pandasのGroupByの拡張のようなTimeGrouperについて情報がなかったので備忘録として。
もっとデファクトスタンダードな方法があれば教えてください!
用例:特定の期間内での集計をしたい場合に有用
例
- 毎月の値を持つデータから6か月ごとに集計する
- 毎日の値をもつデータから1か月毎の集計をする
- タイムスタンプで取引記録を持つようなデータから日毎の集計をする
関連するstackoverflow
用例1:毎月の値を持つデータから6か月ごとに集計する ([1]より)
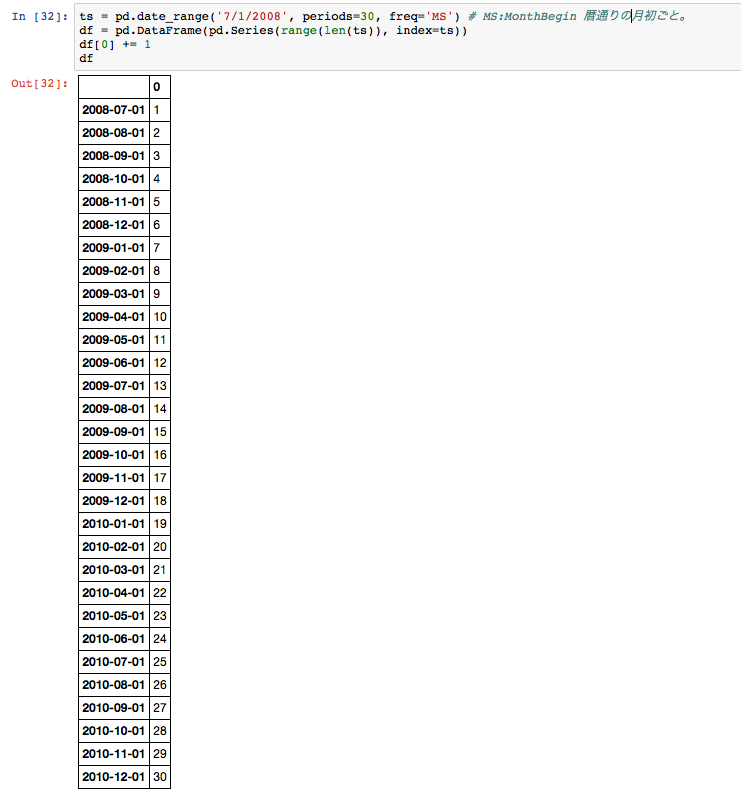
ts = pd.date_range('7/1/2008', periods=30, freq='MS')
df = pd.DataFrame(pd.Series(range(len(ts)), index=ts))
df[0] += 1
df # 2008/7/1から始まる月ごとのデータフレームができる
df2 = pd.DataFrame([0], index = [df.index.shift(-1, freq='MS')[0]])
df2

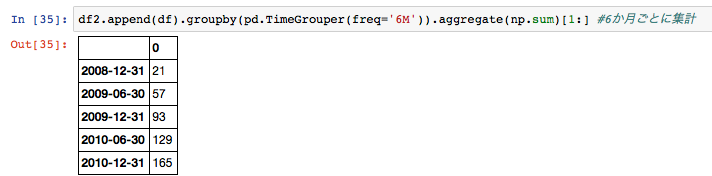
df2には6か月ごとの集計ができる
df2.append(df).groupby(pd.TimeGrouper(freq='6M')).aggregate(np.sum)[1:]
用例2:タイムスタンプで取引記録を持つようなデータから日毎の集計をする
rng = pd.date_range(start = '2014-01-01',periods = 100, freq='H')
df_original = pd.DataFrame({'Volume' : np.random.randint(100,2000,len(rng))}, index=rng)
df_original
Out[148]:
Volume
2014-01-01 00:00:00 1484
2014-01-01 01:00:00 1635
2014-01-01 02:00:00 984
2014-01-01 03:00:00 1239
2014-01-01 04:00:00 785
2014-01-01 05:00:00 871
2014-01-01 06:00:00 614
2014-01-01 07:00:00 119
2014-01-01 08:00:00 933
2014-01-01 09:00:00 624
... ...
2014-01-04 19:00:00 1832
2014-01-04 20:00:00 1996
2014-01-04 21:00:00 1040
2014-01-04 22:00:00 1867
2014-01-04 23:00:00 1098
2014-01-05 00:00:00 1397
2014-01-05 01:00:00 1996
2014-01-05 02:00:00 610
2014-01-05 03:00:00 1242
100 rows × 1 columns
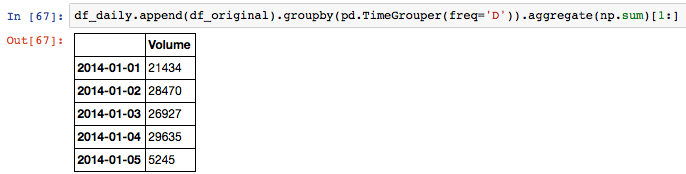
df_tmp = pd.DataFrame({'Volume':[0]}, index = [df_original.index.shift(-1, freq='D')[0]])
df_daily=df_tmp.append(df_original).groupby(pd.TimeGrouper(freq='D')).aggregate(np.sum)[1:]
df_daily
P.S
Qiitaでjupyterの埋め込みしたい