アンケートの自由記述の回答をもとに回答者をグループ分けすることができる、トピックモデル(LDA)について簡単に紹介します。
アンケートによくある質問のタイプの1つが「自由記述」です。自由記述の回答は、5段階評価などでは得られない、より詳細な情報を得ることができます。
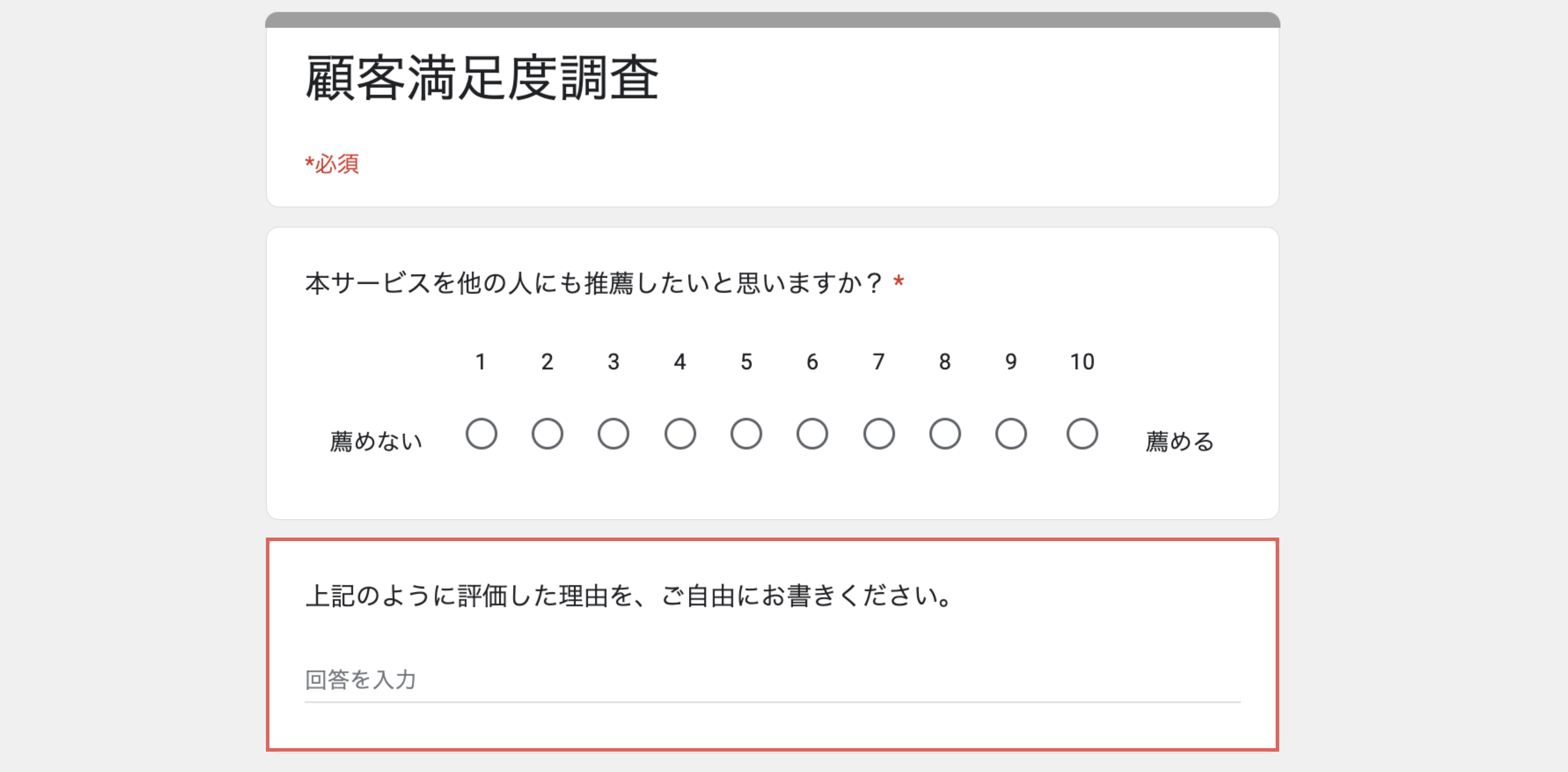
例えば、あるソフトウェアのサービスが、自社のサービスの満足度調査の一環として推奨度(NPS)と推奨度の理由についてアンケートをとったデータがあったとします。
そして、今回得られたアンケート結果をもとに、推奨度が高い人たちに対して「紹介キャンペーン」を行いたいとします。

その際に、自由記述の回答である「推奨度の理由」をもとに、それぞれの回答者の特徴を理解して、それぞれの回答者(顧客)に対してキャンペーンを行いたいです。
しかし、自由記述の回答は、回答者が少ない場合は1つ1つ読んでいくことができますが、多い時には全てを見て傾向を把握することは現実的に難しいです。
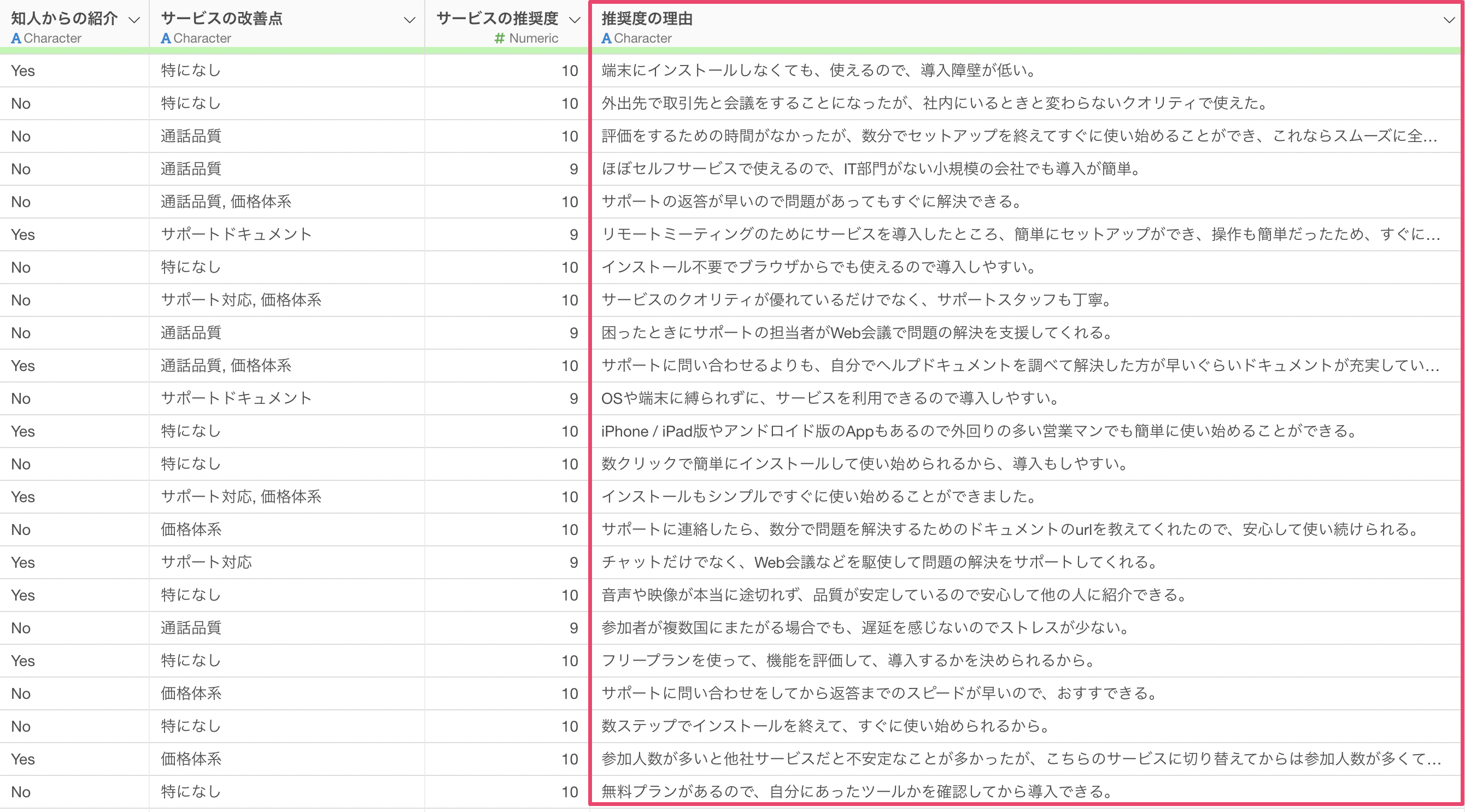
さらには、それぞれの文章の特徴をもとに、ラベルづけを行うとなれば、余計に時間がかかってしまい、途方もない作業となります。
その結果、一律のキャンペーンを実行してしまい、それぞれの回答者(顧客)に適したキャンペーンができなくなってしまいます。
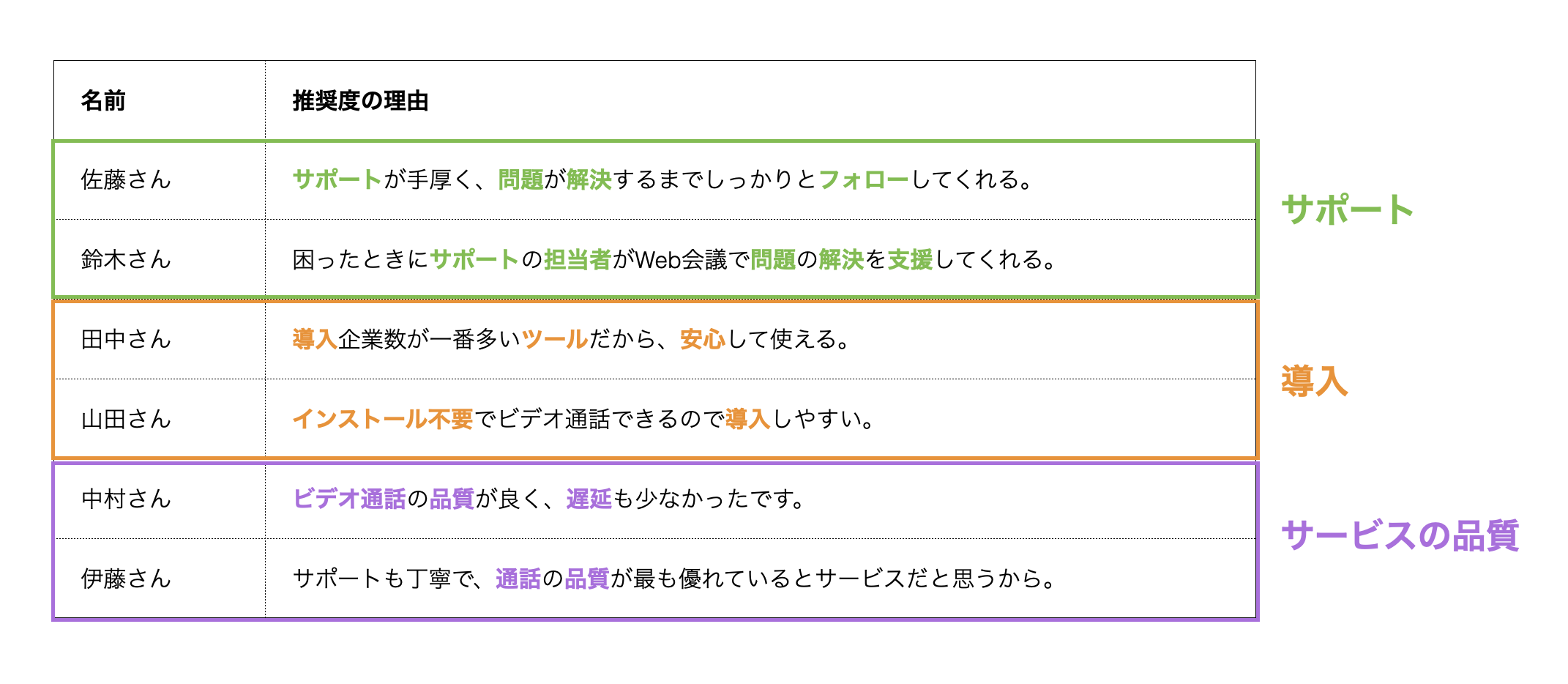
例えば、下記の文章があったとしましょう。

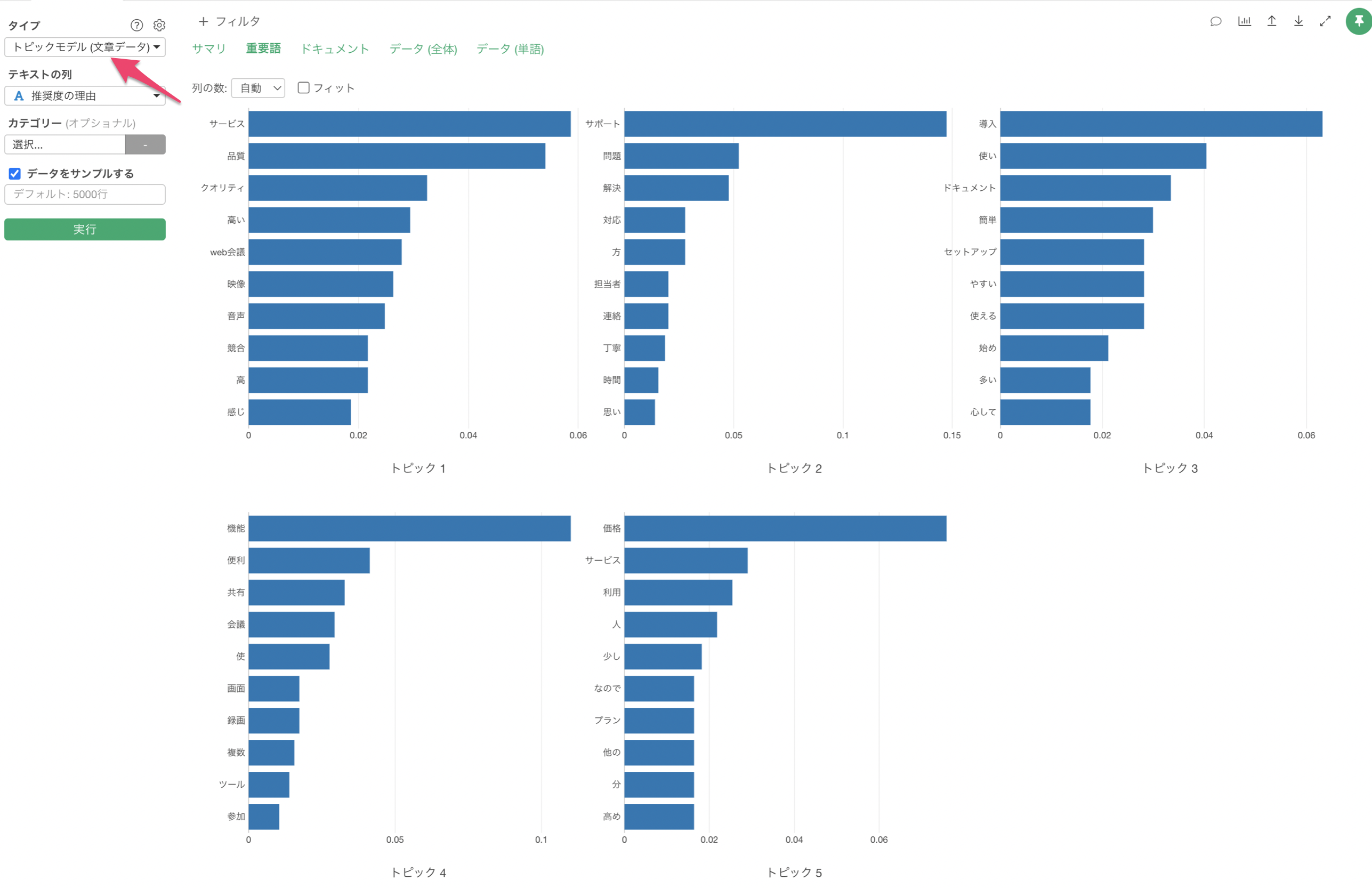
それぞれの文章をみると、「サポート」、「導入」、「サービスの品質」に関するグループがあるように見えます。
これらの文章の傾向をもとに回答者を機械的にグループ分けできないか、その問題を解決してくれるのがトピックモデル(LDA)です。
トピックモデルでは、「トピックモデル」を実行すると、文章ごとに各トピックの比率(確率)を得ることができます。

文章の中にはトピック1(サポート)、トピック3(品質)のどちらにも言及していることがありますが、トピックモデルではそれぞれのトピックの確率を出すようになっています。
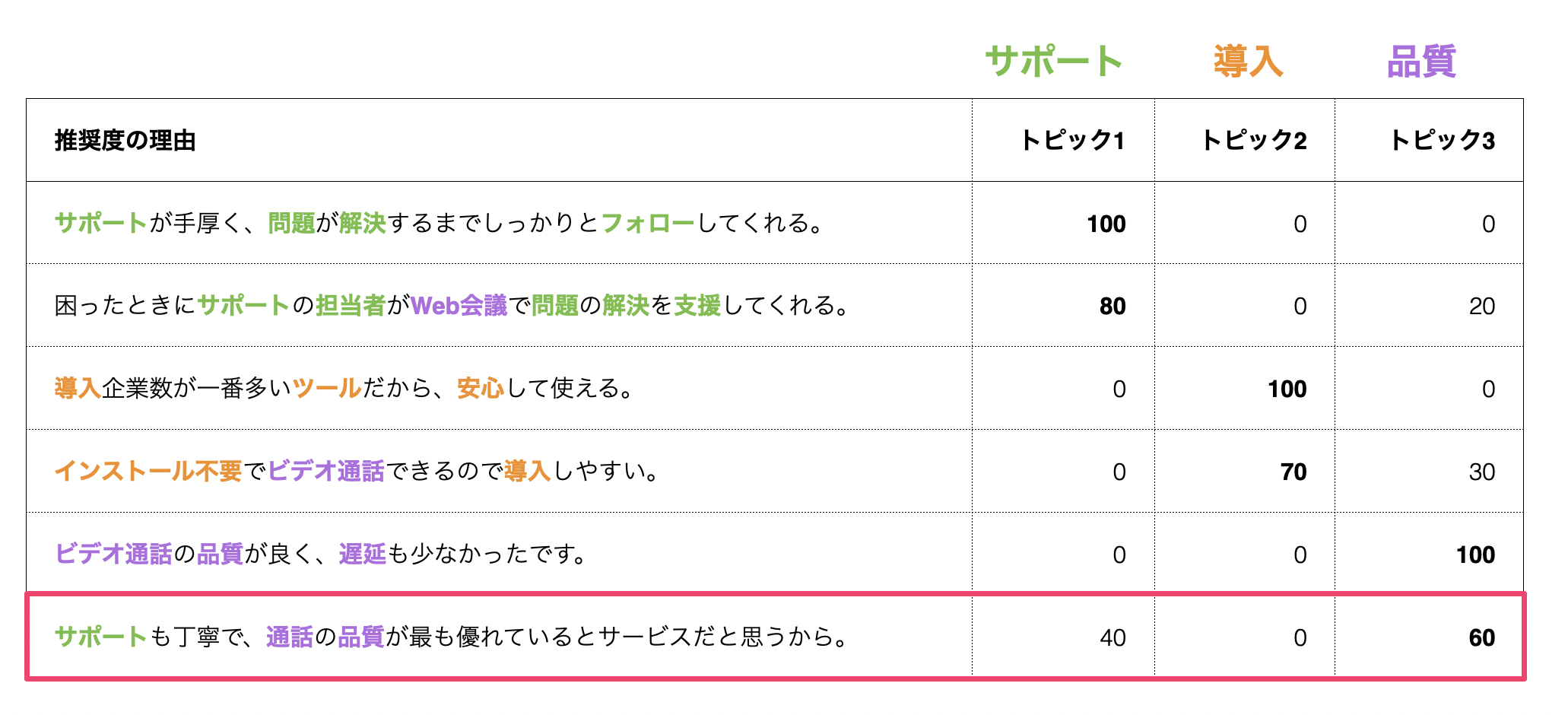
その文章におけるトピック比率が高いものをもとに、それぞれの回答者をグループ分けすることができます。
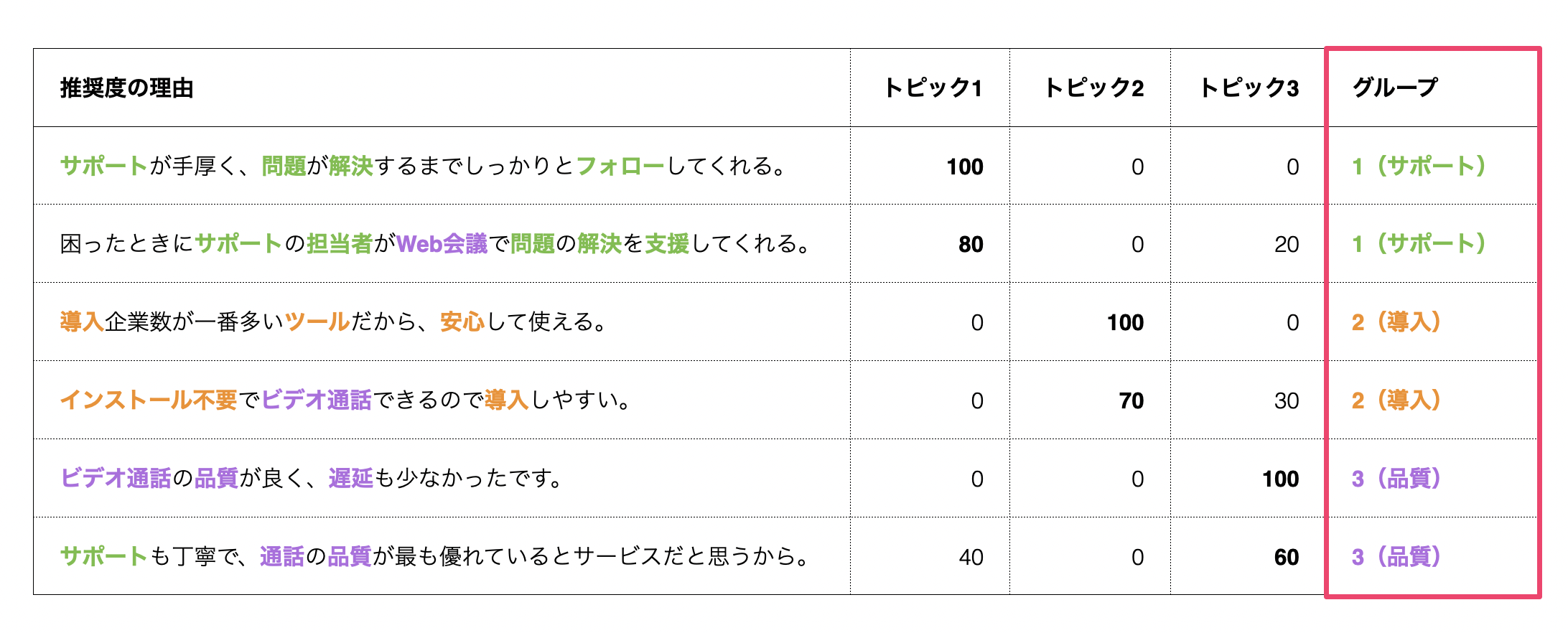
これにより、それぞれのグループにあった適切なキャンペーンを行うことができるようになります。
Exploratoryの場合は、アナリティクス・ビューの下で「トピックモデル」を選び、「自由記述」の列を選択することで簡単にトピックモデルを実行することができます。
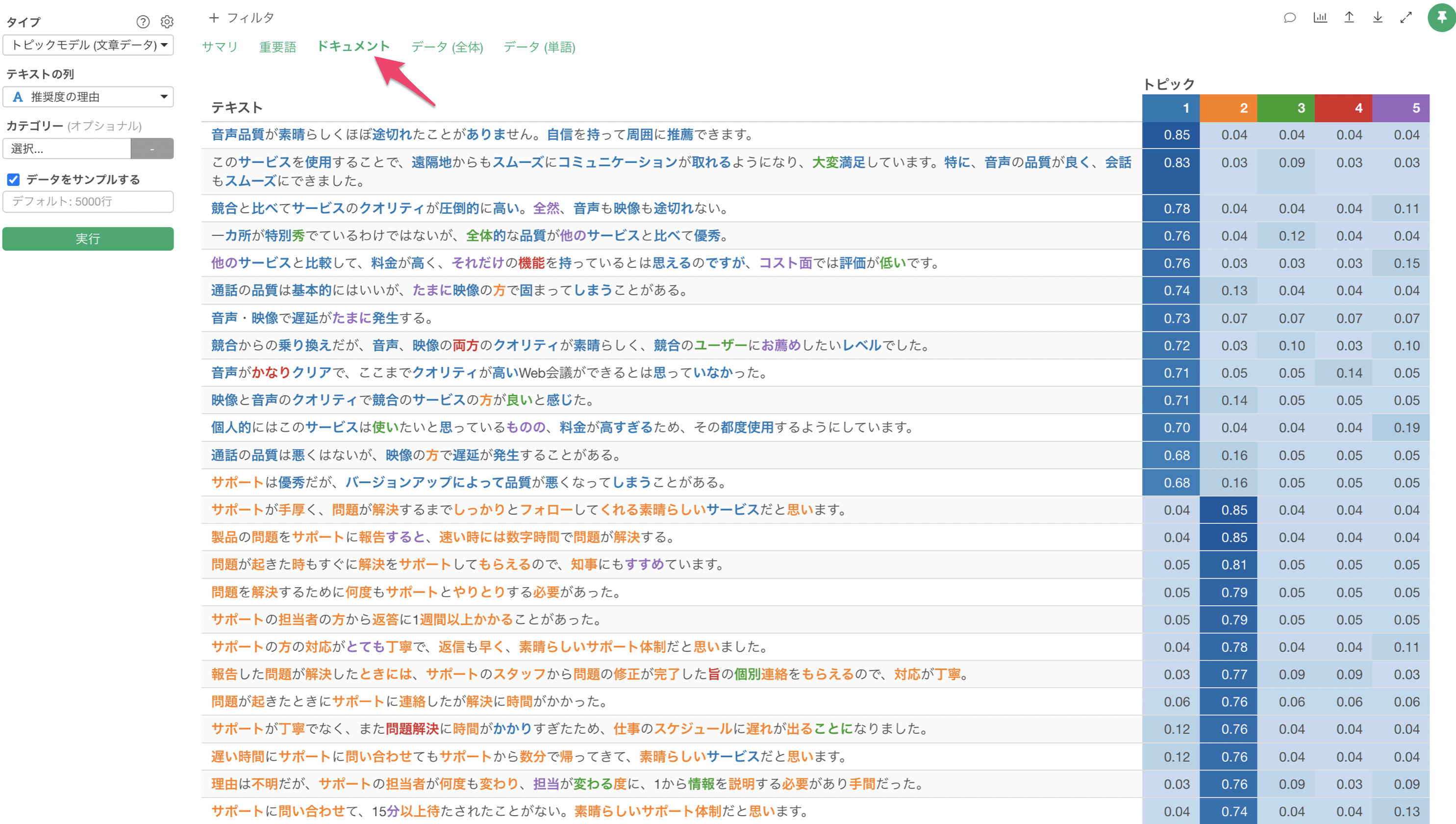
「ドキュメント」タブを使うことで、それぞれのトピックの確率が高い文章を確認することができ、どういった文章がグループ分けされているのかを簡単に解釈していくことができます。
実務で使えるスキルを身に着けたい!

今回紹介したようなアンケートデータの分析に役立つ分析手法、さらにアンケートデータに特有なデータ加工の問題の解決方法などをもっと深く学び、さらに現場で使えるレベルのスキルを身に着けたいという方は、アンケートデータの加工と分析に特化したトレーニングを用意しておりますので、ぜひご検討いただければと思います。
自分のデータで試してみたい!
記事内の全てのチャートは、データの加工、可視化、分析、レポーティングのためのUIツールのExploratoryを利用して作成しています。
ご自身のデータを使って、これらのチャートを作成したり、データの分析をしたい方は、下記のページより無料トライアルが可能ですので、ぜひ、お試しください!