「アンケートはしてみたものの、得られた回答データを有効に活用できていない。」というのは多くの組織が抱えている悩みです。
せっかくアンケートデータを集めたが、ただ平均値を計算して比べたり、自由記述の回答を読んだりするだけで、ビジネスやサービスの改善に向けた具体的なアクションに導くことができない、というのはよくある話です。
そこで、アンケートデータの有効に活用するための3つのポイントを記事としてまとめました。
データの持ち方
アンケートデータを収集した際に、データの持ち方には下記の2つのパターンがよくあるかと思います。
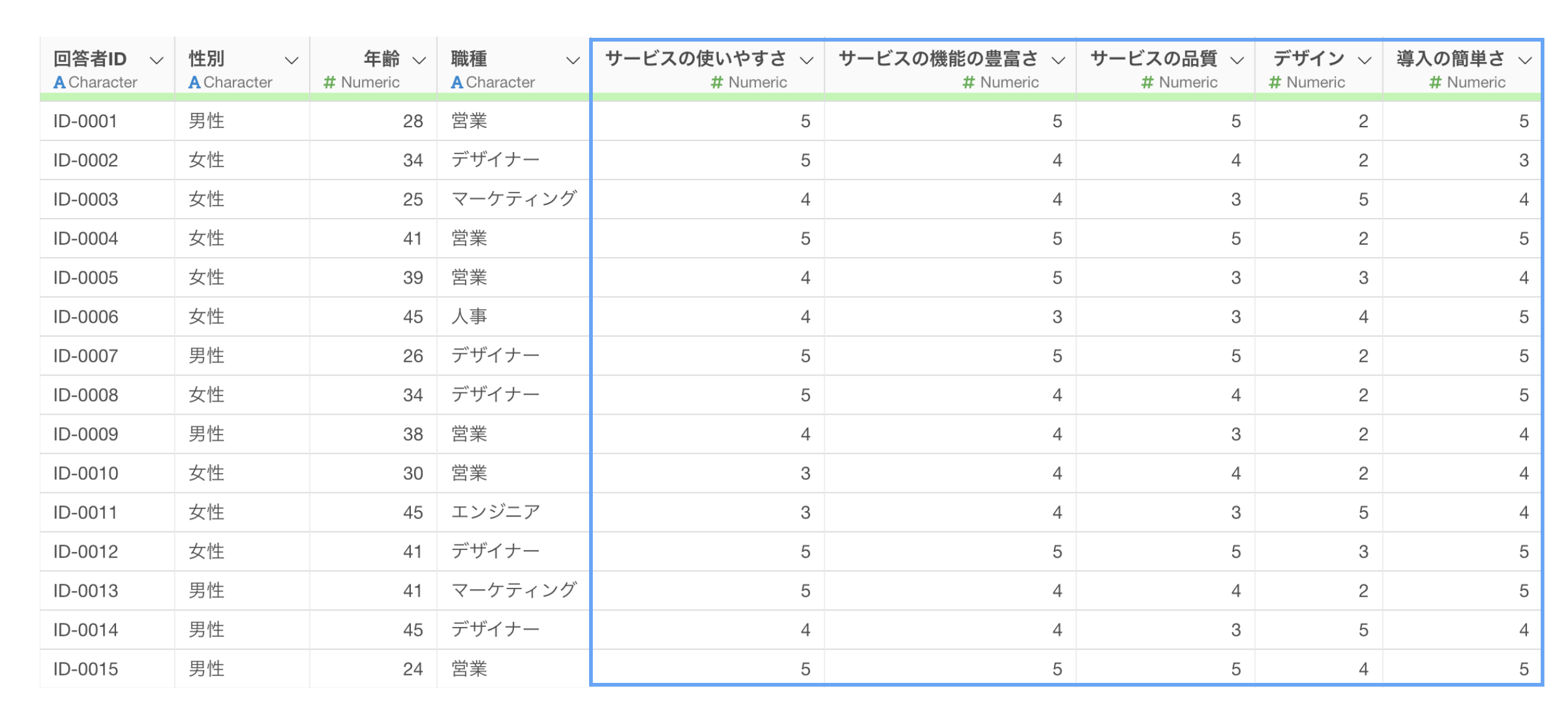
1行1回答者で列に質問項目があるデータ
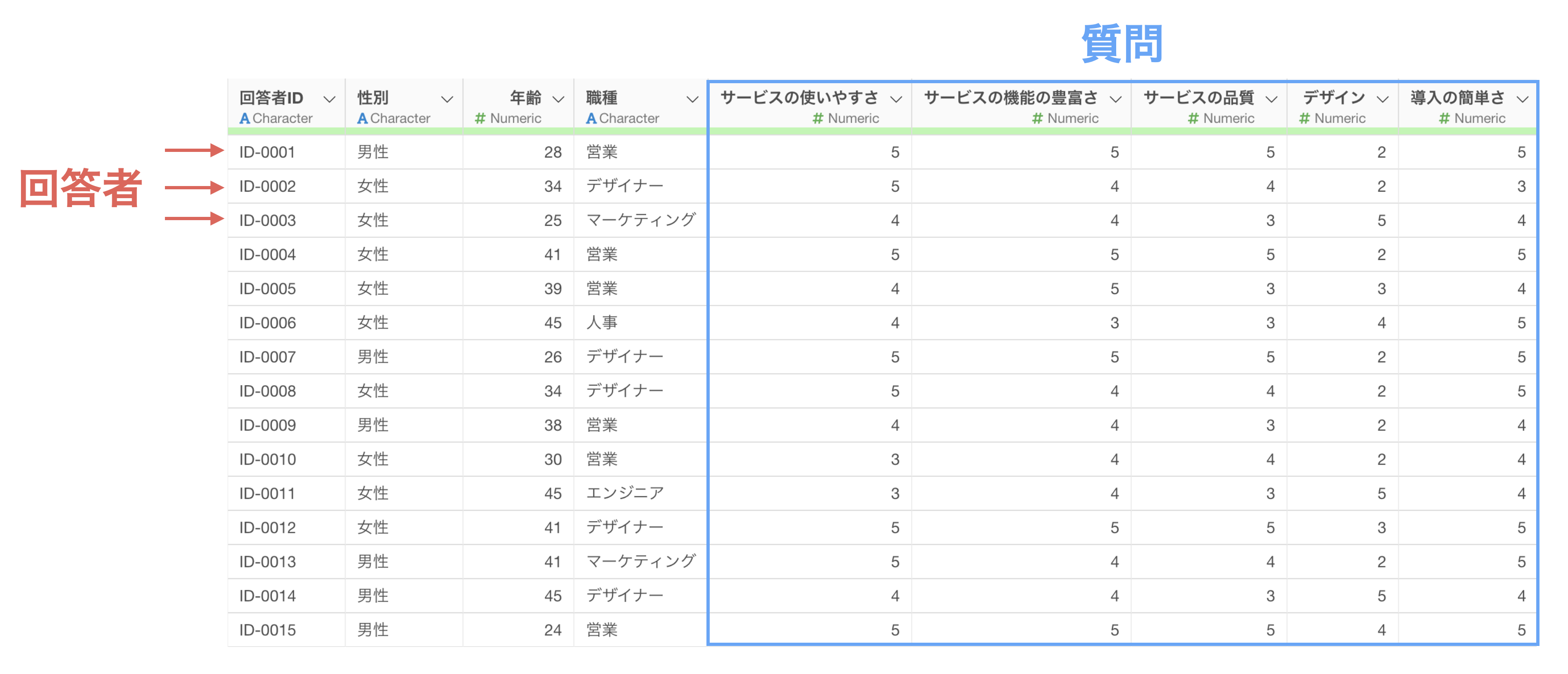
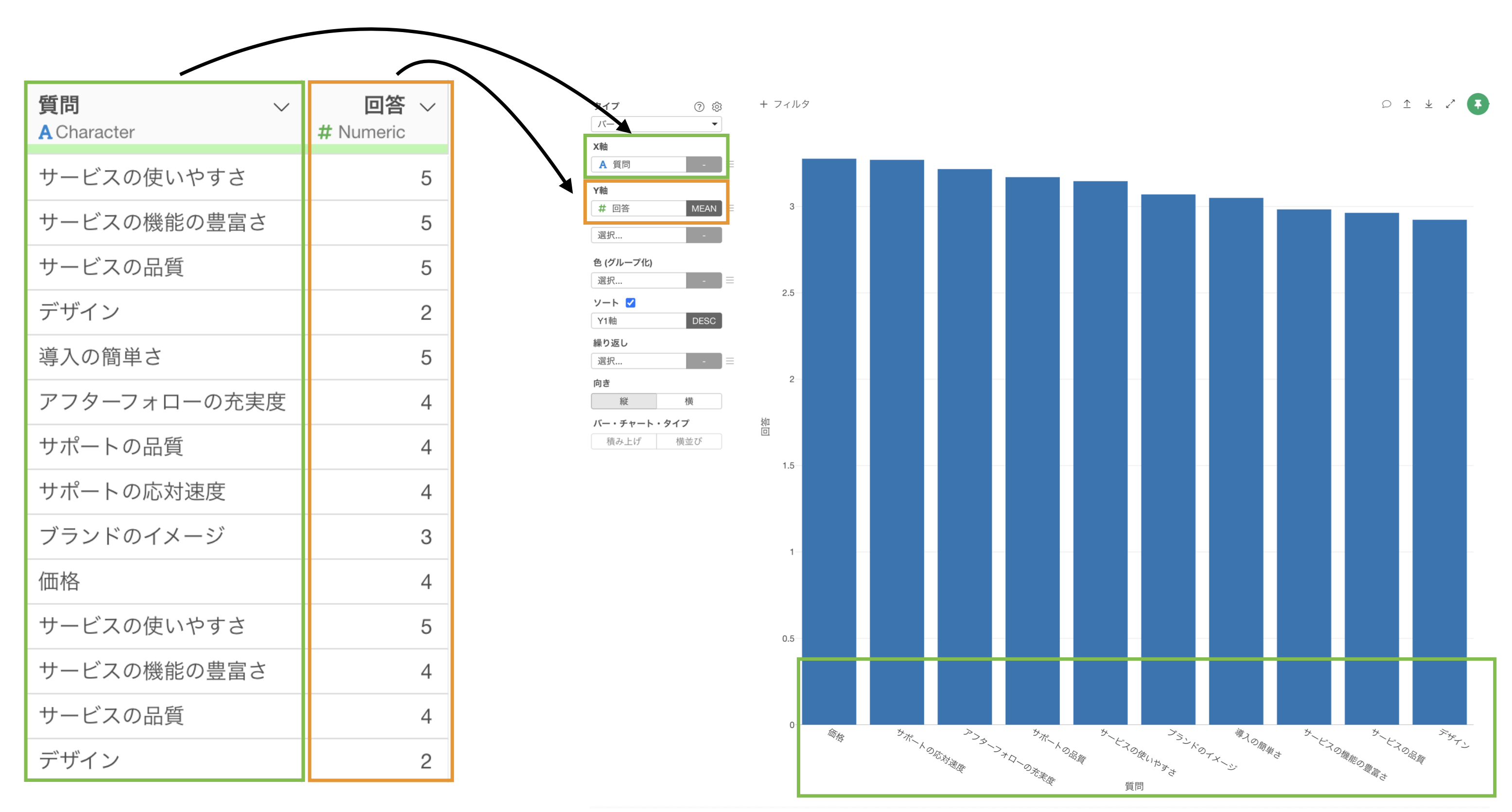
質問と回答をそれぞれ1つの列にまとめたデータ

アンケートデータではよく、現状を把握するために「データを可視化」したり、質問項目どうしの関係性を分析するために「相関分析」や「因子分析」、または回答者傾向を調べるための「K-Means」クラスタリングが使われます。
一方で、取得したデータがそのままの状態で「可視化」や「分析」に適したデータの形になっていることはありません。
というのも、「可視化」や「分析」にはそれぞれ適したデータの形があるからです。
例えば、可視化の場合は質問ごとに回答の平均値を可視化する、といったことがよく行われます。
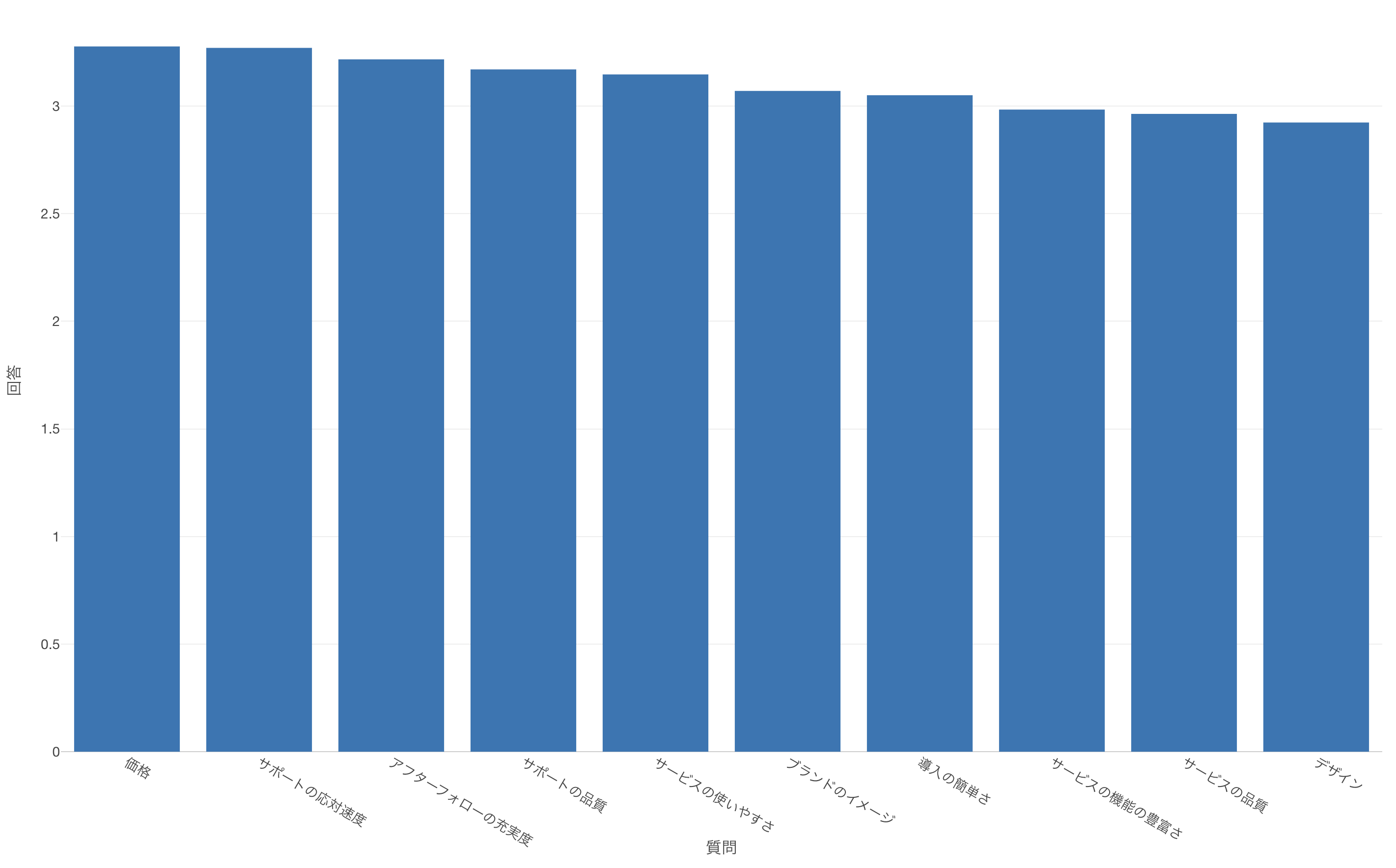
その際に、横軸(X軸)、縦軸(Y軸)に質問と回答の列を割り当てていく必要があるのですが、質問が列ごとに分かれてしまっては横軸(X軸)に質問の列を割り当てることができません。
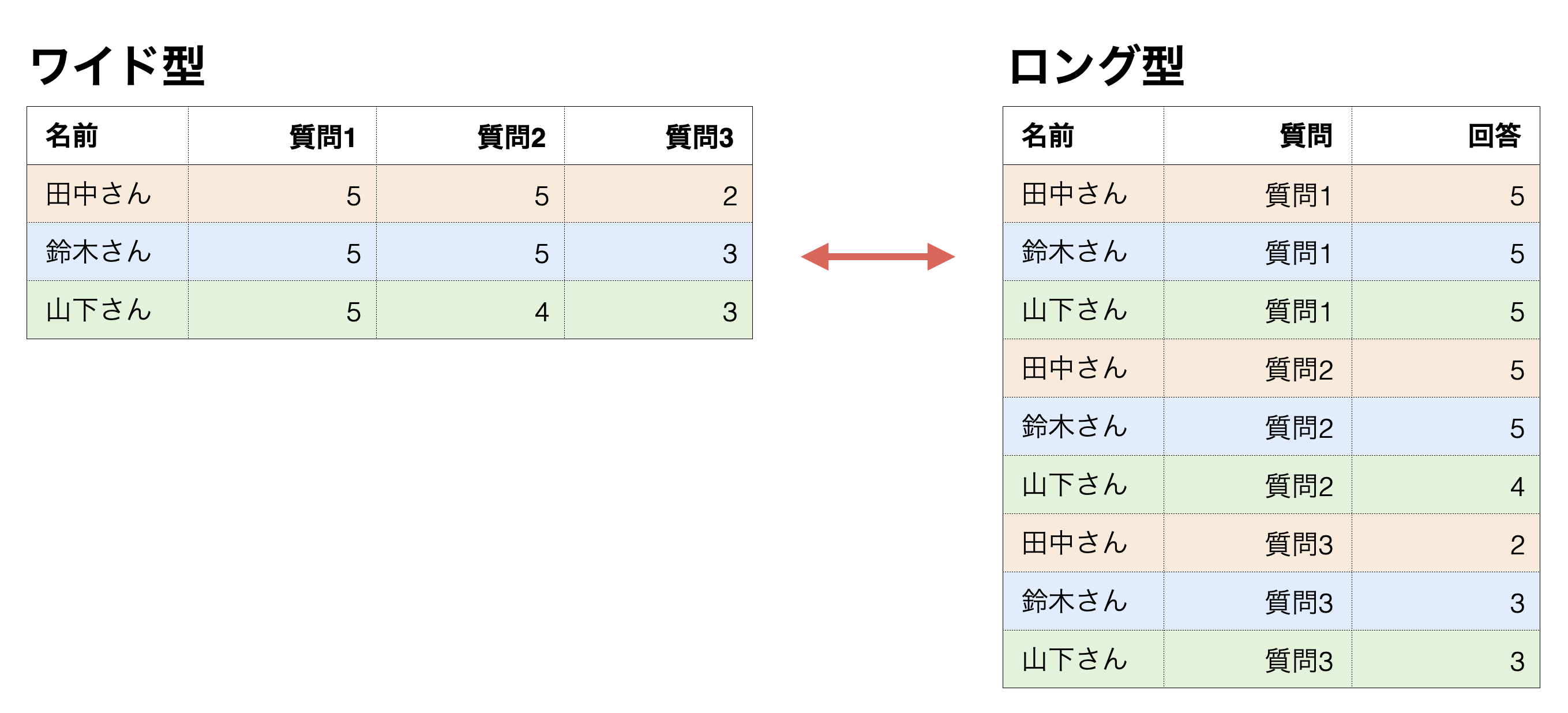
そこで、質問と回答をそれぞれ列にまとめた、いわゆるロング型のデータが適しています。
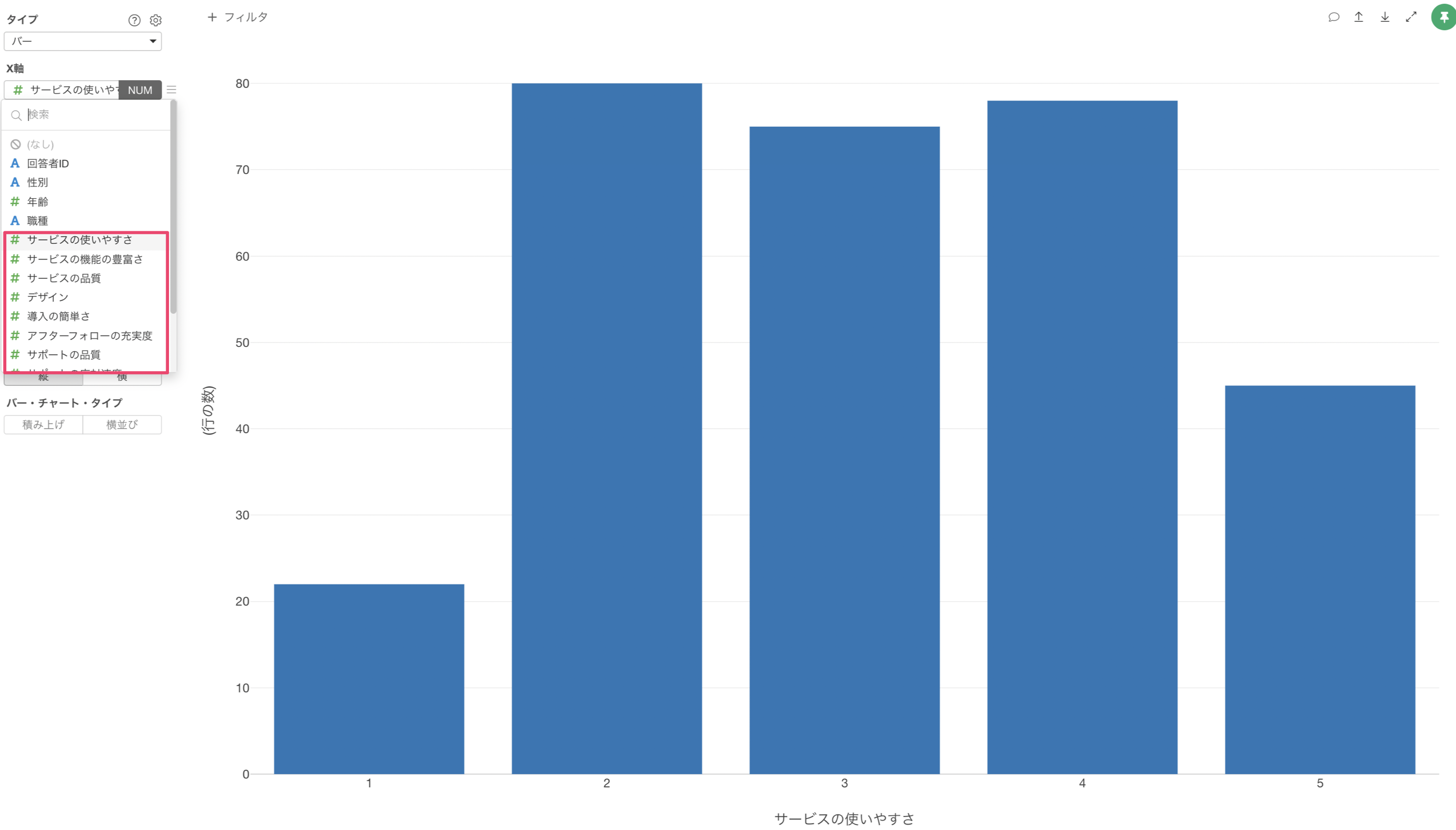
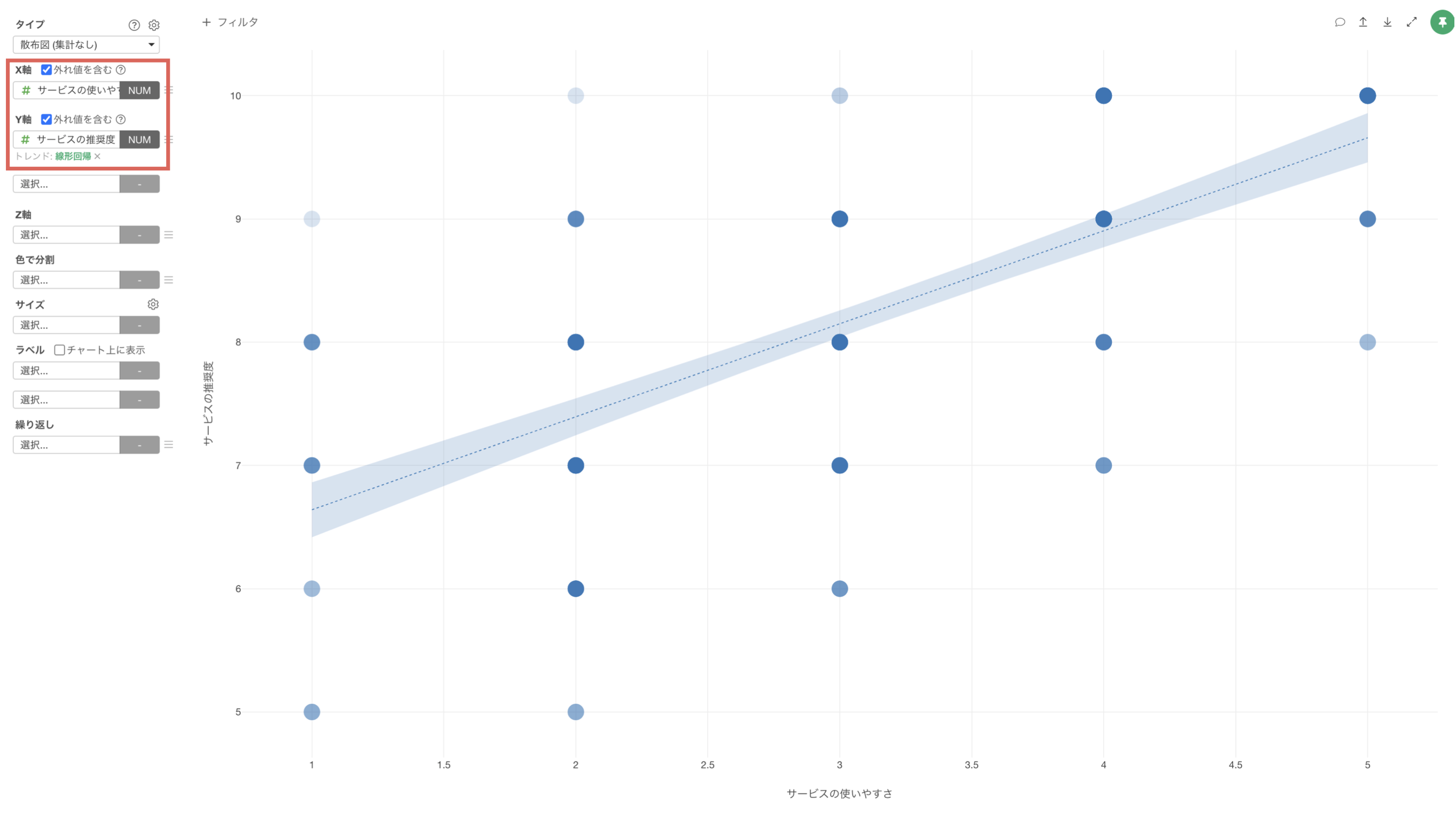
一方で、相関分析などでは、1行1回答者で列に質問項目があるワイド型のデータが適しています。
ワイド型のデータの場合、横軸(X軸)、縦軸(Y軸)にそれぞれの質問の回答の列を割り当てることで、2つの列の相関関係を分析していくことができます。
つまり、アンケートデータを扱っていくにあたって、目的に合わせて「データの持ち方」を柔軟に変えていく必要があります。
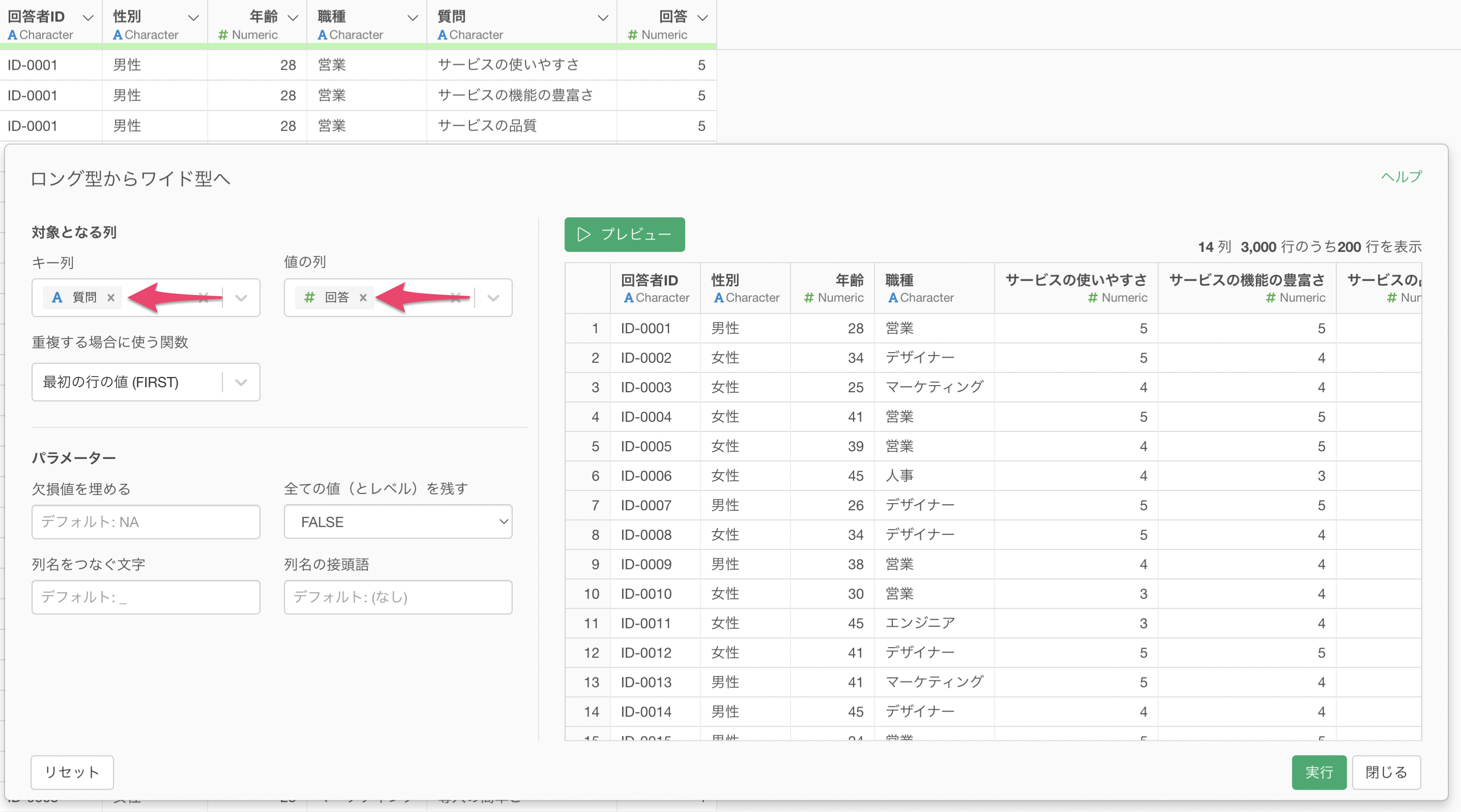
Exploratoryでは、アンケートデータの持ち方をワイド型、ロング型を柔軟に変えていくことが可能です。
その違いは意味のある違いと言えるのか?
アンケートデータを可視化をした際に、下記のように性別ごとにサービスの満足度の平均値に違いがあったとします。
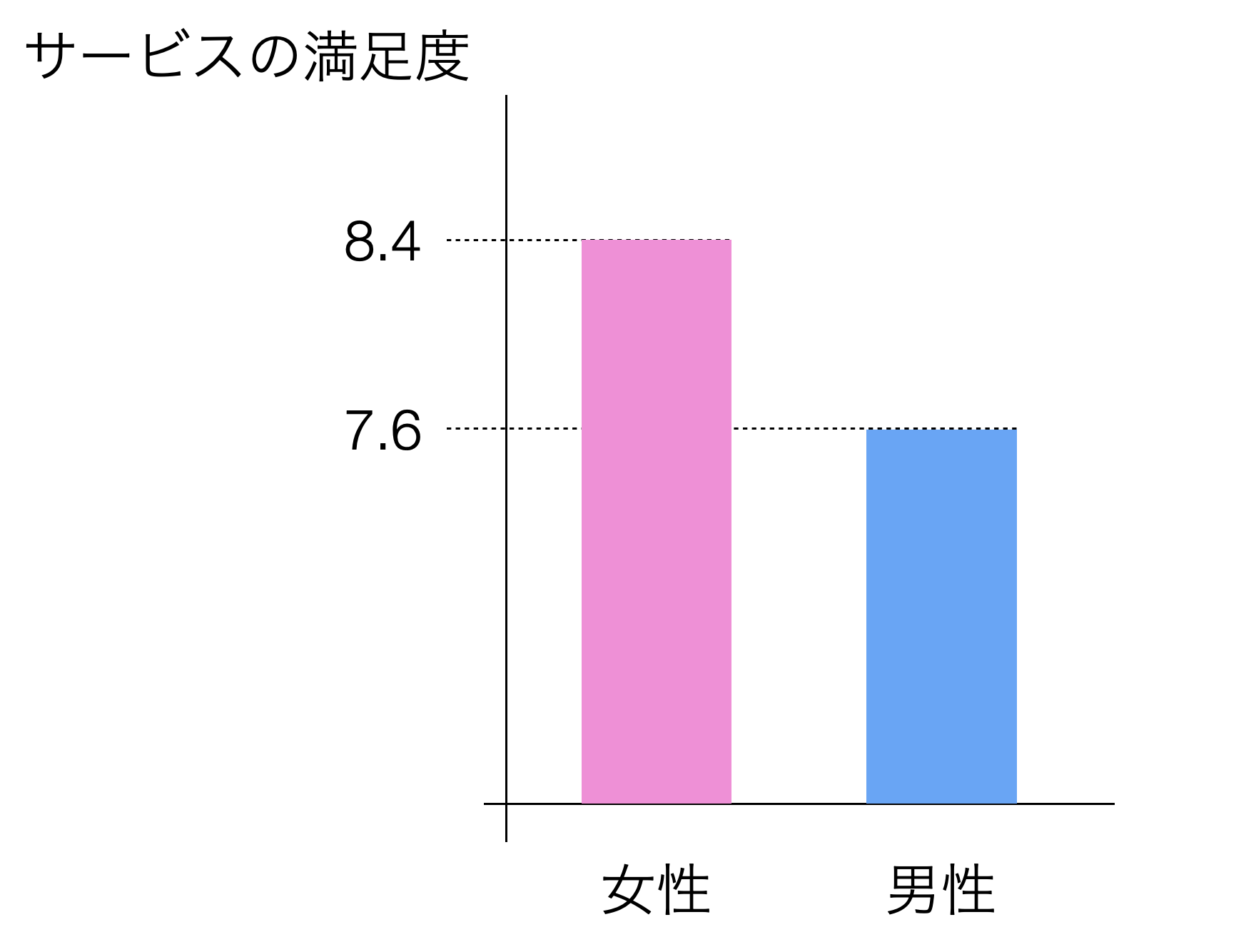
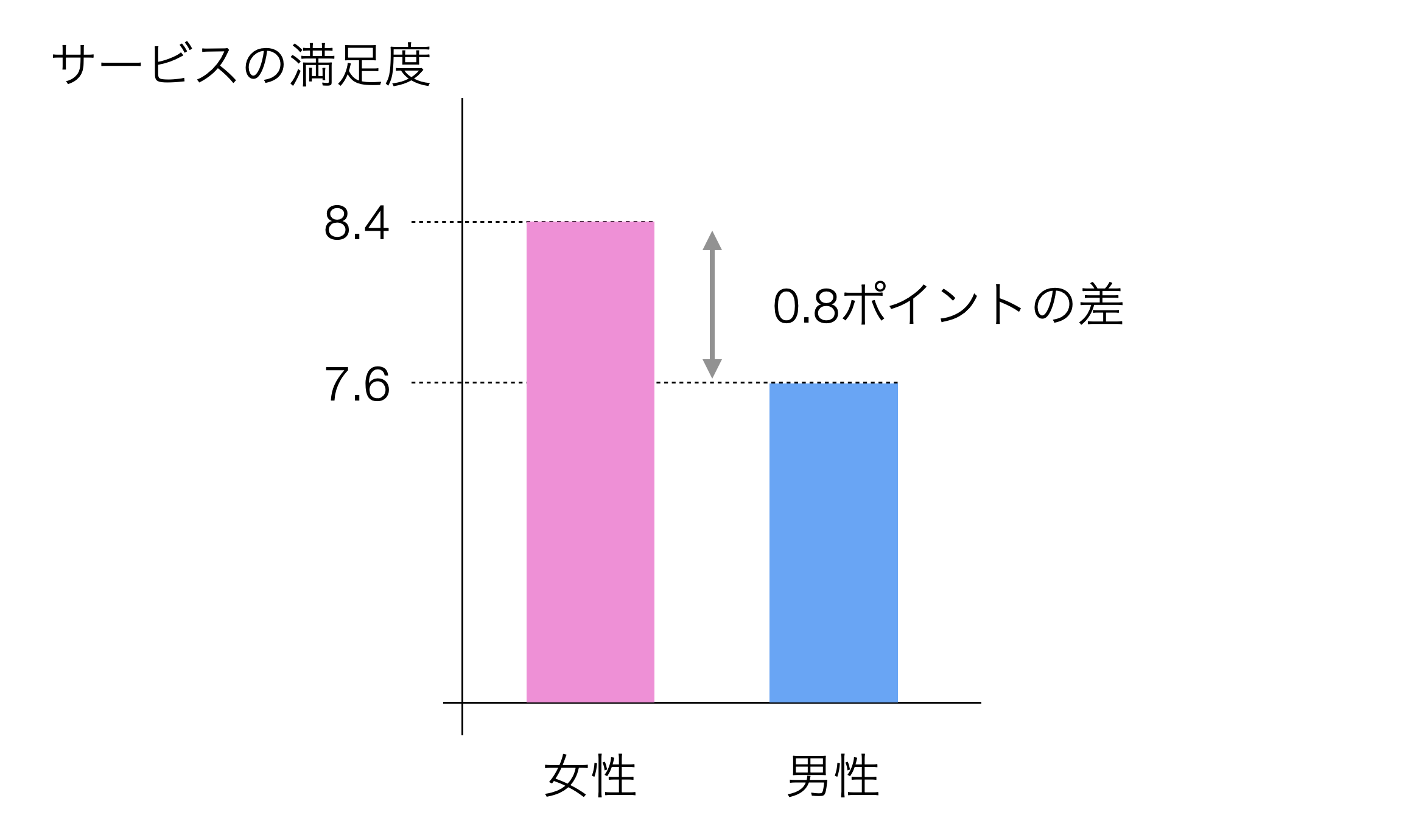
両者の平均値には0.8の差があったため、女性の方が男性よりも良いと結論づけてしまって良いのでしょうか?
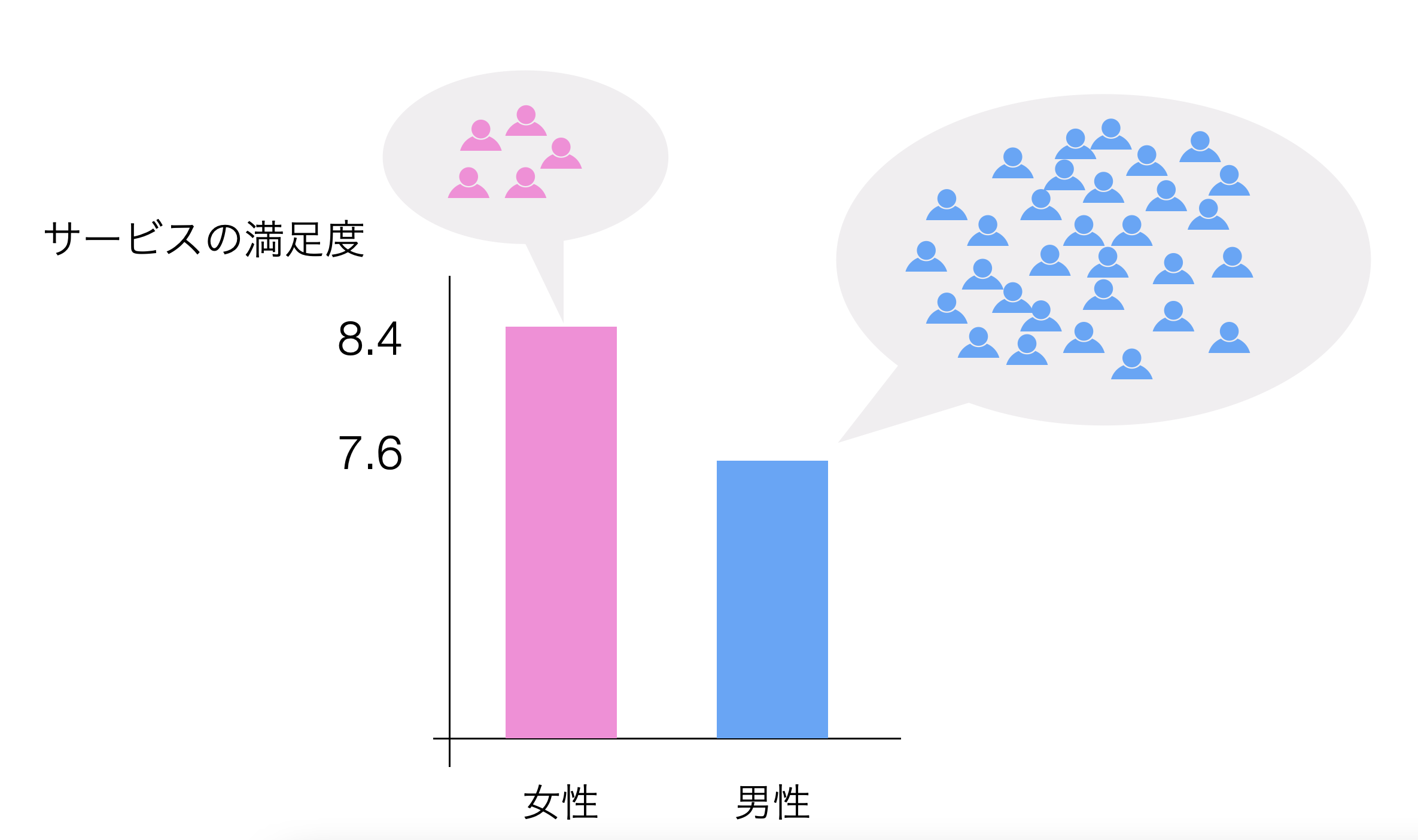
というのも、女性は男性よりも回答者が少ない場合があります。(逆のケースもある)
平均値は、データの数が少なければちょっとした変化に敏感になるために、値がぶれやすいという特徴があります。例えば、回答者のうち一人が値が低かったら男性と同等の平均値になる、ということもあり得ます。
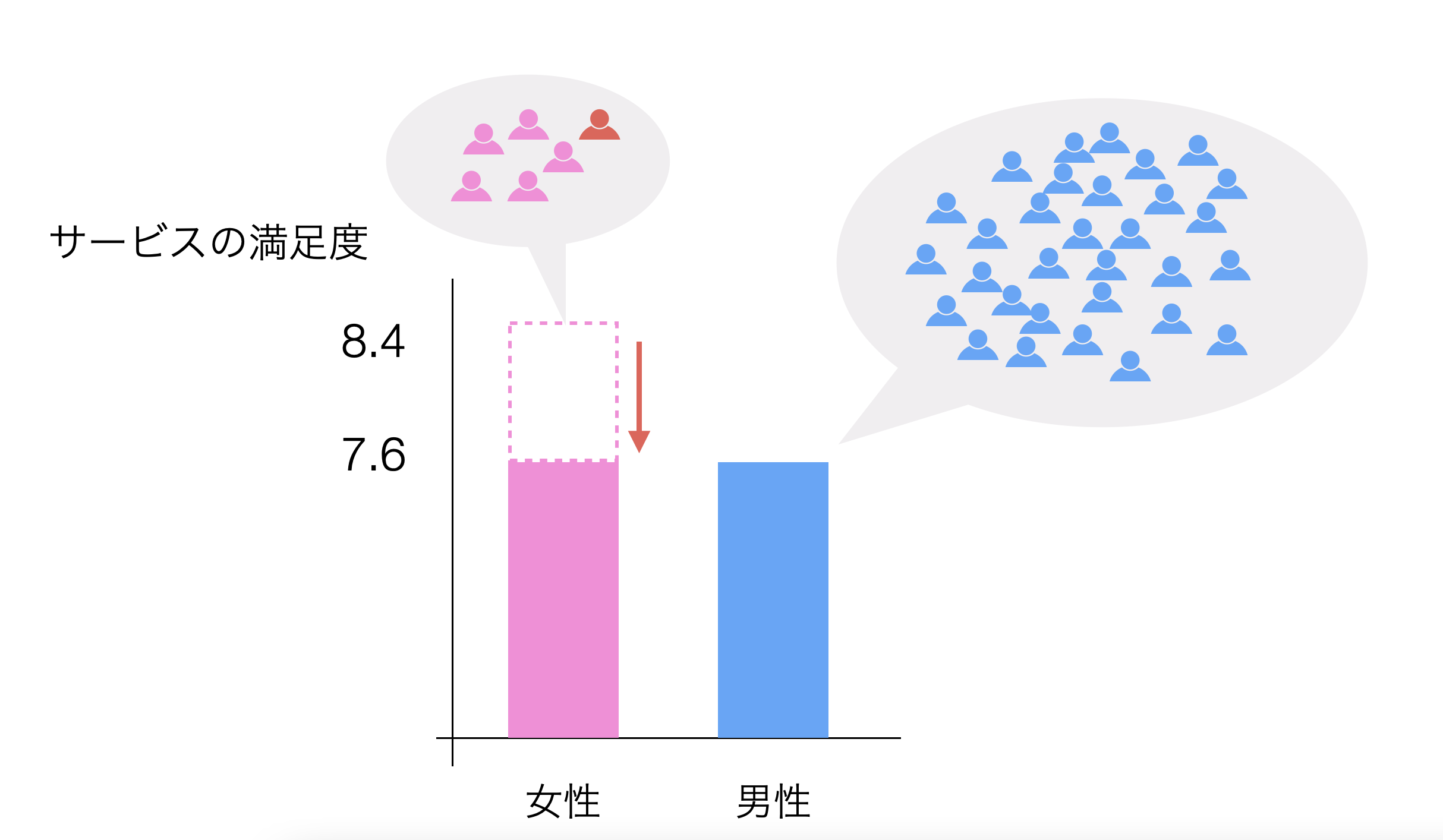
そのため、平均値だけを見ていても、本当に違いがあったのかどうか、自信を持って判断していくことができません。
そこで使えるのが信頼区間です。
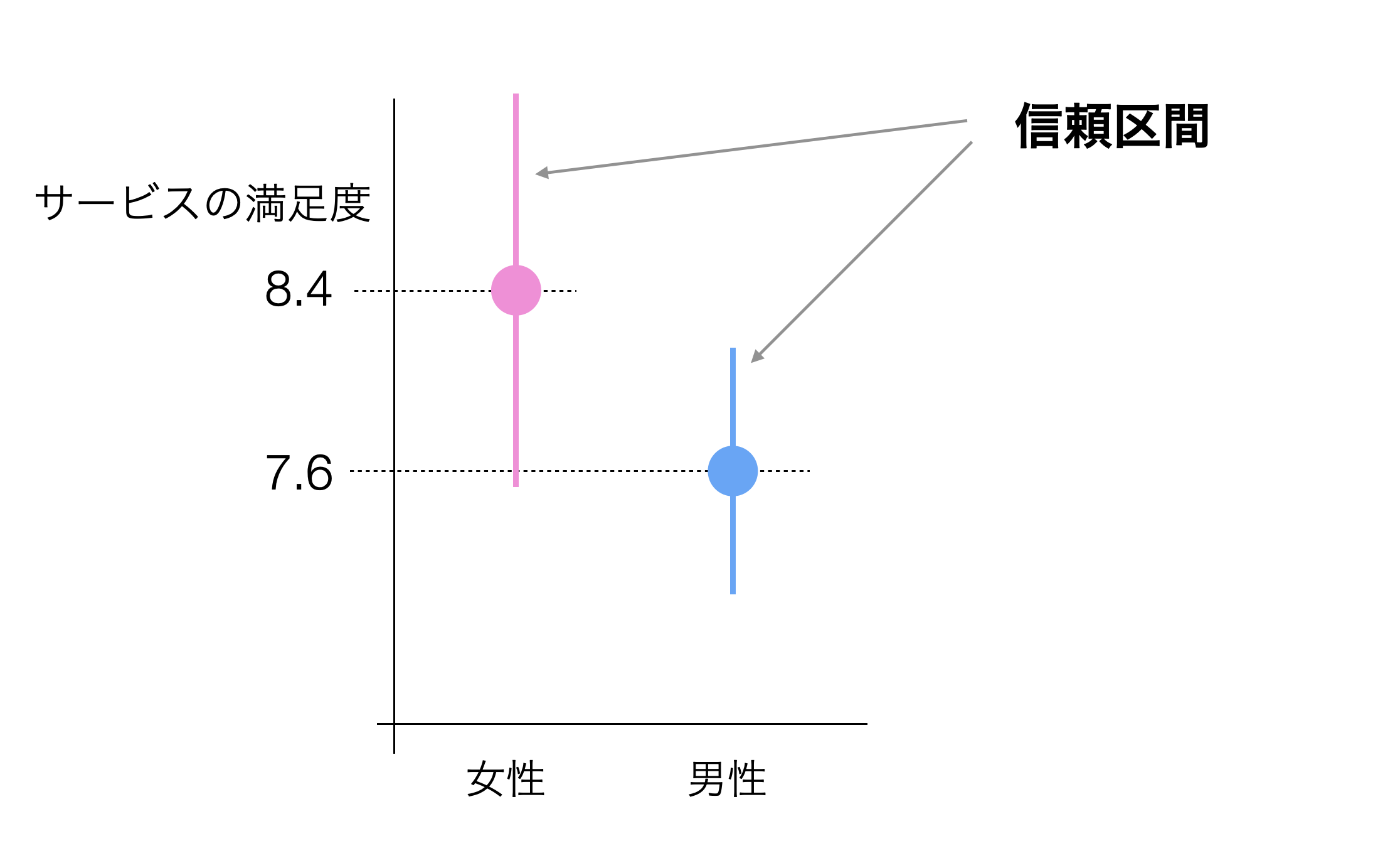
信頼区間は、手元のデータから母集団の真の平均値を推測したものです。
これを使うと何が嬉しいか、というとその2つの平均値の違いが意味のある違いなのか、有意な違いと言えるのかを判断するために使えるといった点です。
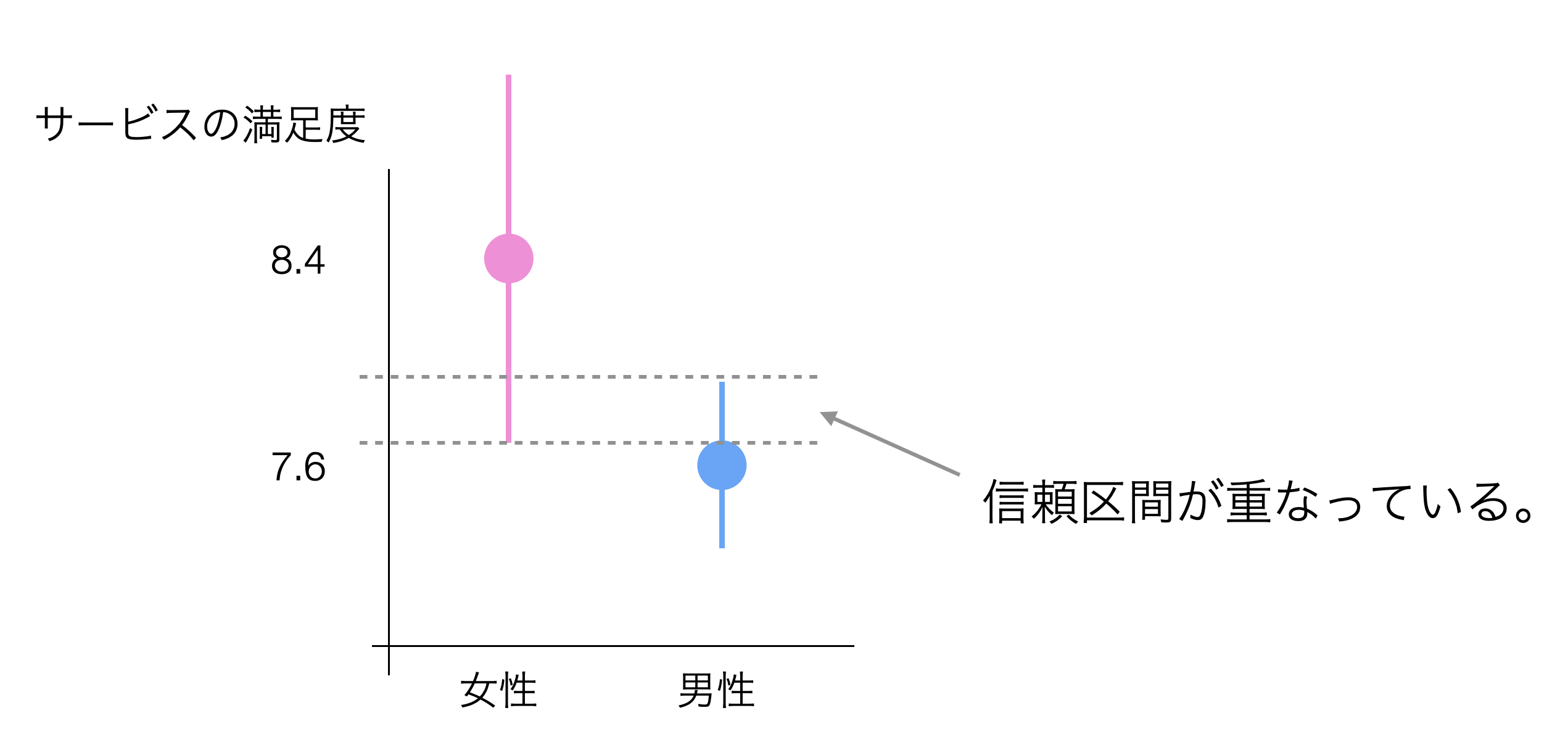
もし信頼区間が重なっている場合は、女性と男性のサービスの満足度の平均値に有意な違いはないという結論になります。
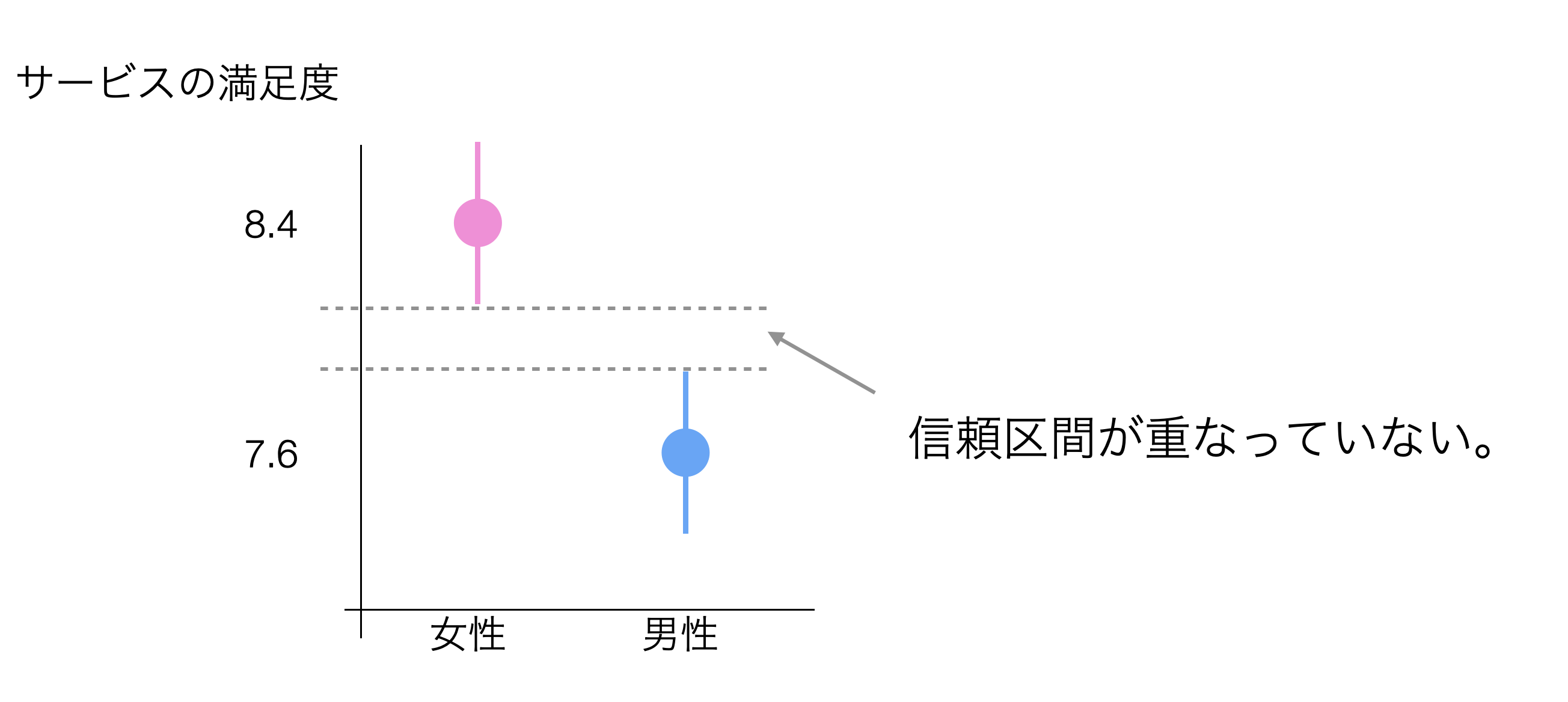
信頼区間が重なっていない場合は、女性は男性に比べてサービスの満足度の平均値が高く、その違いも有意な違いがあると言えます。
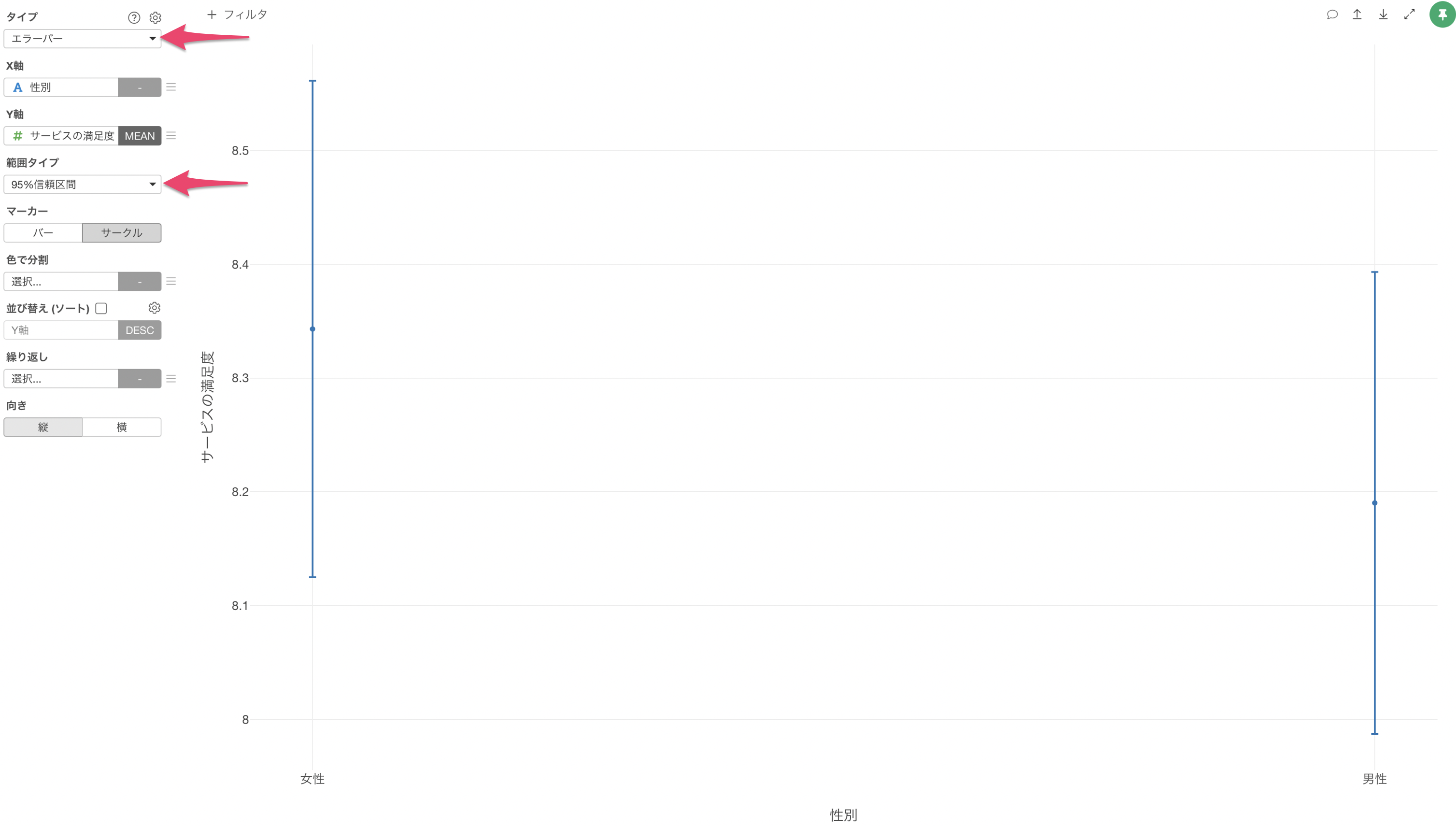
Exploratoryでは、エラーバーといったチャートを使うことで、信頼区間を簡単に可視化していくことが可能です。
自由記述の回答データ
アンケートによくある質問のタイプの1つが「自由記述」です。自由記述の回答は、5段階評価などでは得られない、より詳細な情報を得ることができます。
例えば、あるソフトウェアのサービスが、自社のサービスの満足度調査の一環として推奨度(NPS)と推奨度の理由についてアンケートをとったデータがあったとします。
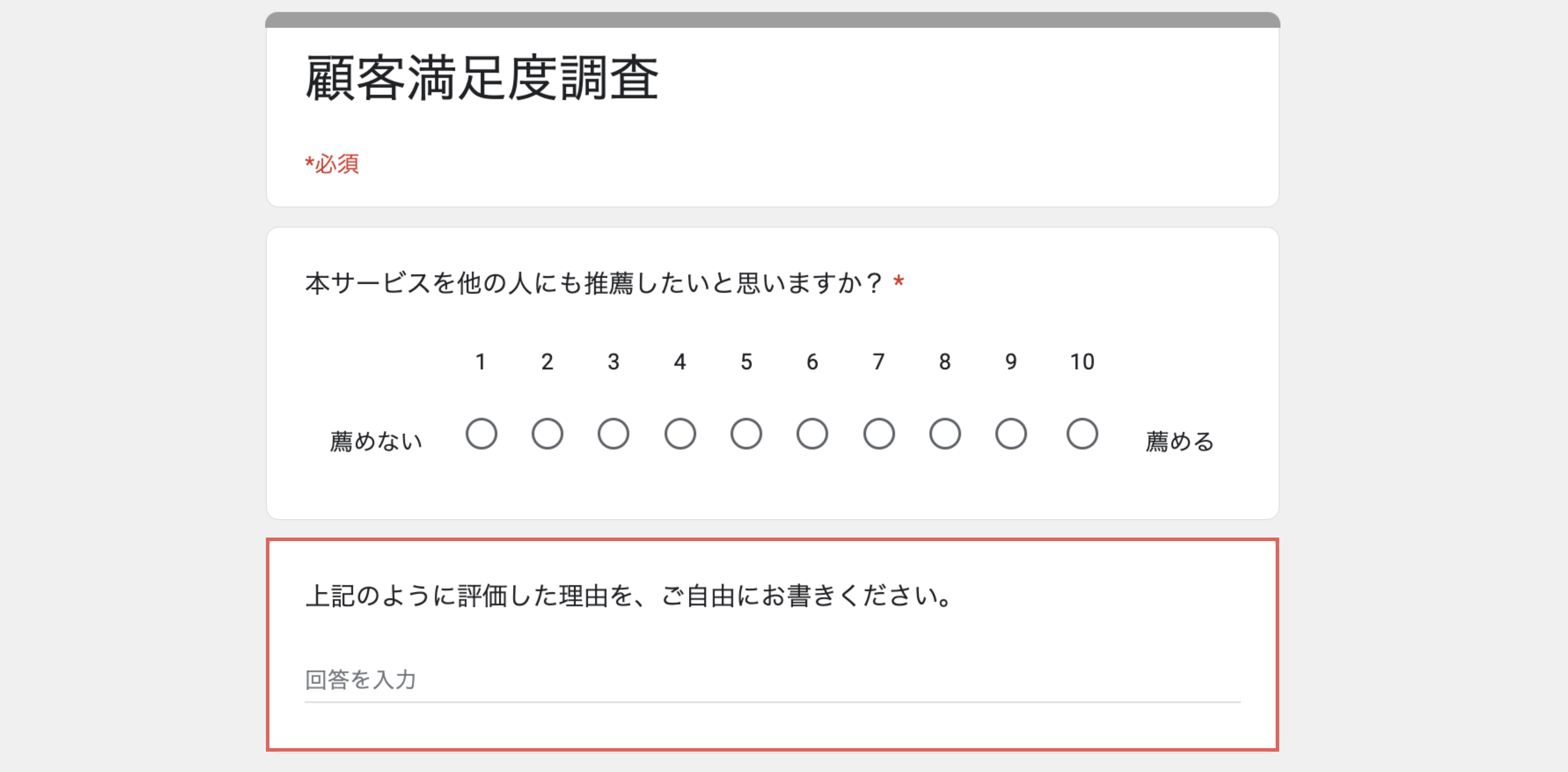
そして、今回得られたアンケート結果をもとに、推奨度が高い人たちに対して「紹介キャンペーン」を行いたいとします。

その際に、自由記述の回答である「推奨度の理由」をもとに、それぞれの回答者の特徴を理解して、それぞれの回答者(顧客)に対してキャンペーンを行いたいです。
しかし、自由記述の回答は、回答者が少ない場合は1つ1つ読んでいくことができますが、多い時には全てを見て傾向を把握することは現実的に難しいです。
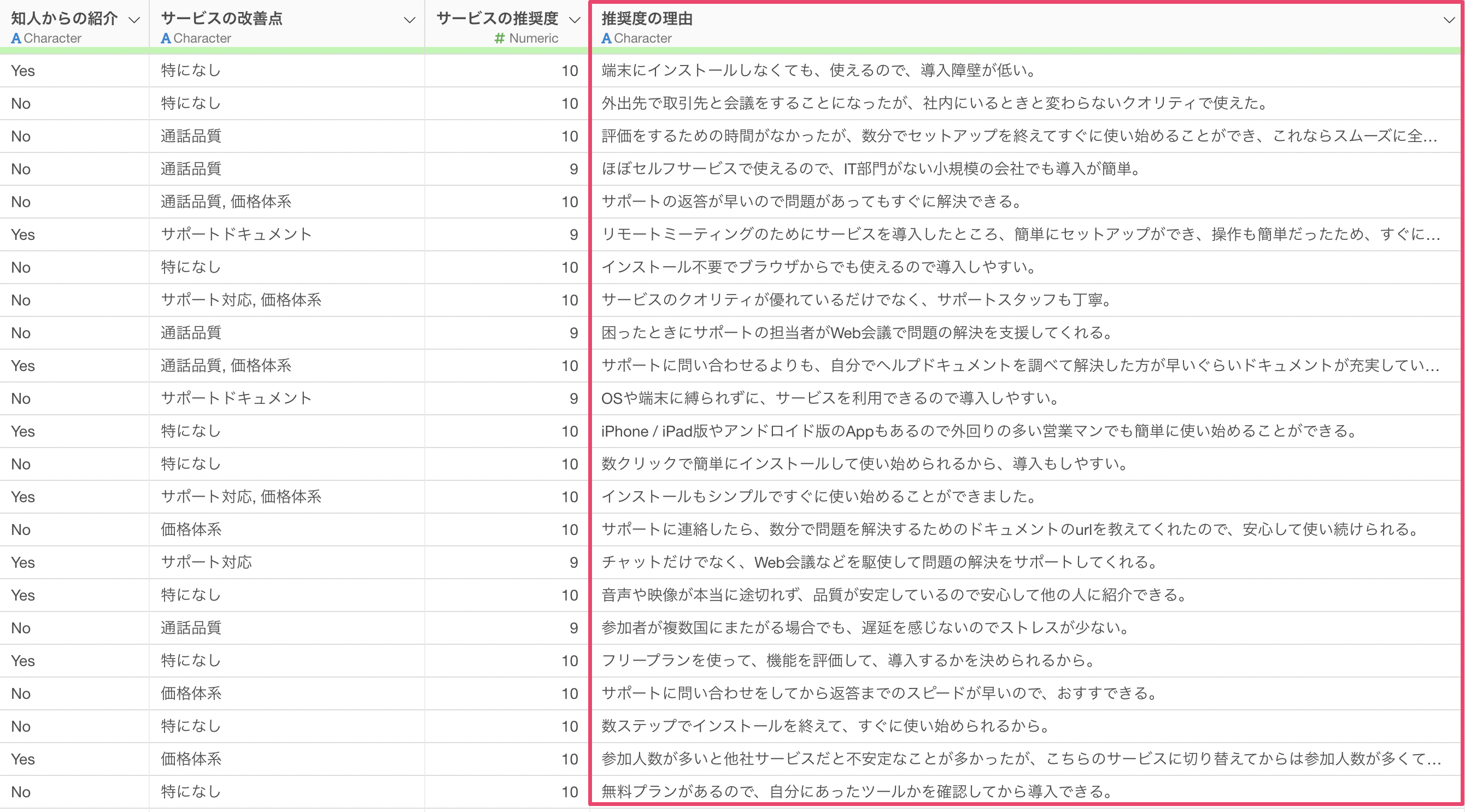
さらには、それぞれの文章の特徴をもとに、ラベルづけを行うとなれば、余計に時間がかかってしまい、途方もない作業となります。
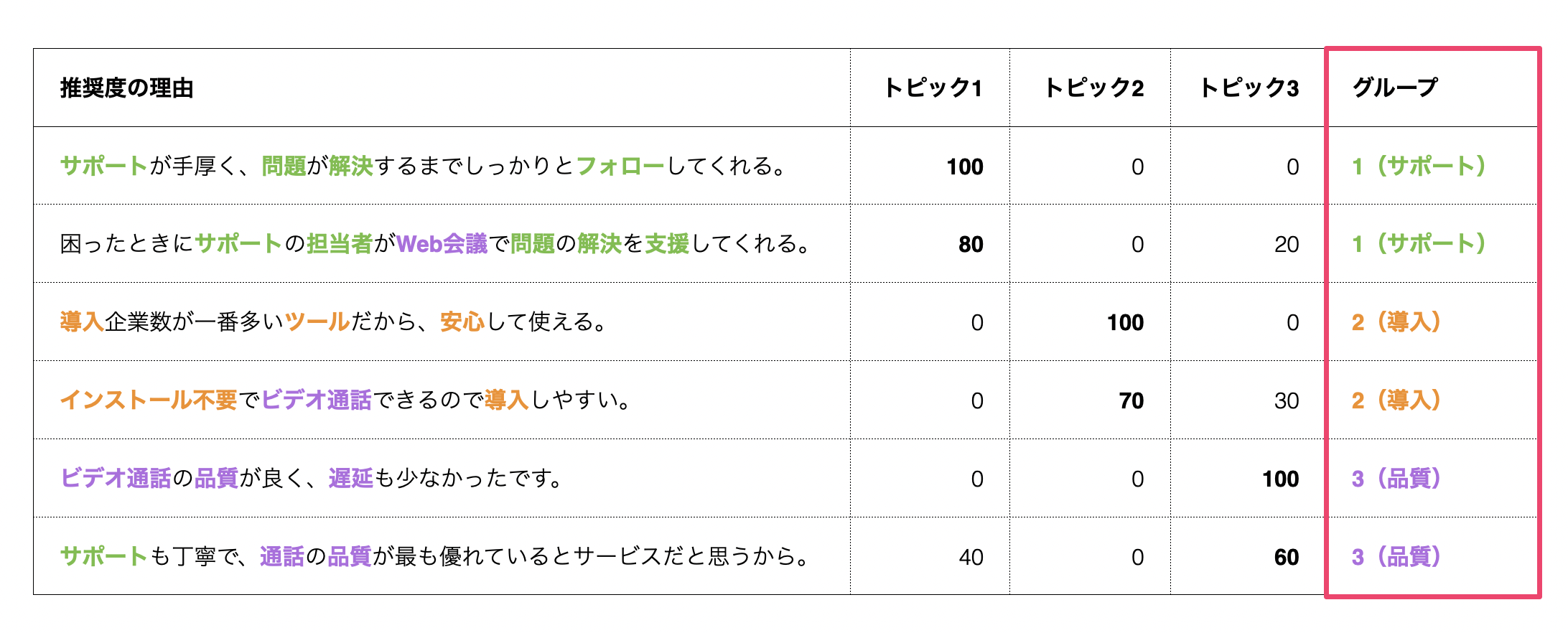
例えば、下記の文章があったとしましょう。

それぞれの文章をみると、「サポート」、「導入」、「サービスの品質」に関するグループがあるように見えます。
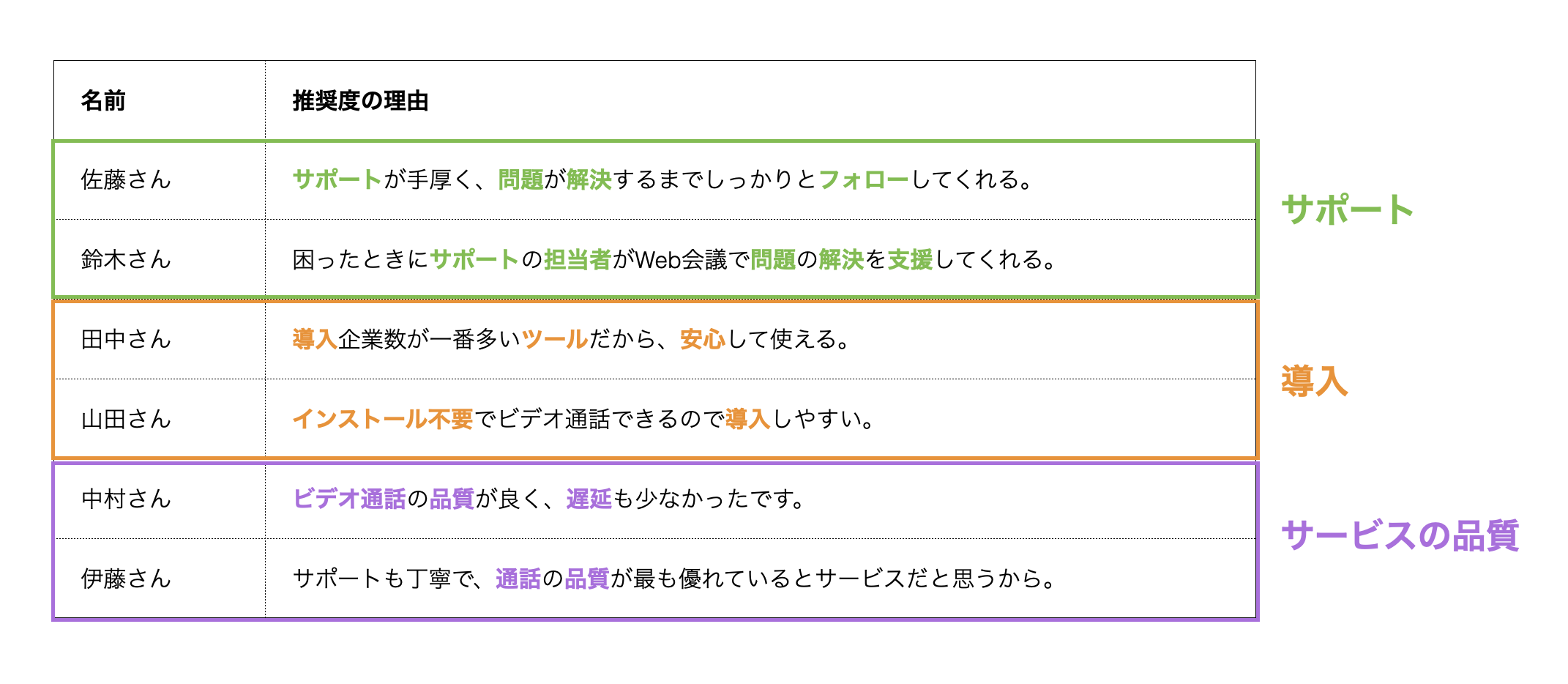
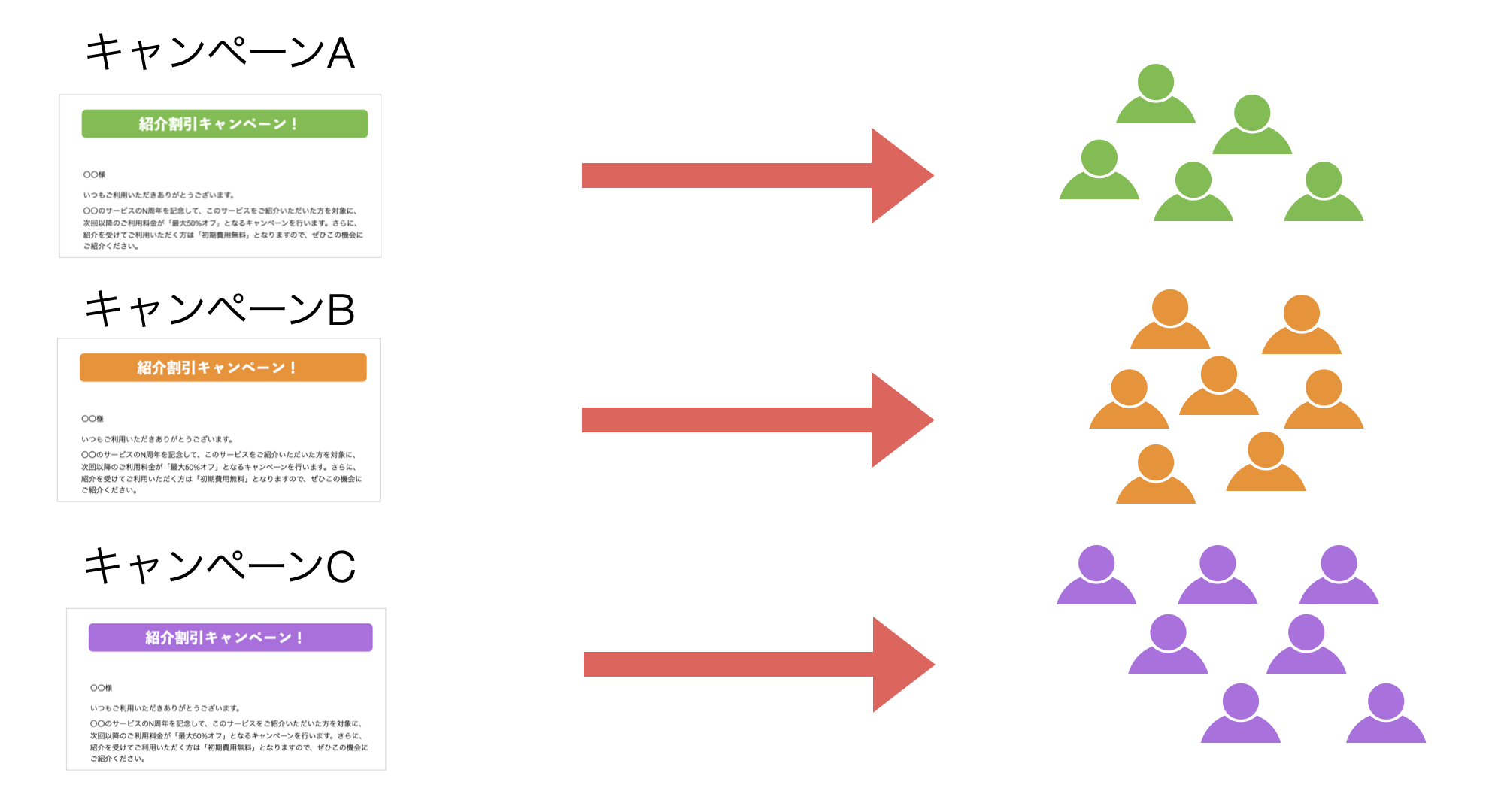
これらの文章の傾向をもとに回答者を機械的にグループ分けできないか、その問題を解決してくれるのがトピックモデル(LDA)です。
「トピックモデル」を実行すると、文章ごとに各トピックの比率(確率)を得ることができます。

その文章におけるトピック比率が高いものをもとに、それぞれの回答者をグループ分けすることができます。
これにより、それぞれのグループにあった適切なキャンペーンを行うことができるようになります。
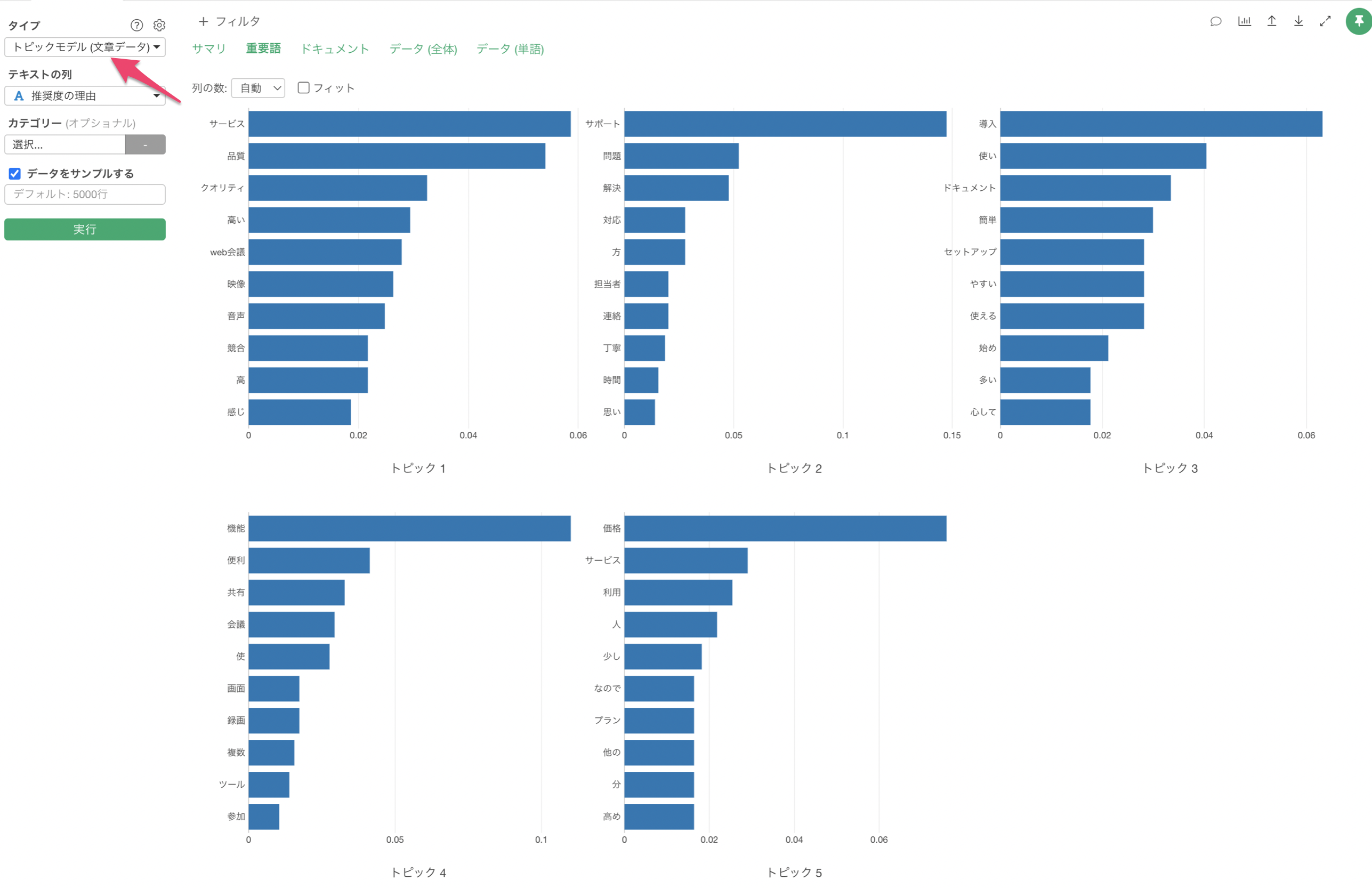
Exploratoryの場合は、アナリティクス・ビューの下で「トピックモデル」を選び、「自由記述」の列を選択することで簡単にトピックモデルを実行することができます。
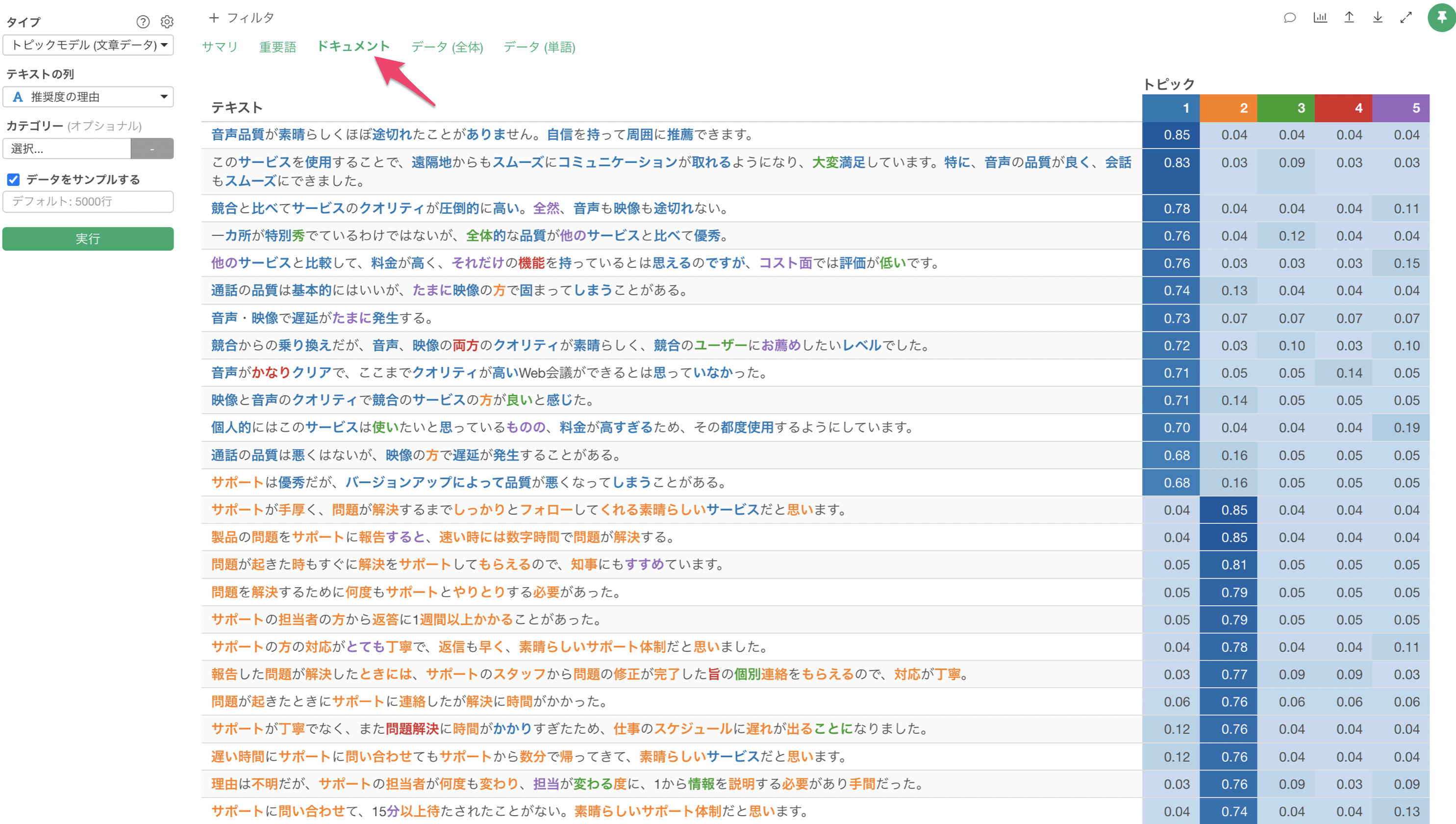
「ドキュメント」タブを使うことで、それぞれのトピックの確率が高い文章を確認することができ、どういった文章がグループ分けされているのかを簡単に解釈していくことができます。
実務で使えるスキルを身に着けたい!

今回紹介したようなアンケートデータの分析に役立つ分析手法、さらにアンケートデータに特有なデータ加工の問題の解決方法などをもっと深く学び、さらに現場で使えるレベルのスキルを身に着けたいという方は、アンケートデータの加工と分析に特化したトレーニングを用意しておりますので、ぜひご検討いただければと思います。
自分のデータで試してみたい!
記事内の全てのチャートは、データの加工、可視化、分析、レポーティングのためのUIツールのExploratoryを利用して作成しています。
ご自身のデータを使って、これらのチャートを作成したり、データの分析をしたい方は、下記のページより無料トライアルが可能ですので、ぜひ、お試しください!