はじめに
この記事は、第5回スタートアップiOS勉強会 - connpassでの同名の発表を文章形式でリライトしたものです。
スライド版(Speaker Deck)はこちら。
String と NSString
「文字列の特定の単語に色をつけて、textViewに表示したい」
…という、ヒトなら誰しもが持つ欲望をさらけ出してください。
そう言われたあなたは、以下のようなコードを書くかもしれません。
func coloredText(from str: String, target: String) -> NSAttributedString {
// 対象単語の出現範囲( Range<String.Index> )を取得
let range: Range<String.Index> = str.range(of: target)!
// Range<String.Index> を NSRange に変換
let nsRange = NSRange(location: str.distance(from: str.startIndex,
to: range.lowerBound),
length: target.characters.count
)
// 対象単語に色をつけて返す
let result = NSMutableAttributedString(string: str)
result.addAttributes(
[NSForegroundColorAttributeName: UIColor.red],
range: nsRange
)
return result
}
この関数に "日本チャチャチャ!" と "チャチャチャ" を与えれば、

このように、「チャチャチャ」だけが赤く色づきました。
一見、うまく動いているコードに見えます。
しかし、これで安心してしまったあなたは、実は見えない罠に嵌まってます。
試しに、 "日本チャチャチャ!" に絵文字 "🇯🇵" を付け加えてみましょう。

「チャチャチャ」ではない部分が赤くなった上に、文字化けまで起こっています。
一体、何故こんなことが起きたのでしょうか。
それは、StringとNSStringの違いを理解せずにコードを書いてしまったからです。
String と NSString 何が違う?
struct と class?
Swift と Obj-C?
いいえ。
それ以上に重要な違いがあります。
NSString は、
- 内部的にはUTF-16でバイト列を保持
- UTF-16のバイト列を操作するためのAPIを提供
というデータ構造です。
それに対してSwiftの String は、
- 内部のバイト列は隠蔽
- 文字列操作のために、書記素クラスタおよび各種UnicodeのコードユニットのViewを提供している
というデータ構造です。
おわかりでしょうか。
…はい、よくわかりませんね。View? 書記素クラスタ?? 各種Unicodeのコードユニット??? 🤔
これらの宇宙語を理解するためには、「そもそもUnicodeとは何か」を紐解く必要があります。
Unicodeとは
コード空間とコードポイント
符号化文字集合や文字符号化方式などを定めた、文字コードの業界規格である。
文字集合が単一の大規模文字セットであること(「Uni」という名はそれに由来する)などが特徴である。
Unicode規格は、21bitの整数値空間(コード空間)を提供しています。これは概念的な空間です。実際のバイトデータとは切り離して考えてください。
世界中のすべての文字は、この空間内のユニークな整数値へと割り当てられます(符号化)。
そして、割り当てられた値を、コードポイントと呼びます。
コードポイントは U+(16進数) で表現されます。
- BMP(基本多言語面) =
U+0000〜U+FFFF - SMP(追加面) =
U+10000〜
具体的には、こんな感じ👇ですね。

エンコーディング
21bitのコード空間を、どうやって実際のバイト列として表現するか?
Unicodeの「コード空間」「コードポイント」という概念については理解できました。
しかし、実際にこれをバイト列として表現するにあたっては、いくつか方法が考えられます。
この方法を エンコーディング と呼びます。
同じコードポイントでも、バイト列表現にはバリエーションがあるのです。
各エンコーディングの違いは、 **「特定のコードポイントを表現するための最小単位を何bitにするか」**の違いです。
そして、最小単位を コードユニット と呼びます。
UTF-8 UTF-16 UTF-32…という、この数字は、コードユニットが何bitになるかを示すものです。
コードポイントとコードユニットという単語、紛らわしいけど、よく覚えておいてくださいね。
コードポイントってのは、概念的なidみたいなもの。
コードユニットは、そのid自体がデカいので小分けにして詰め込むための、箱のサイズです。
それでは各エンコーディングを、詳しく見てみましょう。
UTF-32

- 1コードユニット = 32bit(4バイト)
- 1コードポイント = 4バイトの固定長
UTF-32のコードユニットは、32bit。コード空間(21bit)より巨大です。そのため完全固定長で表現できる!というのがUTF-32の強みです。
たとえ1世紀後に宇宙文明とコンタクトして、収録しなきゃいけない文字が今の1000倍になったとしても、耐えきれるポテンシャルの持ち主です。
その分、データとしては無駄が大きいんですけどね。 abc と書くだけで12バイト。ヤバいですね。
UTF-16

- 1コードユニット = 16bit(2バイト)
- 1コードポイント = 2バイト or 4バイトの可変長
実は、Unicode 1.0.0の頃は、このUTF-16の範囲内に世界中の文字が収まる想定でした。かつてコード空間は16bitだったのです。
しかし、想定外の事件が次々に起こり、コード空間は21bitに拡大を余儀なくされました。結果、UTF-16はサロゲートペアという苦し紛れの策を取ったのですが、それについては省略。
我々プログラマが憂慮すべきは、その頃生まれたプログラム言語が「Unicodeの最終形はUTF-16だ」と思い込んで設計されていることです。
Objective-Cも、例外ではありません。
UTF-8

- 1コードユニット = 8bit(1バイト)
- 1コードポイント = 1バイト〜4バイトの可変長
今回のトピック絡みではあまり説明することのないエンコーディング形式です。おじいちゃん(ASCIIコード)とも意気投合できる、良い奴ですよ。
抽象文字、書記素クラスタ
ここまで読まれたあなたは、「コードポイントって用語、分かりづらいな」と思われているかもしれません。
「要は『一文字』のことでしょ」と理解しているかもしれませんね。
けど、実は違うんです。
「一文字」は、Unicode界隈では**抽象文字(abstract character)**と呼ばれるそうです。
言い換えると、「カーソルキーの移動単位」と考えるといいかもしれません。
で。抽象文字と符号化文字は 多対多 の関係なのです。
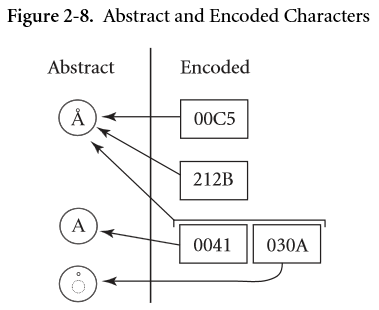
さらに、コードポイントにはそれ単体では成立せず、組み合わせて使うものもあります。
組み合わされて成立した抽象文字を 書記素クラスタ (grapheme cluster) といいます。
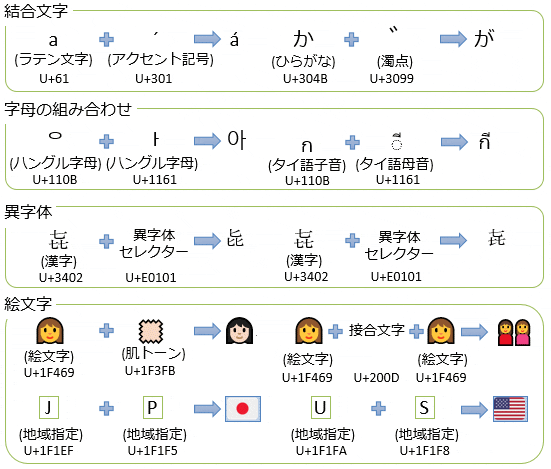
Unicodeとは? その歴史と進化、開発者向け基礎知識より
余談:グリフ(glyph)
グリフ(glyph)というまた別の概念もありまして、
- 文字の見た目(位置、サイズ)の情報
- 文字は必ず左から右に流れるわけじゃないでしょ、ってこと
- CoreTextで管理される
…のだけど、今回は省略。
ここまでのまとめ
Unicode自体の話は、これでおしまいです。
だいぶ用語が増えて混乱してきた頃合いでしょうから、一旦まとめましょう。
- 抽象文字の作りかた
- コード空間(21bit)内にコードポイントがあるので、
- 割り当てられた符号化文字
 ,
,  を組み合わせて
を組み合わせて -
抽象文字 / 書記素クラスタ
 を作る
を作る
- エンコーディングとは
- 特定の コードポイント (最大21bit)を
- 規定サイズの コードユニット (8bit / 16bit / 32bit) に詰め込む方法
Unicode と Swift.String のAPI
ここまで、Unicodeとは何か、どのように文字が表現され、そこにエンコーディングがどう関わるかを説明してきました。
ここからは、Unicodeがどのように Swift.String のAPIで表現されているかを説明します。2
Swift.String は、書記素クラスタおよび各種UnicodeのコードユニットのViewを提供している、と述べました。
var characters: String.CharacterViewvar unicodeScalars: String.UnicodeScalarViewvar utf16: String.UTF16Viewvar utf8: String.UTF8View
Stringは、これらの4つのViewを通して操作することができます。
※UTF-32はUnicodeのコード空間を内包するので、 UnicodeScalarView という名前
4つのViewを使ってみよう
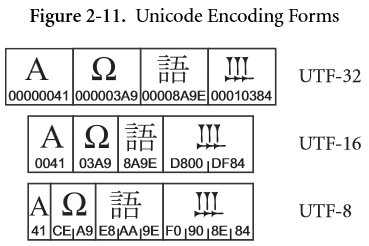
👆の図に登場する文字列 "\u{41}\u{3A9}\u{8A9E}\u{10384}" を各Viewで表現したとき、そのcountはいくつになるのか確かめてみましょう。
let str = "\u{41}\u{3A9}\u{8A9E}\u{10384}"
str.characters.count //4 👈書記素クラスタ
str.unicodeScalars.count // 4 👈UTF-32でのコードユニット数
str.utf16.count // 5 👈UTF-16でのコードユニット数
str.utf8.count // 10 👈UTF-8でのコードユニット数
図と出力結果の辻褄、合っていますね!
String.CharacterView は 強い
書記素クラスタは、人間の考える「一文字」だと先程述べました。
つまり、「一文字」をカウントするのは String.CharacterView であると言えます。
このイケメンは、Unicodeの複雑な仕様を吸収してくれます。合字もいい感じに処理してくれます。
var cafe = "Cafe" // "Cafe"
cafe.characters.last // "e"
cafe.characters.count // 4
cafe += "\u{301}" // "Café"
cafe.characters.last // "é"
cafe.characters.count // 4
うーん強い。
String.CharacterView は 常に最強ではない
…ただ、物によってはCharacterViewをもってしても「1文字」を認識できないこともあります。
"👩👩👧👦".characters.count // 4
何故でしょうか。
Unicodeとは? その歴史と進化、開発者向け基礎知識 - Build Insiderから引用します。
ただし、これらのルールや新しい文字は、Unicodeのバージョンアップに伴って随時追加されているわけで、実際にこれらが1文字として描画されるかどうかは環境依存である。OSがそのバージョンによって異なるのはもちろん、フォントによっても1文字で表示できるかどうかが変わる。結合文字などは古くからあり対応しているものも多いが、絵文字に関しては最近の仕様なのもあってかなりばらつきがある。
どれくらいバージョンアップがあるのかは、Unicode - Wikipedia #各バージョンとその特徴で確認できます。
結構頻繁ですね。
ということは、わかりますか?
「文字数に従って云々してくれ」というアプリの仕様が提示されたときには、心して挑まなければなりませんよ、ということです。
(追記 12/6)
ちなみに "👩👩👧👦" の正体については、丁度タイムリーに解説記事が上がっていました。
家族👨👩👦👦はreplaceされてしまうのか?あるいはZWJの話😂 - Qiita
http://qiita.com/todokr/items/8b813e14d3fdb4111cb7
いずれにせよ、SwiftのString APIはよく考えられています。
UTF-16が前提であるNSStringよりも、もっと本質的に「文字」を扱うことができるのが、 Swift.String のAPIであるといえます。
というわけで。
みなさん、もうNSStringのことはもう忘れて、今後は Swift.String と楽しく過ごして下さい💮
…。
…ってわけには、いかないんですよね。
Foundationに根を下ろし、NSStringと共に生きよう
そもそもの話の発端は、 NSAttributedString と UITextView でした。
どんなに良く設計されたValueTypeを作っても、Cocoaから離れては生きられないのです。
現実を受け入れた上で、ではどう生きるかを考えましょう。
NSStringは UTF-16
もう一度、バグを生んでいるコードを確認しましょう。
func coloredText(from str: String, target: String) -> NSAttributedString {
// 対象単語の出現範囲( Range<String.Index> )を取得
let range: Range<String.Index> = str.range(of: target)!
// Range<String.Index> を NSRange に変換
let nsRange = NSRange(location: str.distance(from: str.startIndex, to: range.lowerBound),
length: target.characters.count
)
// 対象単語に色をつけて返す
let result = NSMutableAttributedString(string: str)
result.addAttributes(
[NSForegroundColorAttributeName: UIColor.red],
range: nsRange
)
return result
}
Range<String.Index> を NSRange に変換 している部分が、なんだか臭いますね。
"🇯🇵" に対する String.characters と NSString でカウントの方式の違いを確かめてみましょう。
let flag = "\u{1F1EF}\u{1F1F5}" // "🇯🇵"
flag.characters.count // 1 👈書記素クラスタは 1
flag.unicodeScalars.count // 2 👈コードポイント2個
flag.utf16.count // 4 👈2コードポイント × 2コードユニット
flag.utf8.count // 8 👈2コードポイント × 4コードユニット
(flag as NSString).length // 4 👈utf16.countと一致
NSStringの内部表現はUTF-16です。納得の結果ですね。
じゃあ、rangeを取得する際には、 String.characters のかわりに String.utf16 を使えばいい?
いや、取得した範囲のRangeを構成する String.Index を Int に変換するのは手間ですよね?
そういうところでミスを犯したくないですよね?3
いえいえ、もっとシンプルで分かりやすい解決策があるのです。
NSStringを使わなきゃいけないなら、最初からもう、Cocoaの世界で処理を閉じたほうが良い
つまり、
let range = str.range(of: target)!
// Range<String.Index> を NSRange に変換
let nsRange = NSRange(
location: str.distance(from: str.startIndex, to: range.lowerBound),
length: target.characters.count
)
👆こう書くのではなく、
👇こう書けばいいのです。
let nsStr = NSString(string: str)
// 一度NSStringの世界に入れば…
let nsRange = nsStr.range(of: target)
// Range<String.Index>を介さないので、変換処理不要

範囲ズレも文字化けも解決し、コードも分かりやすくなりました ![]()
今日の結論。
-
StringとNSStringは別物-
Range<String.Index>とNSRangeも別物 - Cocoa世界が関わる文字列操作は、必ず
NSStringのAPIを通しましょう
-
- あと、仕様に「文字数をカウントして云々」が出てきたら身構えましょう
以上、みなさん気をつけていきましょうね。
参考リンク
Unicode のサロゲートペアとは何か - ひだまりソケットは壊れない
http://vividcode.hatenablog.com/entry/unicode/surrogate-pair
なぜSwiftの文字列APIは難しいのか | プログラミング | POSTD
http://postd.cc/why-is-swifts-string-api-so-hard/
Unicodeとは? その歴史と進化、開発者向け基礎知識 - Build Insider
http://www.buildinsider.net/language/csharpunicode/01
Unicodeと、C#での文字列の扱い - Build Insider
http://www.buildinsider.net/language/csharpunicode/02
Swift 3のStringのViewに対して、Intでsubscript出来ない理由 – Swift・iOSコラム – Medium
https://medium.com/swift-column/swift-string-7147f3f496b1#.x1n3vrh1p
-
正直、公式リファレンス( https://developer.apple.com/reference/swift/string )がとても分かりやすいのでそっち読むといいです。 ↩
-
あえてそういうデザインになっている理由を考えるにあたっては、「Swift 3のStringのViewに対して、Intでsubscript出来ない理由 – Swift・iOSコラム – Medium」が参考になると思います。 ↩