今回は、アンケートの自由記述の回答からどの単語がよく使われるのかを調べる方法について簡単に紹介します。
アンケートによくある質問のタイプの1つが「自由記述」です。自由記述の回答は、5段階評価などでは得られない、より詳細な情報を得ることができます。
例えば、セミナーを定期的に開催していて、セミナーを改善するためのヒントを得るために、アンケートを取っていたとしましょう。
また、具体的な改善点を模索するために、「より良くするための提案」といった自由記述の回答を得ていたとします。
しかし、自由記述の回答は、回答者が少ない場合は1つ1つ読んでいくことができますが、多い時には全体像が掴みにくいといった問題があります。

全てのデータを見ることは現実的には難しいため、このままのデータではよりインパクトのある文章に印象を引っ張られてしまい、どこを優先的に改善すればいいのかのヒントを得ることが難しくなってしまいます。

そういった時に、文章を「単語」に分けることで、それぞれの単語の出現回数を集計(定量化)し、データの中にあるパターンや特徴を掴むことができるようになります。
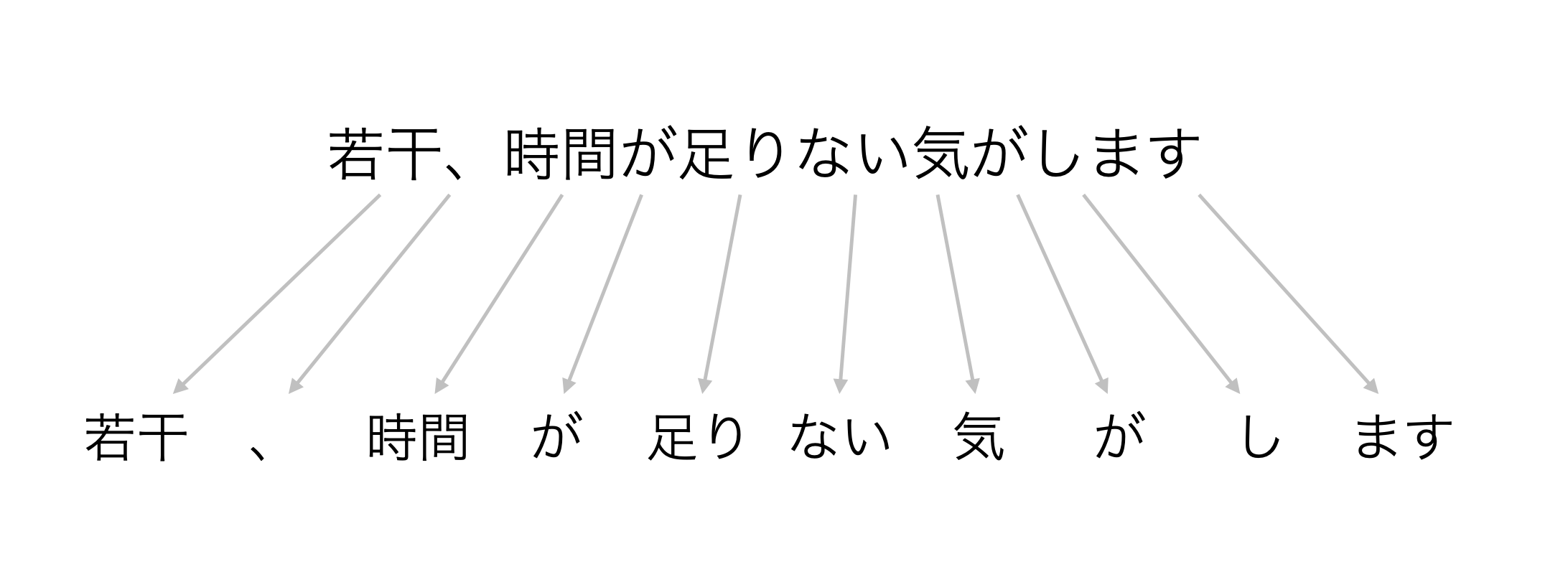
例えば、下記のように「時間」といった単語がどれだけ出現しているのかを知ることで、アンケートの回答者が「時間」を気にしている人が多いのか(少ないのか)を比べていくことができます。
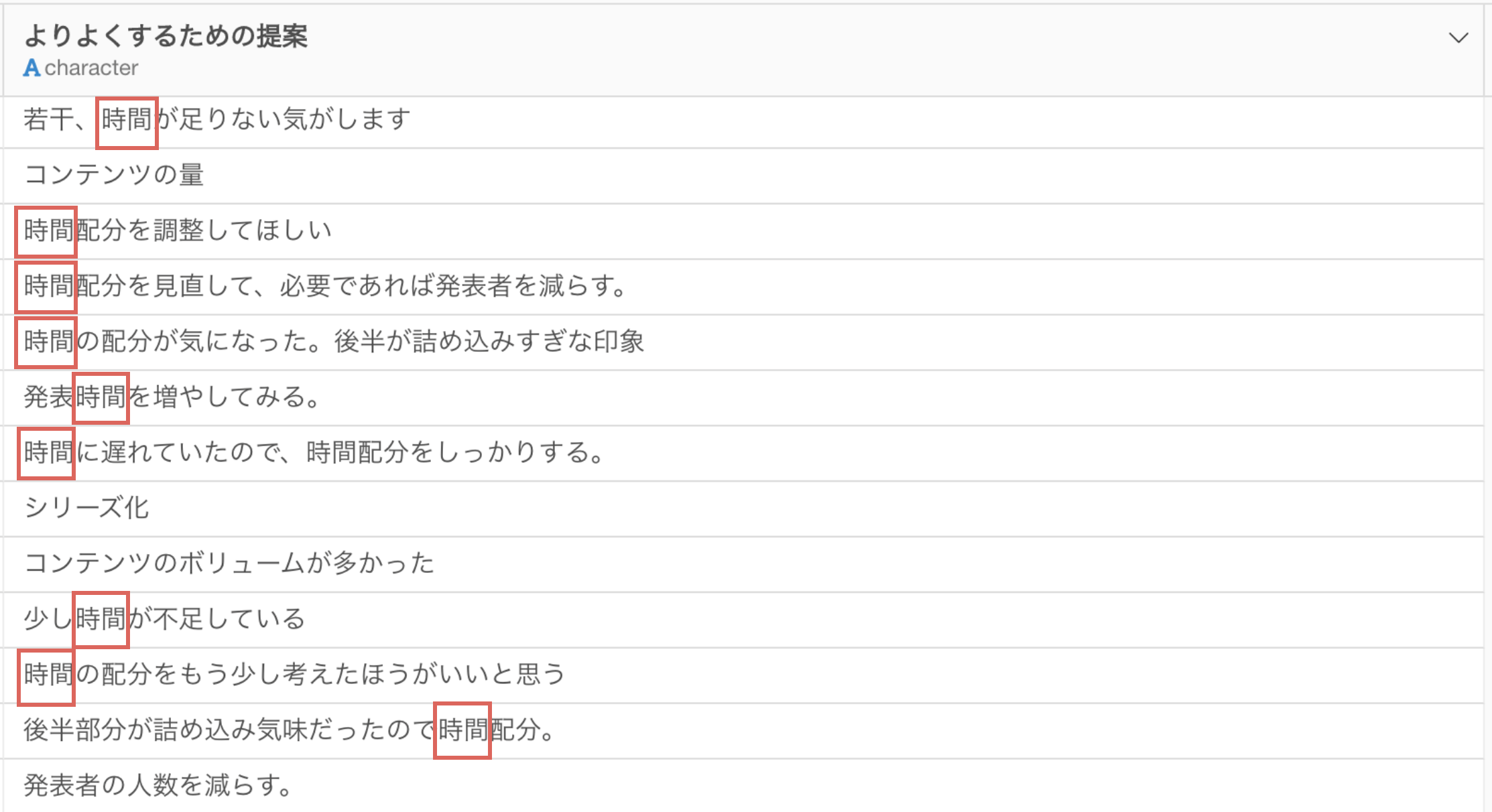
実際に単語化した際のそれぞれの出現回数は以下となりますが、「時間」や「事例」といった単語の出現回数が多いために、これらを優先的に解決することでより満足度を高めやすくなるのではないかと考えることができます。
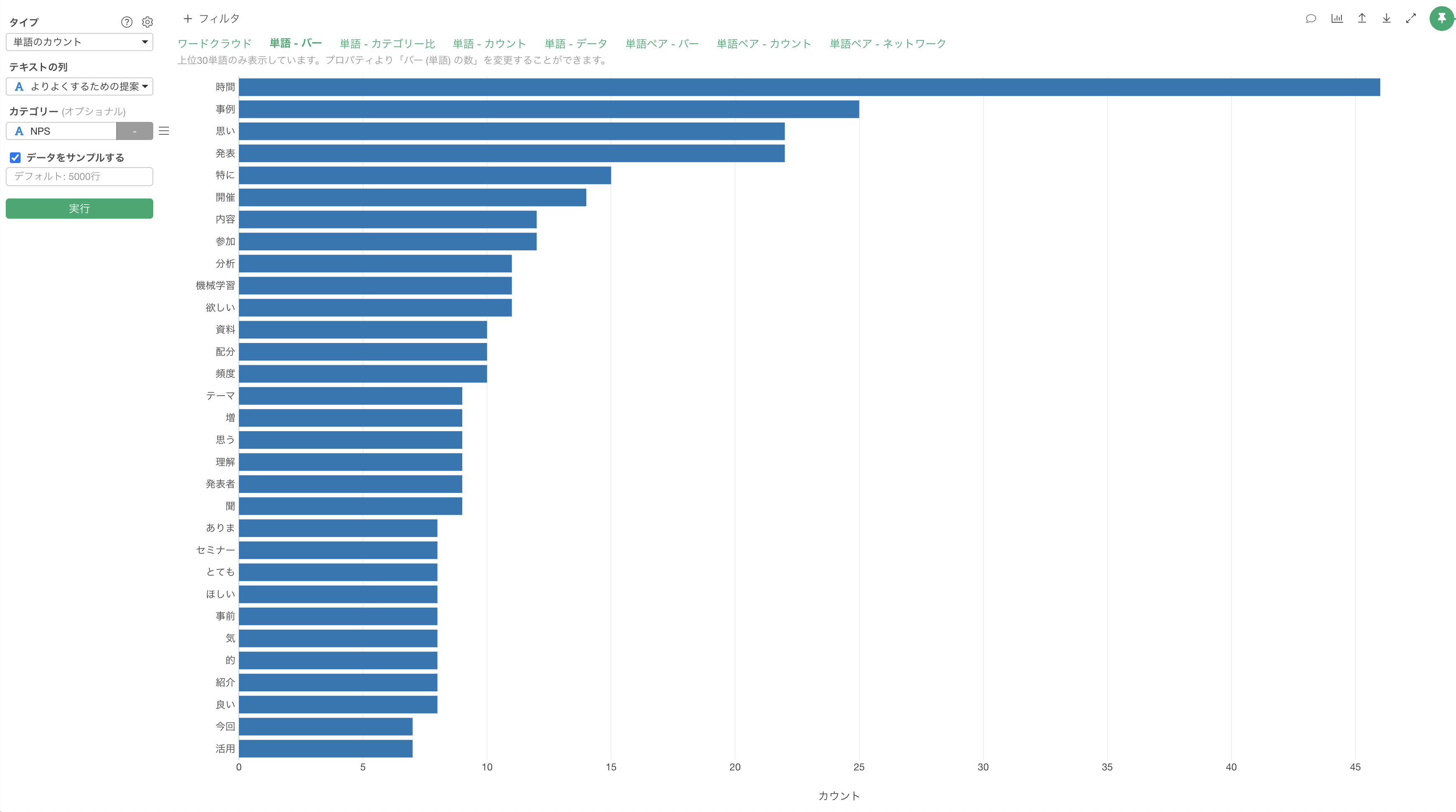
RではRMecabなどを用いて文章の単語化ができますが、Exploratoryの場合、アナリティクス・ビューにある「テキスト分析 - 単語のカウント」にて簡単に単語化できます。
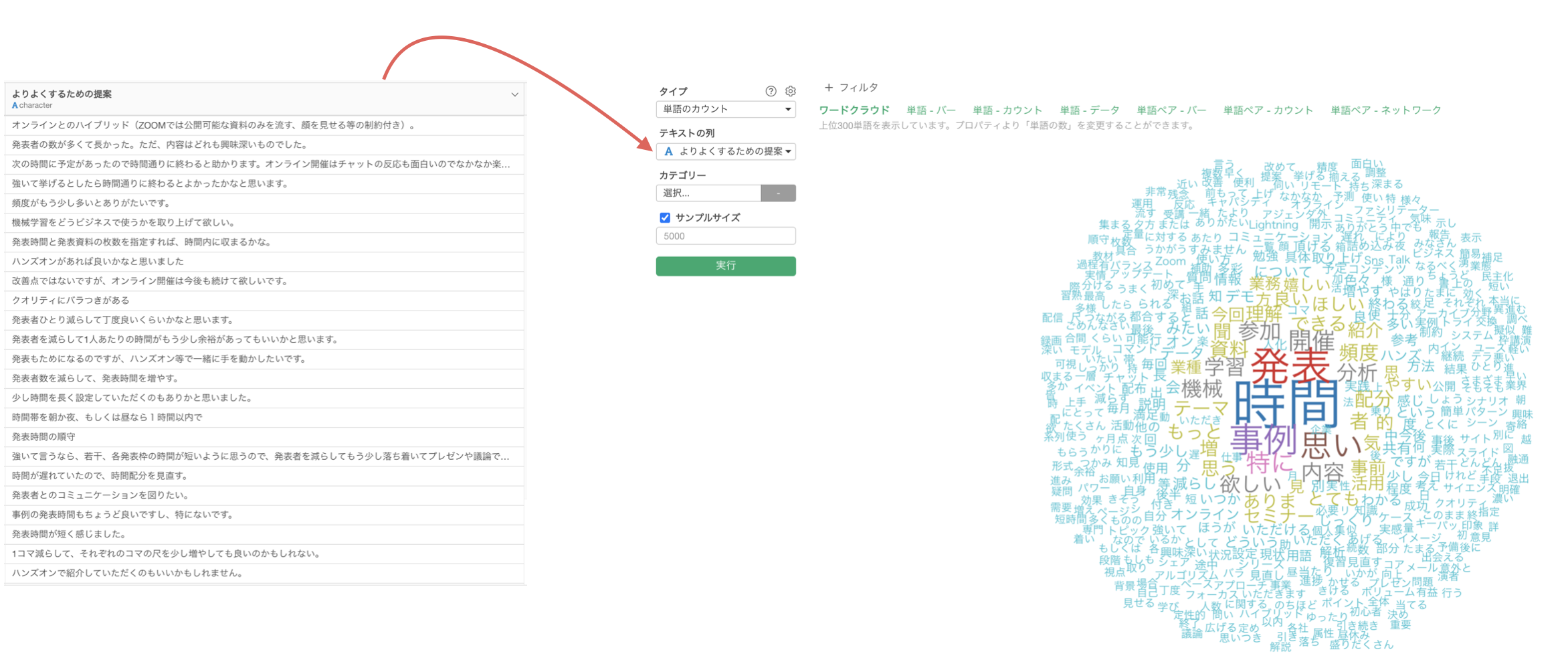
さらには、文章が単語化されるだけでなく、ワードクラウドや共起ネットワークといったものを使って単語の使用頻度に関する傾向が直感的につかめるようになります。
ワードクラウド

共起ネットワーク
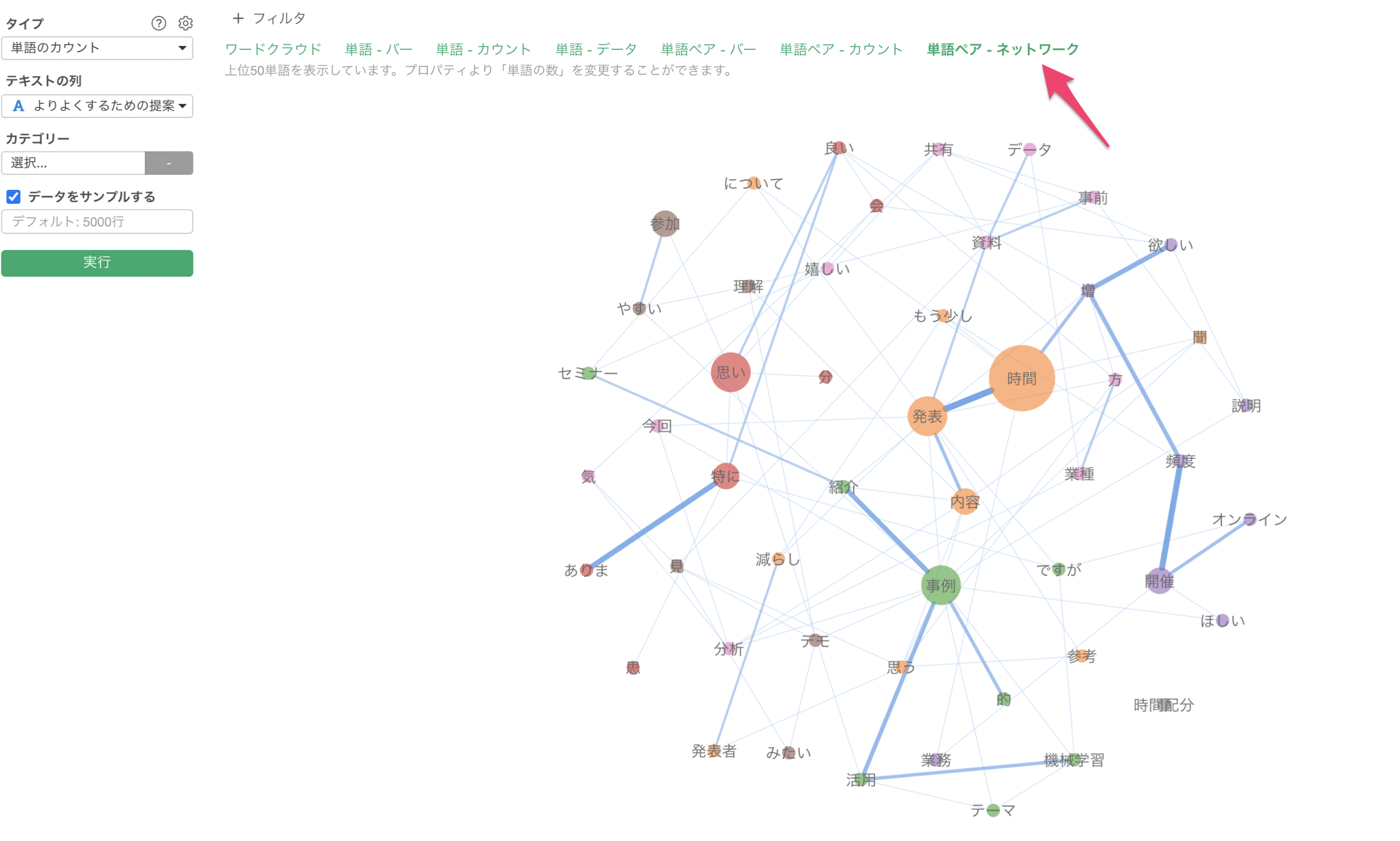
最後に、アンケートの自由記述の回答はプロダクトやサービスなどを改善するために有益な情報ですが、使いこなせていないのが現状です。
そこで、文章を単語化して定量データとして扱うことで、何を優先的に見るべきかのヒントを得られますので、今回の記事の例が皆様のアンケートデータを活用していくうえでご参考になれば幸いです!
実務で使えるスキルを身に着けたい!

今回紹介したようなアンケートデータの分析に役立つ分析手法、さらにアンケートデータに特有なデータ加工の問題の解決方法などをもっと深く学び、さらに現場で使えるレベルのスキルを身に着けたいという方は、アンケートデータの加工と分析に特化したトレーニングを用意しておりますので、ぜひご検討いただければと思います。
自分のデータで試してみたい!
記事内の全てのチャートは、データの加工、可視化、分析、レポーティングのためのUIツールのExploratoryを利用して作成しています。
ご自身のデータを使って、これらのチャートを作成したり、データの分析をしたい方は、下記のページより無料トライアルが可能ですので、ぜひ、お試しください!