はじめに
検索結果のdedupe(重複排除)はユーザのために非常に重要です。検索結果から重複した情報を削除することで、ユーザーが重複した情報を省略して、より重要な情報を素早く把握することができます。
この記事では、OSS検索エンジンのVespaを使って検索を行う場合のdedupeの方法を説明します。
検索結果のdedupe(重複排除)とは
今回は、dedupeの題材として以下の仕様を考えます。
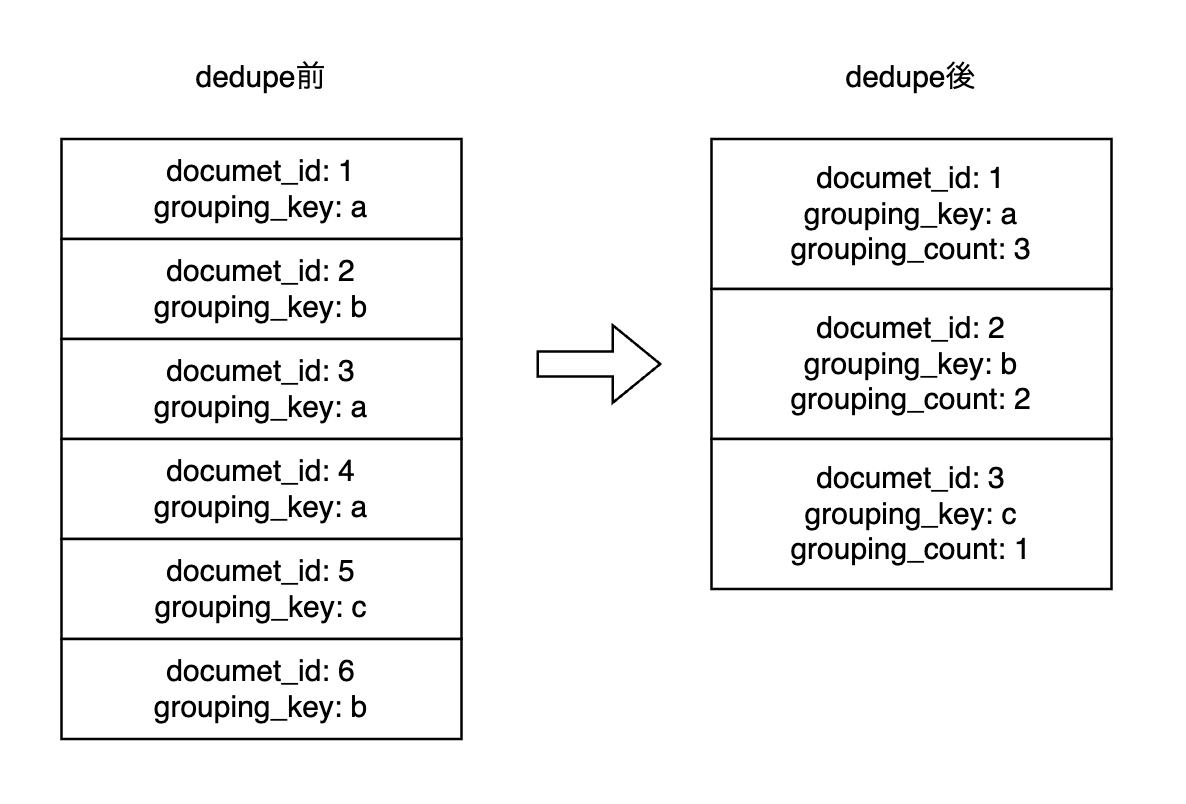
dedupe前の検索結果は、検索語句の関連度に基づいて並んでいますが、同じ内容のドキュメントが複数ある場合があります。例えば、ニュース記事を検索した場合、タイトルが同じ記事が複数ある可能性があります。この場合、dedupeを行うことで、重複した記事を1つだけ残し、他の記事は検索結果から削除することができます。dedupeを行う際には、重複判定を行うためのキーとなるgrouping_keyを指定します。このキーを基に、重複したドキュメントを検出し、検索結果から削除します。削除されなかったドキュメントには、検索結果に含まれる同じgrouping_keyを持つドキュメントの総数が保存されます。
Vespaとは
Vespaとは、検索エンジンの1つです。Vespaは、Yahooが開発したオープンソースのプラットフォームであり、Webページの検索や大規模データセットの探索などに使用されます。Vespaは、スケーラブルで高速な検索性能を実現するために、分散処理システムや分散データベース技術を採用しています。また、Vespaは、多種多様なデータタイプに対応しており、様々なアプリケーションやシステムで活用されています。
Vespaによる重複排除の方法
Vespaでは検索結果を集計する機能としてgroupingがあります。
group化の構造は以下の4つの操作を組み合わせて表現されます。
-
all(statement): 入力リスト全体に対してネストされたステートメントを一回実行する -
each(statement): 入力リストの各要素に対して、ネストされたステートメントを実行する -
group(specification): 入力リストをグループ化の指定にしたがってリストのリストにする -
output(): 何らかの値を出力する。countやsum、summaryなどの操作が実行できる。
詳細については公式ドキュメントを参照してください。
groupingを行う場合、通常の検索クエリのあとに|でグループ化式を繋ぐことで検索結果のグルーピングができます。今回のdedupe仕様を実現するクエリは、次のようなクエリになります。
yql=select * from job where true | all(group(grouping_hash) max(200) each(max(1) output(count()) each(output(summary()))))
上記のgroupingをもう少し見やすくすると以下のような構造になっています。
all(
group(grouping_hash) // grouping_hashでグループに分割
max(200) // 上位200件のグループを取得
each(
max(1) // 各グループから最大1件取得
output(count()) // 各グループのヒット数を取得
each (
output(summary()) // 各ドキュメントの情報を取得
)
)
)
図で表すと以下のようになります。
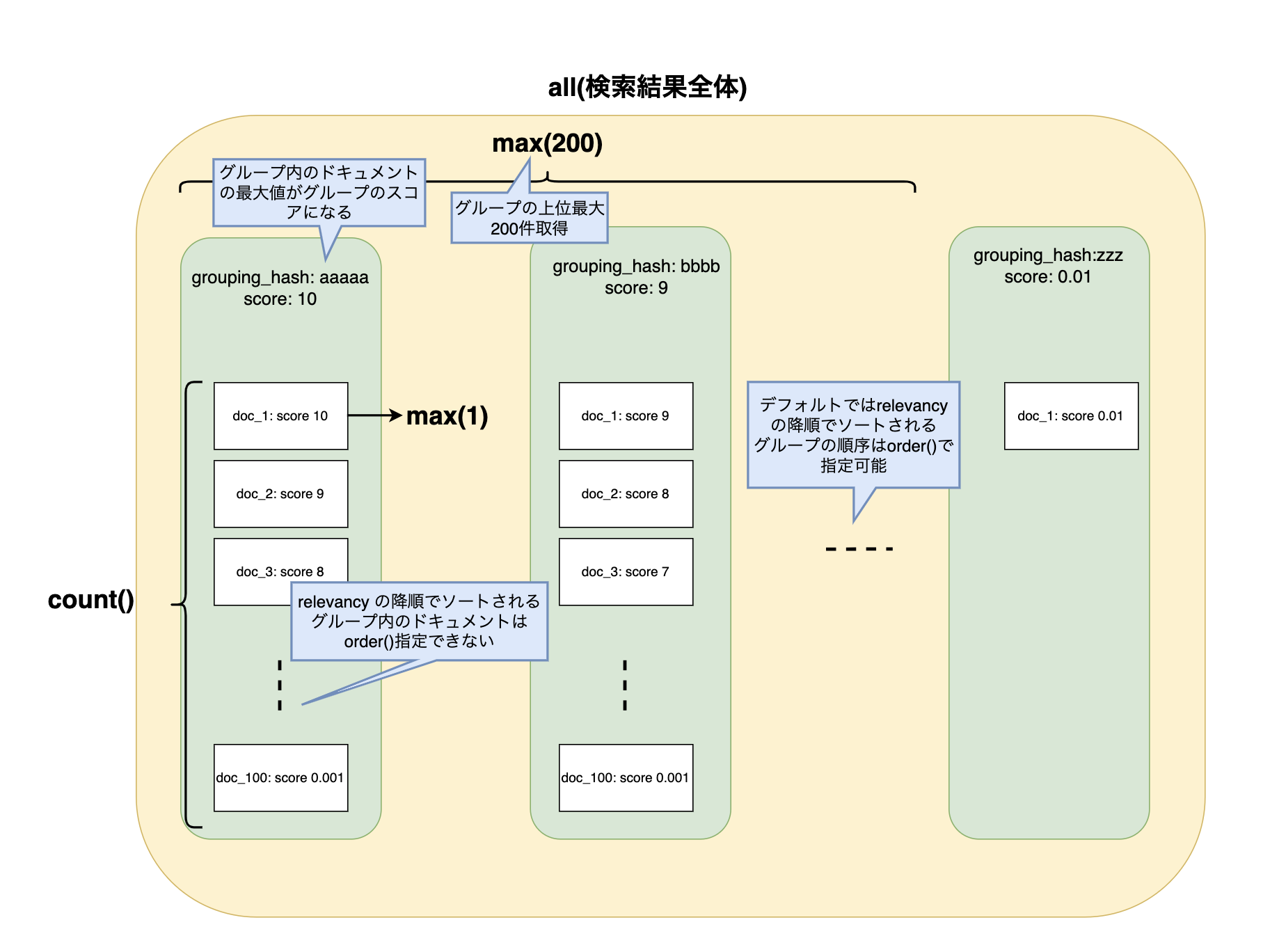
| のすぐ後のallで検索結果のリストを全てを対象とします。次にgroup(grouping_hash)でgrouping_hashごとにグループにリストを分割します。さらにmax(200)で上位最大200グループを対象として後の操作を実行します。分割された各グループに対してeach()でネストの中の操作を行います。each()のネストの中ではmax(1)で各グループの最上位の1件を取得しています。また、output(count())で各グループに含まれるドキュメント数も集計します。さらに、maxで取得したドキュメントに対して、each(output(summary)))でドキュメントの情報を取得します。
このように複数の操作を組み合わせることで、重複排除をVespaで実現することができます。
文章でクエリの説明をしてもわかりづらいので、実際にVespaを使って重複結果の排除を試したいと思います。
Vespaでローカル開発環境を構築する
まず、ローカルでVespa開発環境を構築していきます。
Dockerを使うことで簡単にVespaを動かすことができます。
ここからの内容は、VespaのQuick Startのページに書いてあることと同じです。
Docker環境の確認
まず、Dockerのメモリを確認します。
ここで最低でもメモリが4GB以上確保されていることを確認して下さい。
$ docker info | grep "Total Memory"
Vespa CLIのインストール
つぎに、VespaのCLIツールをインストールします。Vespa CLIはVespaのコマンドラインインタフェースです。Vespa CLIを使用することで、Vespaクラスタを管理したり、アプリケーションをデプロイしたりすることができます。
$ brew install vespa-cli
macOS以外のOSを使用している場合は、以下から自分の環境にあったものをダウンロードしてください。
インストールできたらvespa-cliの設定を行います。今回はローカルのDockerでVespaを動かすので、targetをlocalに設定してください。
$ vespa config set target local
Vespaコンテナの起動
VespaのDockerコンテナを開始します。ここでは8080と19071の2つのポートを公開しています。8080ポートは検索とフィードのインターフェイスをDockerコンテナの外からアクセスできるようにするために公開しており、19071は設定サーバーのエンドポイントになります。
$ docker run --detach --name vespa --hostname vespa-container \
--publish 8080:8080 --publish 19071:19071 \
vespaengine/vespa
Vespaのステータスを確認します。
$ vespa status deploy --wait 300
Waiting up to 5m0s for service to become ready ...
Deploy API at http://127.0.0.1:19071 is ready
Vespaの設定を行う
Vespaの設定はapplication packageをデプロイすることで行います。application packageとはアプリケーションを定義する、特定の構造を持つファイルのセットです。application packageには、アプリケーションのデプロイと実行に必要なすべての設定、コンポーネント、機械学習されたモデルが含まれます。
まず、application packageの元となる設定ファイルを作成します。適当なディレクトリを作成し、以下のような構造でファイルを配置してください。
.
├── schemas
│ └── job.sd
└── services.xml
ここで、services.xmlはアプリケーションを構成するサービスを指定する設定ファイルです。また、schemasディレクトリには、アプリケーションのドキュメントタイプと、それらのクエリーと処理の方法を記述した*.sdファイルが含まれています。
services.xmlの中身は次のように記述します。設定の詳細については公式ドキュメントを参照してください。
<?xml version="1.0" encoding="utf-8" ?>
<services version="1.0" xmlns:deploy="vespa" xmlns:preprocess="properties">
<container id="default" version="1.0">
<document-api/>
<search/>
<nodes>
<node hostalias="node1" />
</nodes>
</container>
<content id="job" version="1.0">
<redundancy>2</redundancy>
<documents>
<document type="job" mode="index" />
</documents>
<nodes>
<node hostalias="node1" distribution-key="0" />
</nodes>
</content>
</services>
schema/job.shの中身は以下のように記述します。今回は検索対象として、求人票を想定しスキーマを定義しました。titleは求人票のタイトルです、またdescriptionは求人票の詳細情報です。
スキーマの定義については以下を参照してください。
schema job {
document job {
field title type string {
indexing: summary | index | attribute
}
field description type string {
indexing: summary | index
index: enable-bm25
}
}
fieldset default {
fields: title, description
}
}
設定の反映はvespa-cliを使って行います。vespa-cliを使うことで自動的にapplication packageを作成してVespaへのデプロイを行ってくれます。
$ vespa deploy --wait 300
Uploading application package ... done
Success: Deployed .
Waiting up to 5m0s for query service to become available ...
ドキュメントをフィードする
最後に、ドキュメントをフィードしていきます。以下のようなファイルを作成してください。
{
"put": "id:mynamespace:job::1",
"fields": {
"title": "Engineers Wanted",
"description": "We are currently recruiting for an engineer."
}
}
vespa-cliを使ってドキュメントをフィードします。
$ vespa document document_1.json
今回は、重複排除を検証するので、タイトルが同じドキュメントを用意します。
上記の操作を繰り返し以下の6件のドキュメントをフィードしてください。
| id | title | description |
|---|---|---|
| 1 | Engineers Wanted | We are currently recruiting for an engineer. |
| 2 | seeking sales staff | We are recruiting for sales positions. |
| 3 | Engineers Wanted | We are currently recruiting for an frontend engineer. |
| 4 | Engineers Wanted | We are currently recruiting for an search engineer |
| 5 | hiring for office positions | We are currently recruiting for an office position. |
| 6 | seeking sales staff | We are recruiting for inside sales positions. |
Vespaで重複排除を実現する検索クエリ
それでは、Vespaでの重複排除を実施してみましょう。
重複排除なし
まず、重複排除なしの場合の検索結果をみていきます。検索クエリは以下です。descriptionにrecrutingを含むドキュメントを検索しています。
$ vespa query "select * from job where description contains 'recruiting'"
このクエリのVespaからのレスポンスは次のようになります。
重複排除なしクエリのレスポンス(クリックして展開できます)
{
"root": {
"id": "toplevel",
"relevance": 1.0,
"fields": {
"totalCount": 6
},
"coverage": {
"coverage": 100,
"documents": 6,
"full": true,
"nodes": 1,
"results": 1,
"resultsFull": 1
},
"children": [
{
"id": "id:mynamespace:job::2",
"relevance": 0.15974580091895013,
"source": "job",
"fields": {
"sddocname": "job",
"documentid": "id:mynamespace:job::2",
"title": "seeking sales staff",
"description": "We are recruiting for sales positions."
}
},
{
"id": "id:mynamespace:job::6",
"relevance": 0.15561636953850272,
"source": "job",
"fields": {
"sddocname": "job",
"documentid": "id:mynamespace:job::6",
"title": "seeking sales staff",
"description": "We are recruiting for inside sales positions."
}
},
{
"id": "id:mynamespace:job::1",
"relevance": 0.15537750641060152,
"source": "job",
"fields": {
"sddocname": "job",
"documentid": "id:mynamespace:job::1",
"title": "Engineers Wanted",
"description": "We are currently recruiting for an engineer."
}
},
{
"id": "id:mynamespace:job::3",
"relevance": 0.15143468537173052,
"source": "job",
"fields": {
"sddocname": "job",
"documentid": "id:mynamespace:job::3",
"title": "Engineers Wanted",
"description": "We are currently recruiting for an frontend engineer"
}
},
{
"id": "id:mynamespace:job::4",
"relevance": 0.15143468537173052,
"source": "job",
"fields": {
"sddocname": "job",
"documentid": "id:mynamespace:job::4",
"title": "Engineers Wanted",
"description": "We are currently recruiting for an search engineer"
}
},
{
"id": "id:mynamespace:job::5",
"relevance": 0.15143468537173052,
"source": "job",
"fields": {
"sddocname": "job",
"documentid": "id:mynamespace:job::5",
"title": "hiring for office positions",
"description": "We are currently recruiting for an office position."
}
}
]
}
}
root.childrenにヒットしたドキュメントのリストが表示されています。この中には同じタイトルのドキュメントが含まれており、重複排除が行われていないことがわかります。
重複排除あり
次にgroupingを使って重複排除を行なった場合の検索結果を見てみましょう。以下のクエリを発行します。grouping前の結果は必要ないので"hits=0"を指定することで検索結果から除外しています。
$ vespa query "select * from job where description contains 'recruiting' | all(group(title) max(200) each(max(1) output(count()) each(output(summary()))))" "hits=0"
このクエリのレスポンスは次のようになります。
重複排除ありクエリのレスポンス(クリックして展開できます)
{
"root": {
"id": "toplevel",
"relevance": 1.0,
"fields": {
"totalCount": 6
},
"coverage": {
"coverage": 100,
"documents": 6,
"full": true,
"nodes": 1,
"results": 1,
"resultsFull": 1
},
"children": [
{
"id": "group:root:0",
"relevance": 1.0,
"continuation": {
"this": ""
},
"children": [
{
"id": "grouplist:title",
"relevance": 1.0,
"label": "title",
"children": [
{
"id": "group:string:seeking sales staff",
"relevance": 0.15974580091895013,
"value": "seeking sales staff",
"fields": {
"count()": 2
},
"children": [
{
"id": "hitlist:hits",
"relevance": 1.0,
"label": "hits",
"continuation": {
"next": "BKAAAAABIBCBC"
},
"children": [
{
"id": "id:mynamespace:job::2",
"relevance": 0.15974580091895013,
"source": "job",
"fields": {
"sddocname": "job",
"documentid": "id:mynamespace:job::2",
"title": "seeking sales staff",
"description": "We are recruiting for sales positions."
}
}
]
}
]
},
{
"id": "group:string:Engineers Wanted",
"relevance": 0.15537750641060152,
"value": "Engineers Wanted",
"fields": {
"count()": 3
},
"children": [
{
"id": "hitlist:hits",
"relevance": 1.0,
"label": "hits",
"continuation": {
"next": "BKAAABCABIBCBC"
},
"children": [
{
"id": "id:mynamespace:job::1",
"relevance": 0.15537750641060152,
"source": "job",
"fields": {
"sddocname": "job",
"documentid": "id:mynamespace:job::1",
"title": "Engineers Wanted",
"description": "We are currently recruiting for an engineer."
}
}
]
}
]
},
{
"id": "group:string:hiring for office positions",
"relevance": 0.15143468537173052,
"value": "hiring for office positions",
"fields": {
"count()": 1
},
"children": [
{
"id": "hitlist:hits",
"relevance": 1.0,
"label": "hits",
"children": [
{
"id": "id:mynamespace:job::5",
"relevance": 0.15143468537173052,
"source": "job",
"fields": {
"sddocname": "job",
"documentid": "id:mynamespace:job::5",
"title": "hiring for office positions",
"description": "We are currently recruiting for an office position."
}
}
]
}
]
}
]
}
]
}
]
}
}
今回はroot.childrenにヒットしたドキュメントではなく、複雑なオブジェクトが返ってきました。
"id": "grouplist:title"というフィールドを持つオブジェクトのchildrenにグルーピングの結果が含まれています。このchildrenリストのオブジェクトには、"value"と"field"というフィールドがあります。"value"にはgroup()操作に指定したフィールドの値が含まれており、fieldにはoutputの値が含まれています。今回の場合はcount()を使用したので、重複したドキュメントの数が含まれます。また、そのさらにchildrenにはoutput(summary)の結果である、ドキュメントの情報が表示されています。
このように、groupingを使用した場合、検索結果はgroupingで指定したクエリの構造によってレスポンスの構造も複雑にネストします。
注意事項
ここまで、Vespaで重複排除を実現する方法を見てきましたが、groupingを行う際に注意点があります。
groupingのcountは正確な数字ではない場合がある
Vespaの公式ドキュメントのgroupingについての説明箇所に以下のような記載があります。
The count aggregator can be applied on list of groups to determine the number of unique groups without having to explicitly retrieve all groups. Note that this count is an estimate using HyperLogLog++ which is an algorithm for the count-distinct problem. To get an accurate count one needs to explicitly retrieve all groups and count them in a custom component or in the middle tier calling out to Vespa. This is network intensive and might not be feasible in cases with many unique groups.
グループのリストに対してのカウントはHyperLogLogによる推定値であるため正確なカウントではないようです。正確な数値が必要な場合は別の手段を考える必要がありそうです。
ページネーションについて
groupingのページネーションはcontinuationを使用するため、特定のページの結果をlimit,offsetで指定することができないようです。直接特定のページに遷移するなどの仕様の場合は、何らかの手段を検討する必要がありそうです。
おわりに
Vespaではgroupingを活用することで、さまざまな集計を実現できます。今回はgroupingの複数の操作を組み合わせることで重複排除を実現することができることを確認しました。Vespaでは他にもさまざまな機能が提供されているので、機会があれば別の記事で紹介していきたいと思います。