こんにちは KDDIアジャイル開発センター たかたにです。
本日もニコニコiOSの新技術を触ってみた記事を書きます。
今回の記事は、
「アプリを生成AIがテキトーに作る」→「作ったものから要件定義をAIに書かせる」→「良いアプリが完成〜」という流れの内容です。
やってみたいこと
- Appleの最新AI技術を活用した実装をしたい
- WWDC25で発表されたFoundation Models(ローカルLLM)を利用したい
- 画像・映像を解析するための機械学習ベースのAPI群の一つであるVisionフレームワークの精度が上がっているので試したい
- iOSローカルのみで完結する画像認識アプリ(機械学習もなし)を作りたい
- claude codeでvibe codingを駆使して、チャチャっとiOSアプリを作りたい
革新的なポイント
- 完全オンデバイス処理 - ネットワーク不要、プライバシー保護、ローカル
- iOS18以降限定 - Appleの最新AI技術
- 日本語ネイティブ対応 - 多言語理解とユーモア生成
- リアルタイム推論 - 高速レスポンス
- AI連携アーキテクチャ
- 二段階AI処理システム:
- Vision Framework - 物体の候補抽出
- Foundation Models - 文脈理解と日本語応答生成
- 二段階AI処理システム:
作るもの
iPhoneのカメラで写真を撮って、AIが何か判別してくれるもの。
とりあえず試してみる。

プロンプトに色々入れてみる。
プロンプト
iOSのアプリをSwiftUIで作っているよ。iOS26ベータ版を利用しており、Visual
Intelligenceを用いて「カメラに映ったものをAIに判別させる」アプリを作ろう
としている。https://developer.apple.com/documentation/visualintelligence
ここに内容は記載されているよ。作ってくれるかな? アプリ起動後ボタンを押下
したらカメラが起動して映ったものが何か判別してくれたらOK。UIはシンプルで
かっこいい物が良いな。アプリ名は「AIカメラくん」にしよう。お願いします。
→ 試すとなんか生まれる。
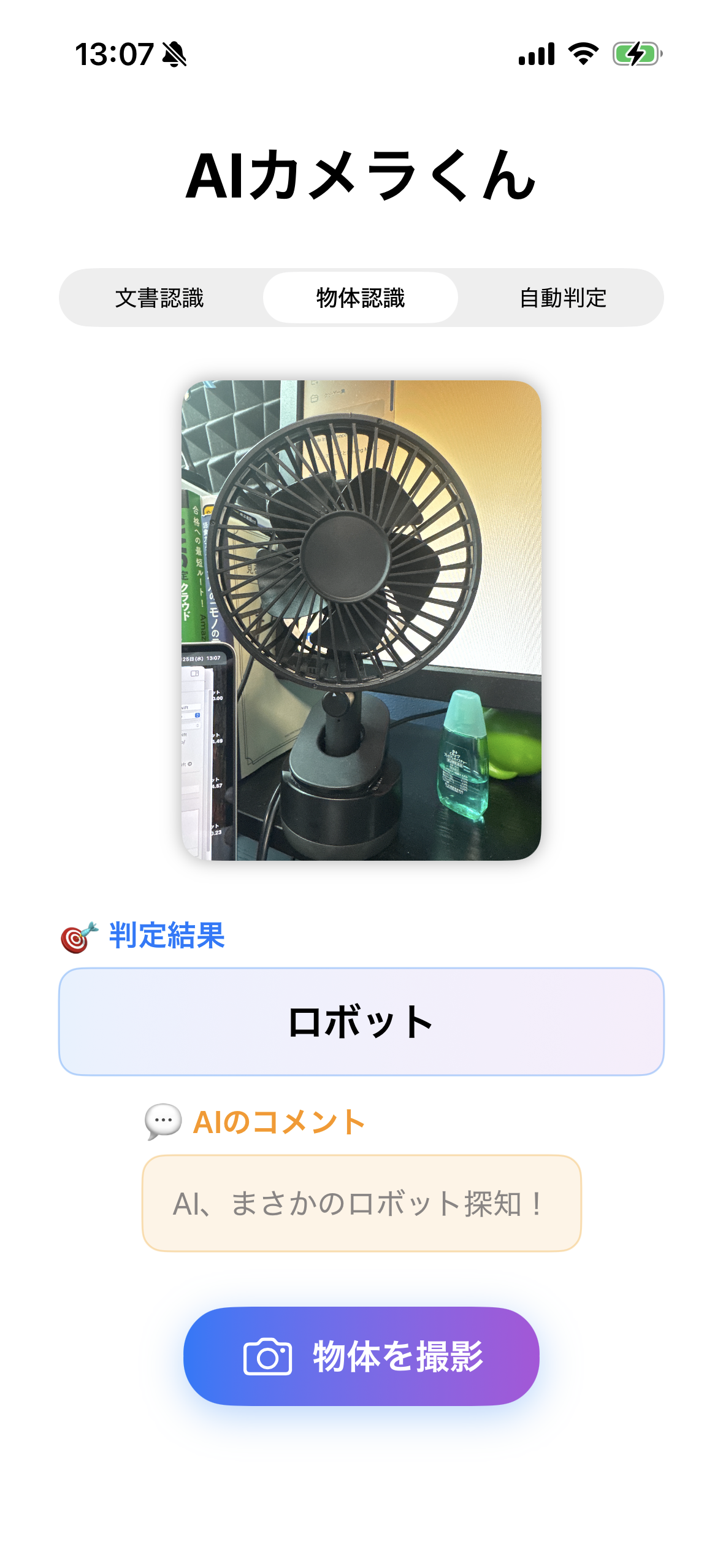
課題
- 物体認識の精度が悪い
- contentView.swiftが長文のコードなっている
- アーキテクチャとして気持ち悪い
アーキ、要件検討
コード自体をしっかり手直ししたくなり、可読性を上げるために、claude codeに以下のプロンプトをお願いする。
contentView.swiftにあるコードをMVVPの形にしてDIについて検討して、アーキテクチャを考え直して。
結果、以下が返ってきた。
概要
CameraAIはMVVM + Clean Architecture + Dependency Injectionパターンを採用したiOSアプリケーションです。
レイヤー詳細
🎨 Presentation Layer
- ContentView: メイン画面のルートビュー
- CameraView: カメラ撮影機能
- UI Components: 再利用可能なUIコンポーネント群
🧠 Business Logic Layer
- CameraViewModel: ビジネスロジックと状態管理
- AnalysisState: アプリケーション状態の定義
⚙️ Service Layer
- VisionService: Apple Vision APIのラッパー
- LLMAnalysisService: Foundation Modelsを使った高度な分析
- TranslationService: 英語→日本語翻訳サービス
🏗️ Infrastructure Layer
- ServiceContainer: Dependency Injectionコンテナ
- External APIs: 外部APIとの連携
データフロー
依存性注入 (DI)
// ServiceContainer による DI 構成
ServiceContainer
├── TranslationService (Singleton)
├── VisionService (Singleton)
├── LLMAnalysisService (依存: TranslationService)
└── CameraViewModel (依存: VisionService, LLMAnalysisService)
物体認識フロー
ファイル構成
CameraAI/
├── Models/
│ └── AnalysisModels.swift
├── ViewModels/
│ └── CameraViewModel.swift
├── Views/
│ ├── ContentView.swift
│ ├── CameraView.swift
│ └── Components/
│ ├── AnalysisResultView.swift
│ ├── CameraButton.swift
│ └── ImageDisplayView.swift
├── Services/
│ ├── VisionService.swift
│ ├── LLMAnalysisService.swift
│ └── TranslationService.swift
└── DI/
└── ServiceContainer.swift
→ これでどう作ると綺麗な構成になるかがわかる。
この構成で作ると可読性も上がり、より良い指示出したができるようになるので、、、次の指示は・・・
このアーキテクチャ構成でアプリを作って!
結果、見事アプリの完成。
iOS26から文字認識の精度も上がったようなので、そちらも対応させてみた。
動作フロー:
- カメラ撮影 → Vision認識
- 即座にローディング表示「🧠 Foundation Modelsで高精度分析中...」
- Foundation Modelsで物体推論
- 「🧠 物体認識完了: XXX」
- Foundation Modelsでコメント生成
- 最終結果「🎯 バッチリ!これは間違いなくXXXですね!」
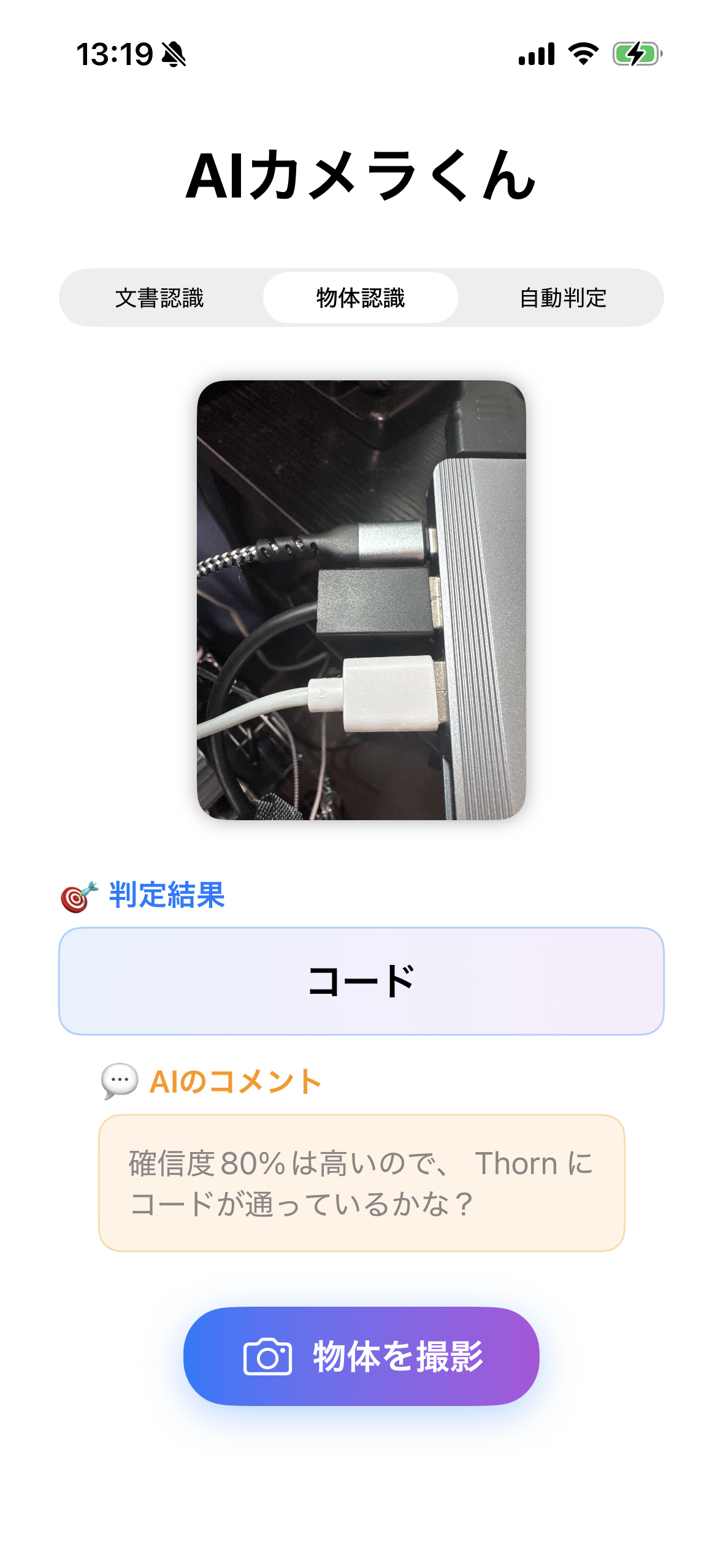
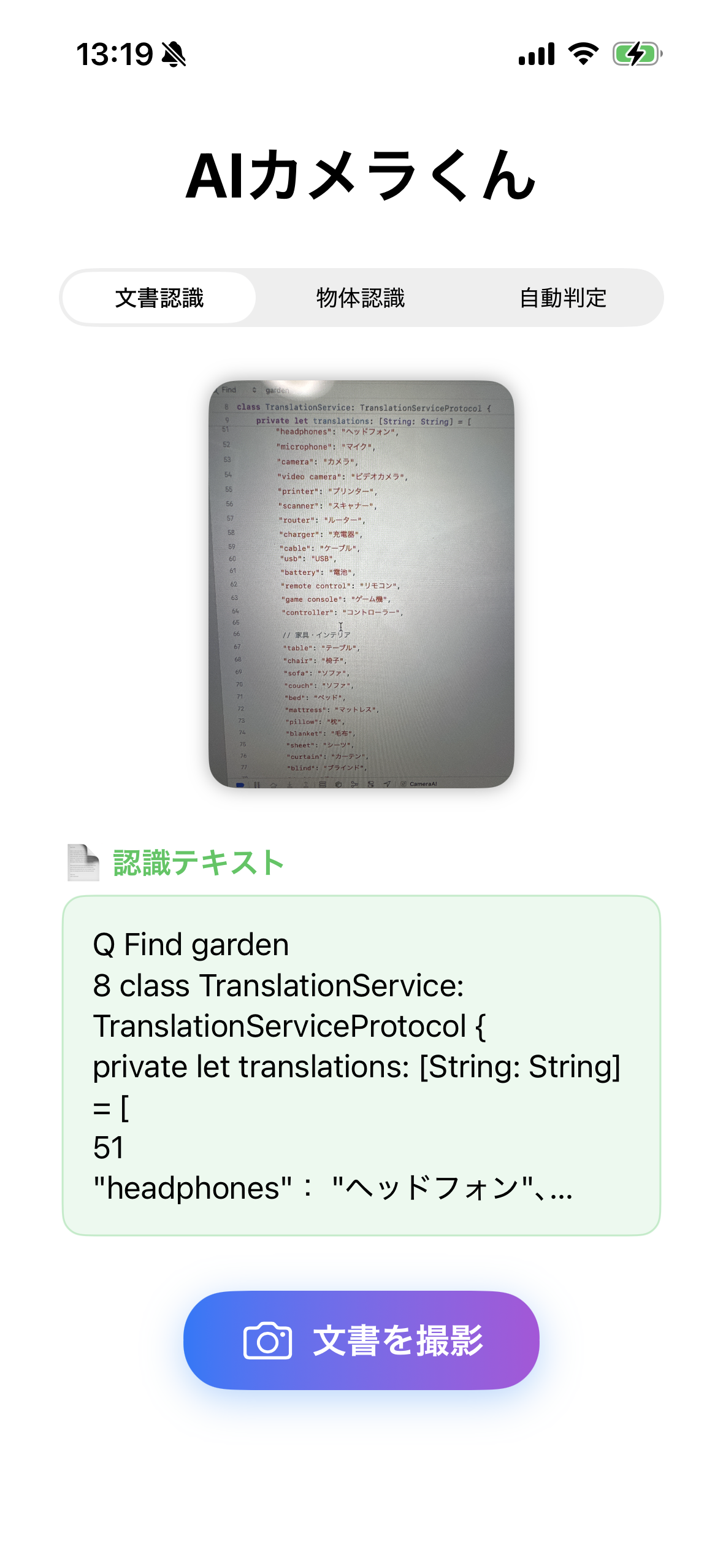
課題となる機能はファイルごとに細かい指示出しをして制度をあげていくと楽しい
苦労した点、楽しかった点
発表された新技術などについては、claude codeくんもまだまだ知見がないためドキュメントを確認して、指示を出さないと動かない時があった。楽しい!!!
プロンプトも色々試すと楽しいね。


おまけ
claude testコマンドはいまだに謎だけど、なんか安心する。

メインコードの一部
LLM実装箇所
import Foundation
import FoundationModels
protocol LLMAnalysisServiceProtocol {
func analyzeSingleResult(identifier: String, confidence: Float) async throws -> AnalysisResult
func analyzeMultipleResults(items: [(identifier: String, confidence: Float)]) async throws -> AnalysisResult
}
struct AnalysisResult {
let objectName: String
let comment: String
}
class LLMAnalysisService: LLMAnalysisServiceProtocol {
private let languageSession = LanguageModelSession()
private let translationService: TranslationServiceProtocol
init(translationService: TranslationServiceProtocol) {
self.translationService = translationService
}
func analyzeSingleResult(identifier: String, confidence: Float) async throws -> AnalysisResult {
let topConfidence = Int(confidence * 100)
let prompt = """
画像認識AIが物体を検出しました:
検出結果: \(identifier) (確信度: \(topConfidence)%)
この英語の物体名を適切な日本語に翻訳し、確信度に応じた30字以内のコメントをしてください。
英単語は日本語にしなさい。
回答形式:
物体名:[日本語訳(1単語)]
コメント:[確信度\(topConfidence)%に応じたユーモアなコメント(30文字以内)]
"""
return try await performAnalysis(prompt: prompt, fallbackIdentifier: identifier)
}
func analyzeMultipleResults(items: [(identifier: String, confidence: Float)]) async throws -> AnalysisResult {
let detectionData = items.map { item in
"\(item.identifier) (\(String(format: "%.1f", item.confidence * 100))%)"
}.joined(separator: ", ")
let prompt = """
画像認識AIが複数の候補を検出しましたが、どれも確信度が低いです:
候補: \(detectionData)
これらの英語の候補から、最も可能性が高い物体を推測して日本語で回答してください。
複数の候補を組み合わせて総合的に判断し、日常でよく見る物体名で答えてください。
回答形式:
物体名:[日本語の物体名(1単語)]
コメント:[推測に基づく面白いコメント(30文字以内)]
"""
let fallbackIdentifier = items.first?.identifier ?? "不明な物体"
return try await performAnalysis(prompt: prompt, fallbackIdentifier: fallbackIdentifier)
}
private func performAnalysis(prompt: String, fallbackIdentifier: String) async throws -> AnalysisResult {
guard #available(iOS 18.0, *) else {
throw LLMAnalysisError.unsupportedIOSVersion
}
// LLM部分
let model = SystemLanguageModel.default
guard model.availability == .available else {
throw LLMAnalysisError.modelUnavailable
}
let response = try await languageSession.respond(to: prompt)
let content = response.content.trimmingCharacters(in: .whitespacesAndNewlines)
// レスポンスをパース
let lines = content.components(separatedBy: .newlines)
var objectName = ""
var comment = ""
for line in lines {
if line.hasPrefix("物体名:") || line.hasPrefix("物体名:") {
objectName = String(line.dropFirst(4)).trimmingCharacters(in: .whitespacesAndNewlines)
} else if line.hasPrefix("コメント:") || line.hasPrefix("コメント:") {
comment = String(line.dropFirst(5)).trimmingCharacters(in: .whitespacesAndNewlines)
}
}
// パースに失敗した場合のフォールバック
if objectName.isEmpty || comment.isEmpty {
objectName = objectName.isEmpty ? translationService.translateToJapanese(fallbackIdentifier) : objectName
comment = comment.isEmpty ? (content.isEmpty ? "AI分析中にエラーが発生しました" : content) : comment
}
return AnalysisResult(objectName: objectName, comment: comment)
}
}
enum LLMAnalysisError: LocalizedError {
case unsupportedIOSVersion
case modelUnavailable
var errorDescription: String? {
switch self {
case .unsupportedIOSVersion:
return "Foundation Modelsが利用できません(iOS18以降が必要)"
case .modelUnavailable:
return "言語モデルが利用できません"
}
}
}
visionフレームワーク部分
import Foundation
import Vision
import UIKit
protocol VisionServiceProtocol {
func performDocumentRecognition(image: UIImage) async throws -> DocumentRecognitionResult
func performObjectDetection(image: UIImage) async throws -> ObjectDetectionResult
}
struct DocumentRecognitionResult {
let recognizedText: [String]
let isSuccessful: Bool
}
struct ObjectDetectionResult {
let classifications: [VisionClassification]
let topConfidence: Float
}
struct VisionClassification {
let identifier: String
let confidence: Float
}
class VisionService: VisionServiceProtocol {
func performDocumentRecognition(image: UIImage) async throws -> DocumentRecognitionResult {
guard let cgImage = image.cgImage else {
throw VisionError.invalidImage
}
return try await withCheckedThrowingContinuation { continuation in
let request = VNRecognizeTextRequest { request, error in
if let error = error {
continuation.resume(throwing: error)
return
}
guard let observations = request.results as? [VNRecognizedTextObservation] else {
continuation.resume(returning: DocumentRecognitionResult(recognizedText: [], isSuccessful: false))
return
}
let recognizedStrings = observations.compactMap { observation in
observation.topCandidates(3).first?.string
}.filter { !$0.isEmpty && $0.count > 1 }
let result = DocumentRecognitionResult(
recognizedText: recognizedStrings,
isSuccessful: !recognizedStrings.isEmpty
)
continuation.resume(returning: result)
}
// 文書認識の設定
request.recognitionLevel = .accurate
request.usesLanguageCorrection = true
request.recognitionLanguages = ["ja-JP", "en-US"]
request.automaticallyDetectsLanguage = true
let handler = VNImageRequestHandler(cgImage: cgImage, options: [:])
DispatchQueue.global(qos: .userInitiated).async {
do {
try handler.perform([request])
} catch {
continuation.resume(throwing: error)
}
}
}
}
func performObjectDetection(image: UIImage) async throws -> ObjectDetectionResult {
guard let cgImage = image.cgImage else {
throw VisionError.invalidImage
}
return try await withCheckedThrowingContinuation { continuation in
let request = VNClassifyImageRequest { request, error in
if let error = error {
continuation.resume(throwing: error)
return
}
guard let observations = request.results as? [VNClassificationObservation] else {
continuation.resume(throwing: VisionError.noResults)
return
}
// 信頼度でソート
let sortedResults = observations.sorted { $0.confidence > $1.confidence }
let classifications = sortedResults.map { observation in
VisionClassification(
identifier: observation.identifier,
confidence: observation.confidence
)
}
let topConfidence = sortedResults.first?.confidence ?? 0.0
let result = ObjectDetectionResult(
classifications: classifications,
topConfidence: topConfidence
)
continuation.resume(returning: result)
}
let handler = VNImageRequestHandler(cgImage: cgImage, options: [:])
DispatchQueue.global(qos: .userInitiated).async {
do {
try handler.perform([request])
} catch {
continuation.resume(throwing: error)
}
}
}
}
}
enum VisionError: LocalizedError {
case invalidImage
case noResults
var errorDescription: String? {
switch self {
case .invalidImage:
return "画像の処理に失敗しました"
case .noResults:
return "認識結果を取得できませんでした"
}
}
}
ありがとうございました〜〜〜〜〜〜〜〜〜