本文に入る前に...
・もともとOT領域でインフラ企画・運用保守面やアプリケーションの機能の実装の業務を行うことが多く、あまり機械学習や人工知能に関するなかったのですが、それらの勉強や実装を行うことになり、経験前と後で機械学習やAIに関する理解が180と変わりました
・そこで得た気づきやデータサイエンス未経験者(自分)が陥りがちな罠をつらつらと忘備録的に記載するために記事を作成することにしました
・基本的な考え方(筆者の理解)から、実際にデータセットを基礎分析・可視化し、モデルを構築して予測を行うまでを実際にコードを記述しながら解説することで自身の理解と自分と同じような方々に届けばと思い、この記事を作成することにしました
機械学習やデータサイエンス、統計学未経験者の理解促進のために記載した記事のため、厳密な表現をすると誤った表現があるかもしれません
機械学習(ML)と人工知能(AI)の違い
そもそも機械学習と人工知能の違いってなんなのか。もともとAIはおろかデータサイエンスという分野も未知の筆者からしたら、機械学習も人工知能もchatGPTのようなものがデータを入れたらそれに対する最適解を導きだしてくれるものだと認識していました。
人工知能 (Artificial Intelligence, AI):
定義: 人工知能は、機械が人間の知能や認知能力を模倣する技術やシステムを指します。
目的: 人工知能の目的は、人間のような知的なタスクを実行することです。これには言語理解、問題解決、意思決定、感知などが含まれます。
範囲: AIは広範で、機械学習やその他の手法を含みます。
機械学習 (Machine Learning, ML):
定義: 機械学習は、プログラミングに直接的な手順を記述するのではなく、データから学習し、パターンを抽出して問題を解決する手法です。
目的: 機械学習の目的は、アルゴリズムがデータから学習して、未知のデータに対する予測や意思決定を行うことです。
範囲: 機械学習は人工知能の一分野であり、データ駆動型のアプローチを使用しています。
定義や目的では少し難しいが簡潔に言えば、人工知能は人間の知能を模倣する技術全般を指し、その一部として機械学習が存在しているイメージ。ここで重要なのは、機械学習は、生のデータをプログラムに投入したら、勝手にプログラムが解析して最適化問題や回帰予測を行うといった類のものではなく、過去のデータをプログラムが構成する(?)アルゴリズムが理解できる形に成形・修正して、そのデータの中の傾向を見て、予測対象となる変数(目的変数)を最適な数式的なもの(モデル)で表現し、予測対象が未知のデータセットに対して予測対象以外の変数(説明変数)というところ
統計学と機械学習の違い
それでは、統計学と機械学習はどのようなところに違いがあるのでしょうか?確認していきます。
目的とアプローチ:
機械学習: 主な目的は、データからパターンやルールを抽出して未知のデータに対して予測や意思決定を行うことです。機械学習は、アルゴリズムがデータから学習し、自己修正して性能を向上させることに焦点を当てています。
統計学: 主な目的は、データの背後にある確率分布やパラメータに関する推測を行うことです。統計学は、サンプリングや推定、仮説検定などの手法を用いて、データの背後にある確率的なプロセスを理解しようとします。
データの取り扱い:
機械学習: 機械学習は大量のデータを扱い、そのデータからモデルを学習します。データの特徴を捉え、未知のデータに対する汎化能力を重視します。
統計学: 統計学は比較的小規模なデータセットに対しても適用可能で、データから母集団の性質についての統計的な情報を引き出します。
認識の枠組み:
機械学習: パターン認識や予測モデリングに焦点を当て、アルゴリズムがデータからパターンを抽出し、新しいデータに適用できるように学習します。
統計学: 統計学は、推測統計と記述統計の2つの側面があり、データの背後にある確率的なプロセスを理解し、未知の情報に対する信頼性のある予測を行います。
機械学習は主に予測とパターン認識に焦点を当て、大量のデータからモデルを構築します。一方で、統計学はデータの背後にある確率的なプロセスや母集団に関する情報を引き出すことに焦点を当てています。...つまり、紙一重だけどもそもそも課題解決の方向性において、モデルを構築して、予測を行い、その予測結果を用いて改善効果を出すのか、もしくは、確率的なプロセスや母集団の情報を数値的な観点から導きだし、その情報を元に分析を行うこと...ということか?と理解しています
(もちろん機械学習モデル構築の中で、この"母集団の傾向"や"データのバイアス"を考慮して説明変数の加工を行う必要もあるため、ある意味機械学習モデル構築の中でも統計学は非常に重要となる)
機械学習(ML)の種類
ここまでである程度機械学習とは何かや統計との違いを記載したので、機械学習における問題や手法の種類について簡単に確認を行います.
-
教師あり学習 (Supervised Learning):
- 特徴: ラベル付きのトレーニングデータを使用して、入力データとそれに対応する出力(ラベルやターゲット)の関係をモデル化します。
- 用途: 予測、分類、回帰などが教師あり学習の例です.
-
教師なし学習 (Unsupervised Learning):
- 特徴: ラベルのないデータを使用し、データの構造やパターンを発見します。モデルはデータの隠れた構造を理解します。
- 用途: クラスタリング、異常検知、次元削減などが教師なし学習の例です.
-
強化学習 (Reinforcement Learning):
- 特徴: エージェントが環境と相互作用し、行動に対して報酬やペナルティを受けながら学習します。目標は、累積された報酬を最大化することです。
- 用途: ゲームプレイ、ロボット制御、自動運転などが強化学習の例です.
-
半教師あり学習 (Semi-Supervised Learning):
- 特徴: ラベルのついていないデータとラベルのついたデータを同時に使用します。通常、ラベルのついたデータが少ない場合に利用されます。
- 用途: 大量のデータがありつつ、ラベルが限られている場合に有用です.
-
転移学習 (Transfer Learning):
- 特徴: あるタスクで学習した知識を、異なる関連するタスクに転移する手法です。
- 用途: 一つのタスクで学習した知識を他の関連するタスクに適用する場合に使用されます.
GPTに問い合わせたところ上記回答でしたが、多くの教本などでは、教師あり学習・教師なし学習・強化学習の3種類としているところが多かったです。また、転移学習については、Deep Learningなどでも活用される技術になります。
今回、以降の中では実装の簡単な教師あり学習について取り扱いたいと思います。
教師あり学習の分類
教師あり学習の問題には大きく分けると分類問題と回帰問題が存在します。(厳密にいうと分類にも二値(0/1やTrue/False)の分類や多値(分類1/分類2/分類3...分類n)の分類があります)
-
分類 (Classification):
- 説明: カテゴリやクラスにデータを分類するタスクです。入力データは離散的なクラスに属し、モデルはそれぞれのクラスに対応するラベルを予測します。
- 例: スパムメールの検出
-
回帰 (Regression):
- 説明: 入力データと対応する連続値の出力の関係をモデル化するタスクです。出力は連続的な数値です。
- 例: 住宅価格の予測、売上の予測
今回、機械学習モデルの構築する方法学ぶために比較的簡単に実装が可能でkaggleの練習問題でも扱われる分類問題のアヤメの分類問題をデータセット取得や前処理からモデル構築、予測までを実装してみたいと思います。
準備事項など
具体的な説明の前に簡単に今回の開発環境や使用するデータ、アルゴリズムに関して下記に記載します。
実装環境
今回、初心者でも環境構築が簡単なgoogle colabを使用しbotebook形式で実装を行います。
(導入済の場合は、jupyter notebookやVScodeのnotebook環境などでも問題ありません)
また、本記事では、サンプルデータセットの取得~データ処理~モデル構築に着目して記載するため、pythonに関する細かい記法などについては、本記事には記載しません。ただ、初学者向けというところもあるため、別の記事に記載したいと思います
使用するデータセット
今回は、sklearnのdatasets.load_irisを使用します。
参照:sklearn
説明変数と目的変数
機械学習アルゴリズムへ投入する過去のデータにおいて、予測を行うターゲットとなる変数とその変数に関わりの深い変数が存在します。この変数について、機械学習では、目的変数(ターゲット特徴量)と説明変数(特徴量)と呼ばれます。以下にそれぞれの特徴量の説明を記載します。
説明変数(特徴量)
説明変数は、機械学習モデルのトレーニングに使用される入力変数または特徴量を指します。これらの変数はモデルが学習する際に考慮され、予測に使用されます。通常、データセット内の各行は1つ以上の説明変数を持ち、それに基づいてモデルは目的変数を予測します。
例えば、住宅価格を予測するモデルの場合、説明変数には家の広さ、部屋の数、地理的な位置などが含まれる可能性があります。
目的変数
目的変数は、モデルが予測しようとする出力変数です。モデルの目的は、与えられた説明変数のパターンから目的変数の値を予測することです。機械学習のタスクによっては、目的変数はカテゴリ(クラス分類)または数値(回帰)のどちらかに属することがあります。
例えば、住宅価格を予測するモデルの場合、目的変数は各住宅の価格となります。モデルは、与えられた説明変数から各住宅の価格を予測しようとします。
使用するアルゴリズム
機械学習でメジャーとなっており、割とどんな問題に対してもロバストなモデルを構築できるTree系のアルゴリズムであるlightGBMを使用します
参照:LightGBM 徹底入門 – LightGBMの使い方や仕組み、XGBoostとの違いについて
機械学習モデル構築までの基本フロー
-
データセットの取得
予測を行いたいデータセットの準備を行います。今回は、ライブラリであるsklearnのdatasets.load_irisの中にあるアヤメのデータセットを使用しますが、実際のビジネスシーンなどでは、予測対象となる変数(目的変数)とその関連性の高い変数(説明変数)がついになったデータをcsv形式で準備して、pandasのread_csvなどを使用して読み込む場合が多いです -
データの基礎集計・可視化(探索的データ解析(EDA))
ここでは、そのデータの傾向に偏りがないか、欠損値(データの中身がnullとなっている変数)がないか、データに外れ値が存在しないかなどをdescribe()やinfo()などの関数を使用して基礎集計を行い、さらにmatplotlibやplotlyなどの可視化ライブラリを使用してデータを可視化することでデータセット全体の傾向を把握します。このデータの基礎集計や可視化は、EDA(探索的データ解析)とも言われ、機械学習の初期段階で重要となります。 -
データの加工・修正・補完などの前処理(データクリーニング)
EDAの中で見た傾向や集計データを元に欠損値(null値が含まれる変数)の補完やデータの揺らぎ(特に文字列データで大文字小文字がバラバラの表記や、文字列の入力ミスの修正を指します)などを補完・修正します。これは、学習を行うアルゴリズムがnullとなったデータを扱えないことやデータの揺らぎにより同一データを異なるデータと見てしまう(例:ONEとoneと1は異なるデータとみなされる)ことから、修正・クリーニングが必要となります。 -
特徴量エンジニアリング
データクリーニングと似た項目にはなりますが、データの偏りを正規化、文字列の変数のカテゴリ化(カテゴリ変数ならば...)などを行って、データをアルゴリズム(分類器)の中に投入する準備を行います。
pycaretなどのAutoMLライブラリなどでは、文字列や欠損があっても処理できますが、多くは、欠損や文字列があるとアルゴリズムの中で処理ができなかったり、データに偏りがある場合は、その偏りに引っ張られる形でアルゴリズムの学習結果が正確に導出できないことがおおいため、データクリーニングと特徴量エンジニアリングについては、基本フローとして記載しました
-
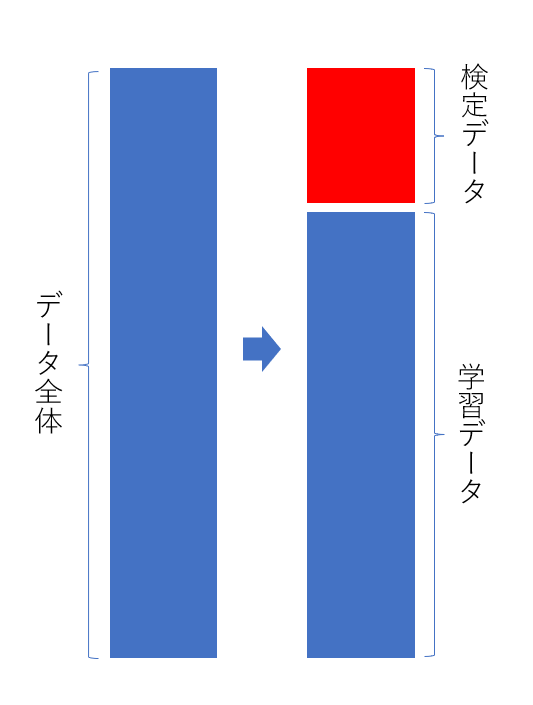
検定スキームの構築
本項目は、人によっては、2番目のフロー上で行うこともあるため、タイミングに関する是非は、実際に自身で前処理~モデル構築までのスキームを構築した際のやりやすさ的な部分で考えてみるといいと思います。検定とは、学習データをいくつかのグループに分け、そのうちの一つをテスト区として、学習したモデルの精度を確認する手法と考えてください。
検定スキームは様々なものがありますが、教師ありの時系列でないMLでは、hold-out法と交差検定(closs validation)については、最低限抑えていると安心なので、後述の中で少し詳しく中身を見ていければと思います。 -
モデリング
機械学習の肝でもあるアルゴリズムに準備したデータセットを投入して、目的変数と説明変数の間にある関係性を数式化するための処理を行います。この部分が機械学習モデルの作成の工程となり、ここで作成した機械学習モデルの精度を評価し、実運用に耐えうるモデルとなったかを確認します。 -
** モデル/特徴量選択**
ここからは、モデル精度向上に向けた手順になります。特徴量修正や異なるアルゴリズムを使用して再度モデル構築を行いながらバリデーション区における精度を確認します。1周目のモデル構築では、すべての説明変数を使用する場合が多く、特徴量の影響度や相関係数などを見て2周目以降で特に関連性の高い説明変数に絞ってモデル構築を行うなどの対応を行います。 -
チューニング
フローの7番目まで繰り返し実行し、目標となる精度や実運用に耐えうるモデルの構築が完了後、さらなる精度向上を目的に、アルゴリズムがデータを学習する際のパラメータをチューニングします。アルゴリズムのパラメータには様々なものが存在しますが、特に今回取り扱うtree系のアルゴリズムでは木の深度やノードを分割するための最小のサンプル数が調整可能なパラメーターとして存在しています。また、これらのパラメーターのことをハイパーパラメーターと呼びます。ハイパーパラメーターチューニングには、手動でパラメータ数値を繰り返し設定しなおす方法の他に、グリッドリサーチやランダムサーチなどの自動化された手法があります。 -
アンサンブル
複数のモデルを組み合わせることで、モデルバリアンスを小さくして各モデルのいずれよりも高精度な予測値を得ることができる手法になります。フローの7番目までの中で複数種類のモデルを構築しながら、その中の上位グループとなるモデルにこのアンサンブルを行うことで、最終の仕上げを行う場合が多いです。
ここまでの流れを図に示すと下記のような形となります

機械学習モデルの構築
いろいろと基本概念的な部分を記載したが、以降は、実際に使用するライブラリのimportから順にコードを実装していきます。
ライブラリのインポート
今回は、sklean、matplotlib、lightGBMに加え、データ加工用・集計用のnampy、pandasをインポートします。(不要なものもありますが、後々使用する可能性のあるライブラリも併せてインポートしておきます)
# ライブラリのインストール
%pip install lightgbm
# ライブラリのインポート
import numpy as np
import pandas as pd
from pandas import Series
# 進捗可視化
from tqdm.notebook import tqdm as tqdm
# グラフ化
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split # ホールドアウト検定
from sklearn.datasets import load_iris # データセット
from sklearn.preprocessing import ( # 正規化用スケーラー
StandardScaler,
MinMaxScaler
)
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import GradientBoostingClassifier
import lightgbm as lgb
import warnings
plt.style.use("ggplot")
pd.set_option("display.max_columns", None)
warnings.simplefilter(action="ignore", category=FutureWarning)
%matplotlib inline
データセットの取得
今回は、sklearnのライブラリ内にあるデータセットを取得します。ついでにデータセットの中身も確認しましょう。
iris_dataset = load_iris()
print("=========type===================")
print(type(iris_dataset))
print("=========feature_names=========")
print(iris_dataset.feature_names)
print("=========data==================")
print(iris_dataset)
実行結果
=========type===================
class 'sklearn.utils._bunch.Bunch'
=========feature_names=========
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
=========data==================
{'data': array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
…
[4.6, 3.1, 1.5, 0.2],
[6. , 3. , 4.8, 1.8],
[6.3, 2.5, 5. , 1.9],
[6.5, 3. , 5.2, 2. ],
[6.2, 3.4, 5.4, 2.3],
[5.9, 3. , 5.1, 1.8]]), 'target': array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
…
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]), 'frame': None, 'target_names': array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
取得したデータセットの型の変更
typeで確認したときにclass 'sklearn.utils._bunch.Bunch'とのことだったため、扱いやすいDataFrameへ変換を行います。この際にカラム名称は、先ほど出力したiris_dataset内に含まれるため、これらを使用する形でDataFrameへ変換します
data1 = pd.DataFrame(data= np.c_[iris_dataset['data'], iris_dataset['target']],
columns= iris_dataset['feature_names'] + ['target'])
display(data1)
実行結果
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | 0.0 |
| 4.9 | 3.0 | 1.4 | 0.2 | 0.0 |
| 4.7 | 3.2 | 1.3 | 0.2 | 0.0 |
| 4.6 | 3.1 | 1.5 | 0.2 | 0.0 |
| 5.0 | 3.6 | 1.4 | 0.2 | 0.0 |
| ... | ... | ... | ... | ... |
| 6.7 | 3.0 | 5.2 | 2.3 | 2.0 |
| 6.3 | 2.5 | 5.0 | 1.9 | 2.0 |
| 6.5 | 3.0 | 5.2 | 2.0 | 2.0 |
| 6.2 | 3.4 | 5.4 | 2.3 | 2.0 |
| 5.9 | 3.0 | 5.1 | 1.8 | 2.0 |
データセットの基礎集計結果の確認
取得したデータセットの基礎統計量の確認と各変数のデータ型を確認します。
この基礎集計の結果、データセットには、欠損がないことがわかります。また、すべてデータ型がfloatであるため、次のフローでそれらの補完やエンコーディングが不要なデータであることがわかりました。
display(data1.info())
display(data1.describe())
実行結果
| # | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 0 | sepal length (cm) | 150 non-null | float64 |
| 1 | sepal width (cm) | 150 non-null | float64 |
| 2 | petal length (cm) | 150 non-null | float64 |
| 3 | petal width (cm) | 150 non-null | float64 |
| 4 | target | 150 non-null | float64 |
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | |
|---|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 | 150.000 |
| mean | 5.843333 | 3.057333 | 3.758000 | 1.199333 | 1.000 |
| std | 0.828066 | 0.435866 | 1.765298 | 0.762238 | 0.819 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 | 0.000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 | 0.000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 | 1.000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 | 2.000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 | 2.000 |
データの可視化-1
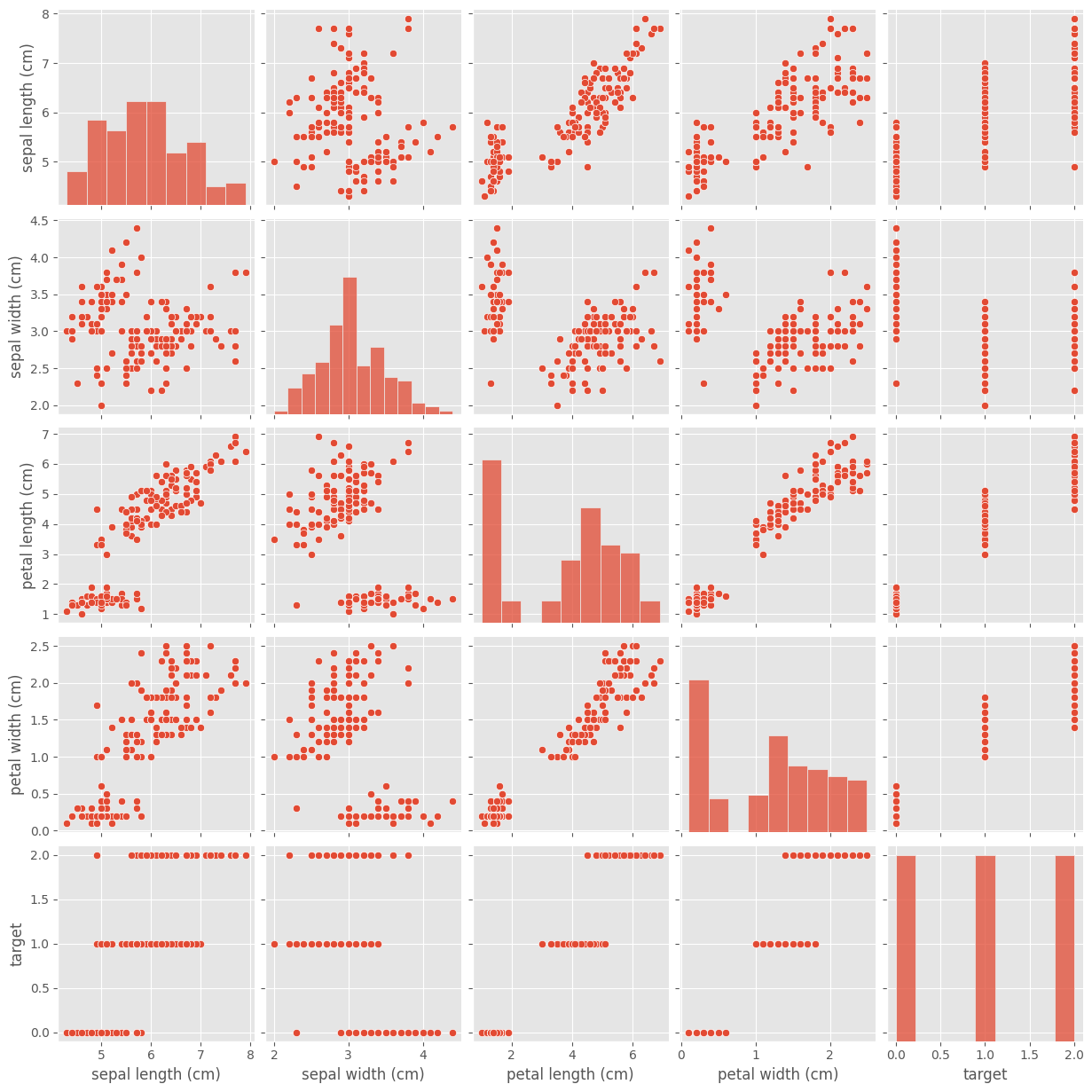
ここでは、各変数のペアプロットを通して、変数の中の偏りや相関関係を可視化します。可視化の結果からtargetの出現率には、カテゴリ間で偏りがないことがわかります。さらに、外れ値らしき値も見受けられないため、今回は、外れ値除去の対応も必要なさそうですね。また、散布図から、各変数同士の相関もボヤっとながら見えてきました。
sns.pairplot(data1.drop())
実行結果
データの可視化-2
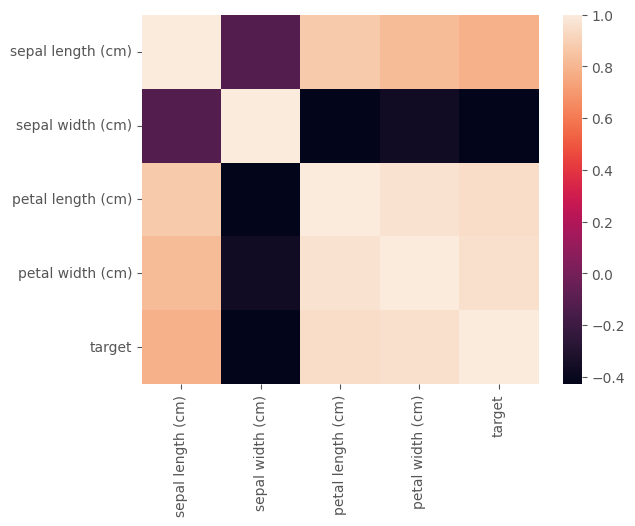
データ可視化-1の中で見えてきた変数間の相関関係を数値化するために、相関係数を算出し、ヒートマップ上に表示します。相関係数が0付近の変数同士は、相関関係がなく、1に近いもの同士は、正の相関が、-1に近いもの同士は負の相関があると考えられます。この中で特に注目すべき部分としては、予測対象となる特徴量(今回は、targetカラム)と相関が高い特徴量がどこになるのかです。1周目でも、目的変数との相関が低い説明変数については、除去してモデリングを行うこともあります。さらに、本来、変数内のデータの分散なども確認しながら、パターンに合わせて標準化・正規化を行いよりロバストに作用するモデル作成を行います。
# 相関係数の計算と可視化
corr = data1.corr()
display(corr)
sns.heatmap(corr)
実行結果
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | |
|---|---|---|---|---|---|
| sepal length (cm) | 1.000000 | -0.117570 | 0.871754 | 0.817941 | 0.782561 |
| sepal width (cm) | -0.117570 | 1.000000 | -0.428440 | -0.366126 | -0.426658 |
| petal length (cm) | 0.871754 | -0.428440 | 1.000000 | 0.962865 | 0.949035 |
| petal width (cm) | 0.817941 | -0.366126 | 0.962865 | 1.000000 | 0.956547 |
| target | 0.782561 | -0.426658 | 0.949035 | 0.956547 | 1.000000 |
データクレンジング
今回、データセットに含まれる情報を可視化した結果、データセットのクレンジングが不要であることが分かったため、ここでは、実施しませんが、通常欠損や外れ値が発生した場合は、補完を行う必要があります。
検定スキームの構築
ここでは、ホールドアウト法による検定を実装しようと思います。ホールドアウト法では、目的変数が明確になっている(正解データがわかっている)データセットの中の一部を学習対象から外し、その区画をテスト対象区として、準備し、テスト区の正解率を見て精度を評価する手法になります。
この場合、テスト区のとった場所によって精度が異なるため、正確な評価となりにくく、交差検定(closs validation)を行うパターンのほうがより正確な評価になりやすい点にご注意ください。
# data1を目的変数と説明変数に分割(目的変数はアヤメの分類なので、int型に変換しています)
X = data1.drop('target', axis=1)
y = data1['target'].astype('int')
# 出力して正しくできているか確認
display(X)
display(y)
実行結果
| # | sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
| ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 |
| # | Target |
|---|---|
| 0 | 0 |
| 1 | 0 |
| 2 | 0 |
| 3 | 0 |
| 4 | 0 |
| ... | ... |
| 145 | 2 |
| 146 | 2 |
| 147 | 2 |
| 148 | 2 |
| 149 | 2 |
特徴量エンジニアリング
今回、データの中身を確認した結果、変数間の最大最小に差がないため、あまり効果を発揮しないかもしれませんが、各説明変数の標準化を行います。今回は、standard scalerを使用します。これを行うことにより、各説明変数のスケールが揃うため、モデルの学習時に各説明変数の特徴がつかみやすくなります。特に各特徴量間で最大・最小値にばらつきがある場合などに使用します。(例:特徴量A 1~100, 特徴量B 10000~20000の場合、特徴量Bの傾向に引きずられやすくなるイメージ)
# スタンダードスケーラーによる正規化
scaler = StandardScaler()
X[X.columns] = scaler.fit_transform(X[X.columns])
display(X)
実行結果
| # | sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) |
|---|---|---|---|---|
| 0 | -0.900681 | 1.019004 | -1.340227 | -1.315444 |
| 1 | -1.143017 | -0.131979 | -1.340227 | -1.315444 |
| 2 | -1.385353 | 0.328414 | -1.397064 | -1.315444 |
| 3 | -1.506521 | 0.098217 | -1.283389 | -1.315444 |
| 4 | -1.021849 | 1.249201 | -1.340227 | -1.315444 |
| ... | ... | ... | ... | ... |
| 145 | 1.038005 | -0.131979 | 0.819596 | 1.448832 |
| 146 | 0.553333 | -1.282963 | 0.705921 | 0.922303 |
| 147 | 0.795669 | -0.131979 | 0.819596 | 1.053935 |
| 148 | 0.432165 | 0.788808 | 0.933271 | 1.448832 |
| 149 | 0.068662 | -0.131979 | 0.762758 | 0.790671 |
スケーリング結果の確認
実際に標準化前後のデータをヒストグラムで可視化して、データの標準化が正しく行われたのかを確認します。
# スケーリング前後の違いを確認
for col in X.columns:
plt.figure(figsize=[7,7])
X[col].hist(density=True, alpha=0.5, bins=50)
data1[col].hist(density=True, alpha=0.5, bins=50)
plt.xlabel(col)
plt.ylabel('density')
plt.show()
実行結果
(sepal lenght(cm)の結果のみ表示します)
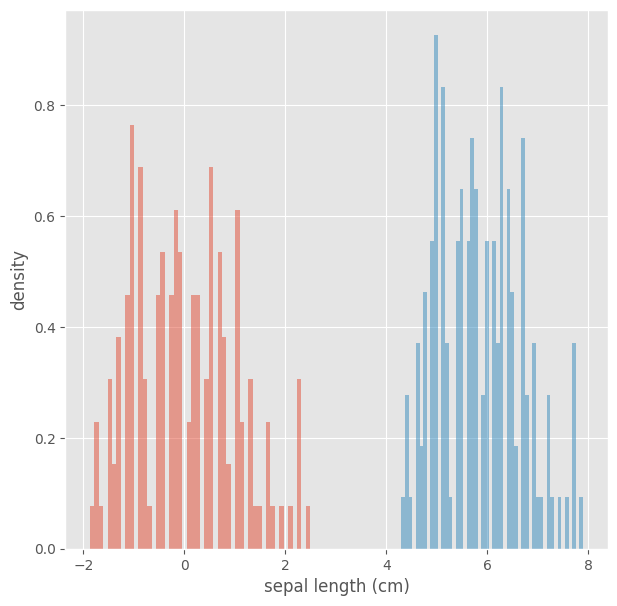
検定スキームの構築
今回は、hold_out法を用い検定を行います。hold_out法では、データ全体を指定した割合で検定データと学習データに分け、学習データでモデルの学習を行い、検定データで学習済モデルの精度検証を行います。
# trainデータとvalidationデータに分割する。分割割合はvalidationを2割、ランダムシード42で固定
train_X, valid_X, train_y, valid_y = train_test_split(X, y, test_size=0.2, random_state=42)
# ちゃんと分割できているか確認
display(train_X)
display(valid_X)
実行結果
◆train_Xデータ
| # | sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) |
|---|---|---|---|---|
| 22 | -1.506521 | 1.249201 | -1.567576 | -1.315444 |
| 15 | -0.173674 | 3.090775 | -1.283389 | -1.052180 |
| 65 | 1.038005 | 0.098217 | 0.364896 | 0.264142 |
| 11 | -1.264185 | 0.788808 | -1.226552 | -1.315444 |
| 42 | -1.748856 | 0.328414 | -1.397064 | -1.315444 |
| ... | ... | ... | ... | ... |
| 71 | 0.310998 | -0.592373 | 0.137547 | 0.132510 |
| 106 | -1.143017 | -1.282963 | 0.421734 | 0.659038 |
| 14 | -0.052506 | 2.169988 | -1.453901 | -1.315444 |
| 92 | -0.052506 | -1.052767 | 0.137547 | 0.000878 |
| 102 | 1.522676 | -0.131979 | 1.217458 | 1.185567 |
◆valid_Xデータ
| # | sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) |
|---|---|---|---|---|
| 73 | 0.310998 | -0.592373 | 0.535409 | 0.000878 |
| 18 | -0.173674 | 1.709595 | -1.169714 | -1.183812 |
| 118 | 2.249683 | -1.052767 | 1.785832 | 1.448832 |
| 78 | 0.189830 | -0.362176 | 0.421734 | 0.395774 |
| 76 | 1.159173 | -0.592373 | 0.592246 | 0.264142 |
| 31 | -0.537178 | 0.788808 | -1.283389 | -1.052180 |
| 64 | -0.294842 | -0.362176 | -0.089803 | 0.132510 |
| 141 | 1.280340 | 0.098217 | 0.762758 | 1.448832 |
| 68 | 0.432165 | -1.973554 | 0.421734 | 0.395774 |
| 82 | -0.052506 | -0.822570 | 0.080709 | 0.000878 |
| 110 | 0.795669 | 0.328414 | 0.762758 | 1.053935 |
| 12 | -1.264185 | -0.131979 | -1.340227 | -1.447076 |
| 36 | -0.416010 | 1.019004 | -1.397064 | -1.315444 |
| 9 | -1.143017 | 0.098217 | -1.283389 | -1.447076 |
| 19 | -0.900681 | 1.709595 | -1.283389 | -1.183812 |
| 56 | 0.553333 | 0.558611 | 0.535409 | 0.527406 |
| 104 | 0.795669 | -0.131979 | 1.160620 | 1.317199 |
| 69 | -0.294842 | -1.282963 | 0.080709 | -0.130755 |
| 55 | -0.173674 | -0.592373 | 0.421734 | 0.132510 |
| 132 | 0.674501 | -0.592373 | 1.046945 | 1.317199 |
| 29 | -1.385353 | 0.328414 | -1.226552 | -1.315444 |
| 127 | 0.310998 | -0.131979 | 0.649083 | 0.790671 |
| 26 | -1.021849 | 0.788808 | -1.226552 | -1.052180 |
| 128 | 0.674501 | -0.592373 | 1.046945 | 1.185567 |
| 131 | 2.492019 | 1.709595 | 1.501645 | 1.053935 |
| 145 | 1.038005 | -0.131979 | 0.819596 | 1.448832 |
| 108 | 1.038005 | -1.282963 | 1.160620 | 0.790671 |
| 143 | 1.159173 | 0.328414 | 1.217458 | 1.448832 |
| 45 | -1.264185 | -0.131979 | -1.340227 | -1.183812 |
| 30 | -1.264185 | 0.098217 | -1.226552 | -1.315444 |
モデリング
いよいよモデリングを行います。モデリングを行うには、モデルに投入するデータセットの作成(lightGBMでは、dataset関数があるため、これを使用)・パラメータ数値設定・モデル学習と検定を行います。今回、他クラス分類で最適化メトリクスはmulti-loglossを使用、early_stoppingは10で設定しました。学習時にこの最適化メトリクスを算出し、この指標が最小化される形でモデルが構築されます。また、学習の繰り返し回数をnum_boost_round=10000で設定しましたが、学習結果を見て設定したearly_stoppingの回数だけメトリクスの数値に変化がなくなると学習が終了します。
# 学習データと検定データをDataset関数を使用して、アルゴリズムに投入できる形に変換
train_data = lgb.Dataset(train_X, label=train_y)
valid_data = lgb.Dataset(valid_X, label=valid_y)
# LightGBMのハイパーパラメータの設定
params = {
'objective': 'multiclass', # 多クラス分類
'num_class': 3, # クラスの数
'metric': 'multi_logloss' # 損失関数にmulti_loglossを使用
}
# LightGBMモデルの学習
gbm = lgb.train(params, train_data,
valid_sets=[valid_data], # early_stoppingの評価用データ
num_boost_round=10000, # イテレーションの回数。early_stopping使用時は大きな値を入力
callbacks=[lgb.early_stopping(stopping_rounds=10,
verbose=True), # early_stopping用コールバック関数
lgb.log_evaluation(1)] # コマンドライン出力用コールバック関数
)
実行結果
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000041 seconds.
You can set force_col_wise=true to remove the overhead.
[LightGBM] [Info] Total Bins 92
[LightGBM] [Info] Number of data points in the train set: 120, number of used features: 4
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines
[LightGBM] [Info] Start training from score -1.098612
[LightGBM] [Info] Start training from score -1.073920
[LightGBM] [Info] Start training from score -1.123930
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf
[1] valid_0's multi_logloss: 0.930658
Training until validation scores don't improve for 10 rounds
…
作成したモデルの精度確認
先ほどの中でmulti_loglossでの最終評価である程度は精度が見えるもののまだイメージがつきにくい可能性があるため、実際に検定データを使用し、予測を行い、検定データのtargetカラムと比較を行う形で、予測結果を確認します。
from sklearn.metrics import accuracy_score
# validデータを使用し、モデル精度を分かりやすく評価
y_pred = gbm.predict(valid_X)
y_pred_class = np.argmax(y_pred, axis=1) # 予測結果のクラスの値を調整 --> 出力結果が各クラスになる確率のため、クラスへ変換
# validデータのターゲットと予測値の比較
accuracy = accuracy_score(valid_y, y_pred_class)
print('Accuracy:', accuracy)
実行結果
Accuracy: 1.0
検定データでは100%正解だったことがわかりました。今回は検定データのtargetカラムを予測しましたが、実際にtargetカラムが未知のデータについても同様の形で予測を行うことができます。
特徴量インパクトの確認
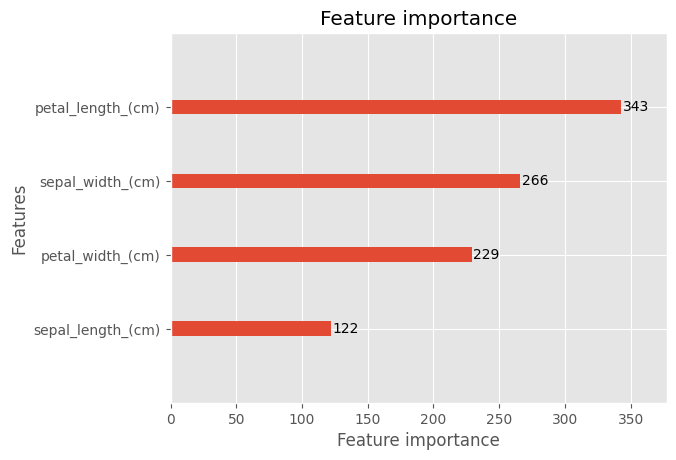
最後に特徴量インパクトの出力を行い説明変数が予測の結果にどのくらい影響したのかを可視化します。機械学習プロジェクトでは説明変数が100個、200個となる場合もあり(目的変数と関連性の高い説明変数がわからないため、手元にあるデータすべてを使用するケースが多い)、この特徴量インパクトを見ながら2周目以降の特徴量選択・モデル選択の参考にします。今回は特徴量が少ないことと、1周目で正答率100%となったため、出力まで行って終了とします。
plt.figure(figsize=(10,6))
lgb.plot_importance(gbm)
plt.show()
実行結果
最後に
機械学習の勉強をしていると難しい数式だったりわからないワード・センテンス、概念などが多く、敷居が高いイメージがどうしてもついてしまいますが、このように少しずつコードを実行しながら、プログラムの動きを見ていくと、それほど難しいことはしていないため、まずは手を動かして、そこから深堀する形でもいいかもしれないと感じています。
筆者の理解が拙い部分もあるため、誤った表現などが散見されるかもしれませんが、その場合はぜひ教えていただけますと幸いです。