AWS 利用料の詳細を把握するため、Data Exports で CUR (Cost Usage Report) 2.0 データを月単位で S3 に出力しているのですが、ここから特定の EC2 インスタンスのデータのみを別の CSV ファイルに抽出したいと思い立ちました。
CUR 2.0 データは CSV 形式のテキストファイルを GZIP 形式で圧縮して S3 に出力しているため、これを展開し、中の CSV ファイルを取り出してから抽出しなければなりません。
手作業は面倒なので、Lambda から Data Exports 出力先 S3 バケットの GZIP ファイルを展開し、EC2 インスタンスのデータのみ抽出して CSV に出力してから別の S3 バケットへ保存する処理を自動化してみたいと思います。
Lambda 関数の作成
マネジメントコンソールから「関数の作成」をします。
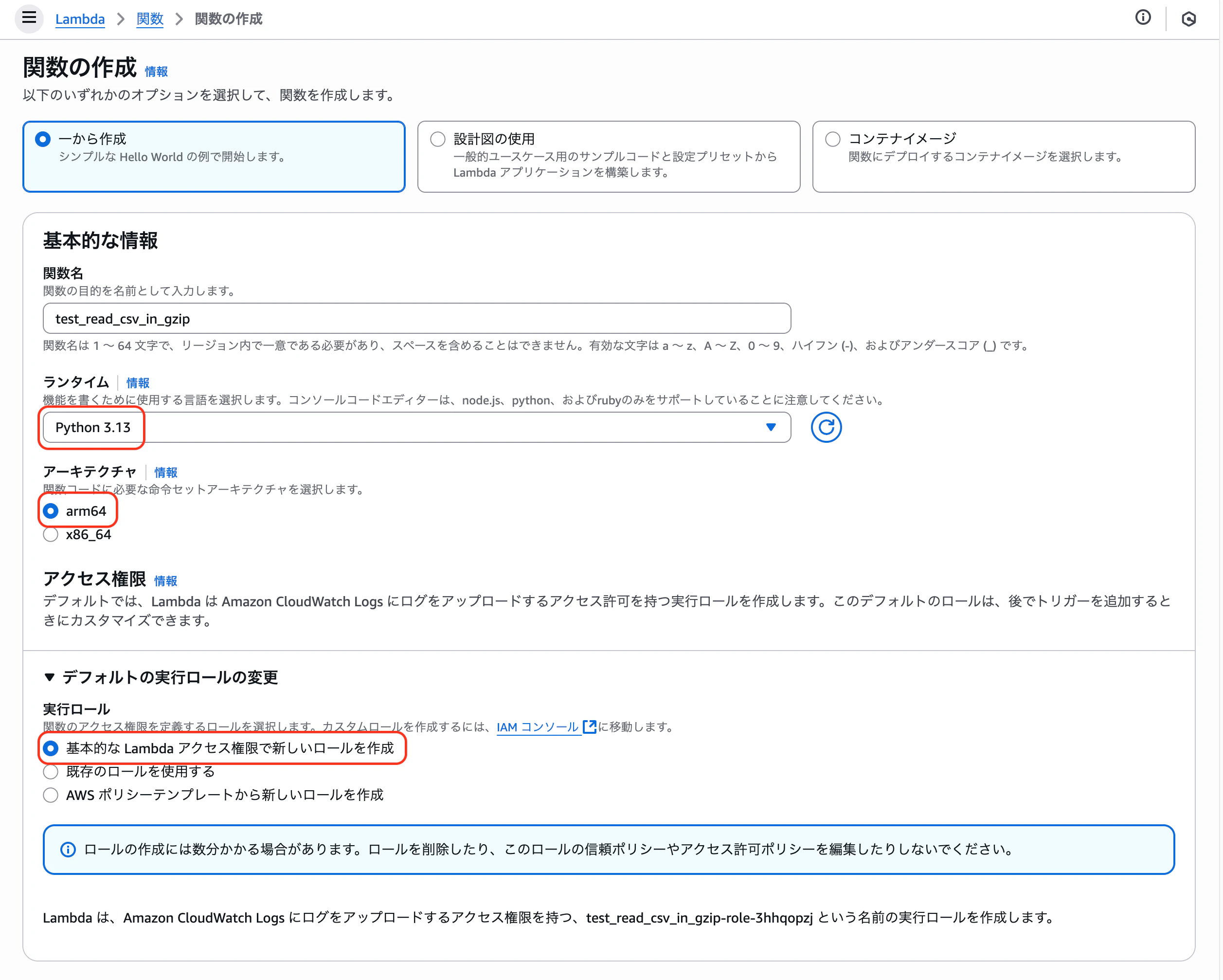
ランタイムは Python を、アーキテクチャはコスト効率の良い arm64 を選択しました。
ここでポイントとなるのが、Lambda 関数の実行ロールです。事前に必要なポリシー、信頼関係などを設定した IAM ロールを作成しておき、それを割り当てるか、この画面で作成するか、いずれかの方法で Lambda 関数に IAM ロールを実行ロールとして割り当てます。
ここでは「基本的な Lambda アクセス権限で新しいロールを作成」で自動的に IAM ロールを作成してみました。
作成された IAM ロールを確認します。

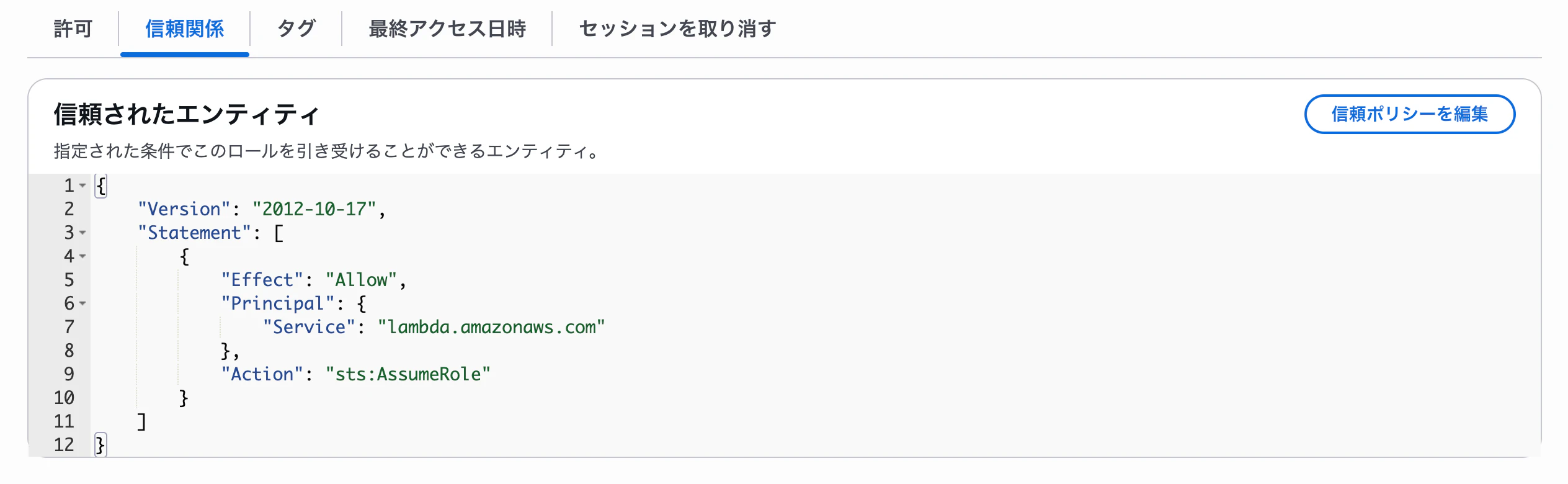
作成する Lambda 関数の処理に合わせて、適宜 IAM ロールの修正が必要になるかと思います。
Lambda 関数から S3 バケットを読み書きするためには、Lambda 関数の実行ロールに設定した IAM ロールに対する許可を、S3 バケットのバケットポリシーで設定する必要があります。
S3 バケットポリシーの設定
Data Exports の出力先 S3 バケット側の設定
既存のバケットポリシーに以下のとおり、Lambda 関数の実行ロールに対して S3 バケットの読み取りを許可する設定を追記しました。
{
"Sid": "EnableAWSLambdaToReadToS3",
"Effect": "Allow",
"Principal": {
"AWS": "Lambda 関数の実行ロールの ARN"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::Data Exports の出力先バケット名",
"arn:aws:s3:::Data Exports の出力先バケット名/*"
]
}
加工した CSV ファイルの出力先 S3 バケット側の設定
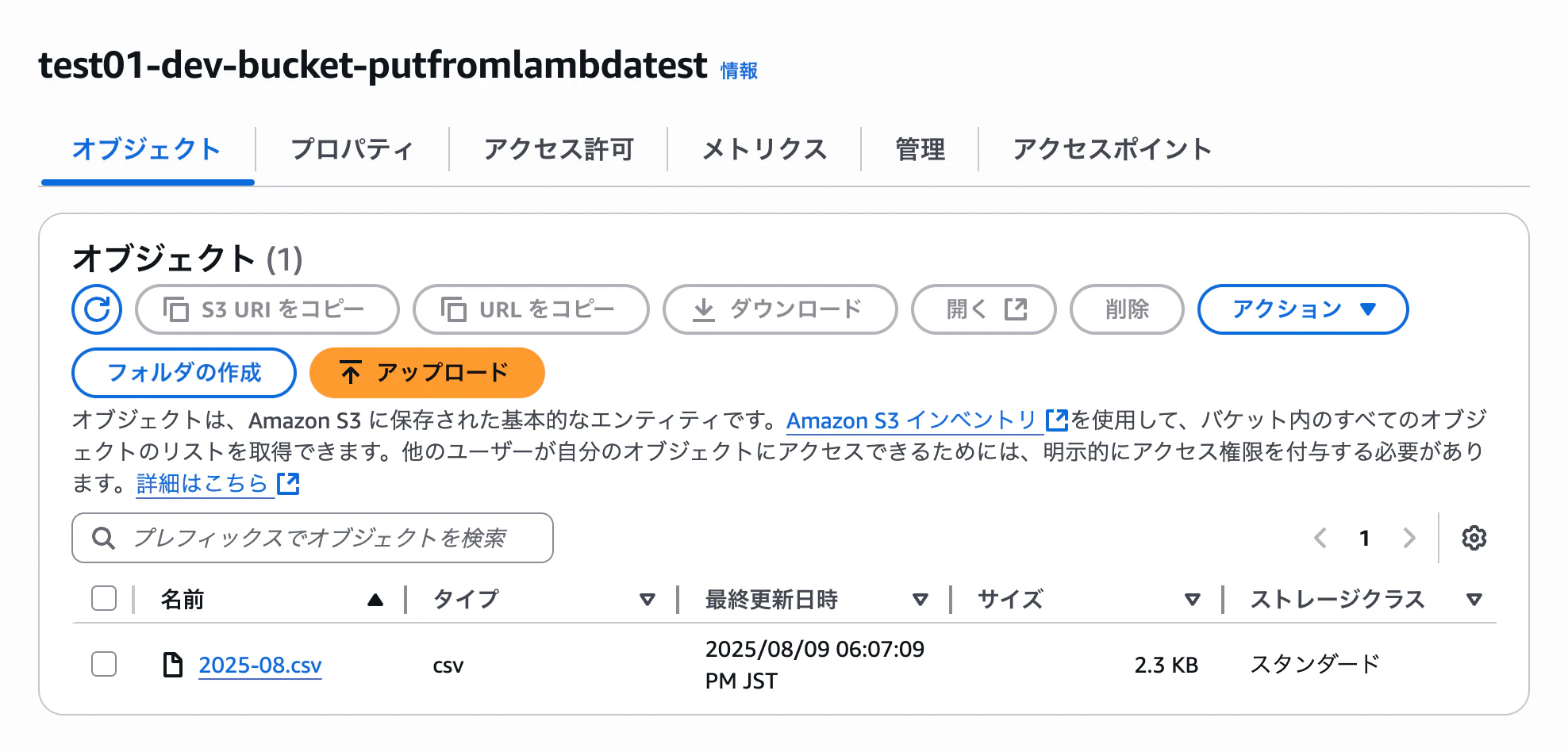
こちらは新規に「test01-dev-bucket-putfromlambdatest」という名前の S3 バケットを作成し、以下の内容で書き込みを許可するバケットポリシーを設定しました。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "EnableAWSLambdaToWriteToS3",
"Effect": "Allow",
"Principal": {
"AWS": "Lambda 関数の実行ロールの ARN"
},
"Action": [
"s3:GetObject",
"s3:ListBucket",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::test01-dev-bucket-putfromlambdatest",
"arn:aws:s3:::test01-dev-bucket-putfromlambdatest/*"
]
}
]
}
これで Lambda 関数から S3 バケットへ読み書きする準備は完了です。
S3 バケットの GZIP ファイルを展開して加工後に別バケットへ保存する Lambda 関数のサンプル
Lambda の開発のお作法が全然分からなかったのですが、最低限動く Python スクリプトのサンプルです。
イベントに、対象年月を「YYYY-MM」の形式で、対象インスタンスのインスタンス ID とボリューム ID をそれぞれキーにセットして Lambda 関数側に渡してパラメーターとします。
一旦 S3 バケットから GZIP ファイルを、Lambda 関数が扱えるローカルのパス /tmp にダウンロードし、これを展開してパラメーターで指定したインスタンス ID かボリューム ID を含む行のみを抽出して別の CSV ファイルとして /tmp に出力し、これを別の S3 バケットへアップロードするようにしました。
Python のサンプルコード
import csv
import gzip
from pathlib import Path
import boto3
CUR_BUCKET_NAME = "test01-dev-buckets-dataexports"
CUR_BUCKET_PREFIX = "CUR/test01-dataexports/data/BILLING_PERIOD="
CUR_FILE_NAME = "test01-dataexports-00001.csv.gz"
OUTPUT_BUCKET_NAME = "test01-dev-bucket-putfromlambdatest"
client = boto3.client("s3")
def lambda_handler(event, context):
# event の "TargetTerm" キーに "YYYY-MM" の形式で対象の月を文字列でセットする。
target_term = event["TargetTerm"]
# Data Exports の出力先 S3 バケットから /tmp に gzip ファイルをダウンロードする。
bucket_prefix = CUR_BUCKET_PREFIX + target_term
key = bucket_prefix + "/" + CUR_FILE_NAME
cur_file_path = "/tmp/" + CUR_FILE_NAME
client.download_file(CUR_BUCKET_NAME, key, cur_file_path)
if not Path(cur_file_path).exists():
return '"' + cur_file_path + '"' + " does not exist."
if Path(cur_file_path).suffix != ".gz":
return '"' + cur_file_path + '"' + " is not gzip file."
# event の "Instances" キーに "InstanceId", "VolumeId" のキーを持つ Dict 要素をセットする。
# これらのキーの値は抽出したいインスタンスのインスタンス ID とボリューム ID をセットする。
instances = event["Instances"]
instances_number = len(instances)
if instances_number == 0:
return "no instance data in event."
# /tmp にダウンロードした gzip ファイルを展開し、CUR 2.0 の CSV から対象インスタンスの行のみ抽出する。
extracted_from_cur = list()
with gzip.open(cur_file_path, "rt") as f:
reader = csv.DictReader(f)
for row in reader:
for n in range(0, instances_number):
instance = instances[n]
if (
row["line_item_resource_id"] == instance["InstanceId"]
or row["line_item_resource_id"] == instance["VolumeId"]
):
extracted_from_cur.append(
[
row["bill_billing_period_start_date"],
row["bill_billing_period_end_date"],
row["line_item_product_code"],
row["line_item_line_item_description"],
row["line_item_line_item_type"],
row["line_item_operation"],
row["line_item_resource_id"],
row["line_item_unblended_rate"],
row["line_item_usage_amount"],
row["line_item_unblended_cost"],
row["resource_tags"],
]
)
if extracted_from_cur == []:
return "no instance data in CUR csv."
# /tmp に新規作成する CSV ファイルに CUR 2.0 の CSV から抽出した行データを書き込む。
output_path = "/tmp/" + target_term + ".csv"
with open(output_path, "w") as f:
writer = csv.writer(f)
writer.writerow(
[
"bill_billing_period_start_date",
"bill_billing_period_end_date",
"line_item_product_code",
"line_item_line_item_description",
"line_item_line_item_type",
"line_item_operation",
"line_item_resource_id",
"line_item_unblended_rate",
"line_item_usage_amount",
"line_item_unblended_cost",
"resource_tags",
]
)
writer.writerows(extracted_from_cur)
if not Path(output_path).exists():
return '"' + output_path + '"' + " does not exist."
# 抽出した CSV ファイルを S3 バケットにアップロードする。
client.upload_file(output_path, OUTPUT_BUCKET_NAME, Path(output_path).name)
return 0
(参考)Lambda 関数のデプロイ方法
Lambda 関数のデプロイ方法は色々あると思いますが、今回 VS Code に「AWS Toolkit」という拡張をインストールして使ったのがとても便利でした。
Lambda 関数を作成するアカウントに対して適切な権限のクレデンシャルを取得できるように AWS CLI のプロファイルを設定しておけば、VS Code で開発し、VS Code からデプロイしてくれます。
Lambda 関数へ渡すイベント
Lambda 関数に渡すイベントの JSON は次のとおりです。
{
"TargetTerm": "2025-08",
"Instances": [
{
"InstanceId": "抽出したい対象のインスタンス ID",
"VolumeId": "抽出したい対象のボリューム ID"
}
]
}
Lambda 関数のテスト
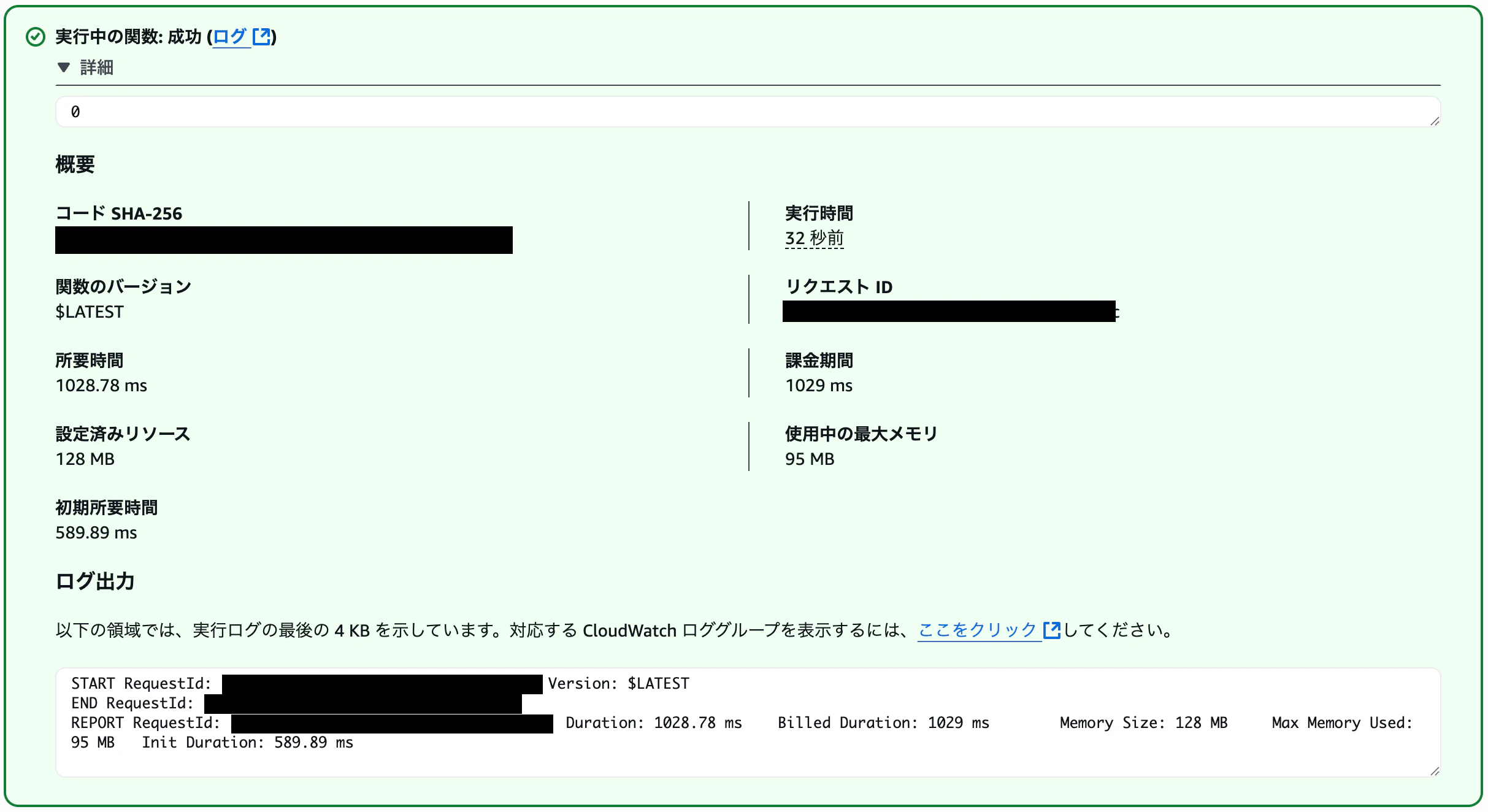
マネジメントコンソールから上記のイベントを設定してテストします。

期待したリターンコードが返ってきました。
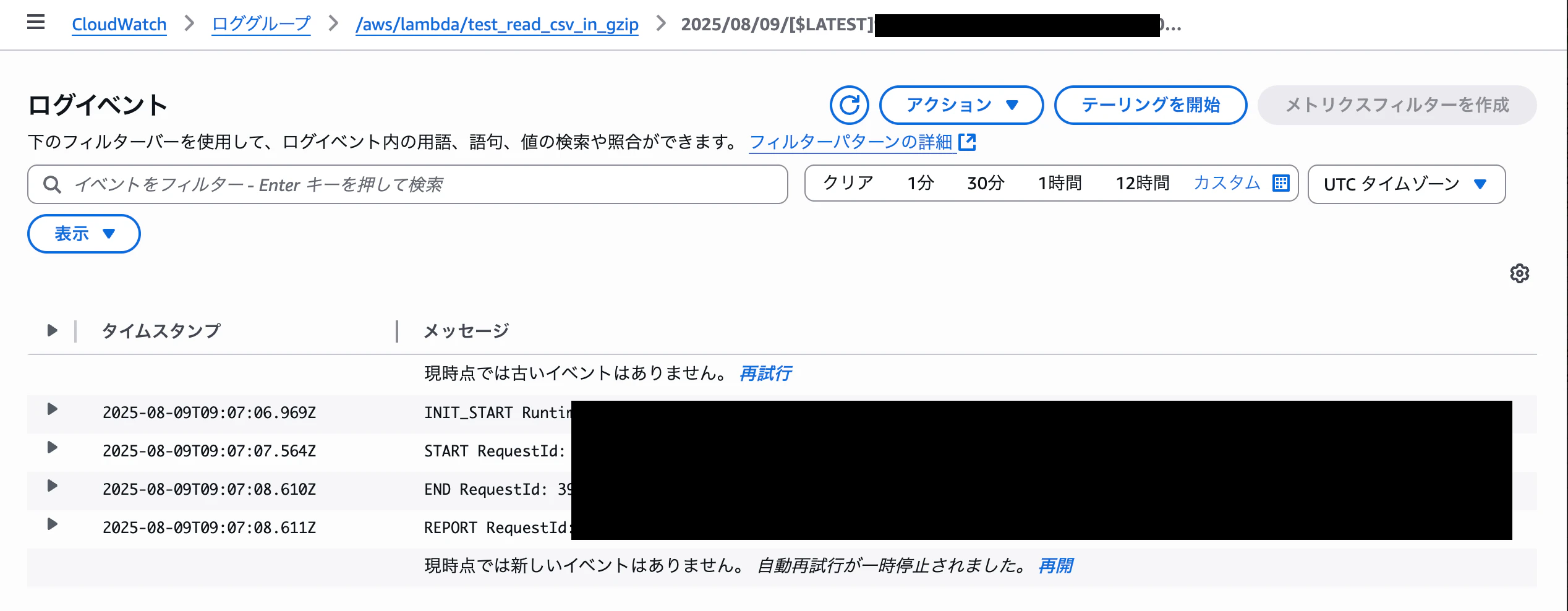
Lambda 関数を作成すると CloudWatch Logs のロググループが自動で作られており、CloudWatch Logs 側にも同様なログが記録されます。
S3 バケットに期待通り Lambda 関数からファイルをアップロードできていました。
こういった AWS リソースを扱う処理を作るのに Lambda は便利ですね。
Gov-JAWS#3 の宣伝
2025/08/20 の水曜日 12:00 から、公共分野の JAWS-UG である Gov-JAWS の第 3 回が開催されます!ガバメントクラウドをはじめ公共系の AWS 活用に興味のある人はぜひ参加をお願いします!