puppeteerでどんなことができるかをざっくりと知るため、puppeteerの公式サンプルプログラムたちを1つずつ紹介してみようと思います。
block-images.js
'use strict';
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setRequestInterception(true);
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto('https://news.google.com/news/');
await page.screenshot({path: 'news.png', fullPage: true});
await browser.close();
})();
Googleニュースの画面スクリーンショットを取得するプログラムです。
以下のようなスクリーンショットが取得できました(実際には画面下まであるのでもっと長いです)。
スクリーンショットはpage.screenshot([options])というAPIを実行するだけで取得できちゃいます。
このプログラムでのポイントはpage.setRequestInterception(true)というAPIです。
HTTPリクエストをインターセプトして、リクエストを継続する(continue())か中止する(abort())かを指定できるようになります。
ここではリクエストするリソースの種類が画像の場合、リクエストを中止するという処理をしています。
なので取得したスクリーンショットに画像が表示されていません。
custom-event.js
'use strict';
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Define a window.onCustomEvent function on the page.
await page.exposeFunction('onCustomEvent', e => {
console.log(`${e.type} fired`, e.detail || '');
});
/**
* Attach an event listener to page to capture a custom event on page load/navigation.
* @param {string} type Event name.
* @return {!Promise}
*/
function listenFor(type) {
return page.evaluateOnNewDocument(type => {
document.addEventListener(type, e => {
window.onCustomEvent({type, detail: e.detail});
});
}, type);
}
await listenFor('app-ready'); // Listen for "app-ready" custom event on page load.
await page.goto('https://www.chromestatus.com/features', {waitUntil: 'networkidle2'});
await browser.close();
})();
Chrome Platform Statusというサイトのロード時に発火されるapp-readyというカスタムイベントを取得して表示するプログラムです。
スクリプトを実行してみると、以下のような出力がされたりされなかったりしました。
$ node custom-event.js
app-ready fired {}
まず気になるAPIはpage.exposeFunction(name, puppeteerFunction)。
これはページのwindowオブジェクトにnameという関数を定義します。
関数本体はpuppeteerFunction。
puppeteerFunctionはブラウザではなくNode.jsのコンテキスト内で実行されます。
ここではwindow.onCustomEvent関数を定義しています。
次はpage.evaluateOnNewDocument(pageFunction, ...args)というAPIです。
ページがロードされたときにpageFunctionを実行します。
pageFunctionはページ内のJavaScriptファイルが実行される前に実行されます。
ここではapp-readyイベントに対するイベントリスナーを設定しており、app-readyイベントが発火したらwindow.onCustomEvent()を呼ぶようにしています。
detect-sniff.js
'use strict';
const puppeteer = require('puppeteer');
function sniffDetector() {
const userAgent = window.navigator.userAgent;
const platform = window.navigator.platform;
window.navigator.__defineGetter__('userAgent', function() {
window.navigator.sniffed = true;
return userAgent;
});
window.navigator.__defineGetter__('platform', function() {
window.navigator.sniffed = true;
return platform;
});
}
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.evaluateOnNewDocument(sniffDetector);
await page.goto('https://www.google.com', {waitUntil: 'networkidle2'});
console.log('Sniffed: ' + (await page.evaluate(() => !!navigator.sniffed)));
await browser.close();
})();
https://www.google.com をロードした時に、JavaScriptからwindow.navigator.userAgentもしくはwindow.navigator.platformが参照されているかどうかを出力するプログラムです。
$ node detect-sniff.js
Sniffed: true
すでに出てきたpage.evaluateOnNewDocument(pageFunction, ...args)というAPIが使われています。
ページがロードされたときに、sniffDetector関数を実行するように設定しています。
sniffDetectorは、window.navigator.userAgentプロパティとwindow.navigator.platformプロパティに関数を設定しています。
それらのプロパティが参照されたときに、window.navigator.sniffedをtrueにするようにしています。
page.evaluate(pageFunction, ...args)は、pageFunctionをそのページのコンテキストで実行します。
pageFunctionの戻り値を取得することができるので、ここでは!!navigator.sniffedつまりtrueが出力されています。
pdf.js
'use strict';
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com', {waitUntil: 'networkidle2'});
await page.pdf({
path: 'hn.pdf',
format: 'letter'
});
await browser.close();
})();
Y Combinator | Hacker NewsのページをPDF化するプログラムです。
以下のようなPDFファイルが生成されました。
page.pdf(options)という一つのAPIだけでPDFが作成できます。
ここではファイル名とフォーマット形式のみ指定されていますが、他にも幅や高さの指定、ヘッダーやフッターのカスタマイズなどもできるようです。
proxy.js
'use strict';
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch({
args: [ '--proxy-server=127.0.0.1:9876' ]
});
const page = await browser.newPage();
await page.goto('https://google.com');
await browser.close();
})();
ブラウザにプロキシを設定した状態でサイトにアクセスするプログラムです。
実際にプロキシ経由でアクセスしているかを確認するために、
ここからプロキシサーバのプログラムを拝借して試してみます(ポート番号だけ変更しました)。
var http = require('http'),
net = require('net'),
httpProxy = require('http-proxy'),
url = require('url'),
util = require('util');
var proxy = httpProxy.createServer();
var server = http.createServer(function (req, res) {
util.puts('Receiving reverse proxy request for:' + req.url);
proxy.web(req, res, {target: req.url, secure: false});
}).listen(9876);
server.on('connect', function (req, socket) {
util.puts('Receiving reverse proxy request for:' + req.url);
var serverUrl = url.parse('https://' + req.url);
var srvSocket = net.connect(serverUrl.port, serverUrl.hostname, function() {
socket.write('HTTP/1.1 200 Connection Established\r\n' +
'Proxy-agent: Node-Proxy\r\n' +
'\r\n');
srvSocket.pipe(socket);
socket.pipe(srvSocket);
});
});
proxy.jsを実行すると、プロキシサーバのログが以下の通り出力されました。
プロキシ経由でGoogleにアクセスできているようです。
$ node proxy-server.js
Receiving reverse proxy request for:http://google.com/
Receiving reverse proxy request for:http://www.google.co.jp/?gfe_rd=cr&dcr=0&ei=-czVWsTxFKauX-bAl9AE
Receiving reverse proxy request for:www.google.co.jp:443
Receiving reverse proxy request for:ssl.gstatic.com:443
Receiving reverse proxy request for:www.google.com:443
Receiving reverse proxy request for:adservice.google.co.jp:443
screenshot-fullpage.js
'use strict';
const puppeteer = require('puppeteer');
const devices = require('puppeteer/DeviceDescriptors');
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.emulate(devices['iPhone 6']);
await page.goto('https://www.nytimes.com/');
await page.screenshot({path: 'full.png', fullPage: true});
await browser.close();
})();
block-images.jsと同じく、画面スクリーンショットを取得するプログラムです。
page.screenshot([options])というAPIを使用しています。
ここで注目すべきはpage.emulate(options)というAPIです。
optionsにはviewportやuserAgentなどを渡すことができ、モバイルデバイスなどをエミュレートできるようです。
メジャーなデバイスについてはpuppeteer/DeviceDescriptorsモジュールを使用することで細かなパラメータの指定をせずに済みます。
ここではiPhone6をエミュレートしてページにアクセスしています。
実際に取得した画像は以下のようなものです。
New Yourk Timesがモバイル用のレイアウトで表示されています。
screenshot.js
'use strict';
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('http://example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
同じくスクリーンショットを取るプログラムです。
http://example.com の画面スクリーンショットを取得しています。
search.js
'use strict';
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://developers.google.com/web/');
// Type into search box.
await page.type('#searchbox input', 'Headless Chrome');
// Wait for suggest overlay to appear and click "show all results".
const allResultsSelector = '.devsite-suggest-all-results';
await page.waitForSelector(allResultsSelector);
await page.click(allResultsSelector);
// Wait for the results page to load and display the results.
const resultsSelector = '.gsc-results .gsc-thumbnail-inside a.gs-title';
await page.waitForSelector(resultsSelector);
// Extract the results from the page.
const links = await page.evaluate(resultsSelector => {
const anchors = Array.from(document.querySelectorAll(resultsSelector));
return anchors.map(anchor => {
const title = anchor.textContent.split('|')[0].trim();
return `${title} - ${anchor.href}`;
});
}, resultsSelector);
console.log(links.join('\n'));
await browser.close();
})();
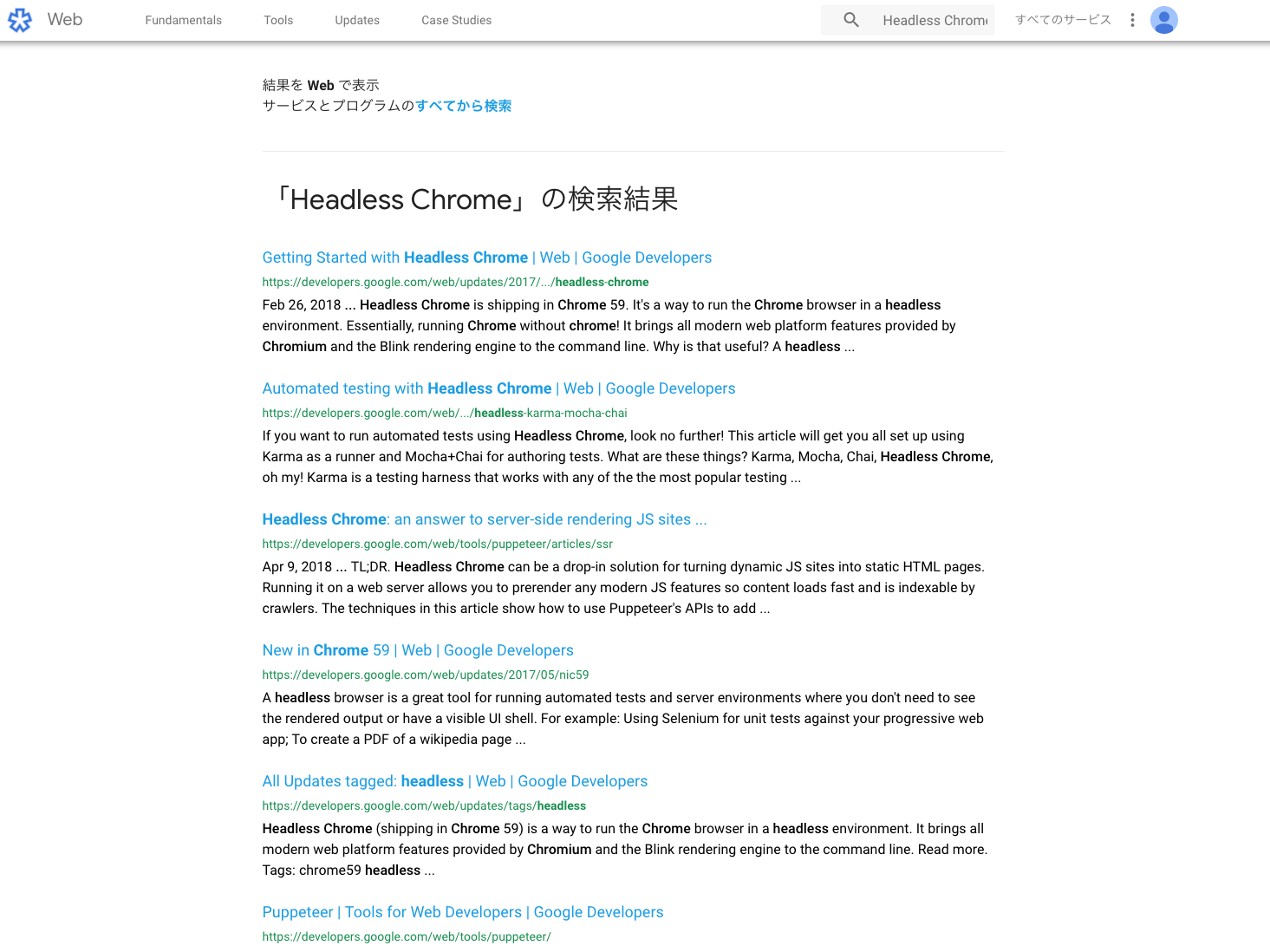
Google Developersで検索を実行し、検索結果のタイトルを取得するプログラムです。
実行結果は以下のとおりです。
$ node search.js
Getting Started with Headless Chrome - https://developers.google.com/web/updates/2017/04/headless-chrome
Automated testing with Headless Chrome - https://developers.google.com/web/updates/2017/06/headless-karma-mocha-chai
Headless Chrome: an answer to server-side rendering JS sites ... - https://developers.google.com/web/tools/puppeteer/articles/ssr
New in Chrome 59 - https://developers.google.com/web/updates/2017/05/nic59
All Updates tagged: headless - https://developers.google.com/web/updates/tags/headless
Puppeteer - https://developers.google.com/web/tools/puppeteer/
Examples - https://developers.google.com/web/tools/puppeteer/examples
ヘッドレス Chrome ことはじめ - https://developers.google.com/web/updates/2017/04/headless-chrome?hl=ja
FAQ - https://developers.google.com/web/tools/puppeteer/faq
Articles by Eric Bidelman - https://developers.google.com/web/resources/contributors/ericbidelman
実際にChromeでアクセスして、Headless Chromeで検索してみました。
上記で出力されているものと一致しています。
page.type(selector, text[, options])はselectorで指定された要素にtextを入力するAPIです。
ここではHeadless Chromeという文字列を検索ボックスに入力しています。
page.waitForSelector(selector[, options])は、selectorで指定した要素が表示されるまで待つAPIです。
ここで指定している.devsite-suggest-all-resultsは、検索候補を表示する部分です。
page.click(selector[, options])というAPIで検索候補の一番目をクリックします。
クリックしたら、.gsc-results .gsc-thumbnail-inside a.gs-titleが表示されるまで待ちます。
これは検索結果を表示する部分です。
検索結果が表示されたら、page.evaluate(pageFunction, ...args)で検索結果のタイトルを取得する関数を実行します。
関数はページのコンテキストで実行されるので、document.querySelectorAll()が使えます。
まとめ
以上、全8つのプログラムを紹介しました。
スクリーンショットやPDFがたった1行のプログラムで取得できたり、画面入力も手軽にできるなど、E2Eテスト目的だけでなくいろいろなことに使えそうです。
ここで紹介されているAPIはほんのごくわずかで、puppeteerにはかなりの数のAPIが用意されています。
是非チェックしてみてください。
puppeteer API