概要(TL;DR)
50列x300万行のcsvの中に、いずれの列でも良いので、ある文字が含まれている行を抽出して欲しいという依頼を受けて、まさかExcelでは開けないので、Pandasで試してみた。
注意
grep使えば・・・とか絶対に言わないこと。あくまでもpandasの練習なんです。
サンプルデータ
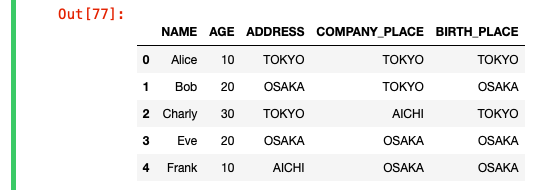
流石に50列x300万行のcsvで書くと面倒なので、下記をサンプルデータとする。(実際のデータはNaNとかもあるので、もう少し複雑だった。)
df = pd.DataFrame({"NAME":["Alice","Bob","Charly","Eve","Frank"],
"AGE":[10,20,30,20,10],
"ADDRESS":["TOKYO","OSAKA","TOKYO","OSAKA","AICHI"],
"COMPANY_PLACE":["TOKYO","TOKYO","AICHI","OSAKA","OSAKA"],
"BIRTH_PLACE":["TOKYO","OSAKA","TOKYO","OSAKA","OSAKA"]
})
df.head()
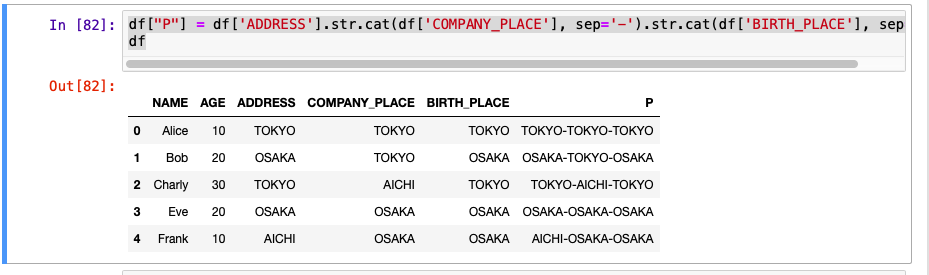
作戦A:すべての列を結合した列を作る
全部の列を結合させて、その列に対して部分一致検索をすればいいじゃないか!
df["P"] = df['ADDRESS'].str.cat(df['COMPANY_PLACE'], sep='-').str.cat(df['BIRTH_PLACE'], sep='-')
df
df[df["P"].str.contains("OSAKA")]

サンプルは5カラムだけど、実データは50列・・・。全部足すのはちょっと・・・。
作戦B:列の結合を工夫しよう
df = df.drop("P",axis=1)
df["P"] = [""] * len(df)
for column in df.columns.values:
if column != "P":
df["P"] = df["P"].str.cat(df[column].astype(str), sep='-')
df[df["P"].str.contains("OSAKA")]
文字列と数字が混ざる危険性があるので、catするときにastype(str)しておくのがポイント。

作戦C:各列を検索して、結果をまとめる。
df["P"] = [False] * len(df)
for column in df.columns.values:
df["P"] = df["P"] | df[column].astype(str).str.contains("OSAKA")
df[df["P"]]

結論
やっぱりgrep + awkが最強。
いいトレーニングにはなったけど、策に溺れた気分・・・・。