本記事は、OpenShift Advent Calendar 2022の16日目になります。
はじめに
分散トレーシングは、マイクロサービスのサービス間の処理にかかったサービスの処理時間を見たりする用途が多いと思いますが、
サービス内でDBアクセスした場合に、どのDBアクセスが遅いのかなどサービス内部の内部保留時間を知りたいことがきっとあると思います。
この記事では、Quarkusのデモアプリをベースに、サービス内の分散トレーシングどうやって取ってるのかを見ていきます。
ちなみに今回は使いませんが、OpenShiftでは、分散トレーシングのOperatorとして以下を提供してます。
・Red Hat OpenShift distributed tracing platform (Jeager)
・Red Hat OpenShift distributed tracing data collection Operator (OpenTelemetry) 2022年時点はまだTP
https://docs.openshift.com/container-platform/4.11/distr_tracing/distributed-tracing-release-notes.html
あと、半年前に分散トレーシング(OpenTelemetry)について、ざっくり書いた記事がありますので、よろしければ、ご参照ください。
https://qiita.com/takashyan/items/9ad6fc76e073b2a6eff2
サンプルを動かしてみる
Quarkusのオブザーバビリティ(OpenTelemetry + Jeager + Prometheus)のデモがあります。
簡単にデプロイできるので、これをサンプルとして使います。
これは、QuarkusのSuper-Heroes Workshopをベースにして、オブザーバビリティを足したもので、ヒーローと悪党を呼び出すマイクロサービスがあって、ヒーローと悪党を戦わせるという世界観がよくわからないサービスになっています。
また、このデモは、無償で使える Red Hat OpenShiftのDeveloper Sandboxでも動かすことができます。
とりあえず、動かしてみます。
プロジェクト名は適当な感じで、oc applyを叩いていきます。
$ oc new-project hoge-dev
$ oc apply -f https://raw.githubusercontent.com/quarkusio/quarkus-super-heroes/main/deploy/k8s/java17-openshift.yml
$ oc apply -f https://raw.githubusercontent.com/quarkusio/quarkus-super-heroes/main/deploy/k8s/monitoring-openshift.yml
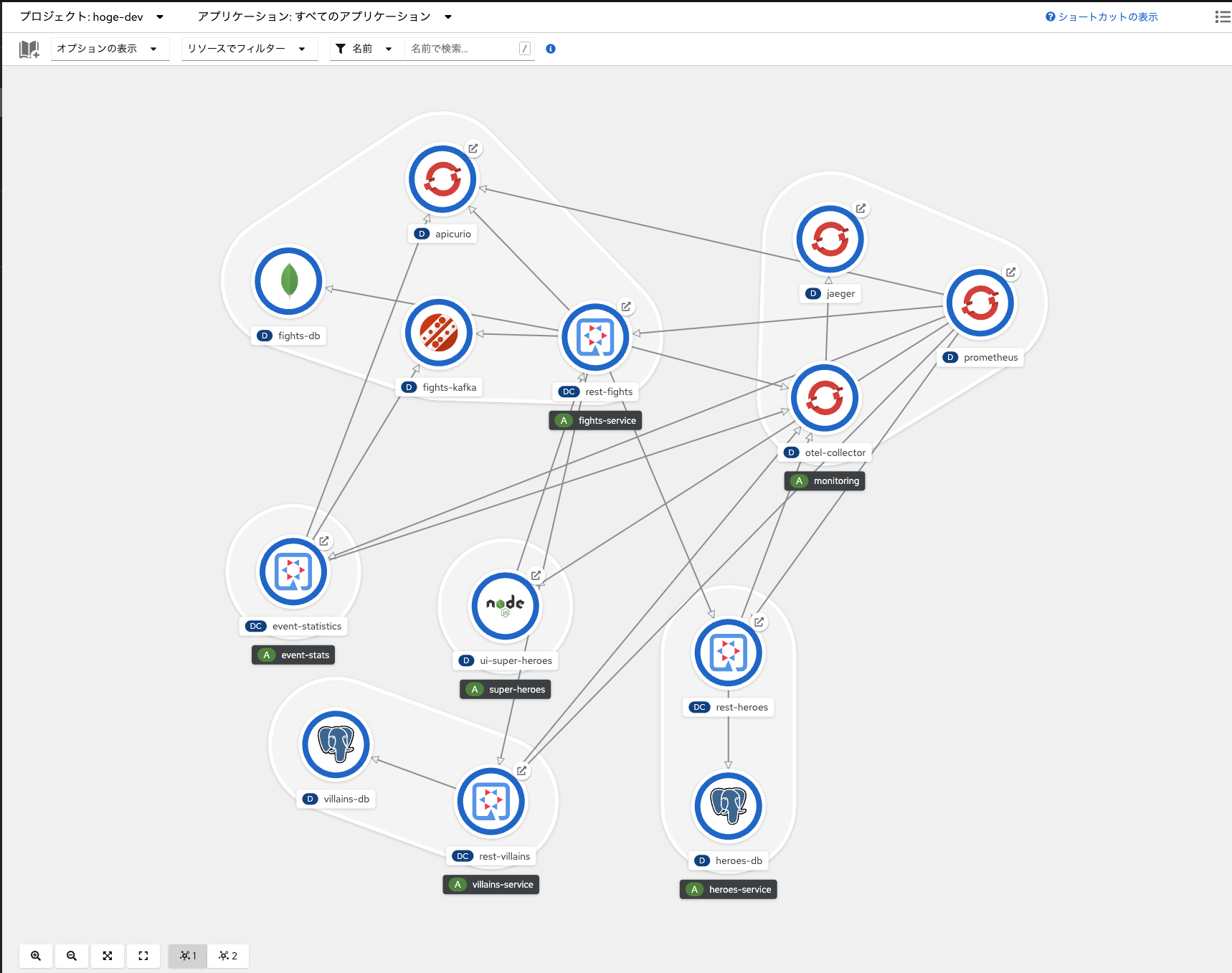
トポロジービューをみると、色々デプロイされてます。
トレースを見てみる
rest-fightsの右上のアイコンを叩いて、アプリを1回動かします。
その後に、Jeagarの右上のアイコンを叩いて、分散トレースの結果を見てみます。
いい感じで、トレースが取れています。
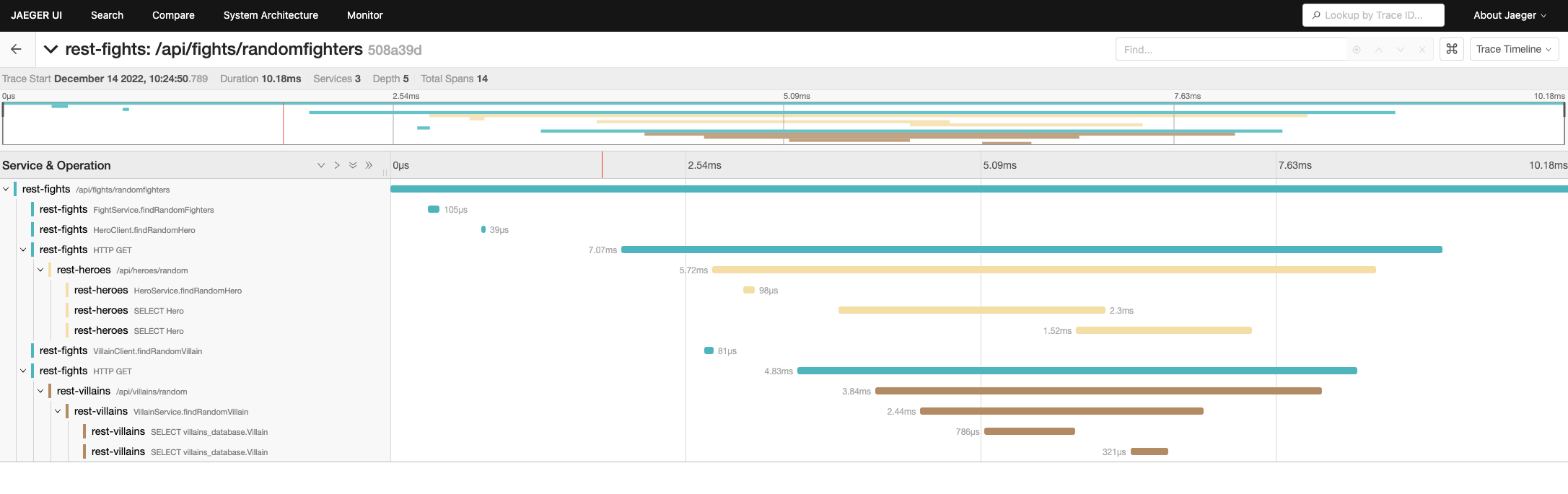
Villainというサービスのところをみると、3つ出ています。
・VillainService.findRandomVillain
・SELECT villains_database.Villain
・SELECT villains_database.Villain
要は、VillainService.findRandomVillain1回呼び出して、その後2回SQLを実行しています。

VillainService.findRandomVillainは、以下のようになっています。
元ソース:https://github.com/quarkusio/quarkus-super-heroes/blob/main/rest-villains/src/main/java/io/quarkus/sample/superheroes/villain/service/VillainService.java
@Transactional(SUPPORTS)
@WithSpan("VillainService.findRandomVillain")
public Optional<Villain> findRandomVillain() {
Log.debug("Finding a random villain");
return Villain.findRandom();
}
シンプルに@WithSpanアノテーションを呼び出して、新しいSpanを作って、トレースを出力しています。
次にSELECT villains_database.Villainですが、これはソースコード上にはありません。
Quarkusの定義ファイルapplication.propertiesでやっています。
元ファイル:https://github.com/quarkusio/quarkus-super-heroes/blob/main/rest-villains/src/main/resources/application.properties
# OpenTelemetry
quarkus.opentelemetry.tracer.resource-attributes=app=${quarkus.application.name},application=villains-service,system=quarkus-super-heroes
quarkus.opentelemetry.tracer.exporter.otlp.endpoint=http://localhost:4317
quarkus.datasource.jdbc.driver=io.opentelemetry.instrumentation.jdbc.OpenTelemetryDriver
これは、JDBCインスツルメンテーションというJDBC用OpenTelemetryラッパーで、SQLを実行する度にスパンを追加してくれます。
このサンプルではJDBCドライバー指定でやっていますが、以下のようにDatasourceにゴリゴリ書くこともできます。(例はSpring)
import org.apache.commons.dbcp2.BasicDataSource;
import org.springframework.context.annotation.Configuration;
import io.opentelemetry.instrumentation.jdbc.datasource.OpenTelemetryDataSource;
@Configuration
public class DataSourceConfig {
@Bean
public DataSource dataSource() {
BasicDataSource dataSource = new BasicDataSource();
dataSource.setDriverClassName("org.postgresql.Driver");
dataSource.setUrl("jdbc:postgresql://127.0.0.1:5432/example");
dataSource.setUsername("postgres");
dataSource.setPassword("root");
return new OpenTelemetryDataSource(dataSource);
}
}
さいごに
Quarkusのオブザーバビリティのサンプルをベースに、サービス内の分散トレーシングをどうやって取ってるのかを見ました。
ソースを修正することになってしまいますが、どこが遅い・遅くないが一目でわかるため、それに見合う価値はあると考えています。
また、常に遅いわけではなく、たまに異常に遅くなる場合などで、サービス間の処理時間しかわからない場合は、
各サービス間のログと突き合わせなどして、かなりの時間を要してしまいますが、内部のトレースもあれば、かなり解析は早くなると思います。
利用するランタイムやフレームワークによっては、ソース修正せずに済むJDBCインスツルメンテーションを使う手もありますが、
SQLを実行する度にスパンをガンガン追加されると、分散トレースが性能に影響を与える場合もあるので、デバック用な気もします。。
SQL文が長い又は明らかに時間を要するものはソースコード中に明示的にスパンを入れるといいような気がします。
参考
QuarkusのOpenTelemetryについて: USING OPENTELEMETRY
JDBCインスツルメンテーションについて: Library Instrumentation for JDBC