はじめに
Residual Network (ResNet) がILSVRC 2015の覇者となり、2015年末にその論文が発表されました。そして、2016年にはResNetの改良版が研究され、「我こそSOTA (state-of-the-art) だ」という論文が大量に発表されました。畳み込み層やチャンネル数を増やしてみたり、ショートカットを増やしてみたり、活性化関数の位置を変更してみたり・・・。その結果、CIFAR-10の画像分類精度も大幅に向上し、2015年のResNetではエラー率6.43%だったのが、2017年2月にはエラー率2.86%が報告されています。
しかし、2017年7月現在、疑問に思うわけです。
何がResNetの分類精度を向上させたのでしょうか?
発表された論文に実験結果が載っているのですが、論文によってパラメータ数や学習回数が異なるので、単純に「エラー率が低い=性能のよいCNN」とは結論付けられません。というわけで、いくつかのDeep-CNNをできるだけ同じ条件で比較してみたいと思います。
ちなみに、ここでは5種類のDeep-CNNだけを試していきますが、さらに多くのDeep-CNNを試したaiskoaskosdさんの素晴らしい記事もあります。
2016年の深層学習を用いた画像認識モデル
評価方法と比較するDeep-CNN
データセットCIFAR-10を使って、Deep-CNNの分類精度を比較評価していきます。比較対象のDeep-CNNは、画像認識CNNの常識を変えたResNet[1]・Wide-ResNet[2]、2016年にCIFAR-10のSOTA競争をしていたPyramidNet[3]・DenseNet[4]・ResNeXt[5]、2017年にCIFAR-10のSOTAとなったShakeNet[6]※です。これらのDeep-CNNについて、パラメータ数が約400万個となるCNNを実装し、CIFAR-10の画像分類タスクのエラー率を測定します。
※ShakeNet: 論文中には名前が出てこないので、勝手にShakeNetと呼ぶことにします。
Deep-CNNの全体構成としては、3x3の畳み込み層で入力処理をした後、ResBlockなどで32x32の畳み込み計算、Average Poolingで16x16に縮小、16x16の畳み込み計算、Average Poolingで8x8に縮小、8x8の畳み込み計算、Global Poolingした後に全結合層で10個の出力にする、となっています。
ResNet (depth=14) の場合、下図のような構成になります。
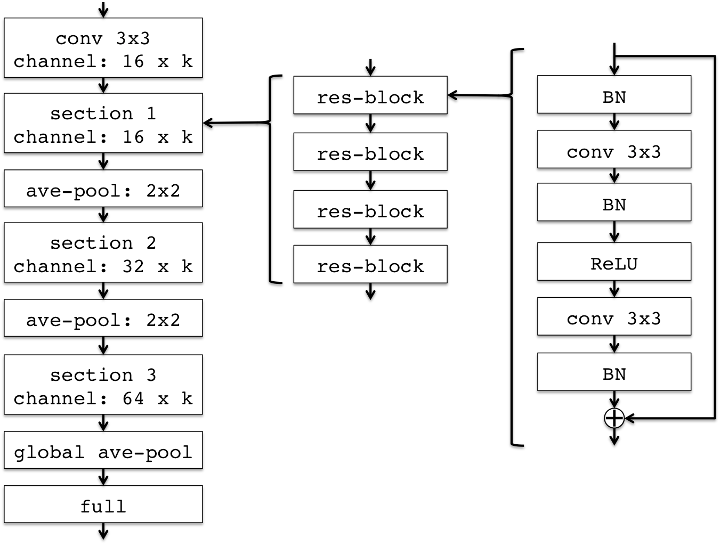
Deep-CNNの中にはstride=2の畳み込み層を用いて画像サイズを縮小しているものがありますが、今回の実験ではAverage Poolingを使って画像サイズを縮小します。また、チャンネル数が異なる場合の加算処理ですが、ここではZero Padding方式で統一しています。
学習時の入力画像ですが、CIFAR-10の画像分類でよく使われているData Augmentation(Random Clippingと反転)を行っています。一方、平均と分散を使った正規化は行っていません。バッチサイズは128で、Momentum SGD (Momentum=0.9, WeightDecay=0.0001) でパラメータを更新します。また、学習回数は300回(epoch)とし、1〜150回目の学習係数は0.1、151〜225回目の学習係数は0.01、226〜300回目の学習係数は0.001としました。
この条件で、下記のDeep-CNNの画像分類精度を比較評価します。
- ResNet, Wide-ResNet
- 論文[1]や論文[2]を参考に実装しました。
ただし、ResBlockは論文[3]で提案されているSingle ReLUにしています。 - PyramidNet
- 論文[3]を参考に実装しました。
これも、ResBlockはSingle ReLUにしています。 - DenseNet
- 論文[4]を参考に実装しました。
ただし、BottleneckやCompressionは導入していません。 - ResNeXt
- 論文[5]を参考に実装しました。
- ShakeNet
- 論文[6]を参考に実装しました。
これも、ResBlockはSingle ReLUにしています。
実験結果
上記の実装にCIFAR-10の画像分類タスクを学習させたところ、それぞれのDeep-CNNの分類エラー率は以下のようになりました。参考として、論文で報告されているエラー率も載せています。
それぞれ、1回だけ試行したときの結果であり、複数回試行の平均値ではありません。そのため、「たまたま」良い結果や悪い結果が得られた可能性がありますが、そのあたりの考察は後述します。
| Deep-CNN | エラー率 (パラメータ数) | 論文中のエラー率 (パラメータ数) |
|---|---|---|
| ResNet k=1 depth=248 |
5.14% (4.0M) | |
| ResNet k=2 depth=62 |
4.72% (3.8M) | |
| ResNet k=4 depth=20 |
4.97% (4.3M) | |
| ResNet k=4 depth=40 [2] |
4.97% (8.9M) | |
| PyramidNet α=84 depth=116 |
4.76% (4.1M) | |
| PyramidNet α=200 depth=26 |
4.98% (3.8M) | |
| PyramidNet α=84 depth=100 [3] |
4.26% (3.8M) | |
| DenseNet k=12 depth=74 |
5.06% (4.0M) | |
| DenseNet k=12 depth=100 [4] |
4.10% (7.0M) | |
| ResNeXt 4x16d depth=101 |
4.62% (4.0M) | |
| ResNeXt 2x32d depth=65 |
4.76% (3.9M) | |
| ResNeXt 8x64d depth=29 [5] |
3.65% (34.4M) | |
| Shake-Shake depth=32 |
4.54% (3.7M) | |
| Shake-Shake depth=26 [6] |
3.55% (2.9M) |
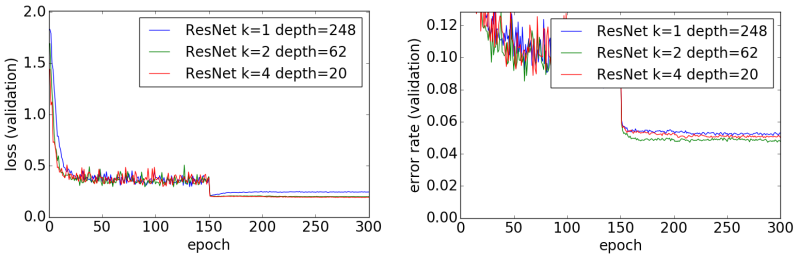
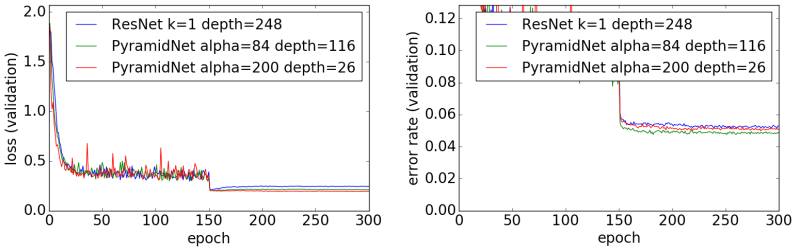
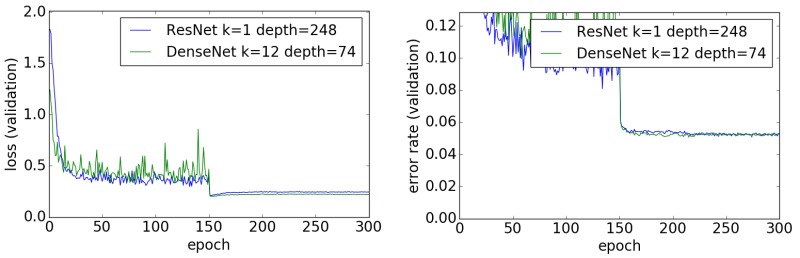
1位はShakeNet(4.54%)、2位はResNeXt(4.62%)、3位はResNet(4.72%)となりました。一方、PyramidNetとDenseNetは、あまり精度が上がりませんでした。
それぞれのDeep-CNNについて
ResNet
論文[1]ではResNetの層数(深さ)を増やすことで画像分類の精度を向上できると考えられていました。しかし、論文[2]で述べられているように、ResNetのチャンネル数を増やすことでも分類精度が向上します。ただし、層数が足りないと分類精度が悪くなるので、ちょうどよい層数とチャンネル数を探す必要があります。ResNetの場合、30層以上であればネットワークの深さには問題ないようですので、あとは層数を増やしてアンサンブル効果[8]を狙うか、チャンネル数を増やして表現力上昇を狙うか、という選択になるのでしょう。
今回の実験では、論文[2]で報告されている分類精度よりも高い精度となりましたが、これはResBlockにSingle ReLUを採用したためと思われます。ResBlockをオリジナルのPre-Activationに変更すると、論文通りの結果となります。ちなみに、Dropoutを入れると、ほんの少しだけ分類精度が上がります。
PyramidNet
論文[3]で報告されている結果に比べて、今回の実験ではあまり良い結果にはなりませんでした。今回の実験で分かったことの1つは、PyramidNetは初期値に左右されやすいCNNだということです。この実験の後に「α=84, depth=116」の再実験を何回かやってみたのですが、結果はエラー率4.34%~5.12%となり、初期値によって大きく分類精度が変わってくるという結果になりました。PyramidNetで高い分類精度を出すためには、初期値ガチャでよい初期値を引く必要があるようです。
一方、この論文[3]で提案されているSingle ReLUはResNetの分類精度を大幅に向上させるようで、Single ReLUこそがこの論文の最も重要な部分かもしれません。現在のところ、ResBlockにはSingle ReLUを使っておけばいいのではないか、と私は思っています。
ちなみに、PyramidNetはチャンネル数を線形に増やすので、ResNetよりも計算量が多くなります。
DenseNet
こちらも、論文[4]には届かない結果となりました。ただし、論文で報告されているパラメータ数は700万個ですので、さらにパラメータ数を増やせば4.10%に届く可能性は十分にあります。
DenseNetの「加算処理」は加算(element wise addition)ではなく連結(concatenation)なのですが、私の経験上、連結はあまりよい方法ではない気がします。ResNetやPyramidNetの加算処理を連結にしてみてもメモリの消費量が増えるだけで、分類精度は上がりませんでした。ただ、DenseNetの連結処理を加算に変更すると分類精度が低下しますので、DenseNetには連結がベストなのでしょう。Deep-CNNの面白いところです。
ちなみに、DenseNetを学習させるためには他のDeep-CNNよりも多くのメモリを必要とします。あと、PyramidNetと同じようにチャンネル数を線形に増やすので、ResNetに比べて計算量が多くなります。高価な実行環境を持っている人向けのDeep-CNNです。
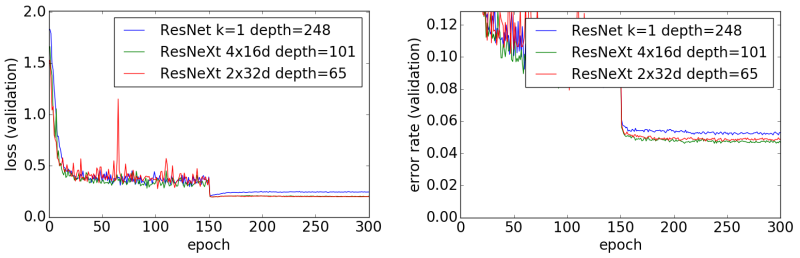
ResNeXt
論文[5]に載っている実験結果を見ると「Wide-ResNetより少しよい」ということですので、今回の実験結果は概ね論文通りと言えるかと思います。また、論文に書かれている通り、大きな畳み込み層を少し配置するよりも、小さな畳み込み層を多く配置した方がよい結果を得られました。
ResNeXtは複数の畳み込み層のアンサンブル効果を狙った構成になっている(と思う)のですが、並列に配置された畳み込み層のアンサンブル効果の発動具合は初期値に依存します。つまり、畳み込み層の数が少ない場合、初期値ガチャで良い初期値を引かないと分類精度が上がらないということになります。今回の実験でも、ResNeXt 2x32dの分類精度はあまり安定しませんでした(PyramidNetほどではないですが)。
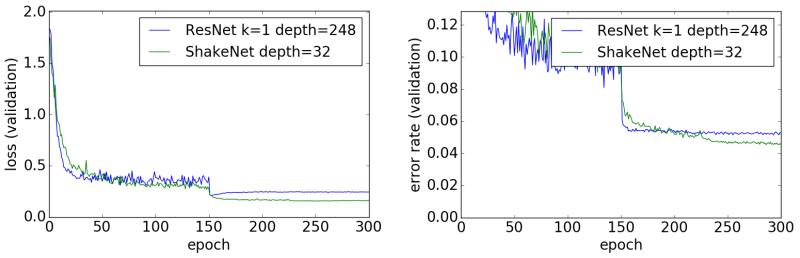
ShakeNet
最後に2017年2月にCIFAR-10のSOTAを出したShakeNetです。ForwardとBackwardのパスが異なるという正気とは思えない設計ですが、意外なことに、これがよい結果を出しています。
特に驚いたのは、学習曲線が他のDeep-CNNとまったく異なる点です。他のDeep-CNNの場合、学習率が0.01以下になった後のエラー率はあまり改善されません。一方、ShakeNetの場合、学習率が0.01以下であってもエラー率が改善されていきます。今回は300回で学習を打ち切っていますが、学習回数を増やせばさらに高い分類精度を叩き出しそうです。
あと、論文[6]によるとCosine Annealing[8]という方法で学習係数を変化させるとよいそうです。つまり、今回の実験はShakeNetには不利な条件ということになるのですが、それでも他よりも高い分類精度を出したわけです。CIFAR-10のエラー率3%以下というのも分かる気がします。
ちなみに、ShakeNetも初期値の影響を受けやすいDeep-CNNで、やはり初期値ガチャが必要です。
おわりに
まずは、Single ReLUの効果が絶大だということが分かりました。普通のResNetのResBlockをSingle ReLUに変更するだけで画像分類精度が大幅に向上します。ResNetにSingle ReLUを導入し、チャンネル数を増やすだけで、CIFAR-10の4%の壁を簡単に突破することができます。
また、初期値の影響を受けやすいDeep-CNNがあることも分かりました。ResNetやResNeXtに比べると、PyramidNetやShakeNetは初期値の影響を受けやすく、よい初期値を引かないと高い分類精度を出せません。同様に、初期値の影響を受けやすいDeep-CNNの要素もありまして、stride=2の畳み込み層による画像サイズの縮小や1x1の畳み込み層によるチャンネル数の変更も初期値に影響されるようです。
最後に、DropoutやStochastic Depthなどのランダムに経路を切る方法についてですが、これらの手法のドロップ率の調整は本当に難しいです。Dropoutの方は頑張ればできるのですが、Stochastic Depthを使って分類精度を上げるためには職人技が必要になってきます。というわけで、私には使いこなせなかったので、今回の実験にはDropoutもStochastic Depthも入れておりません。
実装
上記の実験に使った実装をgithubで公開しています。
https://github.com/takedarts/resnetfamily
参考文献
- He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. (2016).
- Zagoruyko, Sergey, and Nikos Komodakis. "Wide residual networks." arXiv preprint arXiv:1605.07146 (2016).
- Han, Dongyoon, Jiwhan Kim, and Junmo Kim. "Deep pyramidal residual networks." arXiv preprint arXiv:1610.02915 (2016).
- Huang, Gao, et al. "Densely connected convolutional networks." arXiv preprint arXiv:1608.06993 (2016).
- Xie, Saining, et al. "Aggregated residual transformations for deep neural networks." arXiv preprint arXiv:1611.05431 (2016).
- Gastaldi, Xavier. "Shake-Shake regularization." arXiv preprint arXiv:1705.07485 (2017).
- Veit, Andreas, Michael J. Wilber, and Serge Belongie. "Residual networks behave like ensembles of relatively shallow networks." Advances in Neural Information Processing Systems. (2016).
- Loshchilov, Ilya, and Frank Hutter. "Sgdr: Stochastic gradient descent with warm restarts." (2016).