NextremerでWeb系プログラマになって9ヶ月のわかばマークです。
Advent Calendar参加は初めてです。どうぞよろしくお願いいたします。
さて、サーバーサイドの皆様、システムの負荷テストしていますか?
「いやいや、俺のシステムはそんなにユーザーいないから」「そんなに性能求められないから大丈夫」
……ふむふむ。そうですね、負荷テストは必須ではない場面も多いと思います。
真面目に負荷テストをやろうとするといろんなことを考えないといけないので面倒くさいです。
オンプレならオンプレの、クラウドならクラウドの負荷テストのやり方があると思いますが、それに合わせたテストシナリオと評価方法を考えて――。
実際、面倒くさいのでやらないケースも考えられますが、簡易的にでもやっておくといいことがあるかもと思って私は積極的に負荷かけています。
……嘘です。本当はただシステムをいじめるのが好きなだけです。みなさんもそうですよね?
でもそれだとあまりにもアレなので、正当化してみようと思います。
※あくまでも簡易的なものなので、真似をするときには、結果をみて一喜一憂しない、強い心を持ってください。
負荷テストの目的
「負荷テストをするのは最後。早すぎる最適化は良くない!」
おっしゃるとおりです。例えばWebアプリケーションサーバーを作りながら負荷テストをしていると、数値の改善に囚われがちです。
要注意ですね。
私は、この簡易的な負荷テストの目的は大きく3つあると思っています。
- 性能を知る
- 限界状態での振る舞いを知る
- リソース管理の考慮漏れを知る
性能を知る
文字どおり、自分の組み上げたものがどの程度の性能を叩き出すかを知ることです。
少し言葉を変えて、性能限界を探ることといってもいいかもしれません。
性能値はいろいろありますが、このあたりがわかりやすいですね。
- スループット
- レスポンスタイム
スループットは単位時間あたりの処理量を意味しますが、1リクエストの処理時間が短ければ向上しますし、リクエストを同時に複数さばければ向上します。
レスポンスタイムはリクエストをしてからレスポンスを受け取るまでの時間ですね。サーバー側で処理の順番待ちになったり、高負荷状態でリクエストの処理に時間がかかったりするとレスポンスタイムは悪化します。
開発中でも、コードを変更する前と後でどのくらい処理時間が変わるか測っておくと、例えば非効率なコードを書いてしまっていることに早目に気付くことができます。
この評価はエンジニアとしての感覚に頼ることになりますが、でも普段から自分のつくっているものを負荷テストにかけておくと「この規模だとこのくらいの性能かな」という感覚をつかめます。
繰り返しになりますが、ここでチューニングをしたくなる気持ちは抑えてください。
負荷テストの最中、CPUの使用率やメモリ使用量、ディスクI/O、ネットワークI/Oも注目しておきます。
対象がどのリソースをどのように消費する傾向があるのか把握しておくと、マシンスペックの決定やトラブル時の対応に役に立ちます。
限界状態での振る舞いを知る
負荷がかかった状況で、対象がどのような振る舞いをするのかを知ります。
下流のアプリケーションやデータベースへの接続が失敗したりタイムアウトを起こしたり、データベースやログファイルへの書き込みがぶっ壊れたり、アプリケーションが落ちたり…どういった挙動を起こすかを知っておくことが大事です。
知らなければ、直すこともできませんしそのままにするという判断もできませんよね。
リソース管理の考慮漏れを知る
コンピュータ上のリソースの種類はいくつかあります。CPU、メモリ、ディスク、ネットワーク…これらはOSが管理し、アプリケーションに割り当てられます。
負荷テストで、これらリソースのハンドリングがマズイところを発見できます(全てではありません)。
よく知られる例はメモリリークです。通常状態ではジワリジワリと起こしているようなものだと長時間運用しないと発覚しませんが、大量の処理を行わせて加速すると短期で観測できることもあります。
その他、データベースのコネクションプーリングの使い方がまずく、リクエスト毎にデータベースに接続していることに気付けたこともあります。思っていた以上に性能が出なかったので気が付きました。
いつ負荷テストをするか
いつやってもいいとは思いますが、意義がありそうなのは以下の4つでしょうか。
- 変更前
- 変更中に実装に迷ったとき
- 変更後
- 本番投入前
変更前後は前述のとおりです。負荷テストの結果は作業環境に強く依存しますから、同じマシンで実行しないと比較になりませんね。
実装に迷ったときというのは、「読みやすさも保守性も大差なさそうな複数のアプローチがあるけれどもどれを採用すべきか迷っている」というときです。性能や安定性という切り口で決めるのもありだと思います。
これはネタではなく真面目に実施されるべきなのですが本番投入前の負荷試験は重要ですよね。IaaSやPaaSなどの環境ごとにクセがあるとは思います。開発時にはわからなかったボトルネックや障害ポイントが現れることもあります。できればリアルなシナリオを使用するのが望ましいです。CPUやメモリ、ディスクI/Oなどのリソース情報は必ず見ておきます。グラフで推移が見えるとベターですね。
最近ではKubernetesでアプリケーションコンテナを展開するのが主流だと思いますが、どのノードにどのアプリケーションをどれだけ動かすか、というリソース配分の参考になると思います。
その他: ぶっ壊してみる
これは負荷テストではないのですが、あの手この手で対象をぶっ壊してみると 面白いです 勉強になります。
kill -KILL で関連プロセスを落としてみたり、アプリケーションが使用するファイルシステムを mount -o remount,ro してみたり、Netfilter(iptables)その他で通信を断続的に遮断してみたり…。
障害時に自動的に回復する仕組みを使っているのであれば当然確認していると思いますが、これらの邪魔をしてみて意図したとおりに切り替わるか、高負荷時にはどうかを観察しておきます。
負荷テスト時の注意事項
負荷テストプログラム自身もコンピュータに負荷をかけてしまうことを忘れないようにします。
テスト対象に大量のリクエストを投げつけるためにCPUとメモリを消費します。テスト対象とリソースを折半している場合、どちらかが不利になっているかどちらも本気を出せていない状態になりますから、正確な結果は期待できません。
これが一番大事です。
他人様の設備に負荷をかける場合には、設備の持ち主に必ず連絡をします。
AWSやGCPなどならサポートに相談しましょう。
負荷テストに役立つもの
テストツールはいくつか有名なものがあります。
ab以外はテストシナリオを書けるツールです。
TsungはErlangで書かれていることもあって比較的軽量なようです。ただしシナリオはXMLで書きます。
ツールによってJVMが必要だったりErlangが必要だったりPythonが必要だったりといろいろなので、ひとまずは導入の手間や好みで選んでも構わないと思います(本気出すならちゃんと選びましょう)。
負荷テストツールではありませんが、cgroupでストレージのIOPSの制限などができ、tcでネットワークトラフィックのロスや遅延を作り出すことができます。
まとめ
- 負荷テストをやると気付ける問題はあります
- 限界を知る・癖を知る・限界状態での挙動を知っておくことでできる判断があります
- 比較するには定量化する必要があります
- 負荷テストをかけるときには事前に相談をしましょう
- ツールはいろいろあります
- 自分の作ったものの耐久試験・障害試験は楽しいです
最後のを言いたかっただけです。本当にすみませんでした。
おまけ
Tsungで適当に作ったブログアプリに負荷をかけてみました。
アプリはElixir + Phoenix。データベースはPostgreSQL 11です。
Markdownで書かれた記事をサーバーサイドでHTMLに変換しています。今流行りのSPAとかではありません。
Tsungのテスト設定は以下です。10000ユーザーで一斉に襲いかかります。ユーザーはページを10回ロードします。
<?xml version="1.0"?>
<!DOCTYPE tsung SYSTEM "/home/tmatsushima/opt/tsung/share/tsung/tsung-1.0.dtd">
<tsung loglevel="notice" version="1.0">
<!-- Client side setup -->
<clients>
<client host="localhost" maxusers="30000" use_controller_vm="true">
<ip value="127.0.0.1"/>
</client>
</clients>
<!-- Server side setup -->
<servers>
<server host="127.0.0.1" port="4000" type="tcp"></server>
</servers>
<load>
<!-- several arrival phases can be set: for each phase, you can set
the mean inter-arrival time between new clients and the phase
duration -->
<arrivalphase phase="1" duration="1" unit="minute">
<users maxnumber="10000" arrivalrate="10000" unit="second"></users>
</arrivalphase>
</load>
<options>
<option type="ts_http" name="user_agent">
<user_agent probability="100">Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.7.8) Gecko/20050513 Galeon/1.3.21</user_agent>
</option>
</options>
<sessions>
<session name="http-example" probability="100" type="ts_http">
<for from="1" to="10" incr="1" var="cnt">
<request> <http url="/posts/77f2850e-4867-4dfa-b205-2e893c850398" method="GET" version="1.1"></http> </request>
</for>
</session>
</sessions>
</tsung>
結果、サーバーサイドでのデータベースへの接続待ちがタイムアウトしてボロボロとエラーを返し、可哀想なことになりました。100秒あたりで接続が詰まってしまったおかげか謎の谷間が発生していますね…
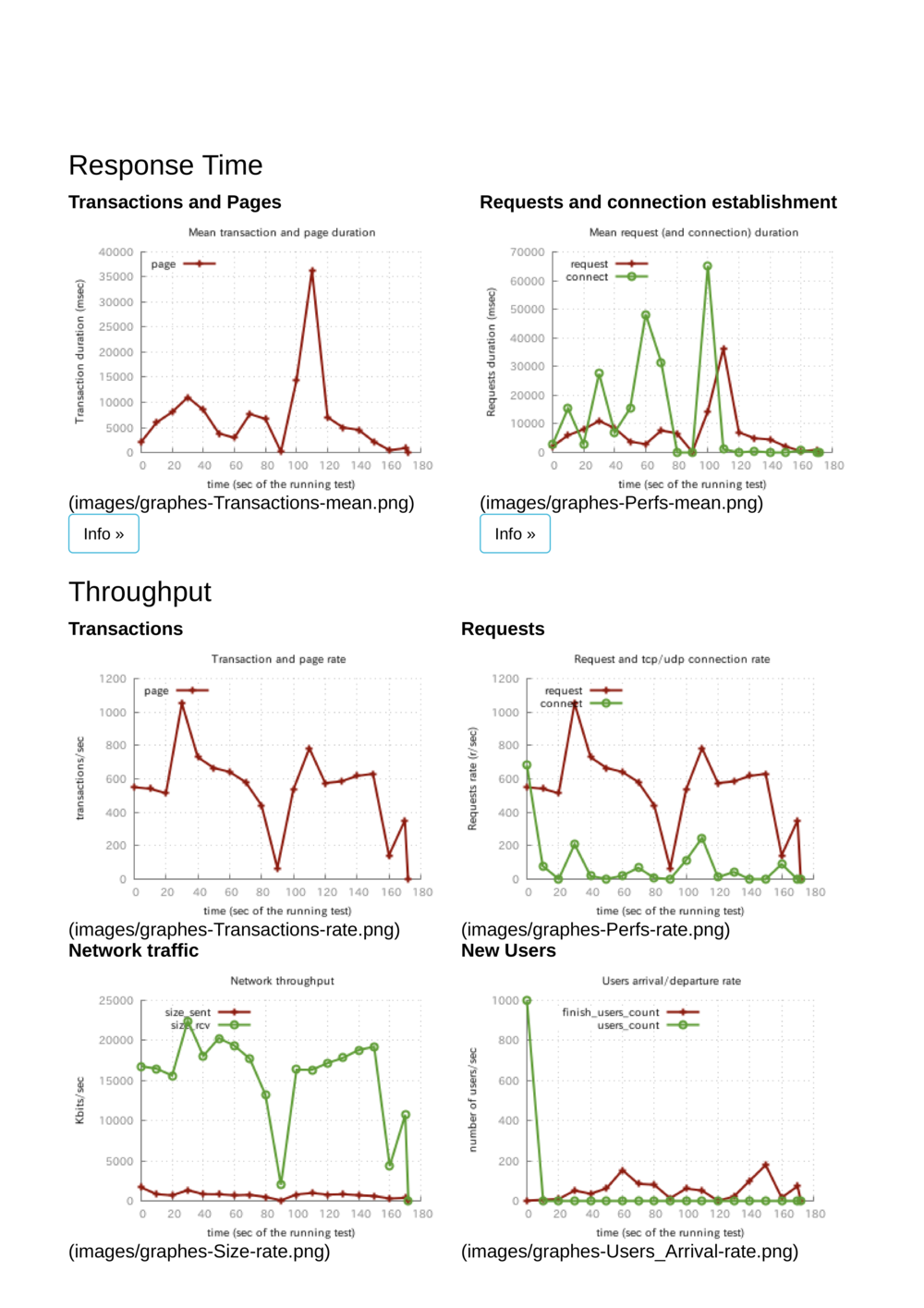
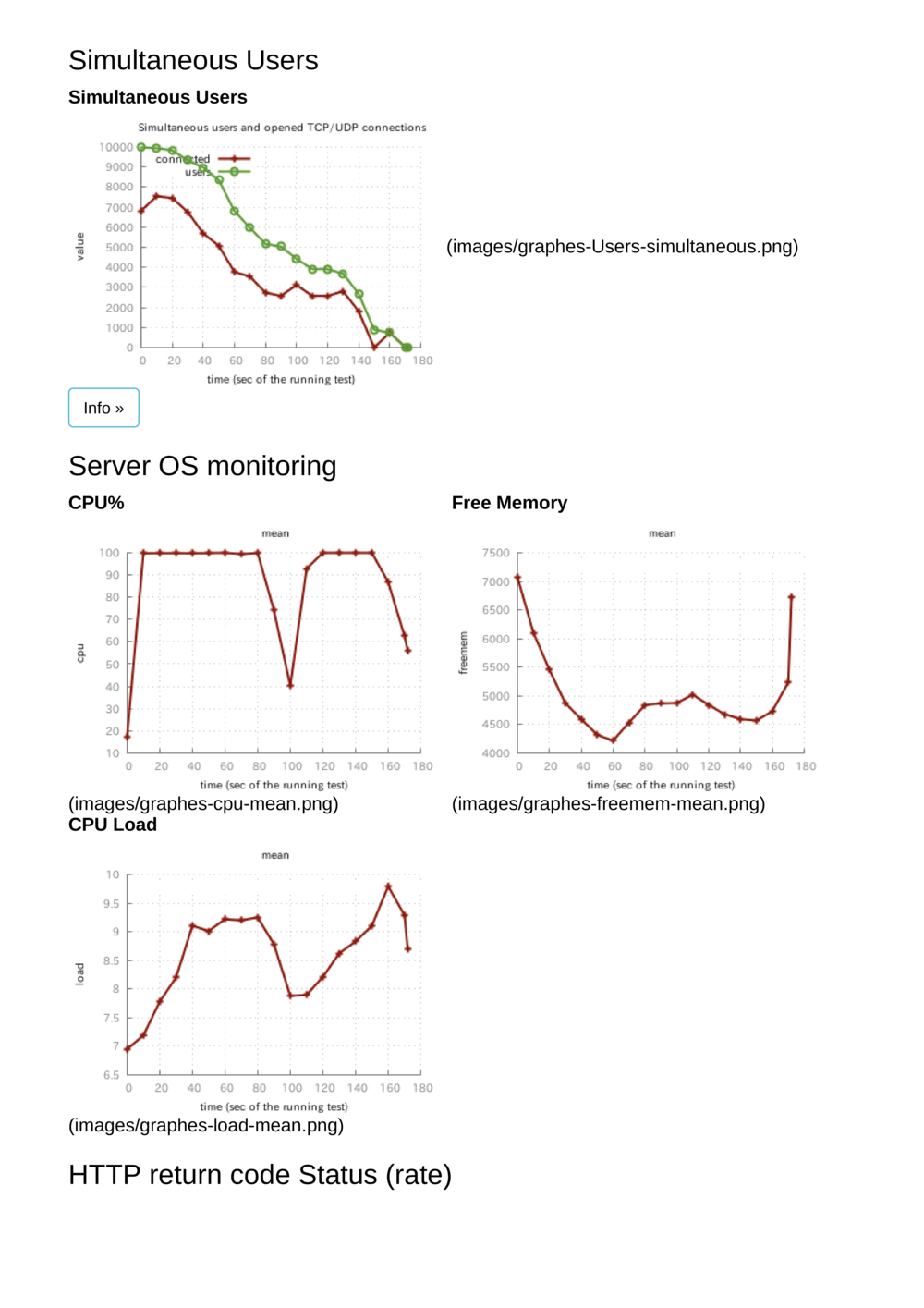
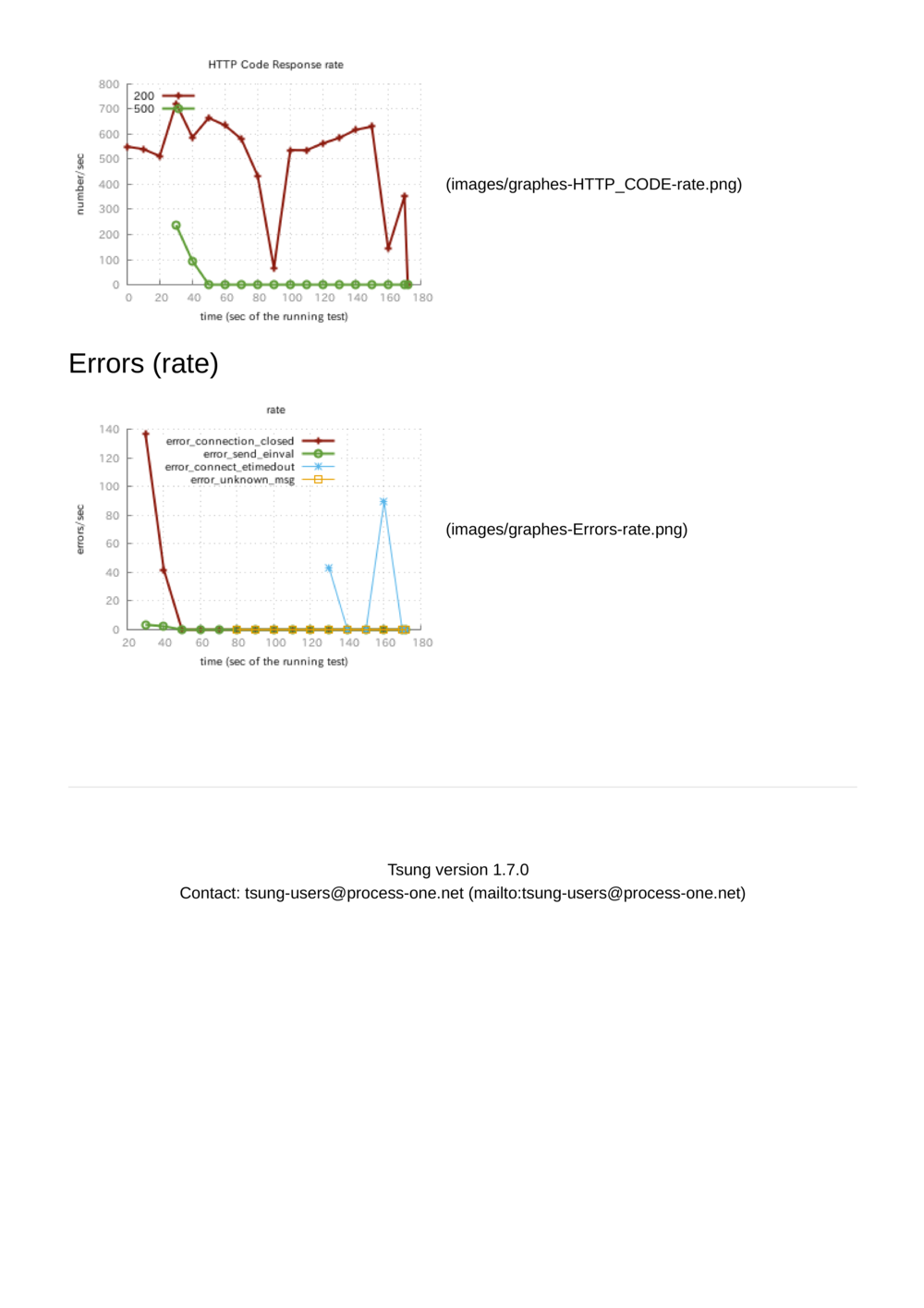
ちなみに、優しくテストしてあげると650req/sくらいさばいてくれました(Tsungとアプリを同じマシンで走らせています)。
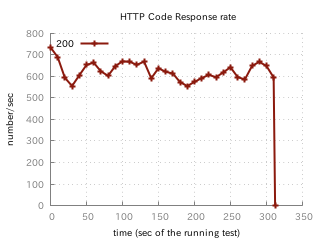
本当は1000req/sくらい出てほしかったのですが。