
画像引用元:[1]
はじめに
今回は以下の論文をかなりざっくり紹介します.巷では「Deep BLEACH」なんて呼ばれ話題になりました.
Su, Hao, Jianwei Niu, Xuefeng Liu, Qingfeng Li, Jiahe Cui, and Ji Wan.
"Unpaired Photo-to-manga Translation Based on The Methodology of Manga Drawing."
arXiv preprint arXiv:2004.10634 (2020).
arxiv: https://arxiv.org/abs/2004.10634
こちらの記事でいち早くわかりやすい解説がされていたので,ここではもう少しだけ踏み込んだ解説ができたらと思います.が,予想以上にモデルや損失関数に細かい工夫がされており,本当はすべて紹介したいのですが,時間の都合で割愛させていただきます🙇🏻♂️
概要
- 敵対的生成ネットワーク(Generative Adversarial Network, GAN)をもとに,
写真を漫画風に変換するMangaGANを提案 - 人気漫画から新しいデータセットを構築
- なめらかな線,ノイズ除去,もとの写真の情報保存を実現するための損失関数を提案
GANによる画像のスタイル変換
画像のスタイル変換とは,今回のMangaGANのように写真を漫画風にしたり,線画画像を写真にしたり,昼間の風景を夜景にしたり(図1)といったように,「入力画像の構図を大きく変えずに,全体の画風や色味を変換する」タスクです.
 図1 pix2pix[2]によるスタイル変換
図1 pix2pix[2]によるスタイル変換
上述のような「データセットにありそうでない画像」を生成するGANは入力にノイズを与えるのに対し,画像のスタイル変換では入力に画像を与えます.出力となる画像を生成する過程でGANのGeneratorとDiscriminatorの仕組みを用いることで,より高精度の変換を実現しています.
目的
この解説の1番上に貼った画像だけ見ると,「この技術何に使うの?」と思う方もいるかも知れませんが,至極まっとうな背景があります.漫画を書くというのはとても時間のかかる作業であり,作業を分担しようにもプロの画風,例えば久保帯人先生の画風を真似るというのは簡単にできることではありません.そういった時間のかかる,プロにしかできない作業をAIで支援するというのがこの研究の目的です.
写真→漫画の変換を目指す上で,以下の4つの問題があります.
- 漫画における人の顔は抽象的で,白黒で,誇張されているという点で写真と大きく異なる
- 顔の輪郭,各パーツの位置やサイズは作者によって大きく異なる
- 入力となる人物と,漫画の画風の両方に似せなければならない
- 漫画のデータセットを集めるのが大変
既存のスタイル変換技術は,この4点が理由で写真→漫画において十分な結果を得られていません.そこでこのMangaGANの登場です.
モデル概要
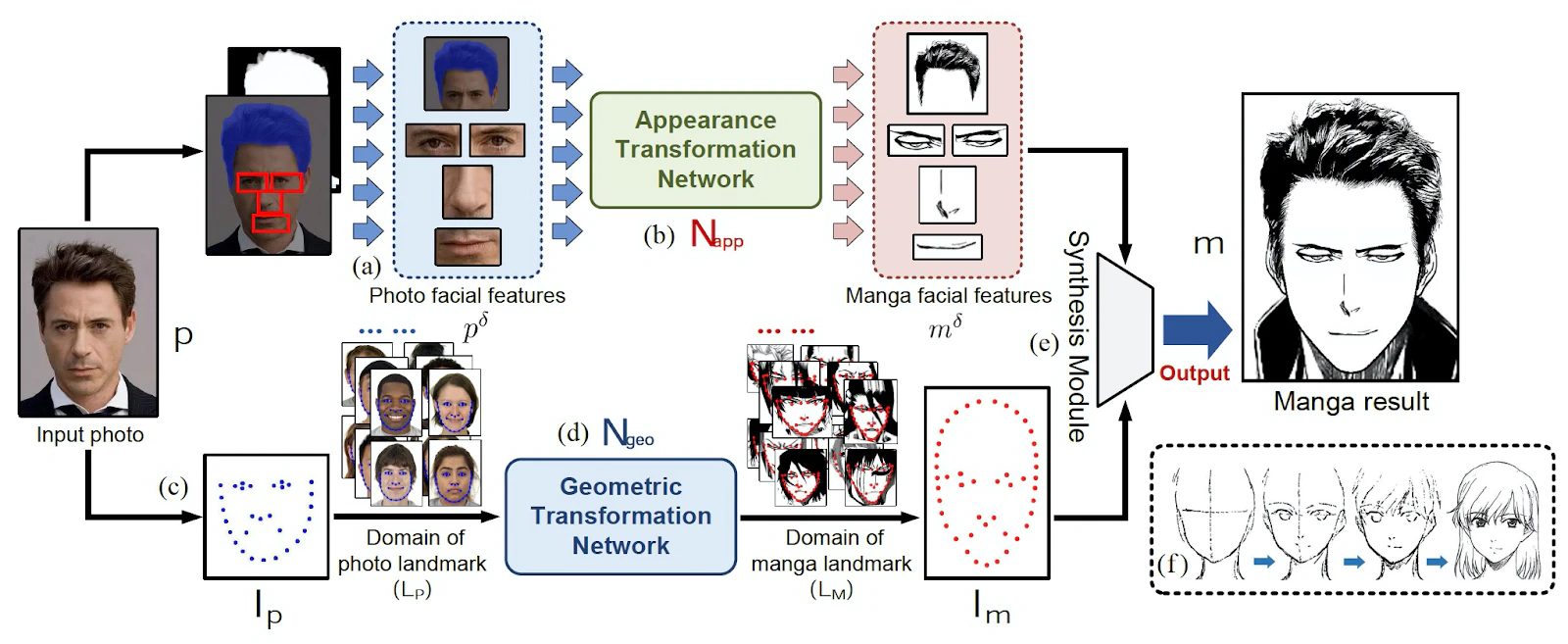
まず,右下の(f)にあるように,MangaGANの仕組みは実際の漫画を書く際の手法にインスパイアされています.はじめに誇張した輪郭を描き,目,鼻,口などの位置を決め,その後細部を描きます.
MangaGANもこれを真似るように,輪郭等の大まかな部分と細部の処理を分けて行います.
ざっくりいうと,入力画像から各パーツを切り出し,それぞれにスタイル変換を施します(上段).同時に,入力画像から輪郭や各パーツの位置とサイズを抽出して漫画風に変換し(下段),それに基づいてパーツを合成します.
損失関数
詳しく説明しようとすると数式がいっぱい出てきて大変なので,ここもざっくりと説明します.
パイプラインの上段,各パーツのスタイル変換には以下の4つの損失関数を用います.
- GeneratorはDiscriminatorを騙すように,DiscriminatorはGeneratorを見破るように仕向けるAdversarial Loss, $L_{adv}$
- 写真の特徴と漫画の特徴をうまく保存するためのCycle Consistency Loss, $L_{cyc}$
- 滑らかな線画を生成するためのStructural Smoothing Loss, $L_{SS}$
- 入力と出力をさらに似せるためのSimilarity Preserving Loss, $L_{SP}$
これら4つのLossに重みをつけて足し合わせます.
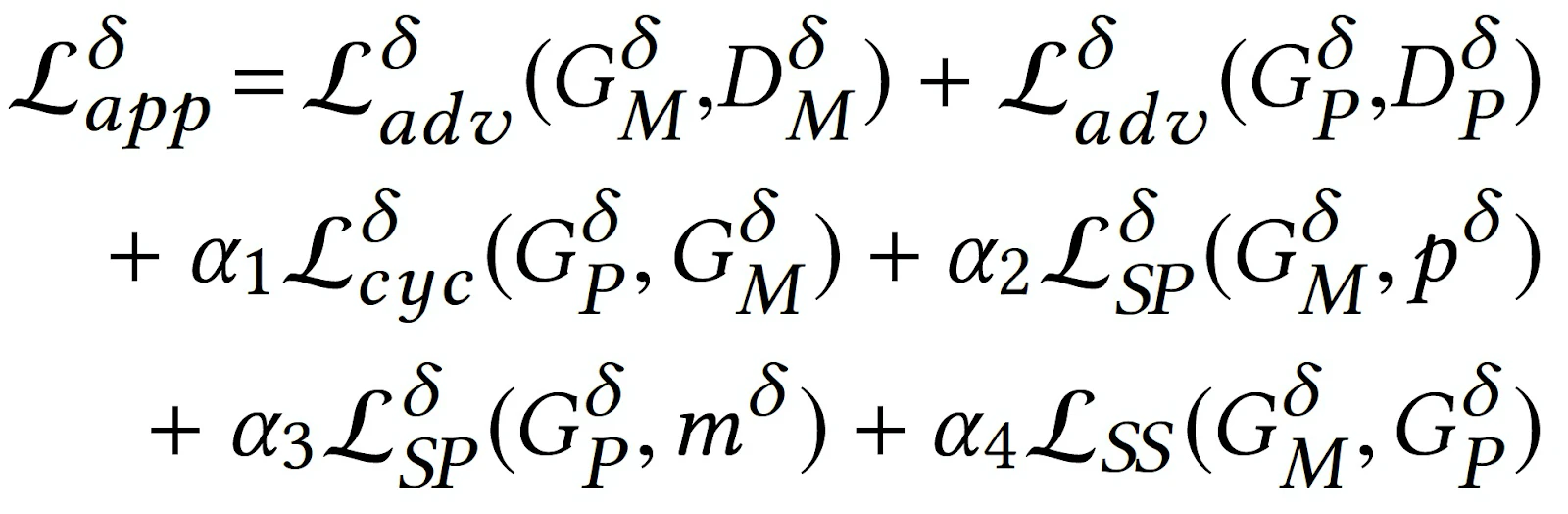
次に下段,幾何情報の変換には,$L_{adv}$,$L_{cyc}$,そして漫画向けに顔を誇張するためのCharacteristic Loss, $L_{cha}$を用います.
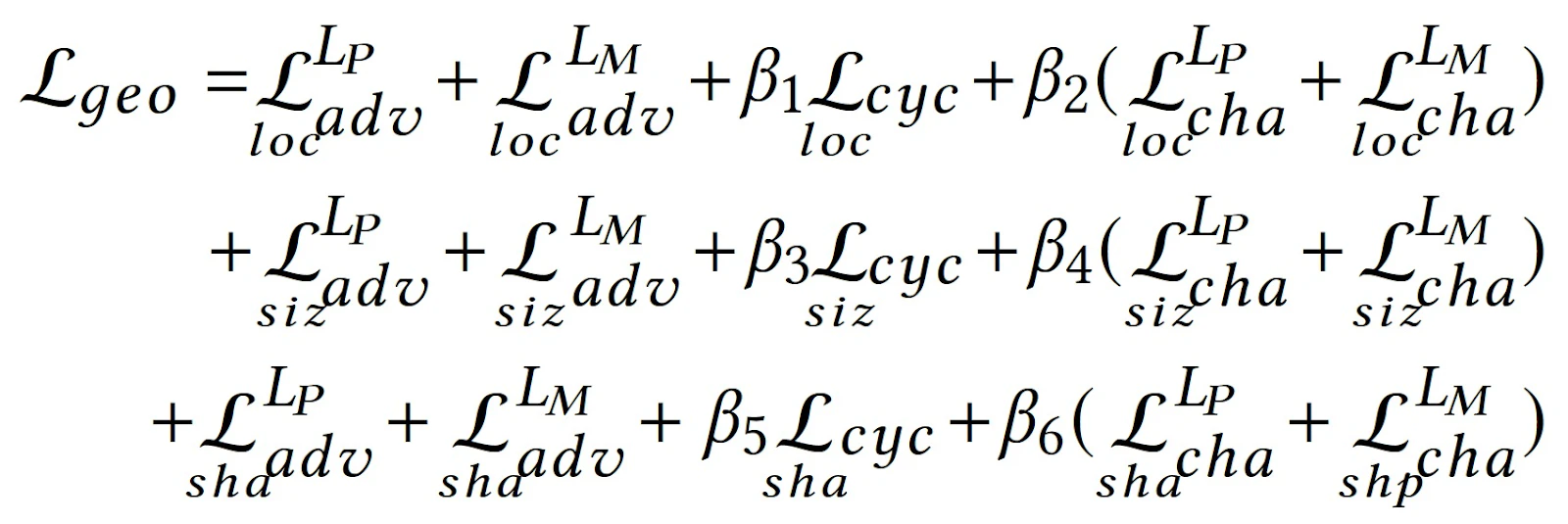
実験結果と考察
MangaGANおよび他の手法での生成結果が図5です.

右端のMangaGANは,瞼が誇張されたり,眉毛や口がすっきりしたりといったBLEACHの画風をうまく捉えつつ,髪型や眉の太さなどは元となっている人物の情報が保持されています.
終わりに
以上がMangaGANの紹介でした.「顔写真をBREACH風に変換する」というキャッチーなコンセプトと裏腹に,モデルも損失関数も非常に細かい工夫がなされていて非常に勉強になりました.実際に漫画を書く手法に着想を得たというのも面白いですね.
あまり細かい解説はしていませんが,これを機にGANに興味を持ってもらえたら嬉しいです!
参考文献
[1] Su, Hao, Jianwei Niu, Xuefeng Liu, Qingfeng Li, Jiahe Cui, and Ji Wan. "Unpaired Photo-to-manga Translation Based on The Methodology of Manga Drawing." arXiv preprint arXiv:2004.10634 (2020).
[2] Isola, Phillip, et al. "Image-to-image translation with conditional adversarial networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.