アンケートをしてみたものの、5段階(または10段階)評価の回答の平均をとって終わってしまっている。あるいは、自由記述の回答を読んで、一喜一憂して終わってしまってしまいビジネスの改善には役立てられていない、といったことがあるかもしれません。
しかし、実はアンケートデータは、様々な分析手法を利用することで、ビジネスやサービスの改善のための具体的なアクションにつながるヒントを得ることができます。
そこで、こちらの記事ではアンケートデータを分析する上で欠かせない、5つの分析手法を簡単に紹介させていただきます。
アンケートデータの基本情報
アンケートを取る時にどういった情報を回答者から学びたいのか、また、それをもとにどういうアクションに繋げたいのか設計することかと思います。
目的の例:
- 顧客や従業員といった回答者を深く理解することで、適切なアクションを素早くとれるようになりたい。
- 自分たちのプロダクトやサービス改善のためのヒントを得たい。
知りたいことの例:
- 回答者はどんなタイプの人達なのか、どういった嗜好を持っているのか?
- 自社のプロダクトやサービスを使いたい、必要とする人はどういう人達か?
- 回答者は自社のプロダクトやサービスのどういった点に満足または不満を感じているか?
これらを調べるためにアンケートの「質問」が作られていきます。
アンケートの質問には大きく分けて下記のようなタイプがあります。
- 回答者の属性情報
- 例:年齢、性別、職種、など
- 数値(5/10段階評価)
- 単一回答
- 複数回答
- 自由記述
そして、得られたアンケートの回答をもとに分析をしたいとしても、何を目的にするのかによっても適したアナリティクス(分析手法)も異なってきます。下記はよくアンケートを分析する時に設定される目的とアナリティクスとなっています。
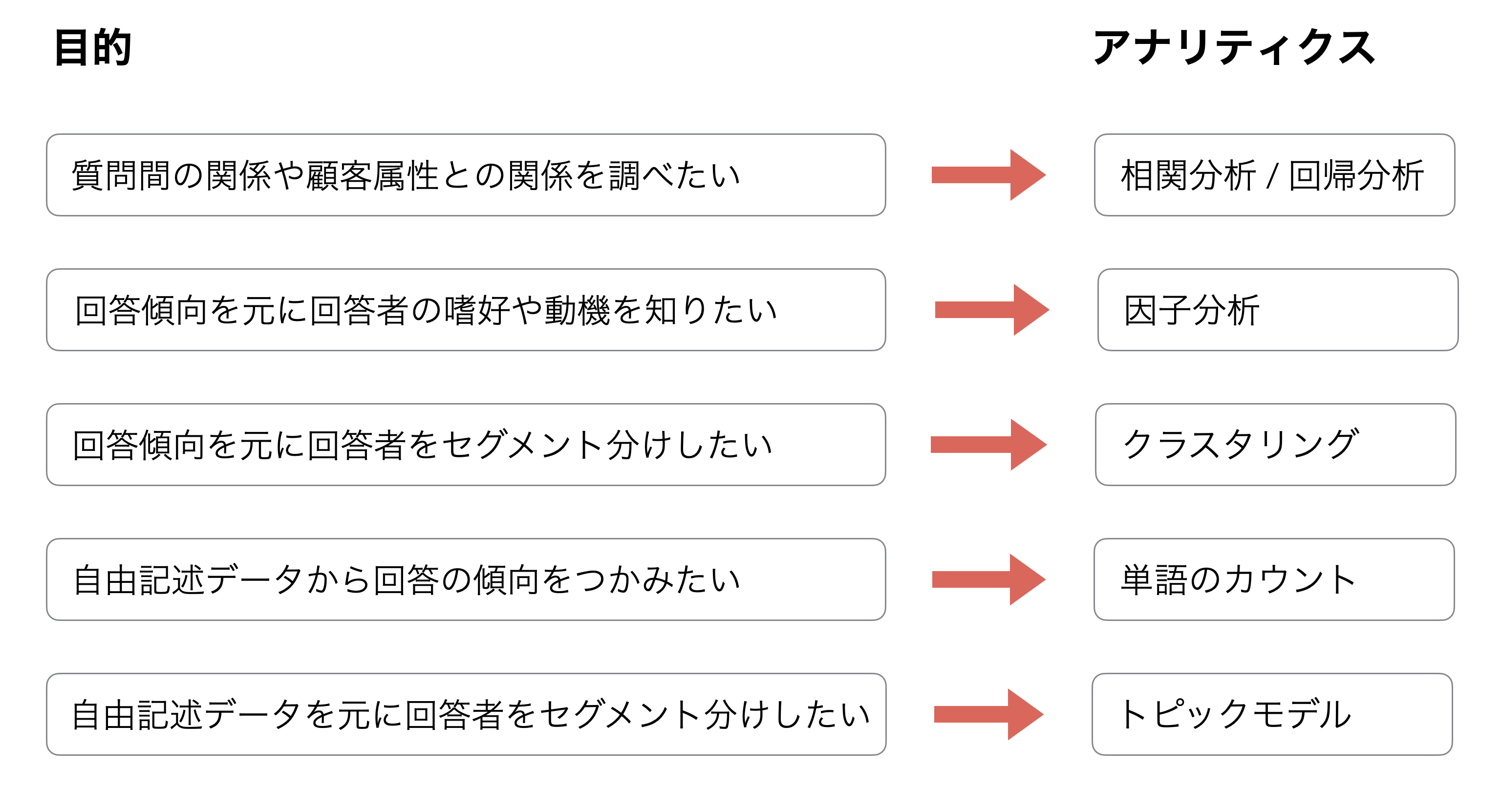
この記事でも、この目的に沿った形で5つのアナリティクス(分析手法)を紹介していきます。
1. 相関分析
アンケートデータを分析する上で、2つの列に「相関関係」があるのかどうかを調べることは重要です。
相関関係とは、2つの変数のうち、1つの変数の値が変わるともう1つの変数の値も一定の規則を持って一緒に変わる関係のことを言います。
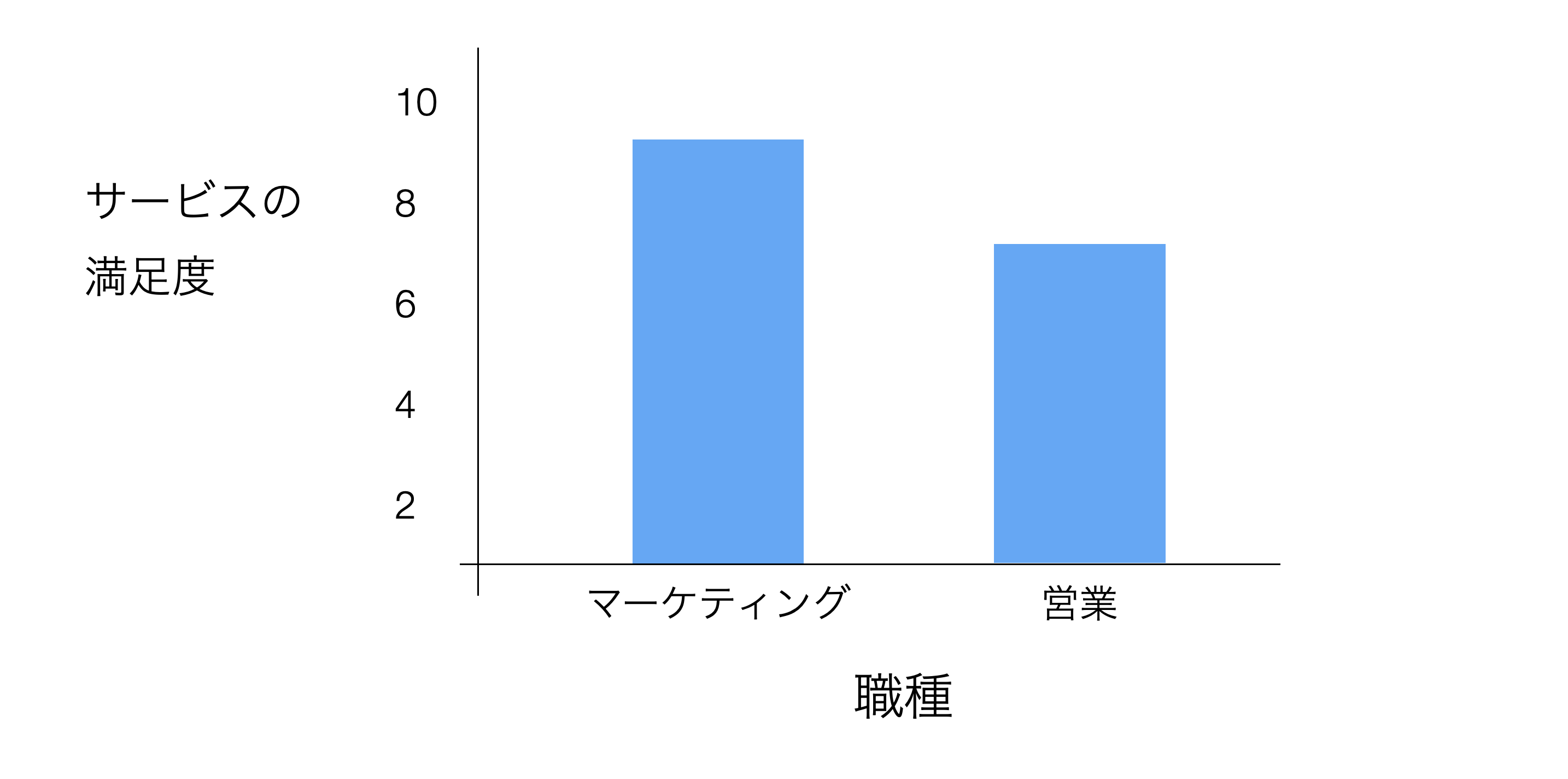
例えば、「職種」によってサービスの満足度が違うようであれば、特定の職種の人たちにターゲットを絞ってマーケティングを行うことが効果的かもしれません。
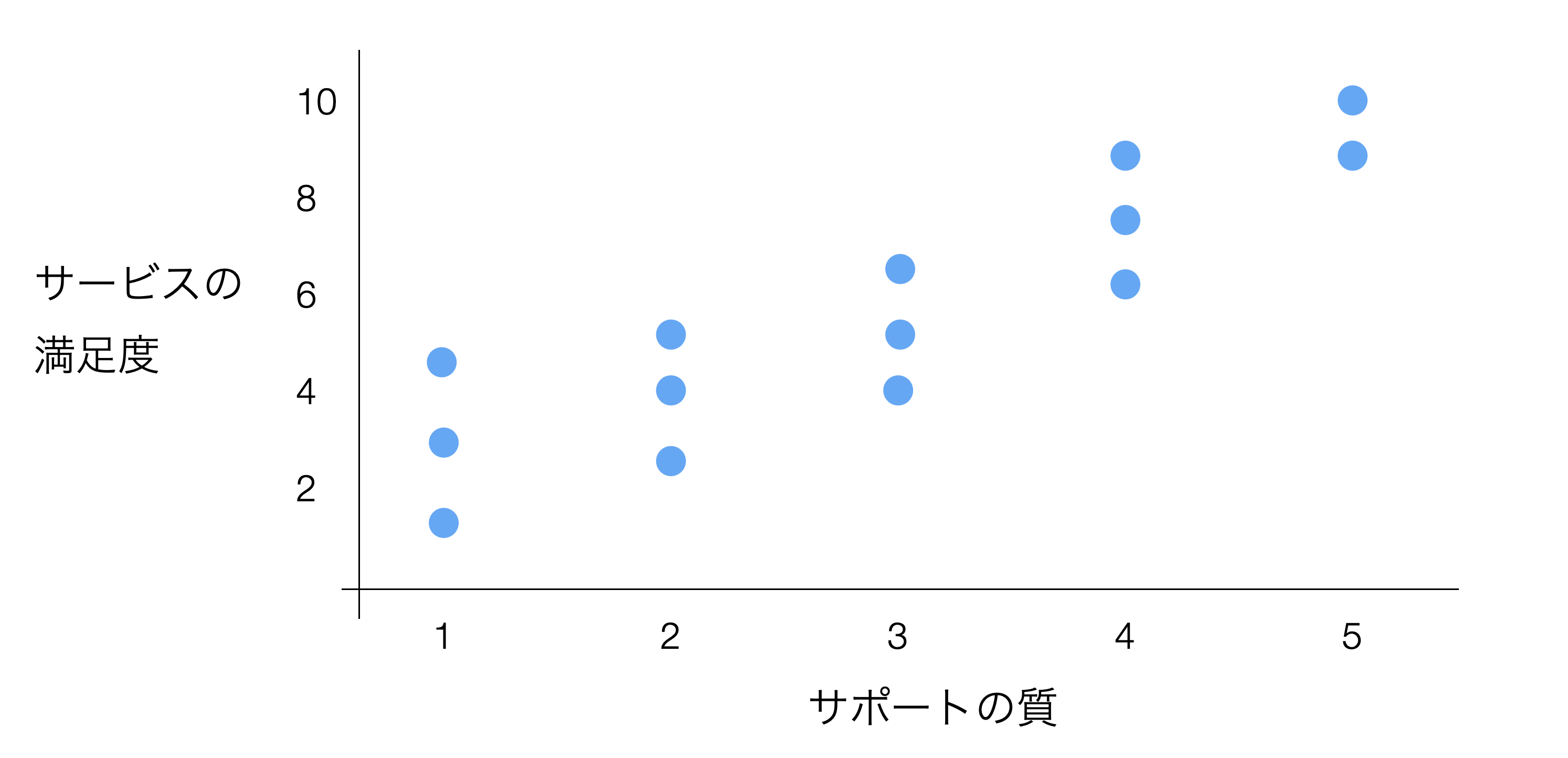
「サポートの質」のスコアが上がるとサービスの満足度も上がるようであれば、満足度を上げたいのであればサポートの質を向上させることが効果的だと考えられます。
「ブランドのイメージ」のスコアが上がってもサービスの満足度は変わらないようであれば、イメージアップ戦略を展開しても満足度の向上にはつながらないことが想定されます。
このように、データの中に「相関関係」があることで、プロダクトやサービスのための改善のヒントを得ることができます。
そして、相関関係を表す指標として、「相関係数」があります。
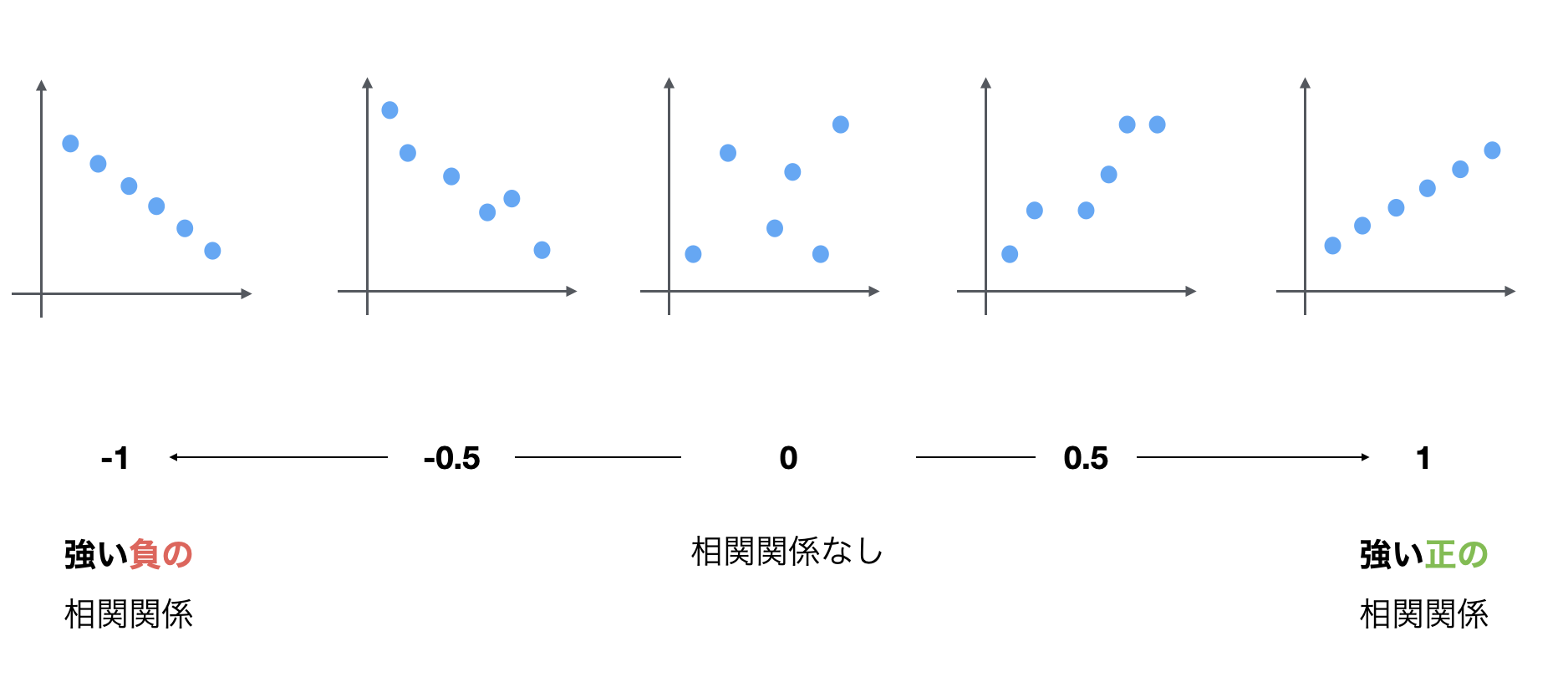
相関係数は-1から1の値を取り、1に近いほど正の相関関係があり、-1に近いほど負の相関があります。また、0に近ければ相関関係がないということになります。
Exploratoryの場合は、「相関モード」という機能を使うことで、注目している列(質問または指標)と、他の質問の相関関係を一度に調べることができます。
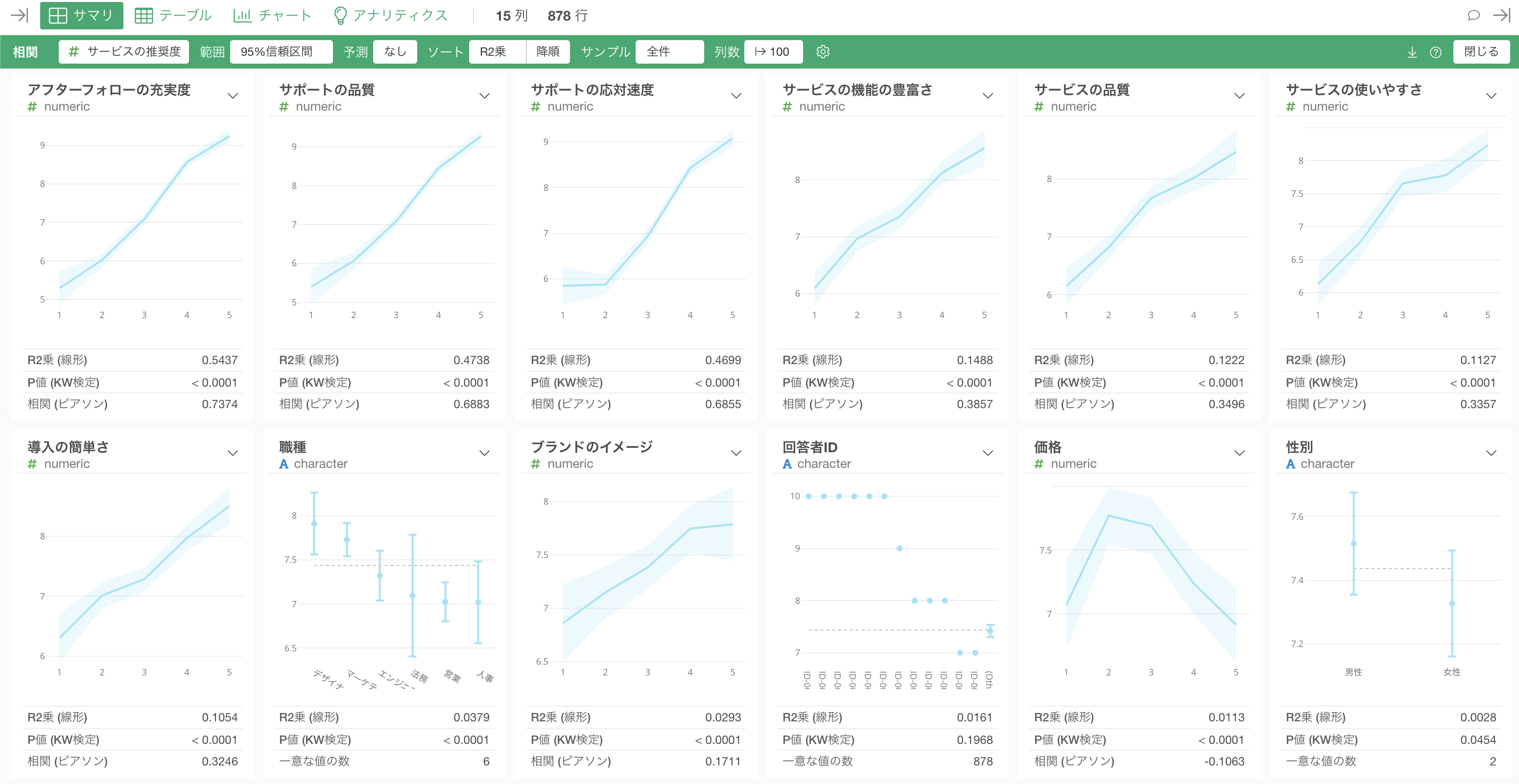
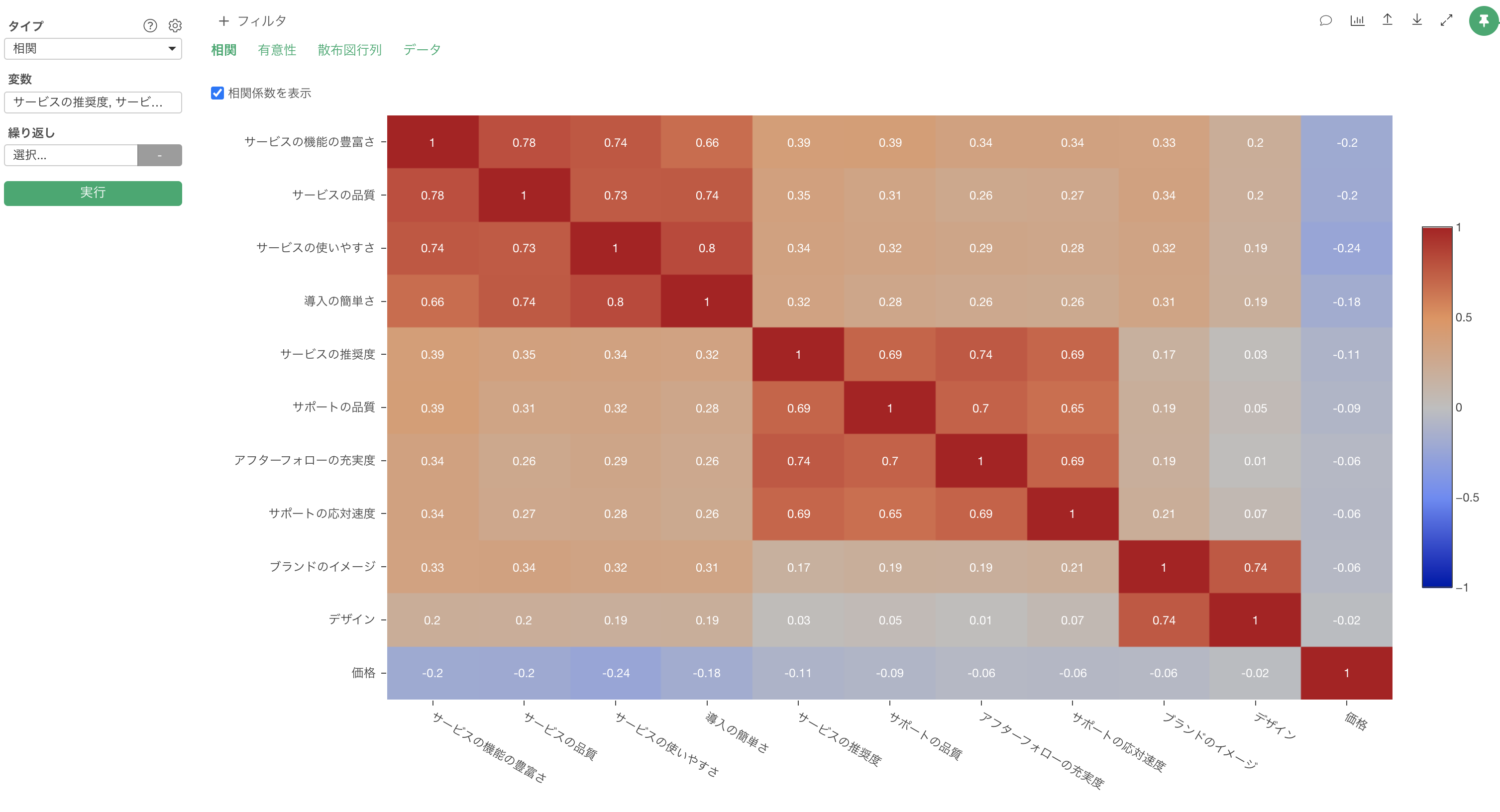
また、アナリティクス・ビューの下で全ての質問間の相関係数を一気に計算し可視化することもできます。
2. 因子分析
因子分析は質問への回答の仕方をもとに回答者の「嗜好」や
回答の裏にある「動機」をつかみたい時に利用できる統計のアルゴリズムです。
今回は、「ビールを選ぶ時に重要とするもの」を例にして説明をしていきます。

「ビールを選ぶ時に重要とするもの」に関するアンケートを実施し、以下の結果を得られたとします。
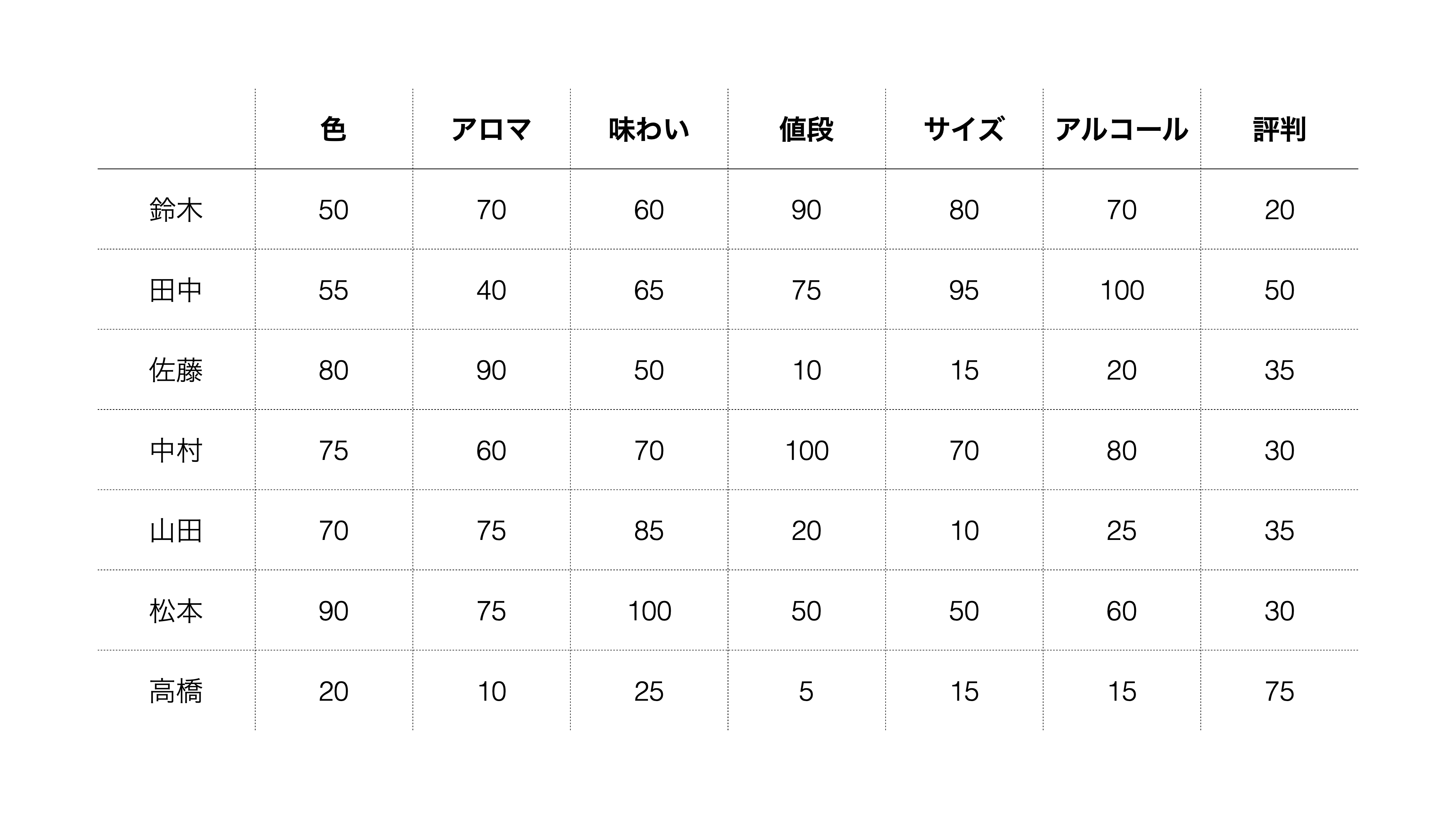
このデータは1行が1人の回答者を表しており、各列は重要度のスコアを表しています。数値が大きくなるほど、その項目の重要度が高くなります。
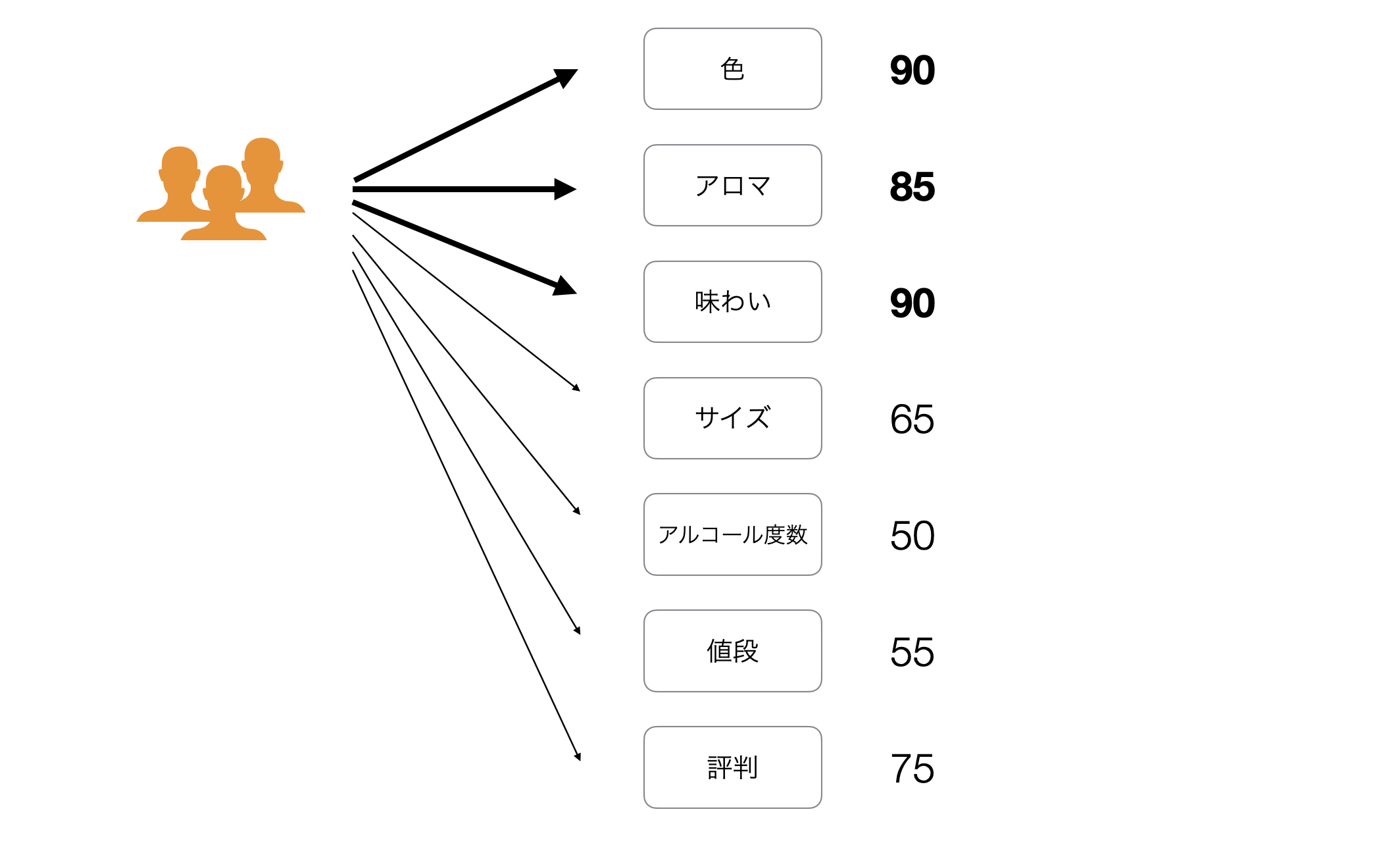
回答者の中には、「色」、「アロマ」、「味わい」を重視する人がいたとします。
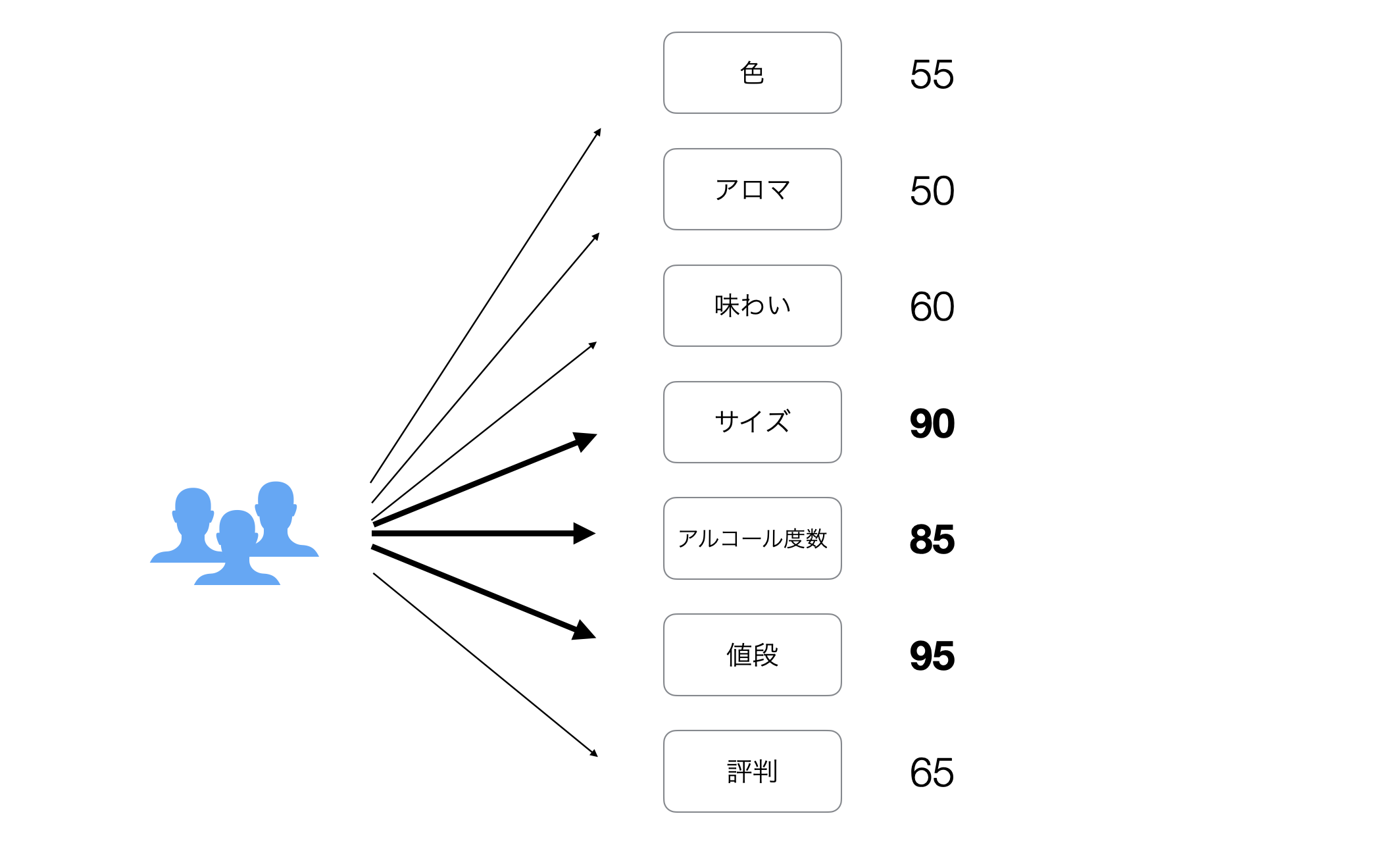
もしくは、「値段」、「サイズ」、「アルコール」を重視する人もいます。
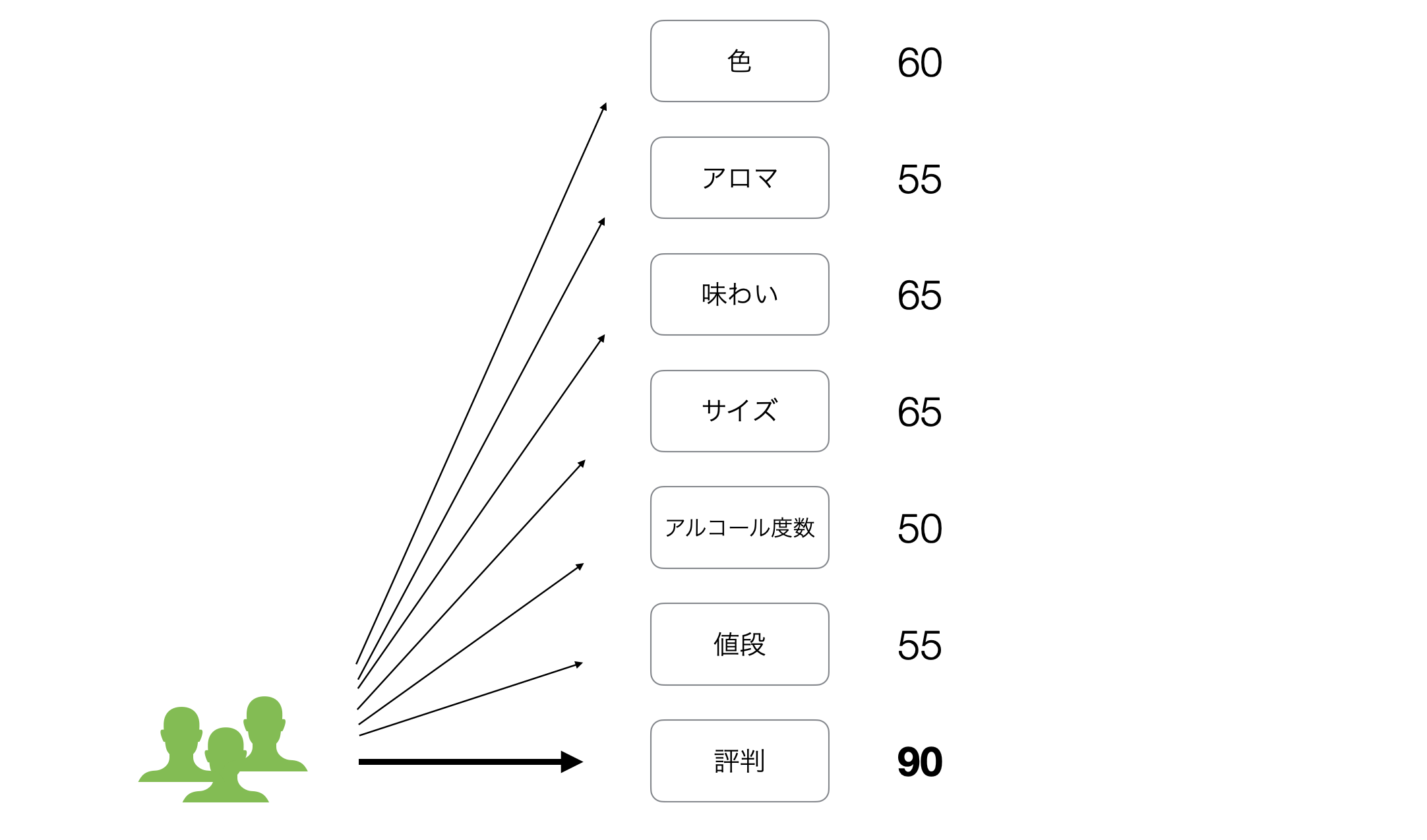
さらに「評判」を重視する人もいるようです。
このように、各々のグループは、重要と考える項目が異なるわけです。
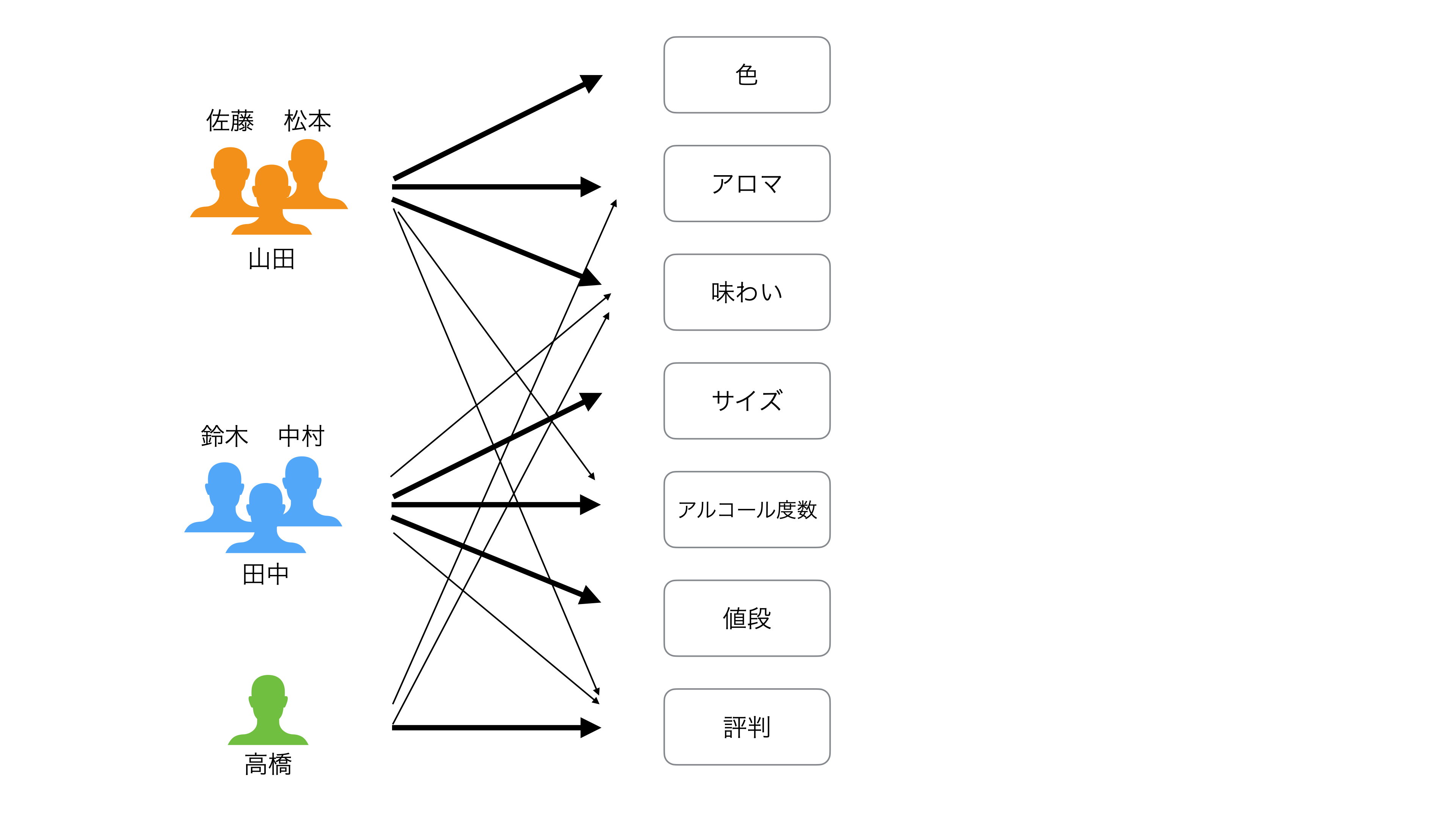
見方を変えると「ビールを選ぶ時に重要とするもの」に対して、以下を重要に考える嗜好(因子)があるとも言えます。
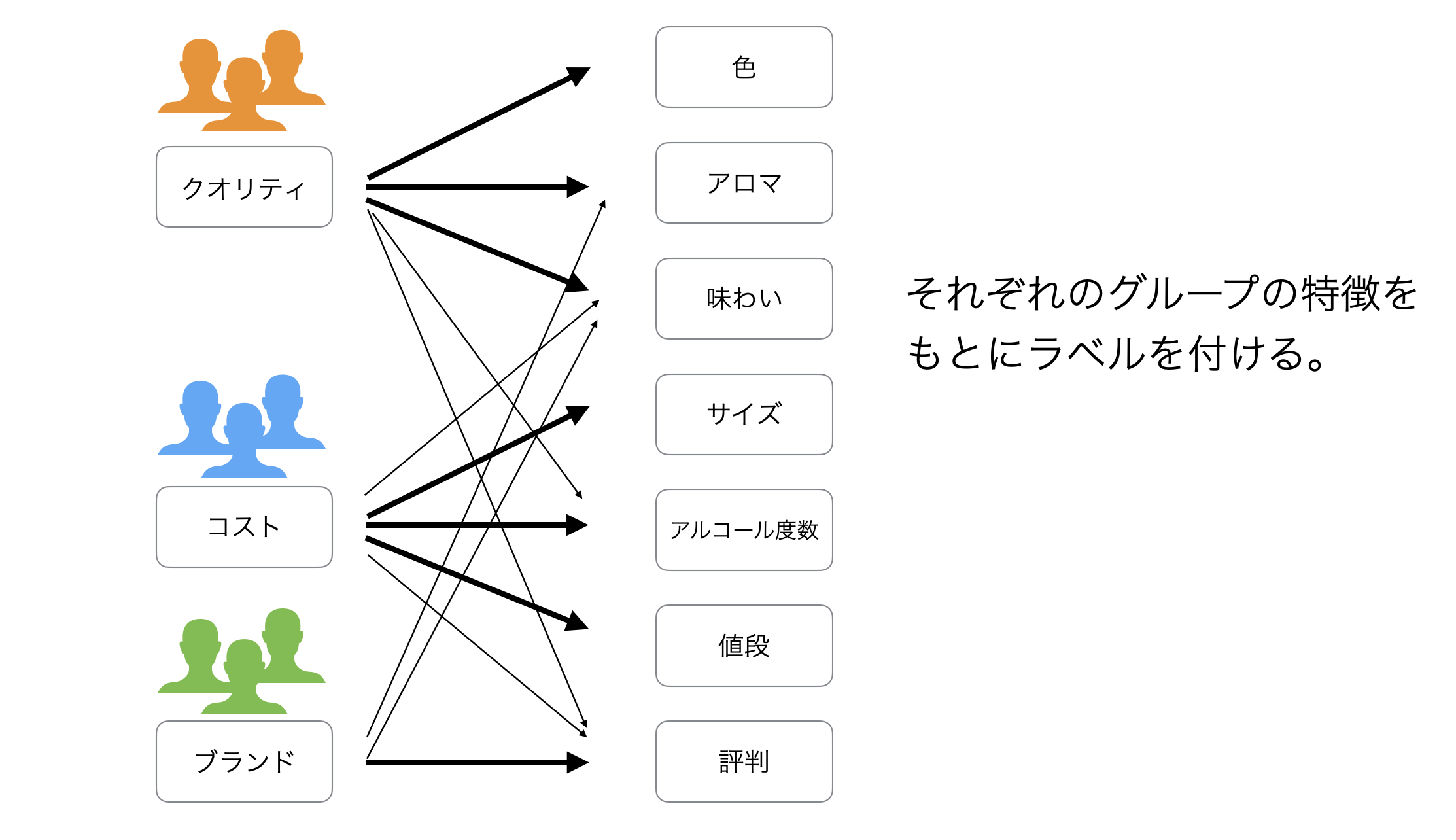
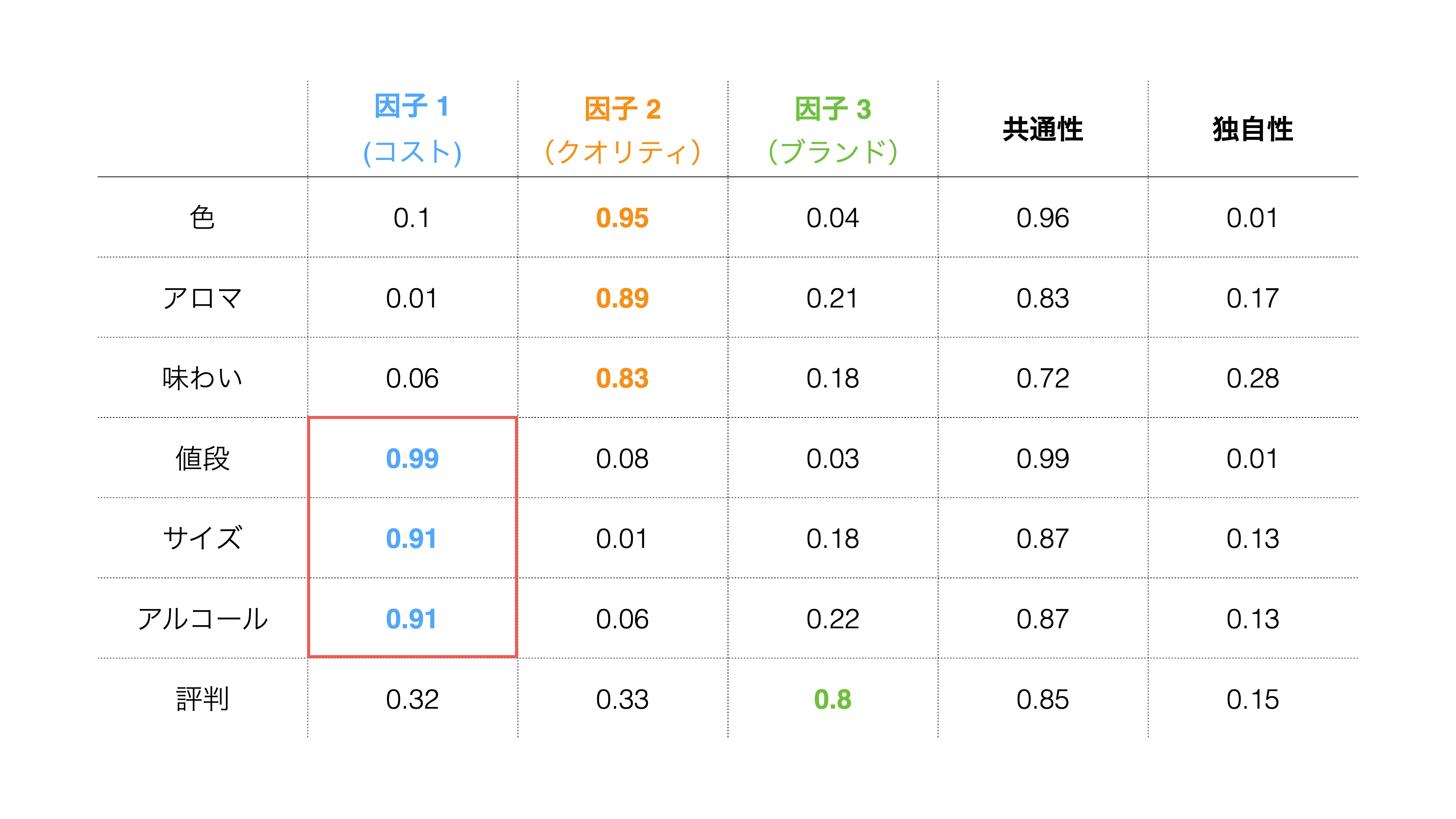
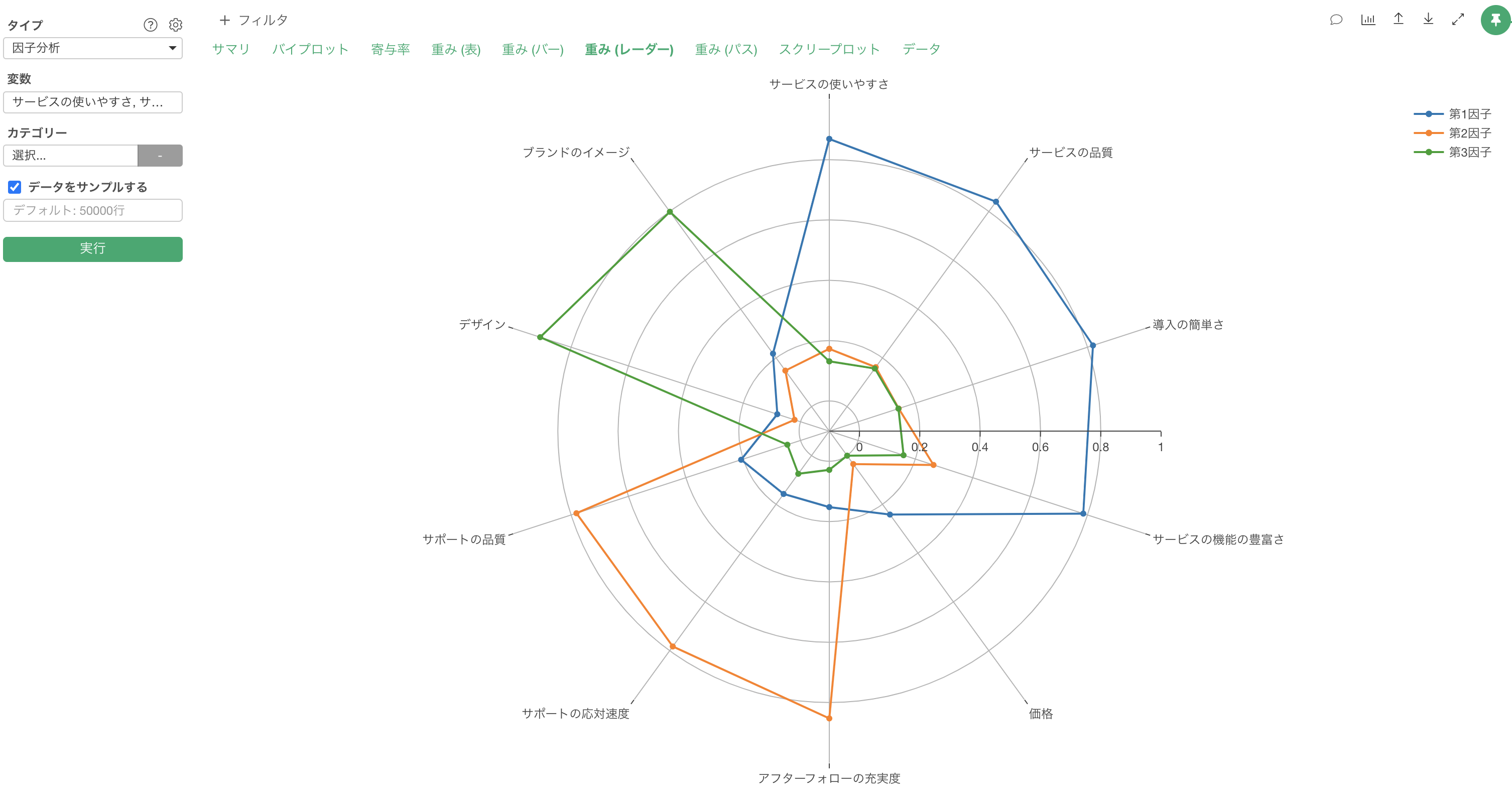
因子分析では、上記のようなモチベーションのラベル付けをできるように、アンケートの背後にあるモチベーションを「因子」として抽出し、各因子と各変数(質問)の相関の強さを「因子負荷量」として、計算します。
因子負荷量は−1から1の間の値をとり、−1または1に近づくほど、各因子がそれぞれの変数に与える影響が強いと言えます。
Exploratoryでは、アナリティクスビューから「因子分析」を簡単に実行することができます。
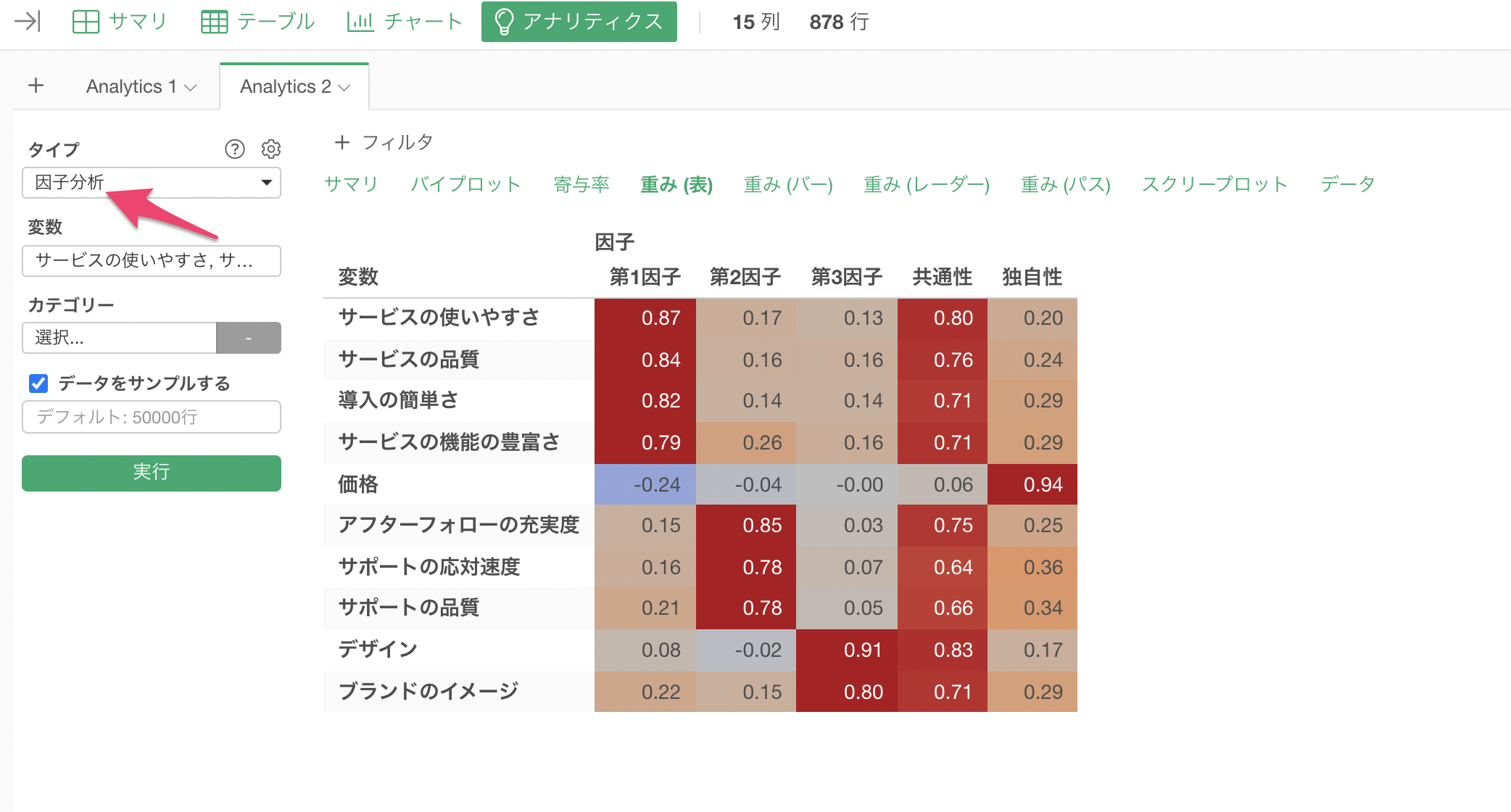
様々なチャートを使って各因子の特徴や因子間の関係を直感的に理解していくことができます。
3. クラスタリング
クラスタリングとは、データの中にある共通な部分を持つグループにデータを分類する手法です。
例えば、マーケティングの担当者として、アンケートに回答してくれた人たちに対してキャンペーンのメールを配信したいとします。
しかし、ここで疑問があります。回答者全員に「同じ」キャンペーンのメールを送ってしまっていいのでしょうか?アンケートの回答者は全員同じ性質であるはずはなく、回答者はそれぞれ異なる性質を持った人たちのはずです。
例えば、あるサービスを導入する時に重視するものについて調査を行ったアンケートデータがあったとします。
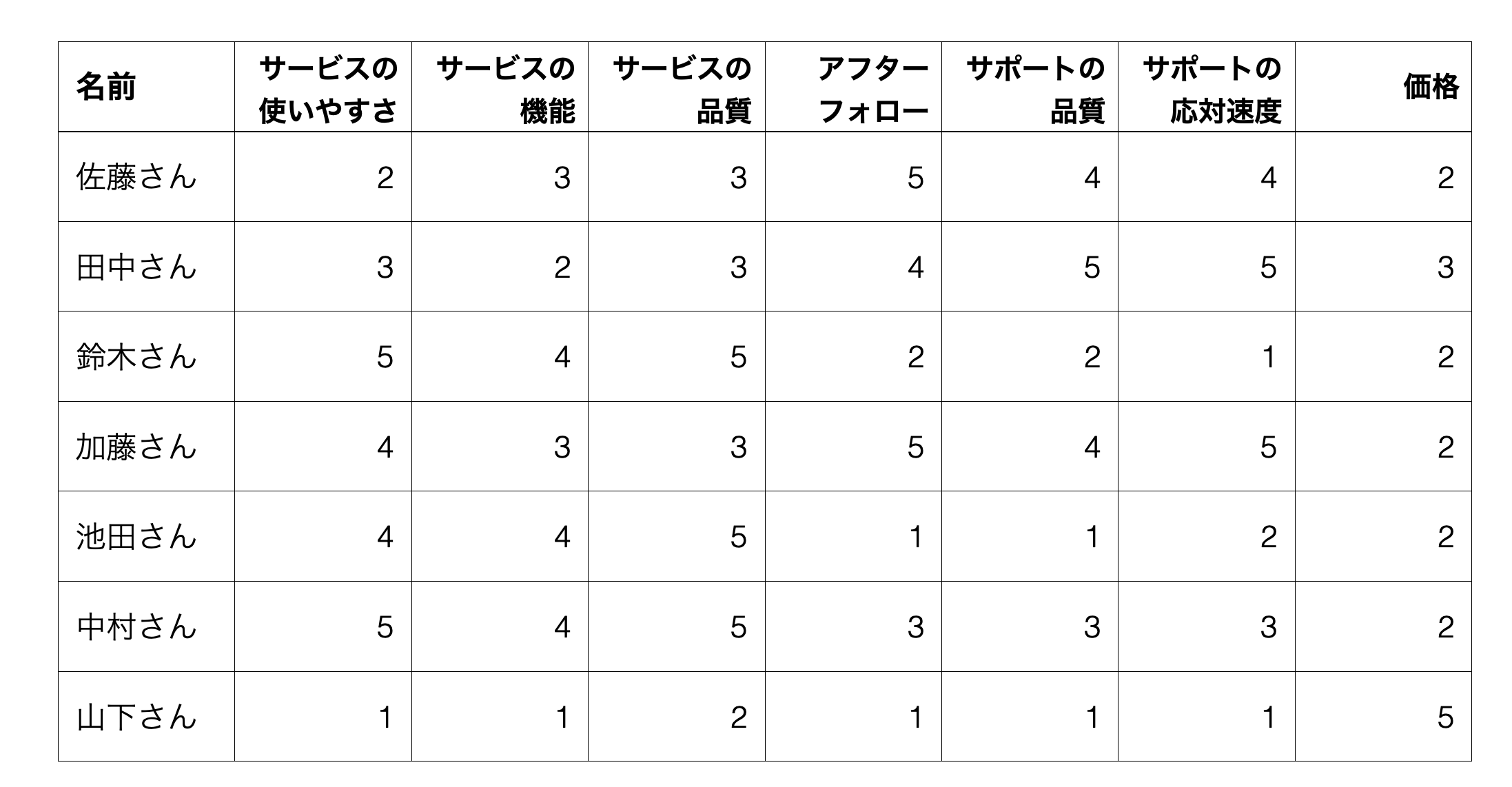
回答傾向をもとに、回答者は以下のような3つのグループがあると考えられます。
サービスの使いやすさ、機能、品質」重要視するグループ
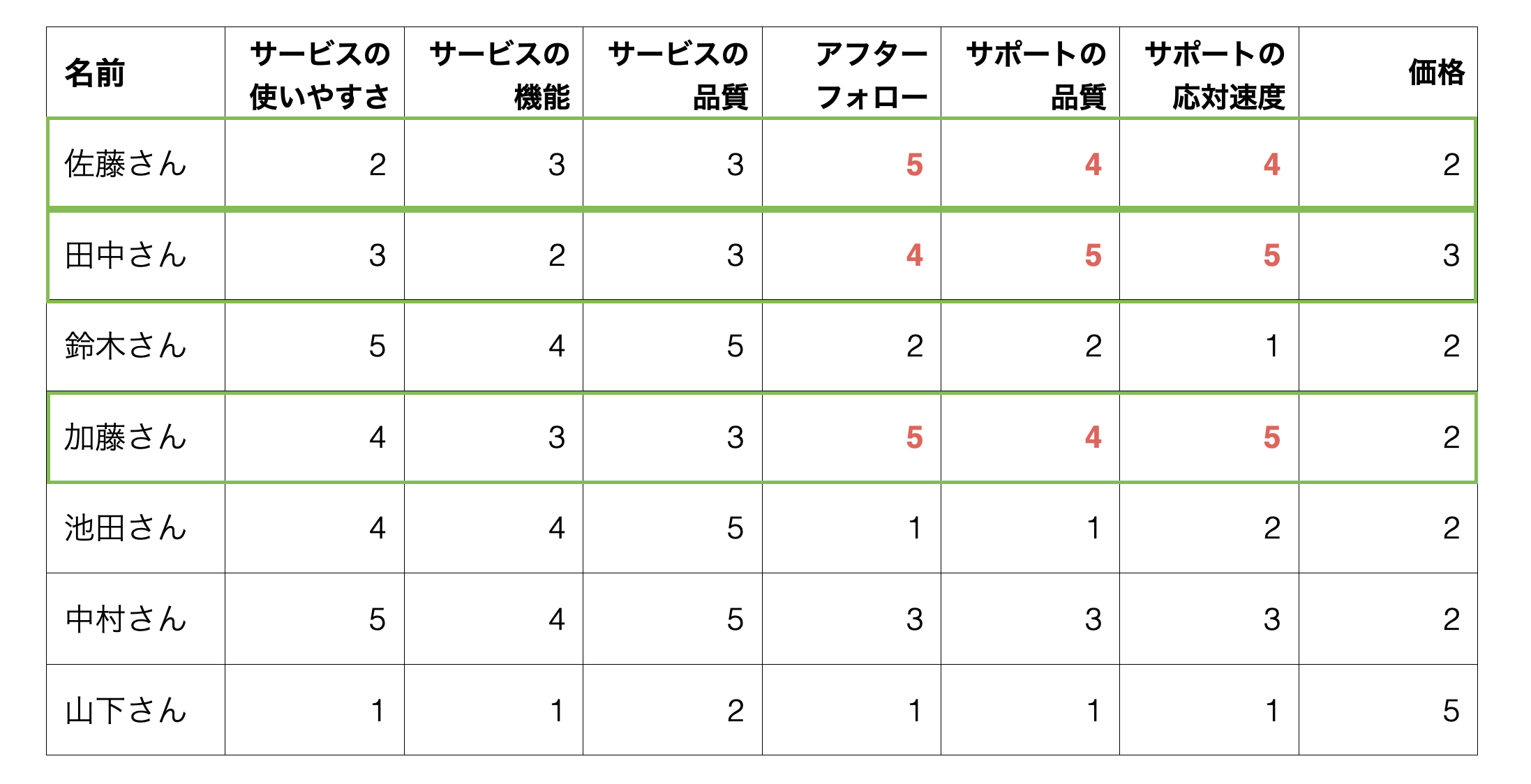
アフターフォロー、サポート品質、応対速度を重要視するグループ
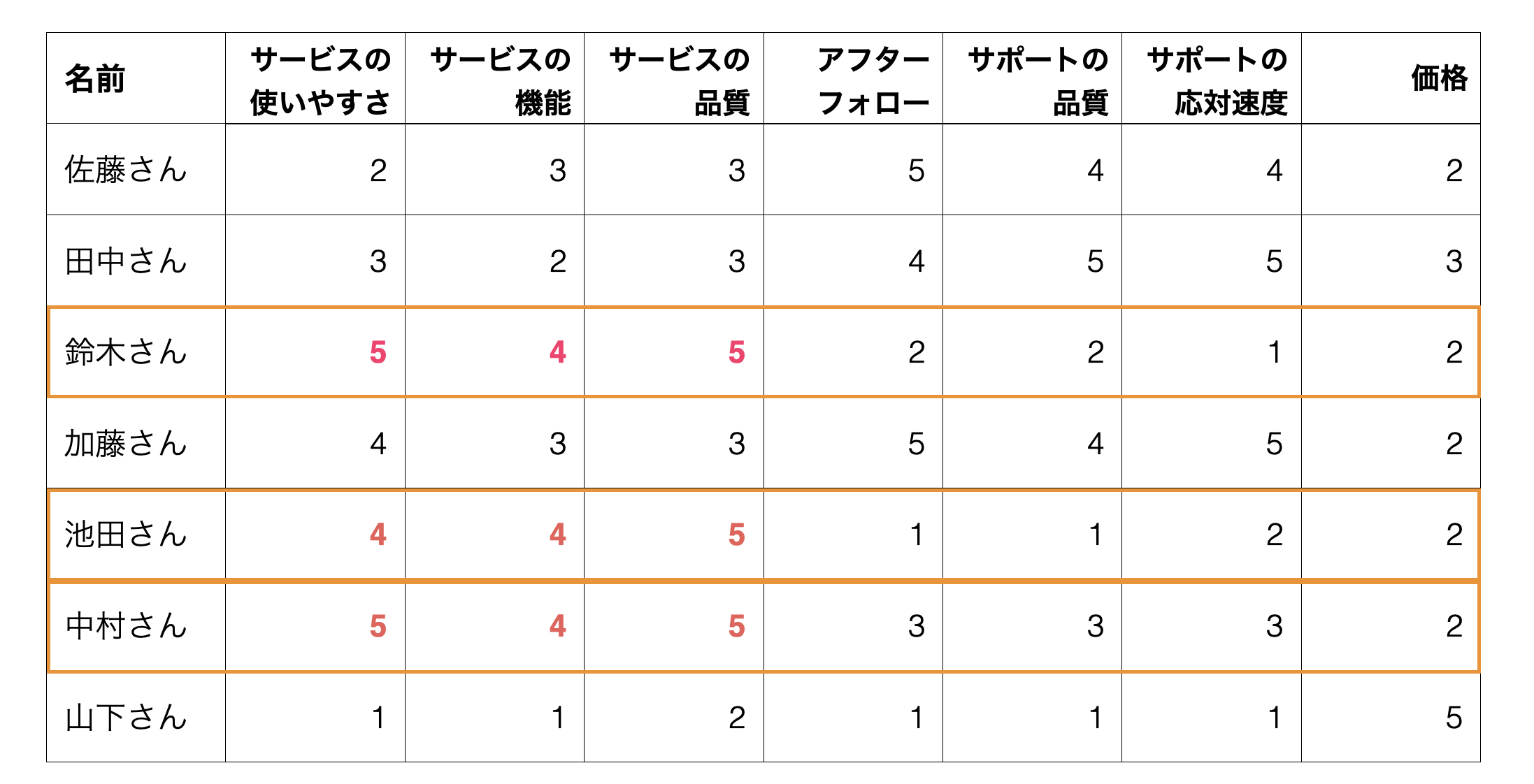
価格を重要視するグループ
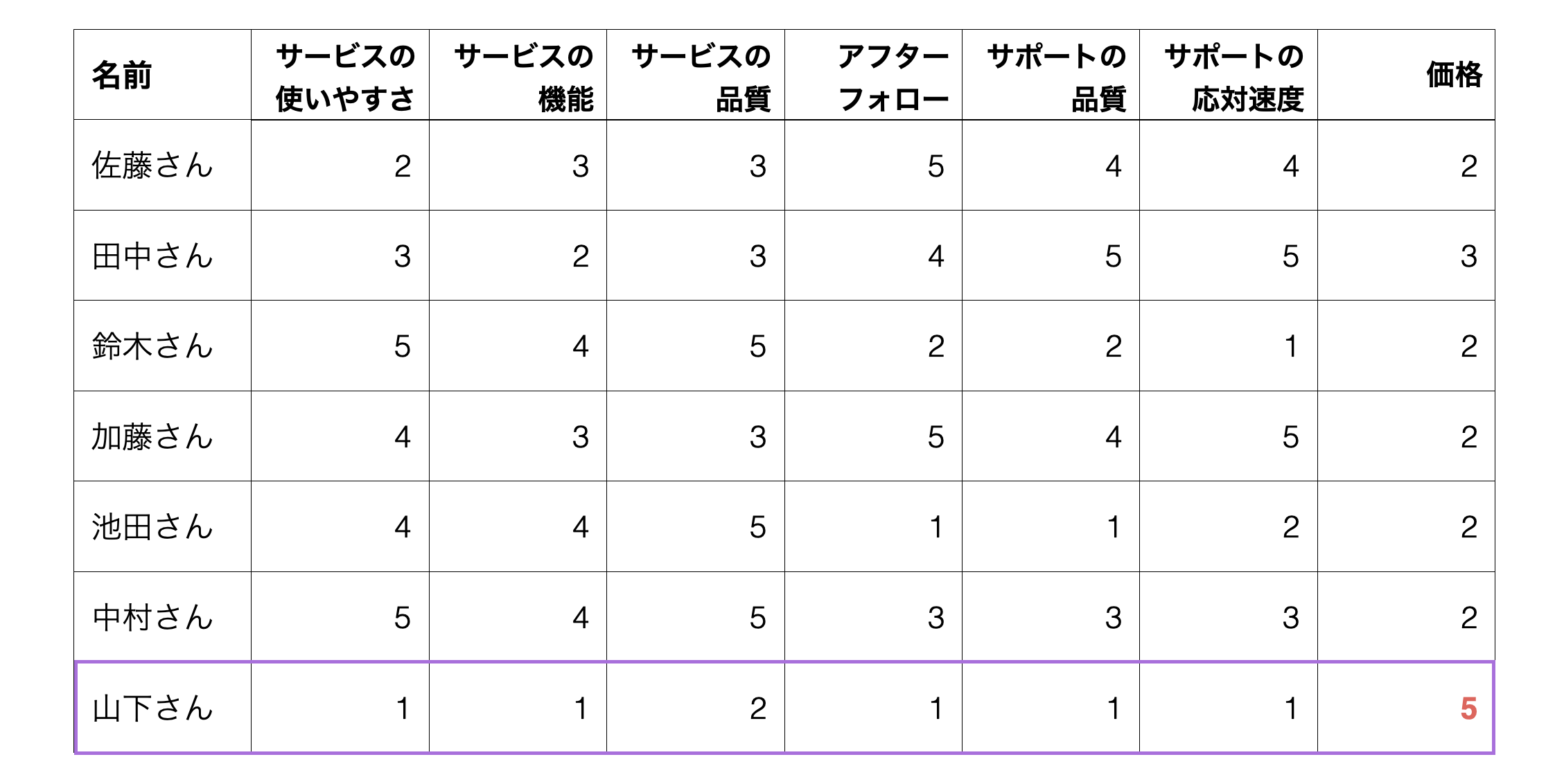
上記のように、アンケートの回答傾向は何を回答者が重視するかによって異なっています。
そこで、「クラスタリング」を行うことで、回答の傾向をもとに回答者をいくつかのグループに分類することができます。
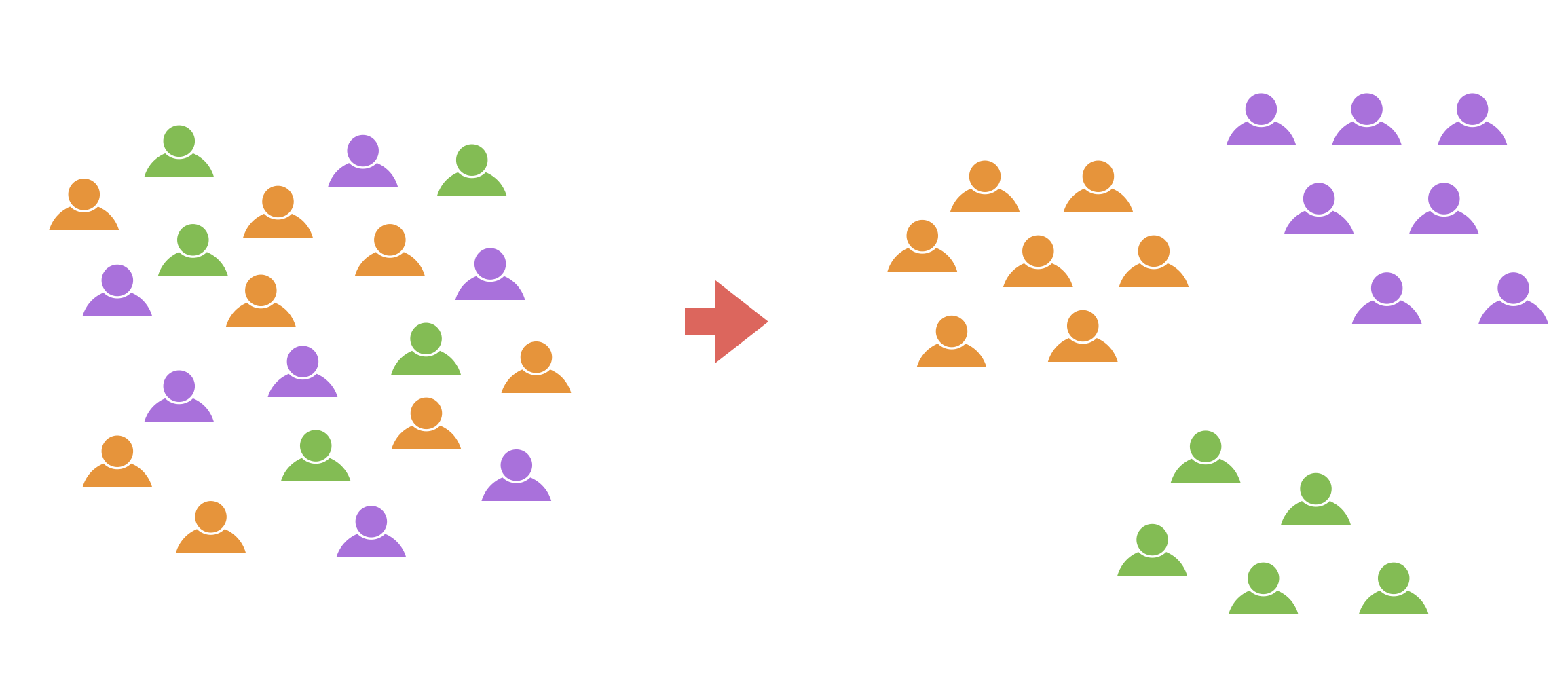
アンケートデータをクラスタリングすることで、グループ分けした回答者に対して、適したアプローチを取ることができるようになります。
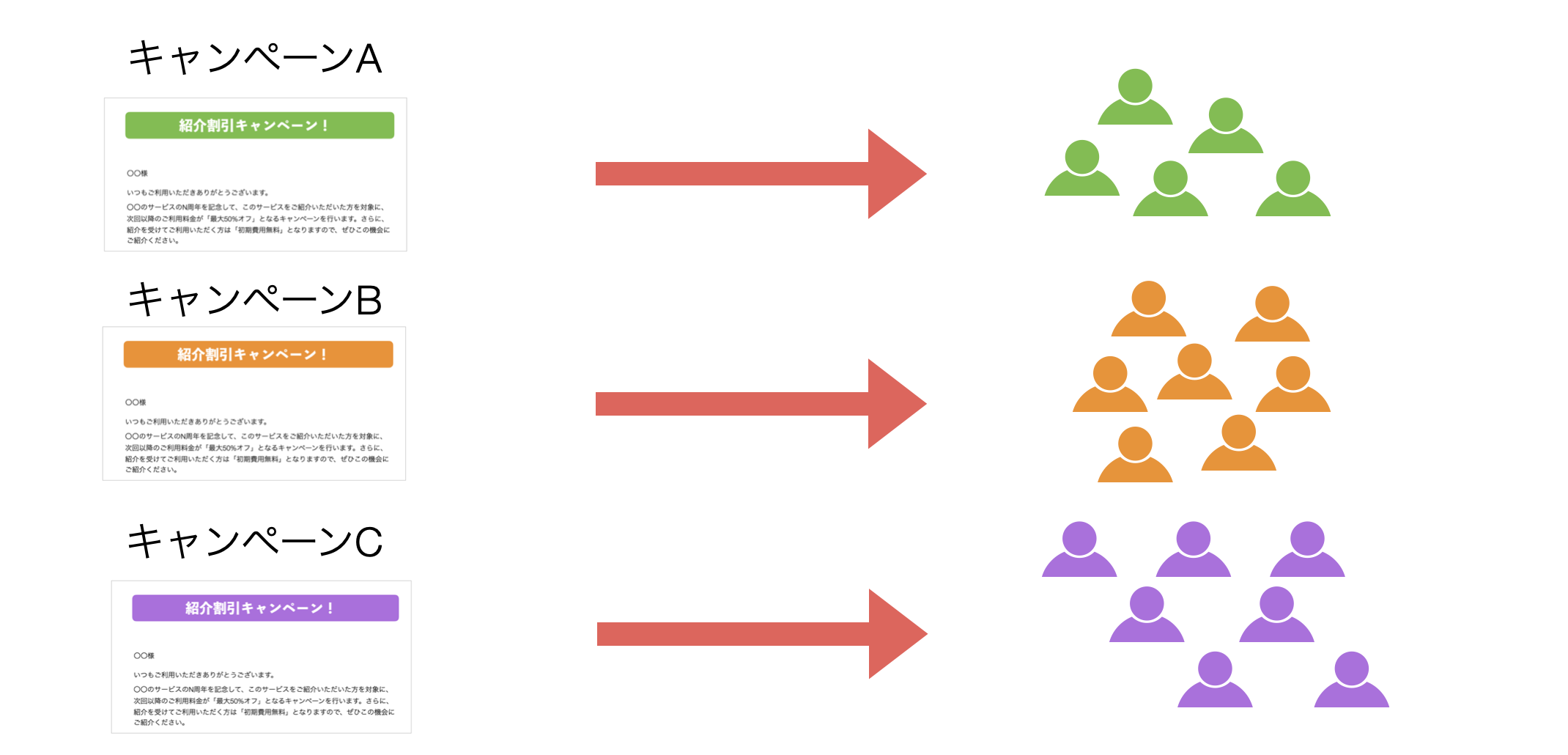
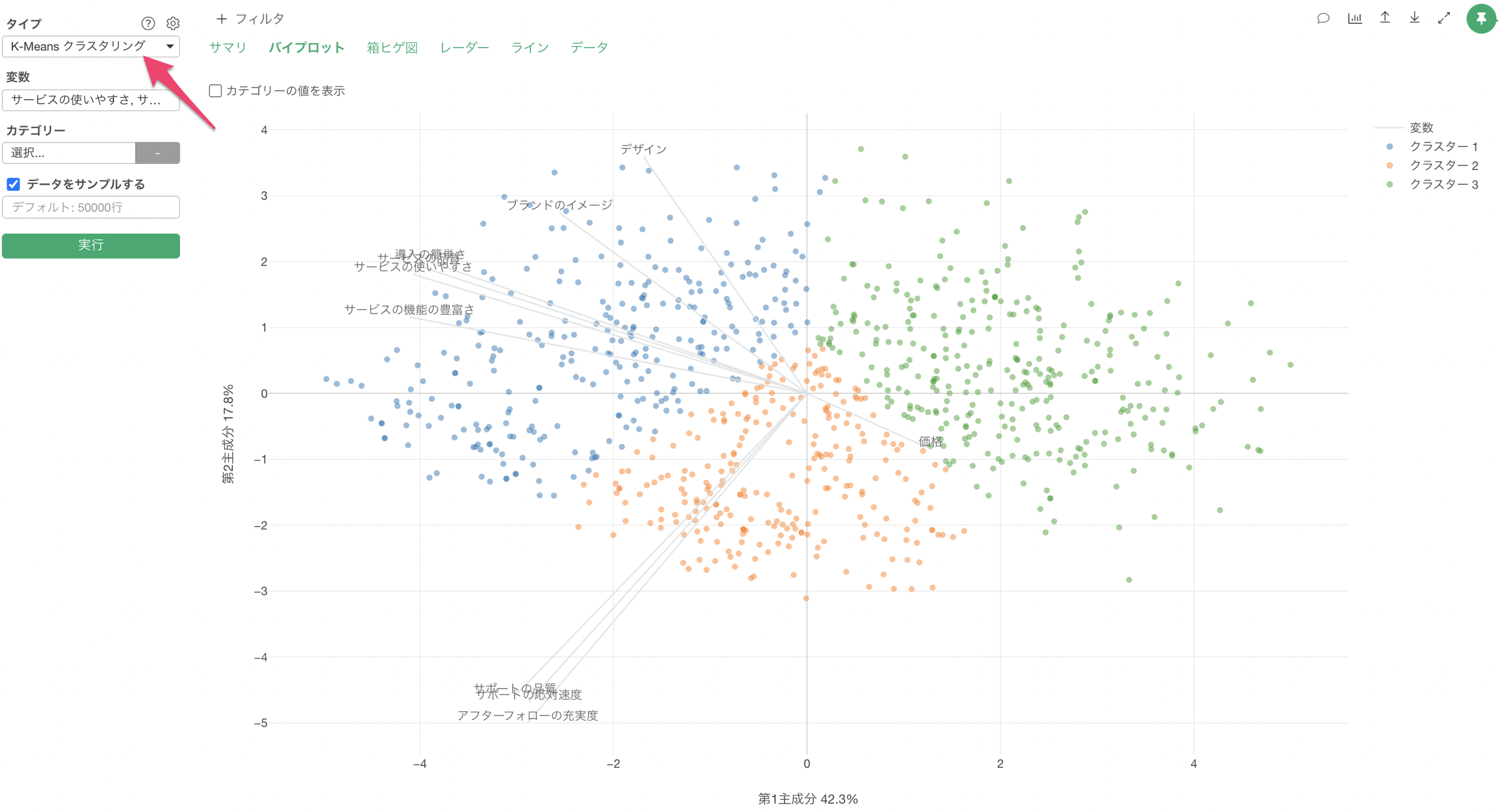
クラスタリングには様々なアルゴリズムがありますが、その中でもよく使われるのは「K-Means クラスタリング」というアルゴリズムです。
Exploratoryの場合は、アナリティクス・ビューの下で簡単に「K-Means クラスタリング」を実行することができ、様々なチャートによってクラスタリングの傾向を直感的に理解できます。
4. テキスト分析 - 単語のカウント
アンケートによくある質問のタイプの1つが「自由記述」です。
しかし、得られた自由記述の回答は、回答者が少ない場合は1つ1つ読んでいけますが、多い時には全体像がつかみにくいといった問題があります。

文章を「単語」に分けることで、それぞれの単語の頻出回数を集計(定量化)し、データの中にあるパターンや特徴を掴むことができるようになります。
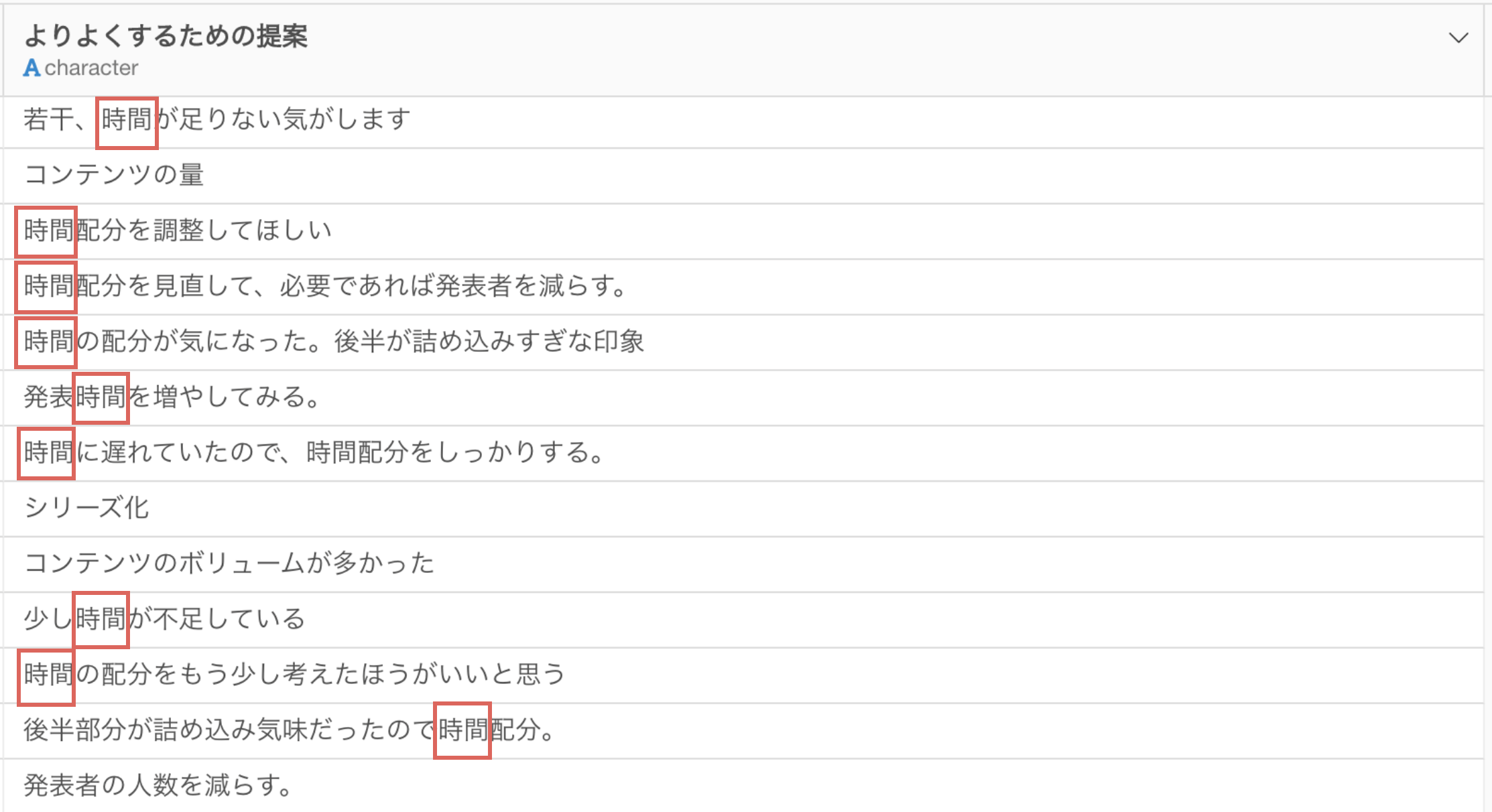
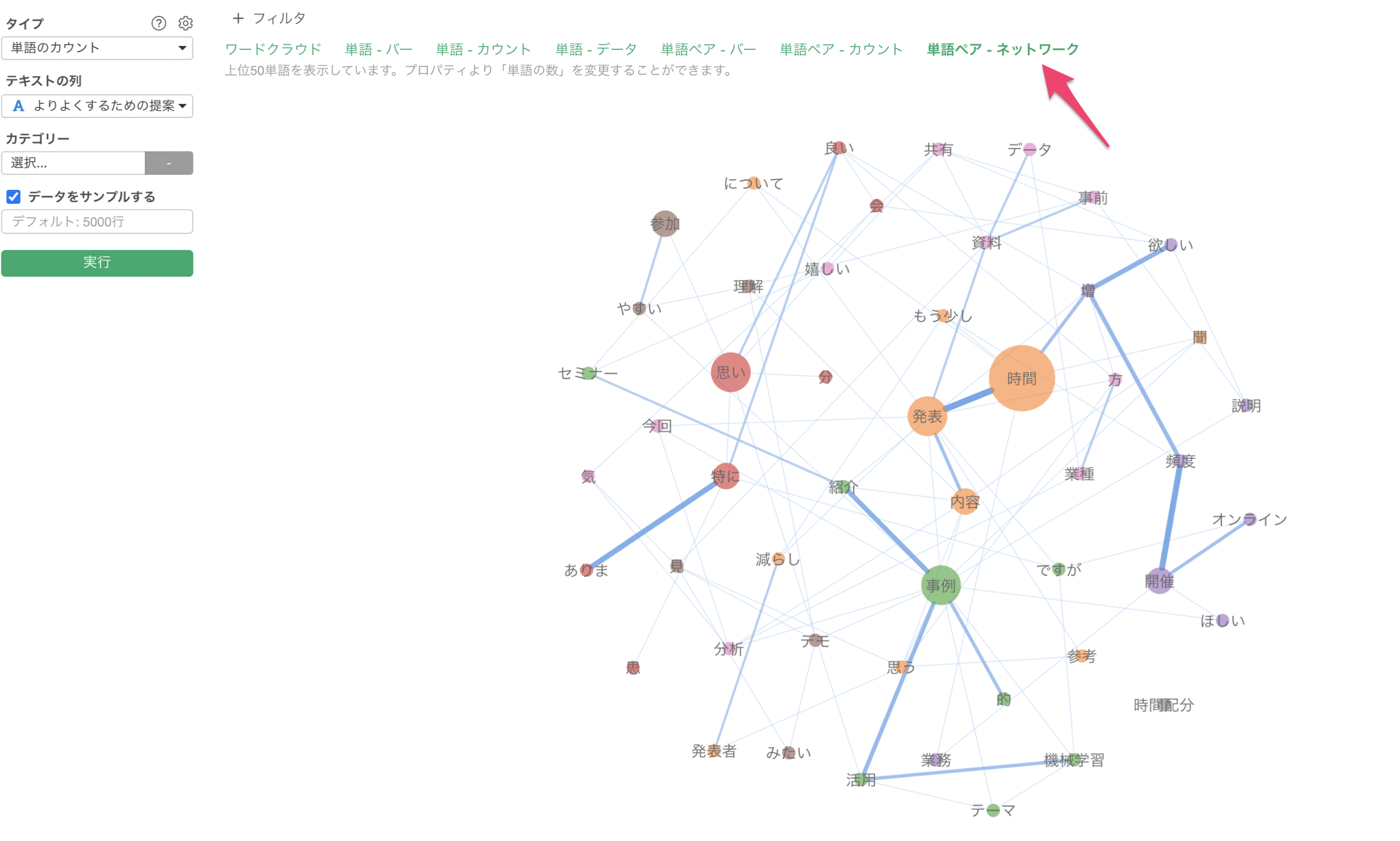
例えば、セミナーの参加者向けのアンケートがあった時に、下記のように「時間」といった単語がどれだけ出現しているのかを知ることで、アンケートの回答者が「時間」を気にしている人が多いのか(少ないのか)を比べていくことができます。
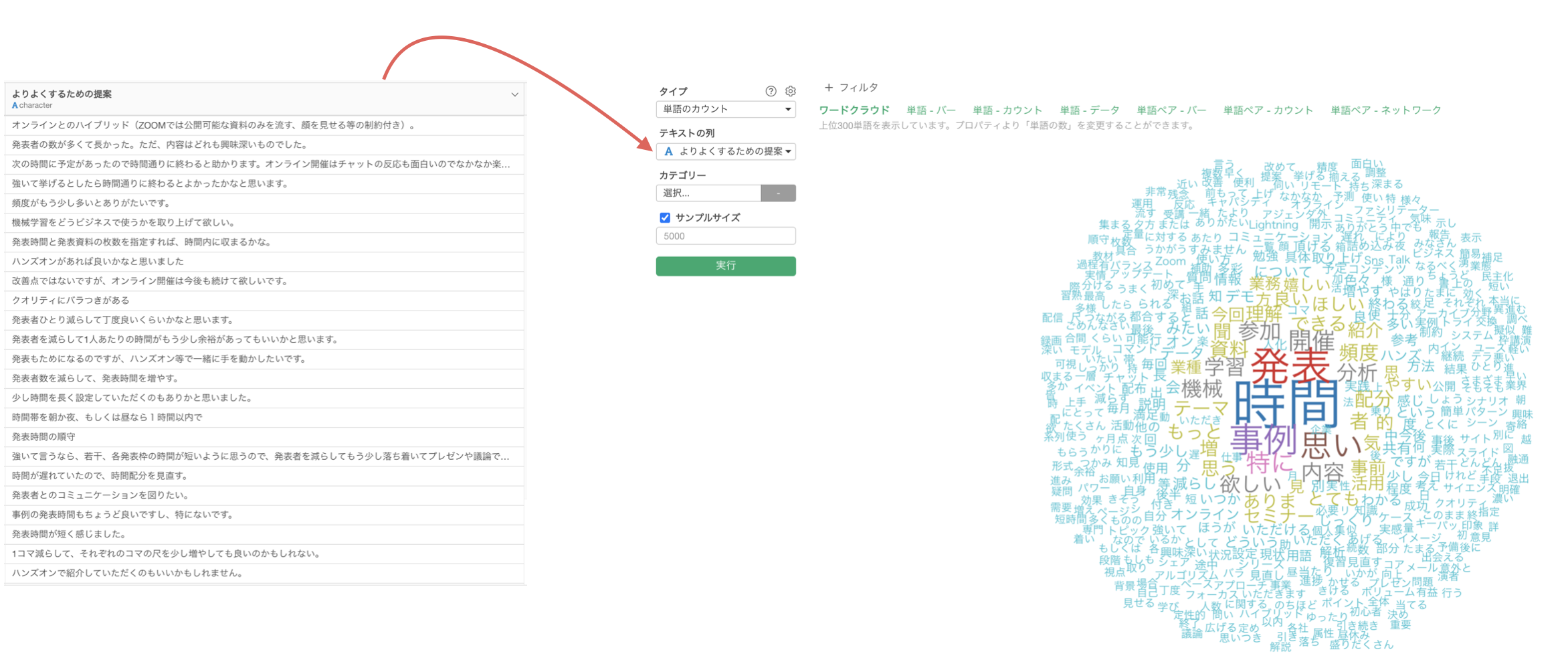
Exploratoryの場合、アナリティクス・ビューの下で「テキスト分析」を実行すると、文章が単語化されるだけでなく、ワードクラウドや共起ネットワークといったものを使って単語の使用頻度に関する傾向が直感的につかめるようになります。
ワードクラウド
共起ネットワーク
5. テキスト分析 - トピックモデル(LDA)
先ほどは「K-Meansクラスタリング」を使って、数値列を対象に回答者のグループ分けを行う方法を紹介しましたが、「自由記述」の回答をもとに、回答者をグループ分けできないでしょうか?

そこで使えるのが「トピックモデル」です。
「トピックモデル」を使うことで、自由記述の回答傾向をもとに回答者をいくつかのグループに分けることができます。
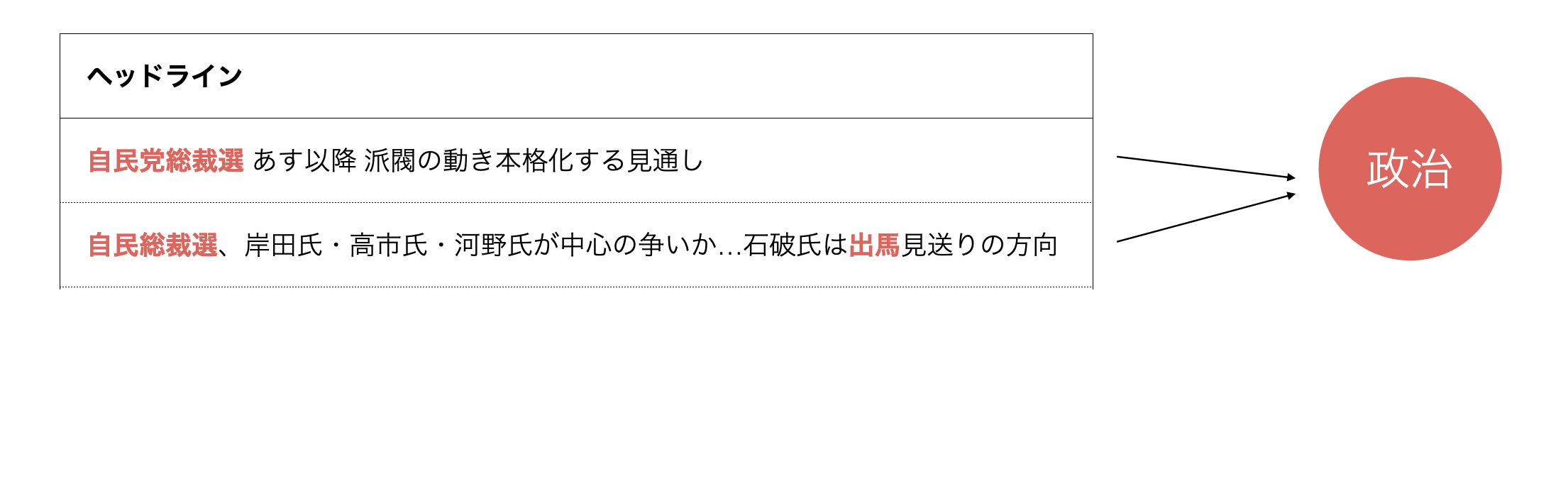
トピックモデルの概念をニュースのヘッドラインの文章を例にみていきましょう。
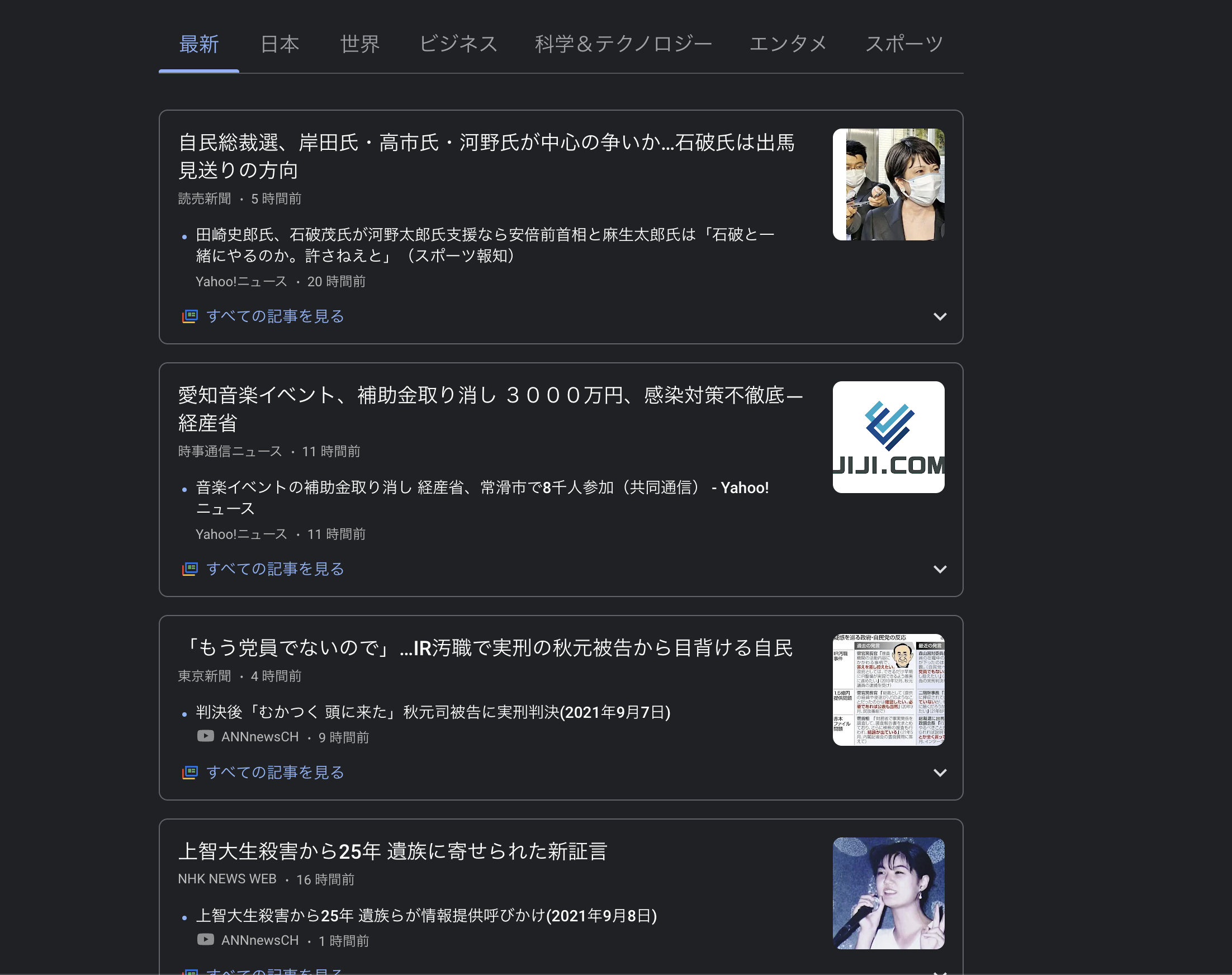
これらの文章は「政治」のトピックだと言えます。
この文章は「スポーツ」に関する文章だと言えます。

「スポーツ」か「政治」かどちらかではなく、両方に属するというものも存在します。

最終的には、それぞれの文章に含まれる単語の使用傾向をもとに、いくつかのトピックを抽出していくことができます。

そして、それぞれの文章ごとにそのトピックに属する確率が求められます。

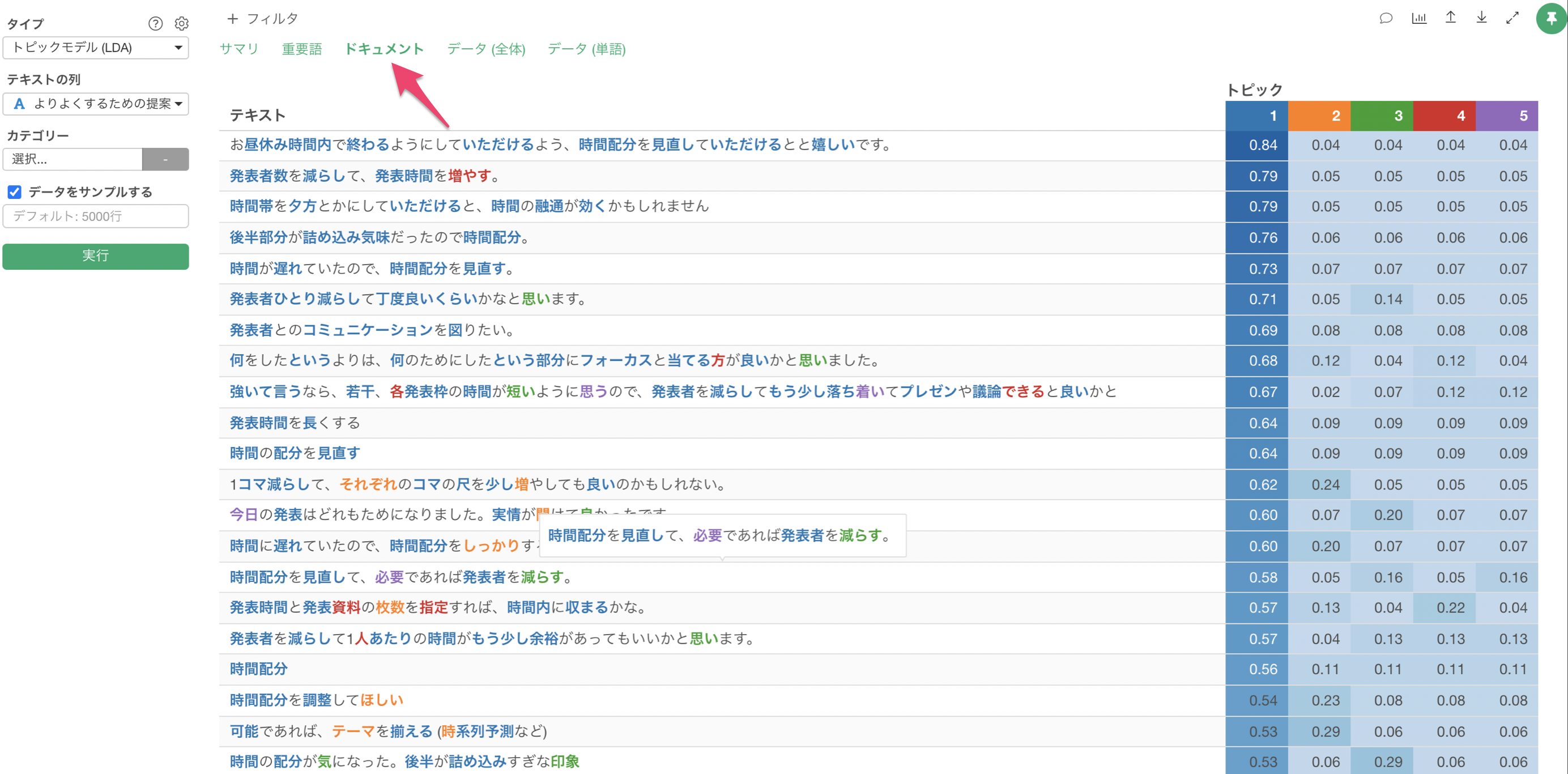
Exploratoryの場合は、アナリティクス・ビューの下で「トピックモデル(LDA)」を選び、「自由記述」の列を選択することで簡単にトピックモデルを実行することができます。
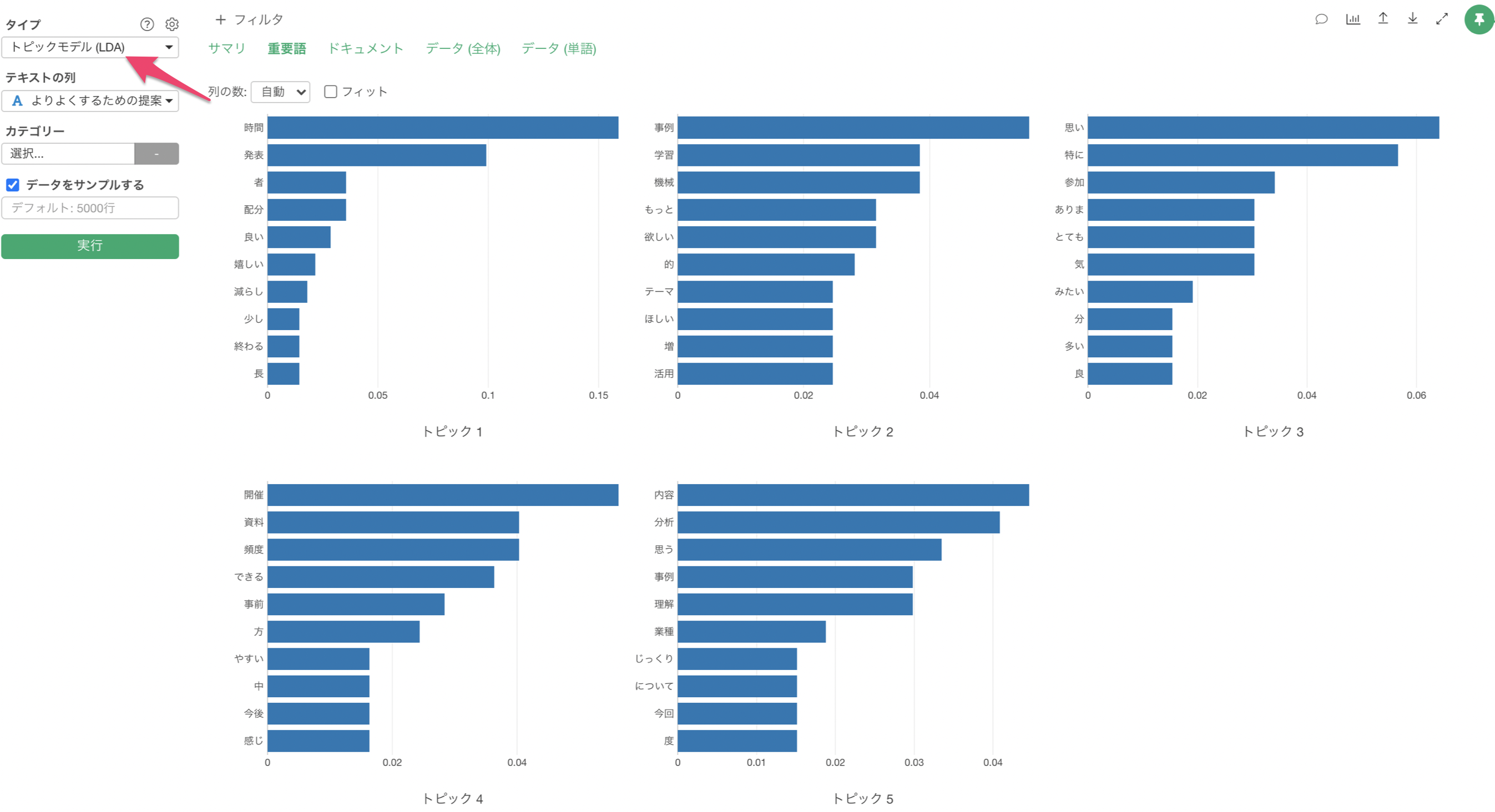
「ドキュメント」タブを使うことで、それぞれのトピックの確率が高い文章を確認することができ、どういった文章がグループ分けされているのかを簡単に解釈していくことができます。
セミナーの録画
こちらの記事で紹介した分析手法を、Exploratoryを使ったデモを交えながら紹介するセミナーを過去に行いましたが、そちらの録画があります。興味のある方はぜひご覧ください!
実務で使えるスキルを身に着けたい!

今回紹介したようなアンケートデータの分析に役立つ分析手法、さらにアンケートデータに特有なデータ加工の問題の解決方法などをもっと深く学び、さらに現場で使えるレベルのスキルを身に着けたいという方は、アンケートデータの加工と分析に特化したトレーニングを用意しておりますので、ぜひご検討いただければと思います。
自分のデータで試してみたい!
記事内の全てのチャートは、データの加工、可視化、分析、レポーティングのためのUIツールのExploratoryを利用して作成しています。
ご自身のデータを使って、これらのチャートを作成したり、データの分析をしたい方は、下記のページより無料トライアルが可能ですので、ぜひ、お試しください!