こんにちは。
Web・iOSエンジニアの三浦です。
突然ですが皆さんは、何もしていないのにEC2が動かなくなった経験はありませんか?
今回は実際に私が体験したそんな話と、その原因について紹介します。
はじめに
オンプレからAWSへの移行というのは、金銭的なコストやマネージングコストの削減、可用性の向上など、様々なメリットをもたらしてくれます。
そのため近年では、色々なところで移行が行われているのを耳にする方も多いのではないでしょうか。
ただ、上記のメリットがある一方で、勝手知ったるオンプレサーバからEC2に移行したとき、その仕様の違いによって様々な不幸がもたらされてしまうのも事実。
今回はそのうちの一つ、「何もしていないのに突然EC2が動かなくなった!」について、実際に私の身に起きた実体験を話していきたいと思います。
1. AWS移行の完了と恐怖の始まり
私が担当していたサービスは、長いことオンプレサーバでWebサービスを提供し続けてきた長寿なサービスでした。
ただ、オンプレサーバでの管理にも限界がやってきて、2019年にAWSへの移行が決定。
2019年の後半からAWSへの移行が開始され、2020年3月、いよいよ切り替えが実行されました。
結果、大きな障害が起きることもなく、Webサーバやバッチサーバ、DB等も含めすべてのオンプレサーバをAWSに移行することができました。
念の為しばらくオンプレサーバも残すことにしつつ、しかしもう使うことも無いだろうと高をくくっていました。
その3日後、突然Webサーバが動かなくなるまでは。
2. 難航する調査
それは突然起こりました。
新しくコードをデプロイしたわけでも、アクセスが急増したわけでもなく、本当に突然EC2が機能しなくなったのです。
それも、複数台に分散処理させていたWebサーバのうち一部のサーバのみが機能しなくなった形でした。
正確には、CPU使用率が急激に落ちた、というものでした。
幸いRoute53を使って取り急ぎサービスをオンプレサーバに戻したので、長期的なサービス障害を避けることはできました。
その後原因を調査し始めたのですが、皆さんならまず何を疑うでしょうか?
パッと思いつくものとしては、
- EC2にt系を用いていた場合は、バースト機能のCPUクレジットが枯渇してCPU使用率が制限された
- ストレージが枯渇した
- AWSで障害が起きた
- オンプレと仕様が変わったため、ネットワーク周りで何かしらが詰まった
- Webサービスのアプリケーションで重い処理に当たってしまい、プロセスが増えすぎて詰まった
- 使用したEC2サーバが偶然にも不具合のあるサーバだった
このあたりではないでしょうか。
少なくとも、当時まだまだインフラ周りの知識の少ない私では、このあたりを思いつくのが精一杯でした。
ただ、調査した結果、「1. CPUクレジット枯渇」「2. ストレージ枯渇」「3. AWS障害」が起きていないことは確認でき、「4. ネットワーク周りでなにか詰まった」形跡も発見できませんでした。
そこで、「5. プロセスが増えすぎた」「6. 偶然不具合のあるEC2に当たってしまった」可能性を考え、以下の対策を行いました。
- アクセスログについて、各アクセスに掛かった処理時間も出力するようにする
- Webサーバ用のEC2を総入れ替えする
そして対策終了後、祈りながらサーバをEC2に再度切り替えました。
3日後、祈り虚しく再びオンプレサーバに出番が出てくるまで、EC2サーバは正常に動いていました…。
アクセスログを見ても長すぎる処理は確認できず(というより、機能しなくなった時間帯のアクセスログは出力されていませんでした)、Webサーバも入れ替えているはずなのに結局障害が起きる始末。
この、「障害発生 -> 原因調査 -> 対策 -> 再度切り替え -> 障害発生」のループは、その後何度か繰り返されつつ、原因が判明することは一向にありませんでした。
3. 持たさられるヒント
このループが何度も繰り返されていたある時のこと、調査時に気になる点を見つけました。
それは、「ファイルIOが詰まっているように見える」こと。
確かにそのサービスは、ログやキャッシュなどでかなりファイルIOしているサービスだったのは確かでしたが、とはいえストレージには十分余裕がありました。
一縷の望みを掛けてなんとか不要なログ出力を減らしたりはしたものの、結局は障害は起き続けるばかり。
心の端には留めていたものの、しかしまさかこれが原因だとは思わず、他の調査に当たっていました。
しかし、これこそがまさしく障害の原因だったのです。
4. 原因の判明と解決
皆さんは、「バースト・クレジット枯渇」と言ったら何を思い浮かべますか?
多くの人はt系のEC2のCPU使用率を思い浮かべると思います。
私もその一人だったわけですが、実はそれ以外にも、バースト・クレジットの形式を持っているサービスがあったのです。
EBSです。
EBSといえばEC2等に使用するストレージなわけですが、そんなEBSの何にバーストがあり、何にクレジットがあるかというと、実はファイルのIO回数にバーストが設定されているのです!
EBS一覧のモニタリングでも確認できます。
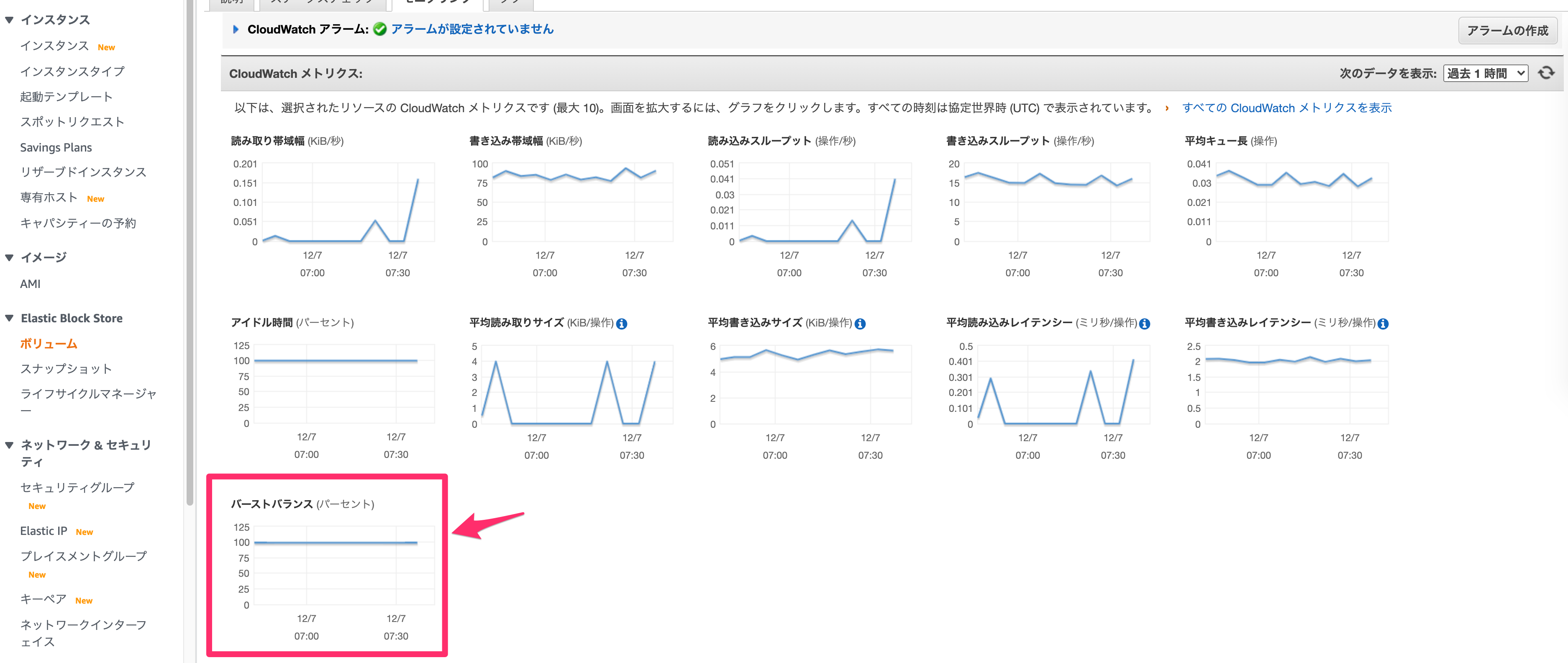
バースト・クレジットはEBSのストレージタイプによって有無が分かれますが、今回使っていたgp2ボリュームはバースト・クレジットが存在しており、そしてこれが尽きたことによってファイルへのIOが急激に遅くなったことが、今回の障害の原因だったのです。
3日とはクレジットが枯渇するまでの時間であり、それによって切り替え後すぐではなく時間差で障害が起きていたのでした。
すべてのサーバが一度に機能を停止しなかったのは、サーバごとに微妙にファイルIO数にばらつきがあったためであり、またエラーログの削減だけで障害が止まらなかったことについては、行った対策だけでは十分ファイルIOを減らせなかったものだと思われます。
ある日の調査で偶然にもこれに思い当たり、まさしく上図のメトリクスでクレジットが尽きていたことを確認した私は、大急ぎで対策を行いました。
EBSのファイルIOのバーストのベースライン(クレジットが減らない最大IO数)は、gp2ボリュームの場合EBSのストレージサイズが大きくなることに比例して高くなっていきます。
当初はオンプレの時に使われていたストレージサイズをもとに必要なストレージサイズを計算していましたが、クレジットが枯渇しないことを念頭に必要なストレージサイズを再計算して適用し、結果ようやくEC2の障害が止まることになったのでした。
さいごに
EC2は、AWSのサービスの中でも特に使われることの多いサービスの1つだと思います。
そこに付属する形でEBSもかなり使われることとなるかと思いますが、どこか「EC2の付属サービス」という認識があり、そこに何かしらの障害の原因があったときに原因の究明に時間がかかることもあるのではないでしょうか。
オンプレからAWSへの移行時なども、基本的にはオンプレのときに使われていたストレージサイズをもとにEBSのストレージサイズを決めることも多いかと思います。
この記事で、原因究明の時間が少しでも減少すれば、または障害の予防になれば幸いです。