ、そのような能力を持つ知性は存在しえないわけです。
この知性を、電気生理学の基礎と築いた、ドイツのエミール・デュ・ボワ=レーモンが「ラプラスの霊(Laplacescher Geist)」と呼び、その後「ラプラスの魔(Laplacescher Dämon)」という名前で世の中に知られました。
「ラプラスの魔」に相当する存在が、テクノロジーの発展によって生まれれば、「原因系特性値をどれだけ変えると結果系特性値がこれだけ変わる」という具合に、一意に算出できるようになるのかもしれません。
しかし、実験計画法を用いる事によって、ある程度、原因系特性値を管理し、結果系特性値のバラつきの分析が可能になるわけです。
管理用特性要因図を作ってチェックする
品質管理においては、結果系特性値に影響を及ぼすと考えられる原因について、予め「特性要因図」というものを作り、漏れがないように把握しておきます。
特性要因図には、2つの種類があります。
- 管理用特性要因図
- 特性要因図予防目的で管理を必要とする事項を全て列挙したもの
- 解析用特性要因図
- データ収集を行い、データから要因を推定して列挙したもの
本来の管理用特性要因図とは、ちょっと異なるのですが、パフォーマンスの因子を掴んでもらうのを目的に作りました。幾つか抜け落ちている因子があると思うので、参考程度に見てください。
Webパフォーマンスにおけるダウンロード完了時間は、HTMLと、そのHTMLの中で記述されたCSS、JavaScript、画像などの全てのオブジェクトのダウンロードの合計値になります。
そして、それらのダウンロード時間は、以下の要素から成り立ちます。
- DNS Lookup … DNSの名前解決にかかった時間
- Initial Connection … TCP/IP 3way handshakeにかかった時間
- SSL Negotiation … SSLを使っている場合、SSLセッション確立までにかかった時間
- First Byte Download … HTTP Get/Postのリクエストが発呼されて、その応答の1Byteめが届くまでの時間
- Content Download … HTTP Get/Postのリクエストの応答の最後のByteが届いて完了するまでの時間
- Client Time … ブラウザ側で処理にかかった時間
つまり、
ダウンロード時間=DNS Lookup + Initial Connection + SSL Negotiatin + First Byte Download + Content Download + Client Time
というわけです。
そして、各要素時間には、様々な原因系特性値が関与しています。
因子の分類
これらの各要素時間も、ミクロな観点で見れば、結果系特性値であると言えます。
各々の結果系特性値に影響を及ぼすと考えられる原因の内、実験で取り上げて水準(=実験条件)を設定し比較される項目を因子と言います。
因子は、主に制御が可能かどうか、選択が可能かどうかによって、以下の四つに分類されます。
- 制御因子
- 実験の場でも、運用の場でも、水準の指定も選択も可能(制御可能)なもので、最適水準を選ぶ目的で取り上げる因子。
例えば、DNS TTL、ページあたりに含めるオブジェクト数、ページの容量、ブラウザキャッシュ有効期限など。 - 標示因子
- 実験の場では制御でき、運用の場では水準の指定はできるが選択はできない因子。その最適水準を選ぶことは意味がなく、他の制御因子との交互作用を検討することが目的となる。
例えば、計測で使う回線、ブラウザ種別、端末種別など。 - ブロック因子
- 実験の精度を上げるために、局所管理に用いる因子。その水準の性質は技術的には明確ではなく、再現性がない。また、制御因子との交互作用には意味がない。
例えば、計測する日、時間など。 - 誤差因子
- 運用の場において、水準の指定も選択も不可能なもので、運用者側でコントロールできない因子。運用の場においては制御できないが、実験の場においては水準の設定ができることが望ましく、実験においてノイズの効果を求めるために選ばれた因子。
例えば、同時接続数や滞留時間、どの端末でアクセスしてくるか、どのブラウザでアクセスしてくるかなど。
品質管理においては、制御可能なものに、つまり制御因子に注力します。Webサイトの配信品質管理においても、制御可能なものに注力します。
Webパフォーマンスの管理用特性要因図をその観点で見て頂くと、「どうやら制御可能な因子は、結構ありそうだぞ」、というのがお分かり頂けると思います。
フィッシャー三原則
これらの因子(=原因)の種別を踏まえた上で、フィッシャーは三つの原則に基づいた実験の管理を提唱しました。
- 無作為化
- 実験の順序によって生じる慣れ、空間的配置などの系統誤差を偶然誤差に転化するために、実験条件の水準組合せに関して実験順序を無作為にすること。
- 局所管理
- ブロックの構成原理とも呼ばれ、系統誤差の大きい部分をブロック間差異として誤差の評価から除去し、制御因子の水準間を精度よく比較できるようにするために、各ブロック内はできるだけ均一になるように管理すること。
- 反復
- 誤差分散を評価するために、同一条件で実験を繰り返すことが必要だが、局所管理が導入された場合、処理の一揃いを2回以上行うことを反復するという。
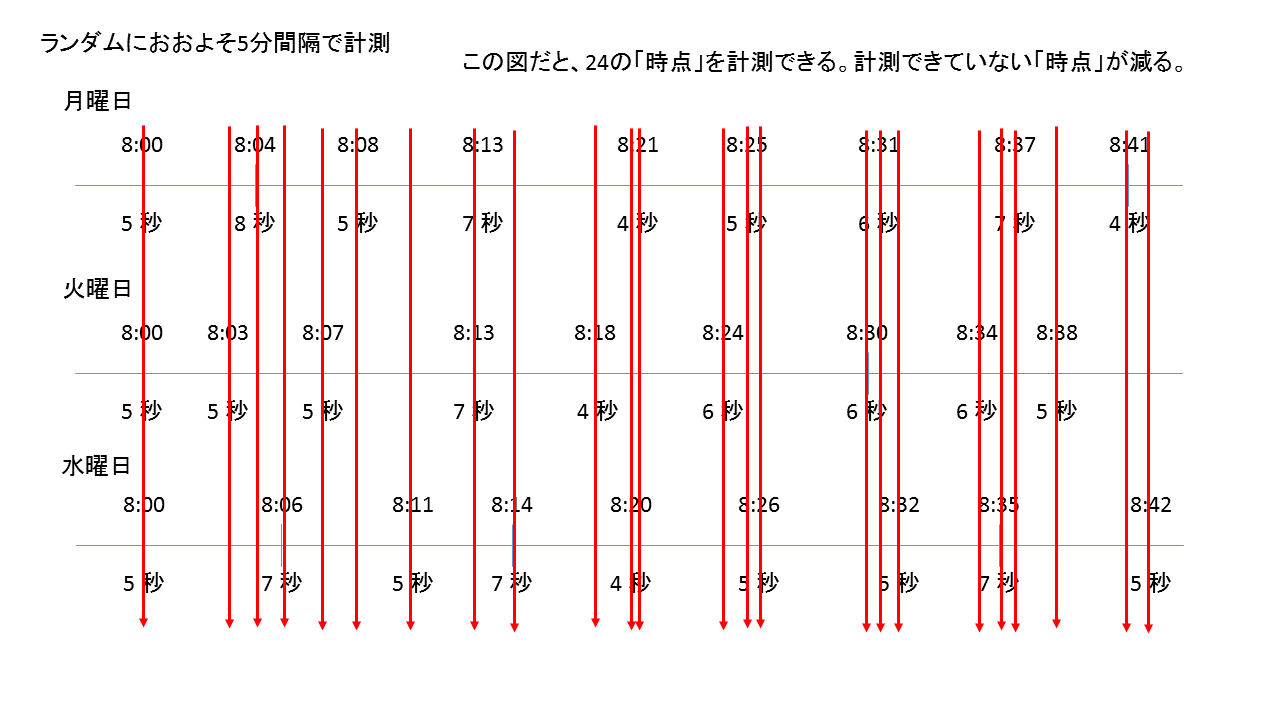
まず、Webパフォーマンス計測における無作為化ですが、計測タイミングのランダム化が行われます。それが「空間的配置などの系統誤差を偶然誤差に転化」に該当します。
例えば、5分に1回の頻度で計測する場合、きっかり5分毎ではなく、少し時間をずらします。
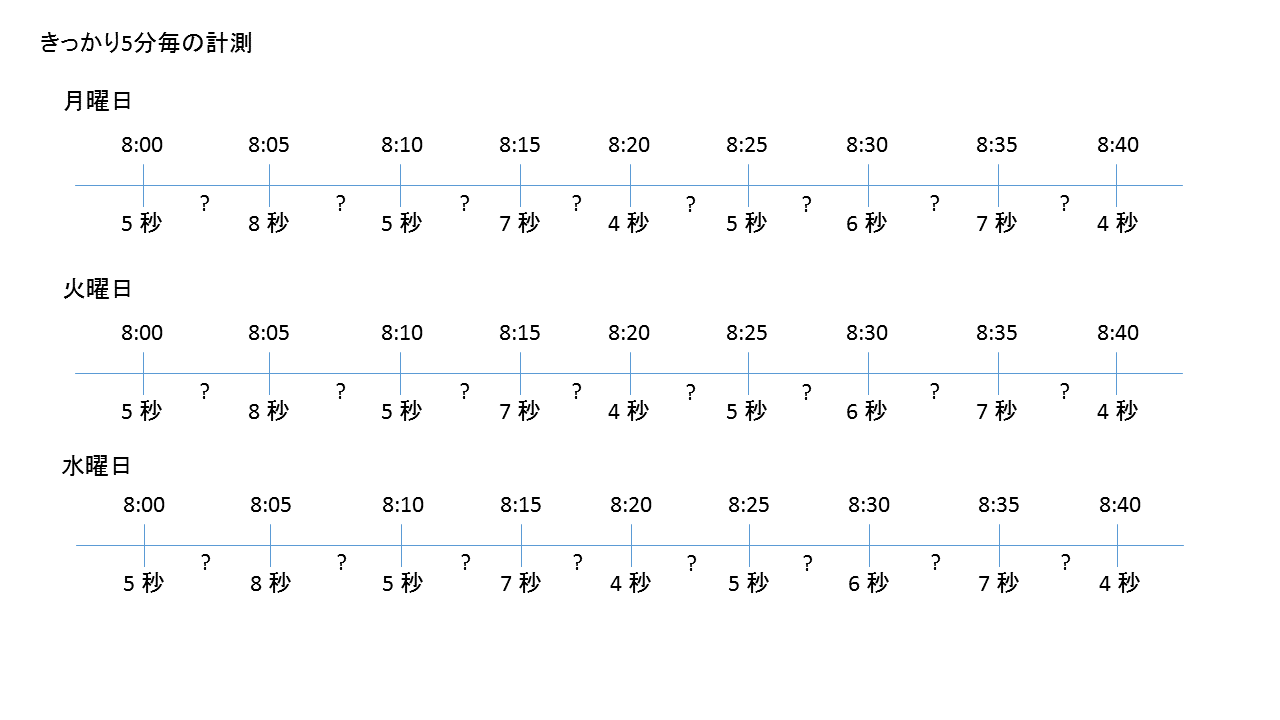
データの計測で、最も避けねばならないことは、偏り(バイアス)です。
偏りを避けるためには、ランダム化が重要になります。ランダム化は、パターンを避けるという事です。
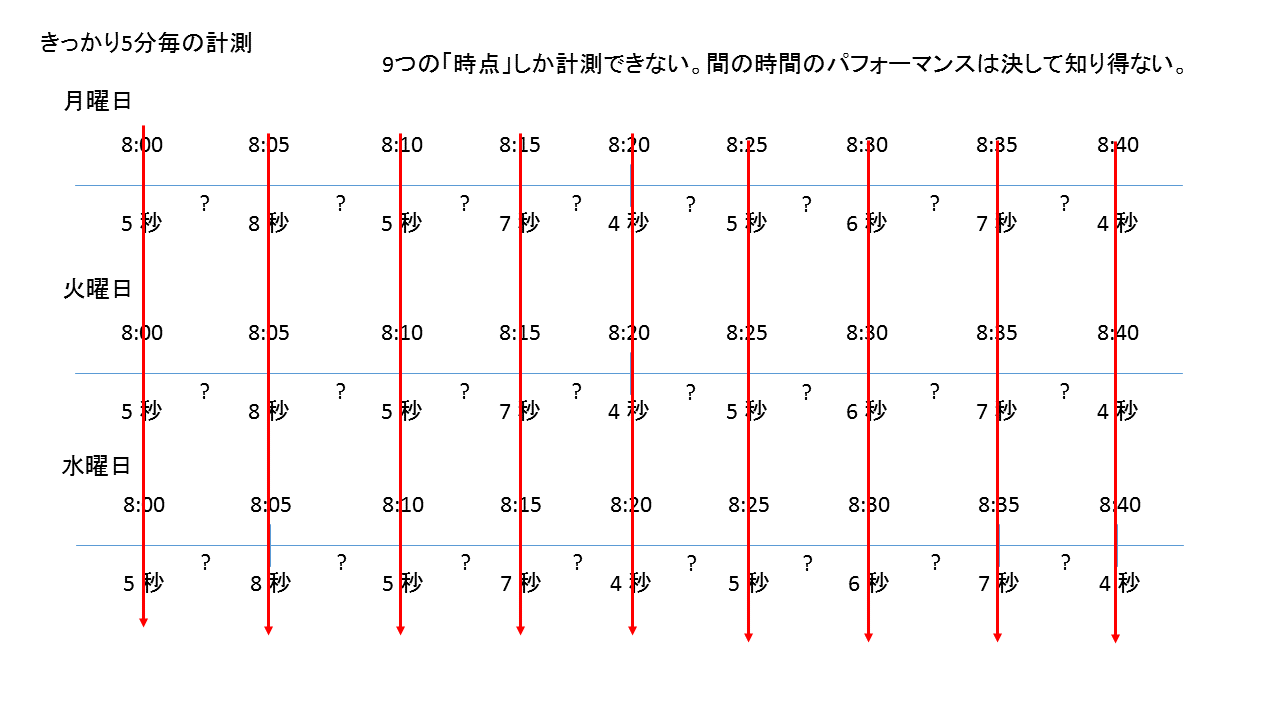

また、ランダム化によって、この手の時系列データの計測でカバーできる時間軸が増えます。
Webパフォーマンス計測における局所管理は、計測環境の統一です。
- 計測マシンのスペックの統一、高性能なマシンにする
- 計測マシンが使う回線帯域の統一、余裕のある回線帯域(ベストエフォートではなく、帯域保証型)にする
- 計測マシンが使うOSやブラウザのバージョンの統一
- 計測マシンで他のアプリケーションが稼働しないこと
これらを統一することで、因子として考慮せずに済みます。
Webパフォーマンス計測では、反復は、計測を継続的に行う事で担保します。
参考文献
- 松原 望・美添 泰人・岩崎 学・金 明哲・竹村 和久・林 文・山岡 和枝(2011)『統計応用の百科事典』丸善出版株式会社
- Martin Sternstein, Ph.D.(2012)『Barron's AP Statistics 7th Edition』 Barron's Educational Series
- 永田 靖(2006)『品質管理のための統計手法』(日経文庫1089)日本経済新聞出版社
- ドナルド・C・ゴース、G・M・ワインバーグ(1987)『ライト、ついてますか ― 問題発見の人間学』(木村 泉訳、共立出版)