はじめに🗻
今年の5月よりCAMPFIREでSREチームに所属しています@takayam26です。
ありきたりの出だしではありますが、今年も早いものであっという間にアドベントカレンダーの季節になってしましました。
急に寒くなり上着を取り出したり、新型コロナも落ち着かない通常とは違う年末ではありますが、今年の振り返りもこめて本日のアドベントカレンダー行かせて頂きます✋
今年はどんな年だったか🤔
皆様、思うところは同じだと思いますし、言い尽くされた言葉ではありますが、今年は新型コロナの影響により、本当に社会のあり方が激変した1年だったかと思います。
僕自身、前職の転勤期間終了に伴い、3月に大阪から東京に戻り、その後、退職をしました。この時は、まだ新型コロナがこのような状況になるとは思ってもいなかったのですが、4月には、転職活動にコロナの影響があれよあれよと出始め、採用面談は全てリモートとなりました。
自分自身、リモート面談での転職活動は初めての経験でしたし、自分の思いがきちんと伝わっているのかなど、不安でな要素はありましたが、5月よりCAMPFIREのSREチームの一員として働けることとなり、今に至ります。
CAMPFIREでは、現在もほぼ社員全員がリモートワークとなっています。リモートワークが長期化する中、SREチームでも採用活動を行い、10月から、@sakaki-cf、@TAKA_0411がJOINしてくれる事となりましたしたが、SREチームのリモートワークについては、僕自身がJOIN当初に苦労した部分など改善しつつ、新しいメンバーに精神的な負担を出来るだけ少なくなるような取り組みを行なっています。
この辺りについては同じSREチームの@TAKA_0411がアドベントカレンダーに書いてくれていますので、興味のある方は、ぜひご一読頂けると雰囲気が分かって頂けるかなと思います。
きっかけ🧐
さて、前置きが長くなりましたが、ここから本題に入ります💦
冒頭にも書いたようにリモートワークを採用する企業が増えるに伴い、大きく変化を余儀なくされた物の1つに「エンジニアの勉強会」があるかと思います。
もちろん、これは勉強会だけでなく、AppleやGoogle、Amazon、GitHubなど、毎年オフラインで行われていた新製品/サービスの発表会イベントは、全てオンライン形式で行われることになりました。
このイベントのオンライン化については、個人的にはデメリットよりメリットの大きさしかないと思っています。
僕が感じているメリットとしては、下記の3つです。
- 地理的な垣根を全て飛び越えて共有できる(特に地方に居住している方には大きなメリットだと思います)
- 会場の収容人数に左右されることがない
- YouTubeなどでイベント内容をアーカイブ化しやすい
*正直、なんで今までオフラインに拘ってきた部分があるのか、と思っていたりもしますが。。。
さて、そんな中、動画でアーカイブされた勉強会の様子が、たくさんYouTubeにアップされていますが、さすがに全部見るというのは時間がなかなか許してくれない部分もあります。
公開されているスライド資料で補完する事ができる場合もありますが、口頭で補足されているのだろうなという部分が知りたい場合にはどうしても動画を見た方が良かったりもします。
そこで、動画を文字起こしして、大体の内容を把握した上で、もっと深堀して知りたい勉強会のセッションについては動画をしっかり見る、というアプローチができれば良いのでは思い、それを実行してみることにしました。
文字起こしのためのツール🪒
今回は下記のツールを使って、YouTubeに上がっているものを文字起こしまで行います。
- 音声抽出:youtube-dl
- 文字起こし:Amazon Transcribe
なお、検証にはmacOS Big Surを用いています。
youtube-dlで音声ファイルを抽出する🎙
youtube-dlのインストールはHomeBrewがあれば簡単ですが、ffmpegのインストールも必要となりますので、そちらも合わせてインストールしておきます。
$ brew install ffmpeg
$ brew install youtube-dl
YouTubeのURLが必要なので、文字起こししたい対象の動画のURLは取得しておきましょう。必要なURL形式はhttps://www.youtube.com/watch?v=xxxxxxxxxです。
下記のコマンドで音声のみをMP3形式で抽出します。実行するディレクトリはホームディレクトリ以下であれば、どこでも構いません。
$ youtube-dl "https://www.youtube.com/watch?v=xxxxxxxxx" --extract-audio --audio-format mp3
[youtube] xxxxxxxxx: Downloading webpage
[youtube] xxxxxxxxx: Downloading MPD manifest
[dashsegments] Total fragments: 105
[download] Destination: タイトル-xxxxxxxxx.m4a
[download] 100% of 15.91MiB in 01:07
[ffmpeg] Correcting container in "タイトル-xxxxxxxxx.m4a"
[ffmpeg] Destination: タイトル-xxxxxxxxx.mp3
Deleting original file タイトル-xxxxxxxxx.m4a (pass -k to keep)
こんな感じで出来上がりますので、念の為出来上がったファイルはQuickTime Playerなどで音声が再生されるか確認をしておいてください。
音声から文字起こしを行う📝
さて、先ほど抽出した音声ファイル(mp3)を元に、Amazon Transcribeを用いて文字起こしをやってみましょう。
Transcribeにインプットファイルとして音声ファイルを渡す際、S3バケットに置いておく必要があります。まずはS3バケットを作成し、そこに音声ファイルを置きましょう。
-
適当なS3バケットを作成し、そのバケットに音声ファイルを置きます。(ここの手順は割愛します)
-
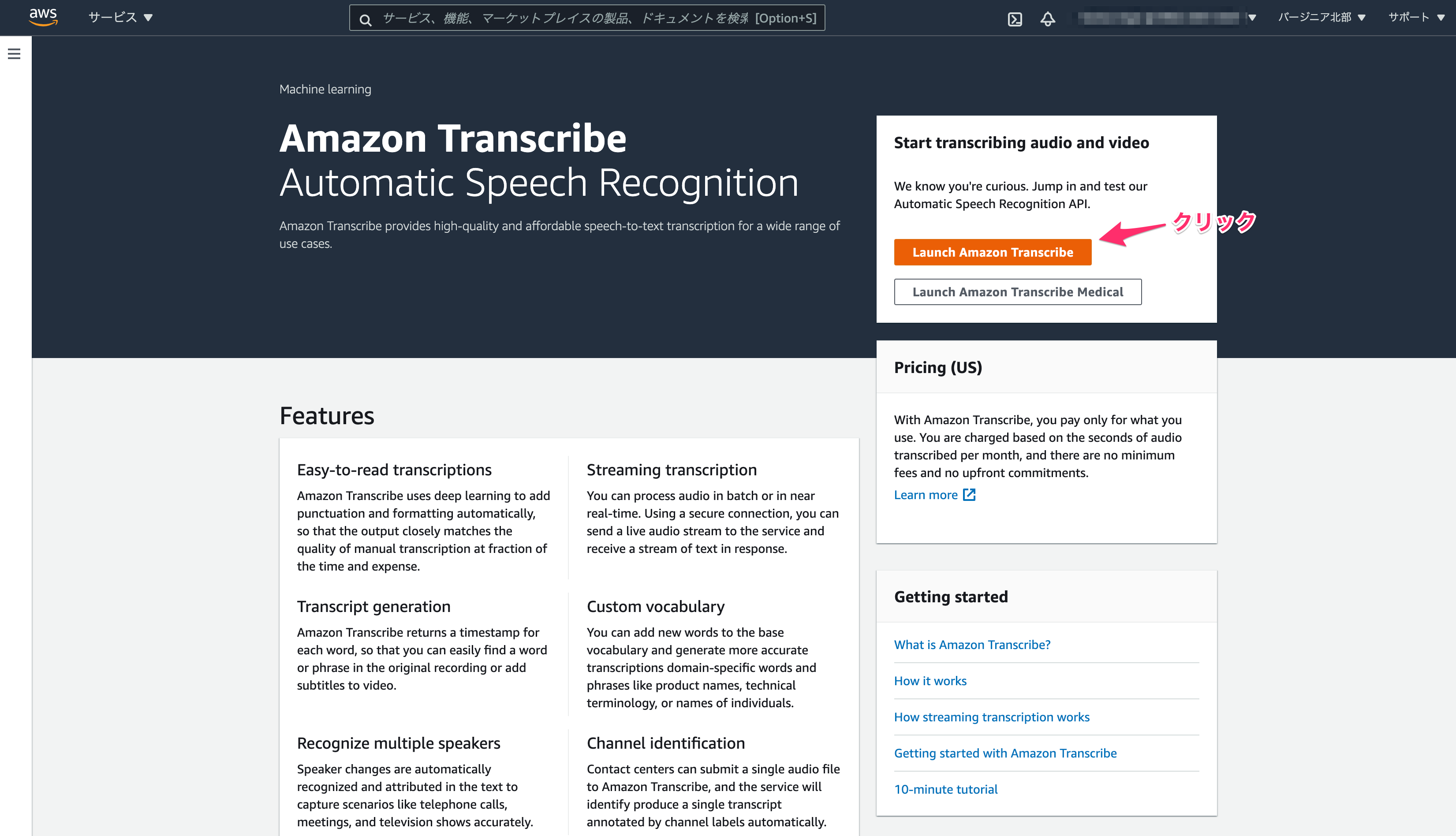
Amazon Transcribeのコンソール画面を開き、右側にある「Launch Amazon Transcribe」をクリックします。
-
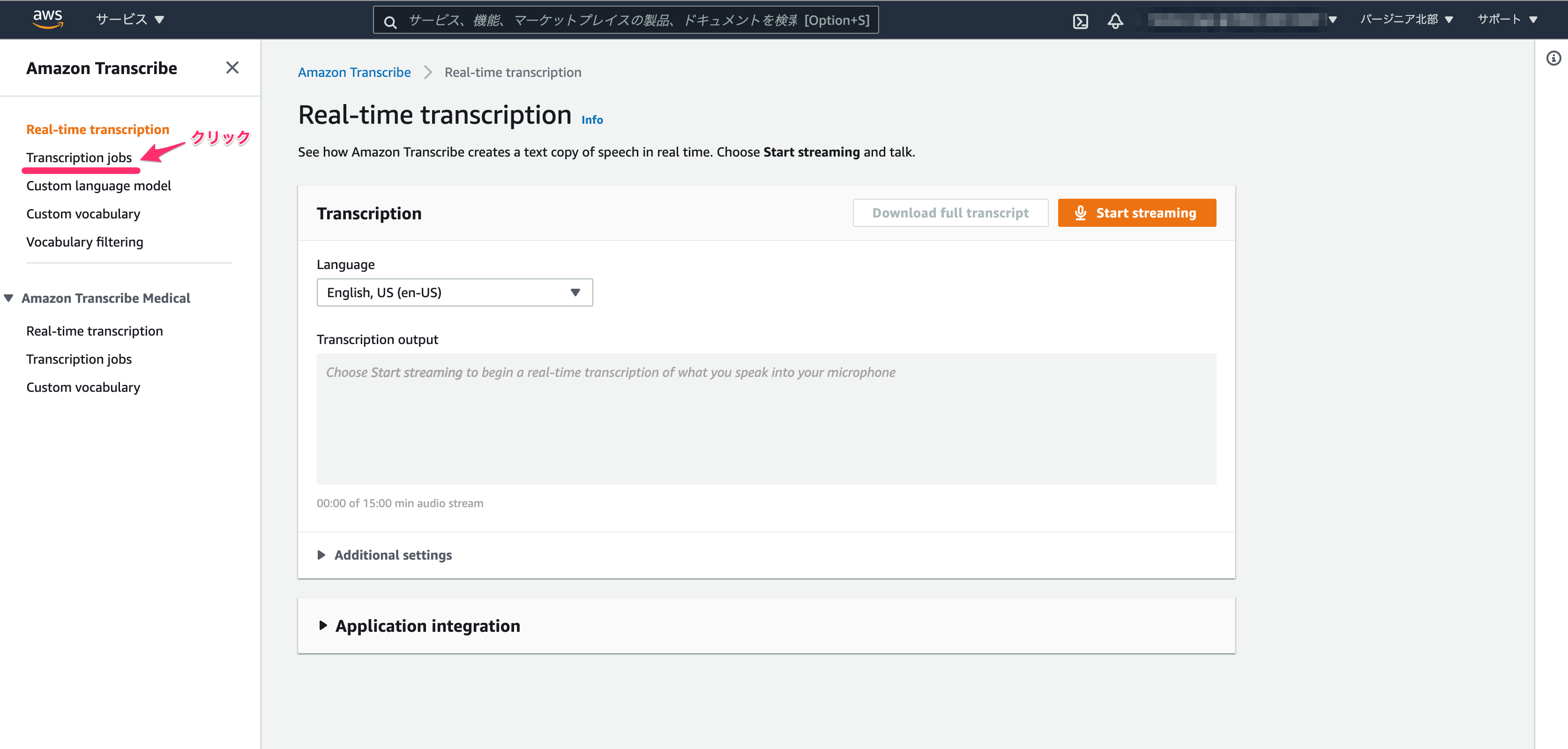
「Real-time transcription」の画面が開くと思うので、左側メニューにある「Transcription jobs」をクリックして移動します。
-
「Transcription jobs」に移動したら「Create job」をクリックしましょう。

-
設定画面は2つです。まずは基本的なjobの設定を入れていき、次の画面へいきましょう。
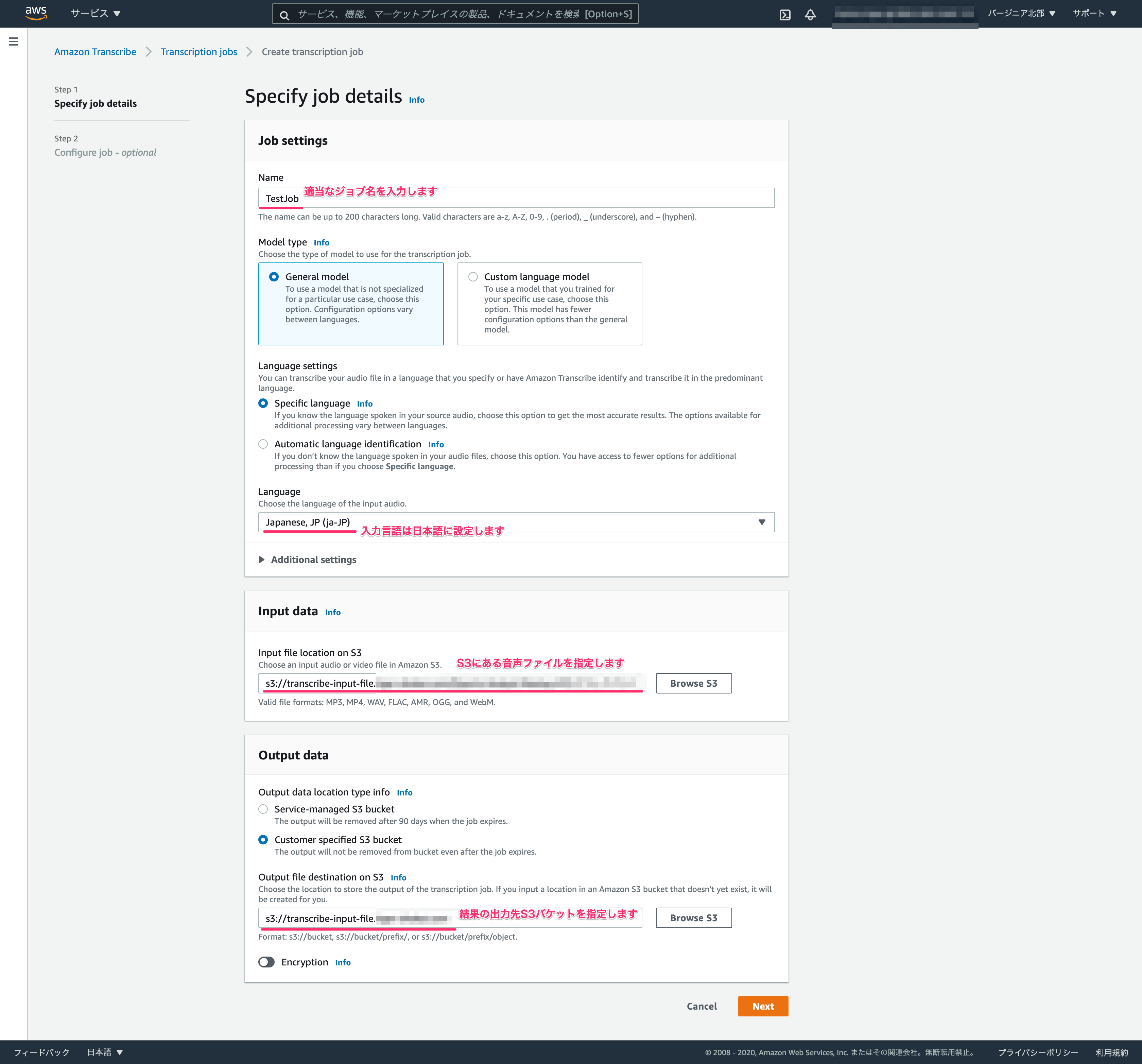
-
2番目の画面はjobのオプション項目ですので、今回は特に変更しません。最後に「Create」を押しましょう。
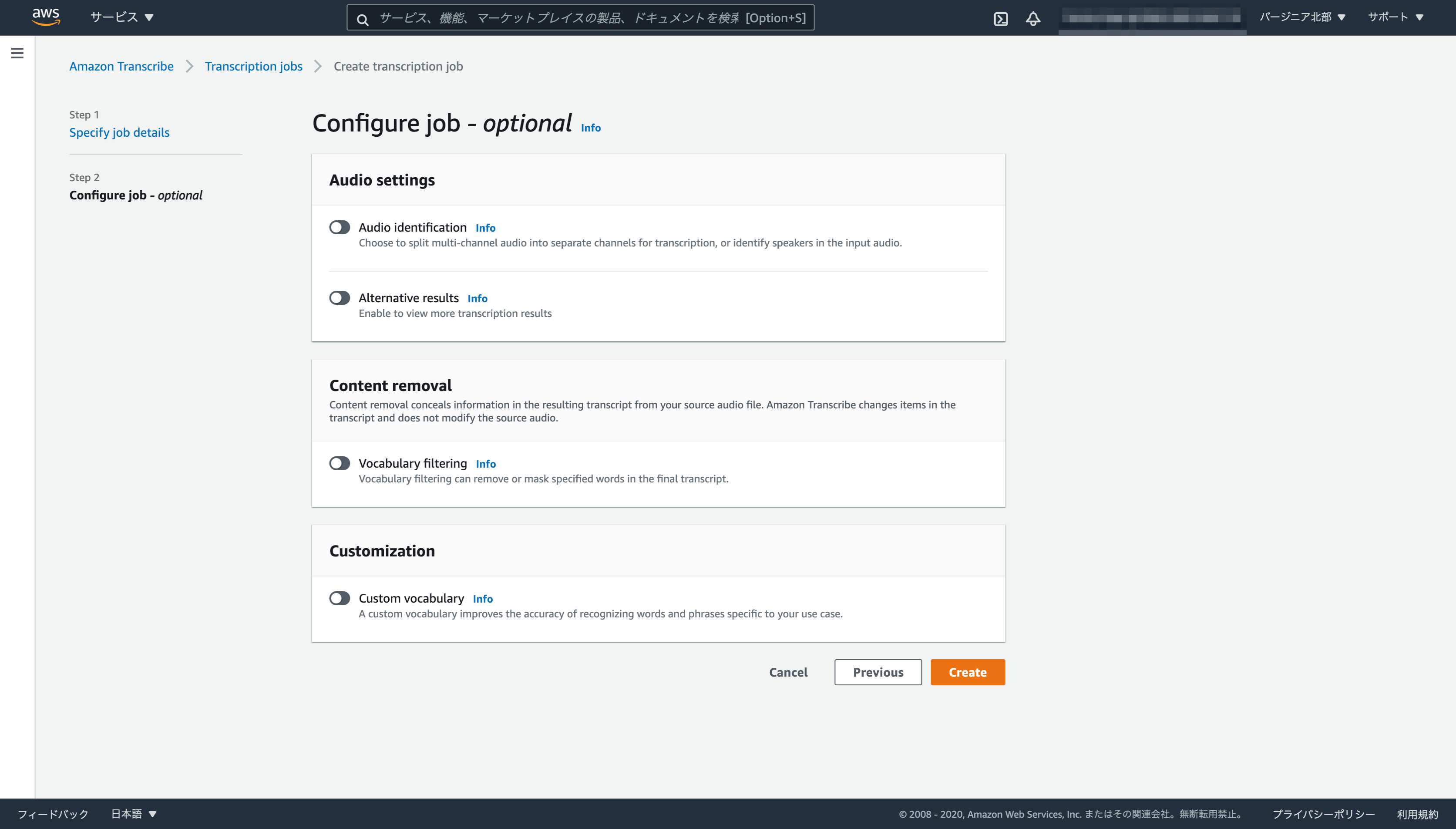
-
すると自動的にJobが実行されます。Statusが「In progress」になったら少し待ちましょう
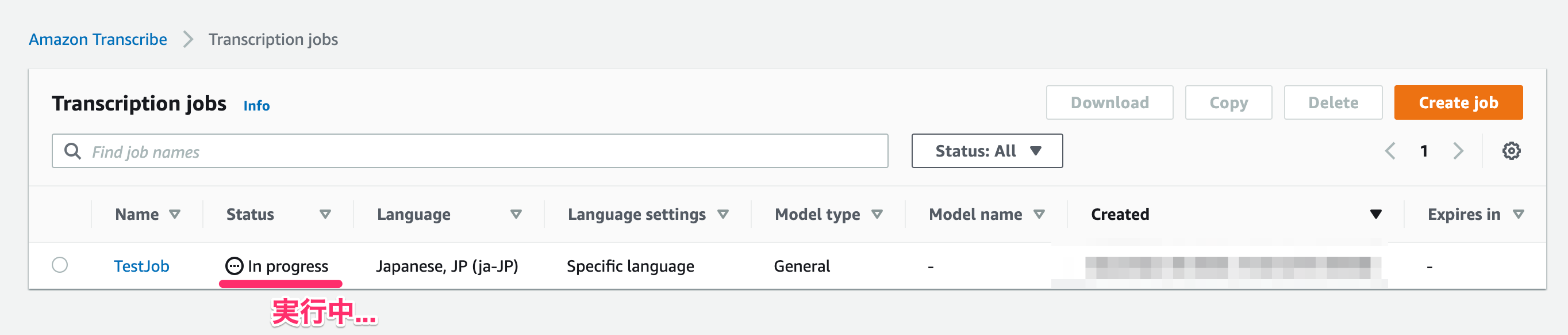
-
完了したらStatusが「Complete」になります。
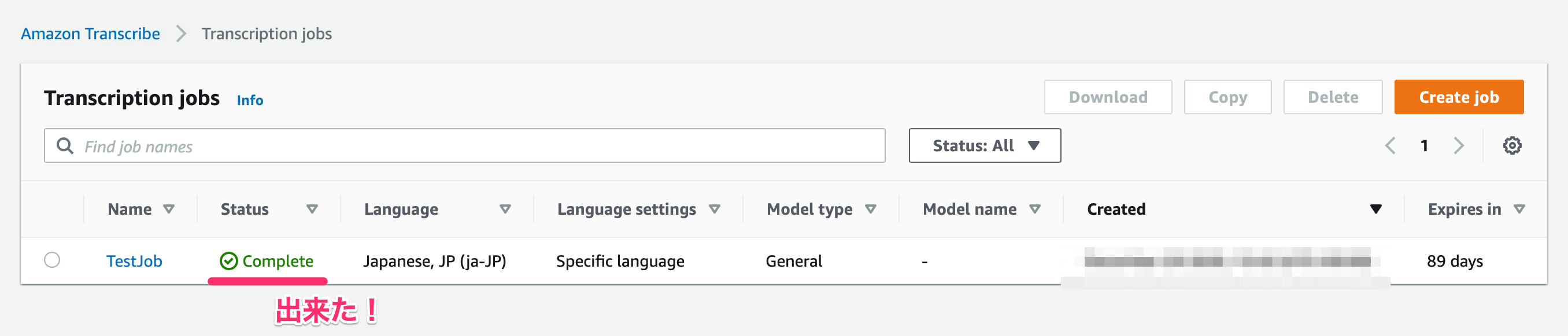
結果発表
さて、出来上がった結果を確認してみましょう。先ほど結果出力先に指定したバケットにjsonファイルが出来上がっているはずです。

Jsonファイルをダウンロードして、中身を確認してみましょう。jqコマンドで抜き出します。
$ cat TestJob.json| jq -r '.results.transcripts[0].transcript'
それでは よろしく お願い いたし ます よろしく お願い し ます え どうして
(以下、省略)
出だしだけのご紹介になってしまいますが、うまく取れているようです!!!
課題
とはいえ、色々と課題もあります。
- 気になる動画について手動で音声ファイルを抽出するのは手間がかかりすぎる。
- どうしても話言葉の中に入る「…という こと で ま つまり ま 誰 も 誰 にとって も…」のような繋ぎ言葉が入ってしまう。
- なので、スペース区切りを一括で消すと、文章が分かりにくくなってしまう。
音声ファイルの抽出などは自動化出来そうな部分ではありますし、話し言葉特有の部分は最適化できるようにできればいいなと思っていますので、また機会がありましたら書いていきたいと思います。
ここまで読んで頂いた方、ありがとうございました!!!