はじめに
この記事はQualiArts Advent Calendar 2023の17日目の記事になります。
StableDiffusionが公開されたのが2022年8月、ChatGPTが公開されたのが2022年11月。
これらのものが公開されてからまだ1年ほどしか経っていないというのは、私にとって未だに信じがたいことです。
去年のAdventCalendarではChatGPTの公開に感動し、GPT-3.5でチャットボットを作ったという記事を書きました。
それから1年経ち、今年はChatGPTを業務に応用したことについて書きます。
経緯
今年の5月ごろに、バックオフィスの方から問い合わせの対応業務を削減できないかという相談がありました(現状、1ヶ月あたり50件ほどのお問い合わせ対応が発生しています)。
QualiArtsでは基本的にお問い合わせはSlack経由で行われているのですが、オフィスに関する情報は社員なら見ることができるサイトにすでにまとめられていました。
しかし、そのページに書いてあることに関しても問い合わせが多いことに悩んでいました。
以前からこのことは問題になっており、すでに数年前にchatbotを導入することで問い合わせを削減する施策を行っていました。
しかし、回答の精度が悪いことで、そのchatbotのみで完結することはほぼなく、また、誤っているものとして利用者に認識されているのか、正しい回答をしても読まれないという問題が発生していました。
(chatbotに回答を求めていないときにも反応して無駄に回答してしまうのがさらに無視される状況に拍車をかけていたように思います)
そこで、ChatGPTを利用することで、精度の良い回答を行うシステムを新たに作ることにしました。
要件
話し合った結果、要件は以下のようになりました。
- 簡単なお問い合わせに関しては、chatbotのみで完結できるようにする
- お問い合わせ方法は今まで通りslackで行えるようにする
- 結論の参考にした資料(URL)を同時に提示する
その理由について説明します。
簡単なお問い合わせに関しては、chatbotのみで完結できるようにする
簡単なお問い合わせ(バックオフィスの方の対応が必要なく、ドキュメントに情報があるもの)に関しては、chatbotのみで完結できることを目標にしました。
お問い合わせの中にはアカウント作成などの操作が必要なものがありますが、その操作を代行するシステムを作ることは難しいので今回の仕様には含めないことにしました。
お問い合わせ方法は今まで通りslackで行えるようにする
お問い合わせの方法については、別のサイトを作ることも検討されました。
しかし、お問い合わせ専用のサイトを用意する場合、利用者にそのサイトのURLや使い方を教える必要があります。
加えて、やり取りのしやすさなどの利便性からslackのチャンネルは残す必要があったため、専用のサイトを用意しても、結局slackのチャンネルから直接問い合わせがされるおそれがあると考えました。
そこで、やはりお問い合わせは従来の通りslackを利用する方針となりました。
結論の参考にした資料(URL)を同時に提示する
このchatbotを作るという話になったときから、ドキュメント群をもとにChatGPTに回答を生成させる方法があるというのは知っていました。これにより、ChatGPTにより、会社特有の情報を精度高く自然な文章で回答させることができると期待していました。
一方で、ChatGPTにはハルシネーションの問題(ざっくりいうと、もっともらしい嘘をつくことがあるという問題)があることもわかっていました。もし、嘘の情報が頻繁に出て、返答が当てにならないということになれば、先代のchatbotと同じ轍を踏むことになります。それは避けねばなりません。
そこで、回答を生成する際に利用した、関連性が高いと思われる資料のURLを回答に含めることにしました。
システム(わとそん)の構成
このお問い合わせ対応を自動化するシステムは「わとそん」と名付けられました。

(余談ですが、このイラストを描いてもらうにあたって、「犬 探偵」だったかでイラストを生成してみて、イメージに合うものをイラストレーターさんに渡して、こういうイメージのものをお願いしますと依頼しました)
わとそんの構成は以下のようになっています。
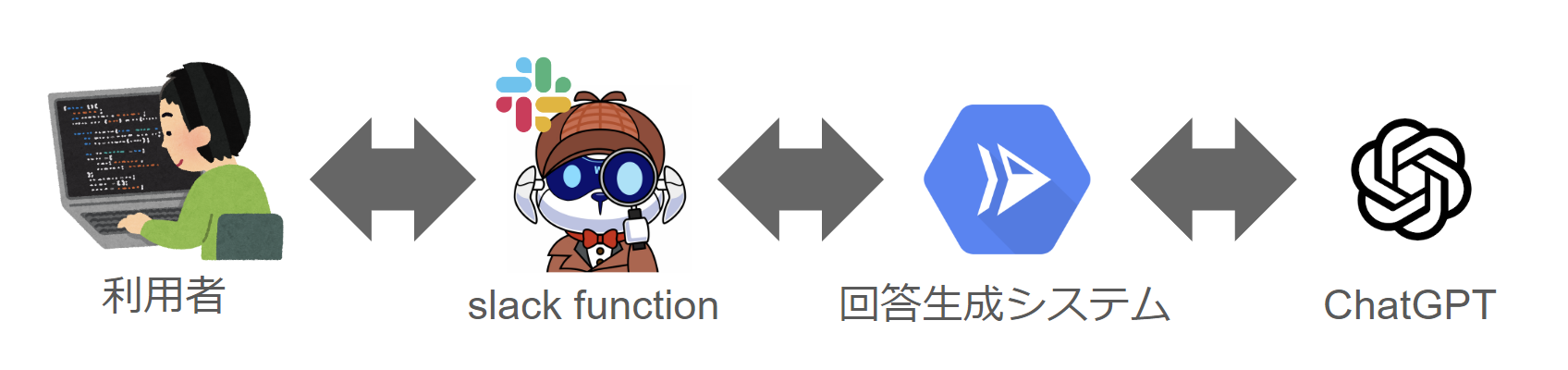
slackbot
slackbotはSlackPlatform上で実装されています。
こちらは@karamaruさんが実装を担当しました。
主な挙動としては、以下のとおりです。
- 利用者がslackのworkflowからslackbotにメッセージを送る
- メッセージを受け取ったslackbotは回答生成システムにその内容を渡す
- 回答生成システムのレスポンスを受け取り、整形して、slackに回答を投稿する
また、スレッド中でメンションをつけることで、スレッド内の話の流れに沿って再度わとそんに問い合わせることができるようになっています。(ただ、実装したもののあまり利用されていないのが悲しいです…)
回答生成システム
回答生成システムでは、slackbotから受け取った問い合わせの内容を、LangChainのRetrievalQAを介してChatGPTに投げ、回答を生成します。
このシステムはPythonにより実装しました。
RetrievalQAについて
RetrievalQAはLangChainの機能の1つです。
- LangChain: https://www.langchain.com/
- RetrievalQA: https://js.langchain.com/docs/modules/chains/popular/vector_db_q
今回、我々はシステムに対して一般的な回答を求めているわけではなく、弊社のオフィスに関わる情報、つまりプライベートな情報に関して回答を求めています。
しかし、ChatGPTは(あたりまえですが)弊社のオフィスに関わる情報を持っていません。加えて、弊社の情報を加えたモデルを再学習し使うこともできません。
そこで、プロンプトの中に弊社のオフィスの情報を加えて、その上で質問を投げるということが必要になります。
ただ、ここでも1つ問題が発生します。それは、プロンプトに含めることができる情報量(文字数)にも限界があるということです。
なので、システムは今回のお問い合わせに必要と思われる情報を厳選し、プロンプトに含める必要があります。
そこで便利なのが今回利用したLangChainのRetrievalQAのようなものです。
RetrievalQAでは複数のドキュメントを読み込み、それをベクトル化し保持します。プロンプトが渡されたとき、プロンプトもベクトル化し、類似性が高いドキュメントを検索します。これにより、関連性の高い情報を厳選してChatGPTへのプロンプトに含めることができるようになります。
同様な機能を持ったものとしてLlamaIndexというものもあります。こちらも試しまして、結果は悪くありませんでした。しかし、LlamaIndexの方では参考としたドキュメントをリストアップすることができなさそうだったので、今回はLangChainの方を利用することに決めました。
実装に際して発生した問題
わとそんを実際に実装するにあたって、いくつかの問題が発生しました。
その中の1つについて記します。
先述したように、オフィスに関する情報は社員なら見ることができるサイトに纏められていました。
具体的には、そのサイトはGoogleSite上で作られており、QualiArtsのアカウントを持っていれば見ることができるようになっていました。
そこで、RetrievalQAのドキュメント読み込みの際にそちらのサイトを読み込ませることを考えていました。
しかし、ここでいくつかの問題があることがわかりました。
- アカウントを持っていないとアクセスできないので、システムがアクセスすることが難しい
- ページ上に不要な情報が想定以上に多い
- 構造化されていないので、情報間のひも付きがわかりにくい
1つ目の問題は最悪ダウンロードするなり、サイトのアクセス制限を変更することで対応できそうだったので大きな問題ではありませんでした。
大きな問題だと考えたのは2つ目と3つ目の問題です。
まず、不要な情報が多いということですが、GoogleSiteで作られたページのソースを確認したところ、ページ上に表示されている文がどこにあるのかわからないレベルでタグのプロパティなどの情報にあふれており、たった何十行かの短い文章が書かれたページがソースにして100KB以上のものに膨れ上がっていました。
また、3つ目の問題として書いたことですが、作られていたドキュメントはGoogleSiteで作られていた関係で、自由なフォーマットで書くことができ、強引に2段組みのようになっていたページもありました(Q&Aを左右に分け、ページ左側に「喫煙場所」、右側に「20時以降は裏口から…」といったようになっていたページがあった)
これではRetrievalQAで利用するドキュメントとして不適切と考え、別にシンプルなドキュメントを用意することにしました。
最終的に、RetrievalQAに読み込ませるドキュメントは、そのサイトから情報を書き写したmdファイルになっています。
成果
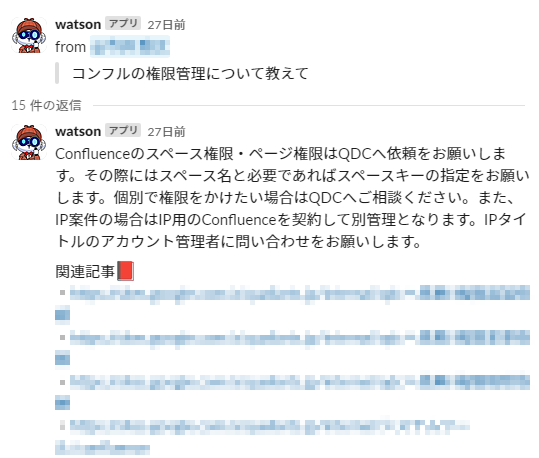
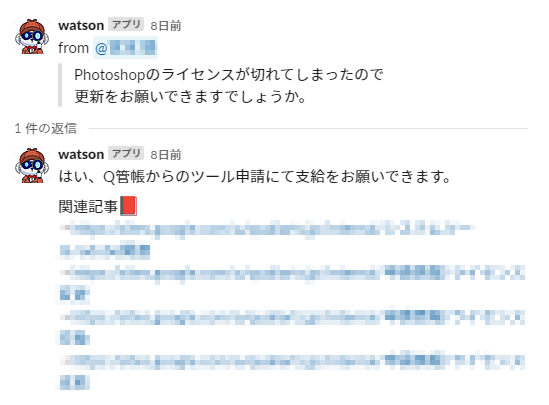
現在はこのように運用が始まっています。
現状ある程度正しい回答が返せているようで、バックオフィスの方から対応件数がだいぶ減って楽になったとの嬉しい報告がありました。
残された課題と展望
ドキュメントの2重管理
先述したように、現状RetrievalQAに読み込ませるドキュメントはmdファイルとなっています。
しかし、元々あったサイトは不要になったわけではなく、わとそんの回答にもそのURLが含まれているため、なにか情報に更新があったときは、mdファイルとサイトの両方を更新する必要があります。この運用は望ましくありません。
そこで今後はGoogleSiteを止め、mdファイルを1次ソースとして、Pandocなどを利用してmdファイルからhtmlファイルを生成し、利用者がアクセスできる場所に置くことを考えています。
URL中のハイフンが抜け落ちる
ドキュメントの中には、各種ページへのURLも記載されています。
しかし、このURLにハイフンが含まれているとき、ChatGPTからの回答にはそのハイフンが抜け落ちるという問題が発生しました。それによりアクセスできないURLが提示されたり、最悪のパターンでは関係ないドメインと一致してしまい、提示されたURLを踏むと怪しいページにアクセスしてしまうという問題が発生しました。
こちら、現在も原因が不明なのですが、ドキュメント中に存在するURLはそんなに多くなかったので、結果にハイフンが抜け落ちたURLがあったとき、強引に置換することで応急処置しました。
こちらの根本的解決はしたいと思っています。
結果を出すまでの時間がSlackPlatformのタイムアウト時間を超えてしまう
今回、slackbotとして、SlackのPlatformを利用しましたが、それにより、処理を15秒以内に収める必要がありました(参考: https://api.slack.com/automation/functions)
一方で、回答生成システムはGCPのCloudRunでデプロイされていますが、起動ごとにドキュメントのベクトル化を行っており、これが10秒弱かかっています。これにより、普通にインスタンスの起動から行ってしまうと15秒を稀に超えてしまうという問題が発生しました。なので、本当はコールドスタートにしたかったのですが、一旦1台のインスタンスは常に立ち上がってるようにしました。
こちらは、今後はイメージビルド時にドキュメントのベクトル化を行い、結果を何らかの方法で保存しておいて、起動時にそのデータを読み込むだけの形にしたいと思っています。
まとめ
今回、バックオフィスの方の業務を改善するため、ChatGPTを利用したslackbotを作りました。
回答生成のための技術としてはLangChainのRetrievalQAを利用しました。
結果として、それなりに良い回答が得られており、バックオフィスの方の対応が必要なお問い合わせ数は減少したとのことでした。