リクルート レストラン客数予測チャレンジのチュートリアルをやってみた記事です。
手順の詳細はリンク先にも載っていますので、ここでは補足事項など記載しながらまとめてみようと思います。
参考にしたチュートリアルはこちら
使用しているデータはこちら
提出用データ形式の確認と前処理
まずはライブラリのインポートを行います
import numpy as np
import pandas as pd
import glob, re
はじめに、Kaggleへの提出データの形式の確認を行ってみます。
これはsample_submission.csvで確認できます。
# データの読み込み&確認
test_df = pd.read_csv('sample_submission.csv')
test_df.head(10)
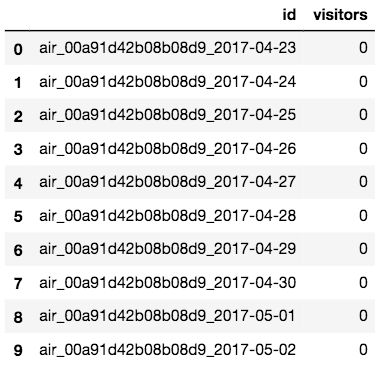
データ形状の確認もしてみます。
test_df.shape
# -> (32019, 2)
こちらに入ってるAirレジのレストランidと日付を使って、実客数の予測をしていきます。
見てわかるように、id列のデータ形状がよくありません・・・
最初から日付とidぐらい別カラムにしてほしいですね。仕事でDB設計やるときもあるので、なおさら気持ち悪いです笑
「air_ストアID_日付」と3つの情報がアンダースコアで連結されているので、前処理として、このIDを情報毎に分解しましょう。
# 元々のIDからstore_idとvisit_dateを切り出す
# str[:20]は最初から20文字目までを取得している
test_df['store_id'] = test_df['id'].str[:20]
test_df['visit_date'] = test_df['id'].str[21:]
# 提出ファイルサンプルのvisitorsカラムは無意味なので削除
# axisは次元を指定しており、axis=0は行、axis=1は列を表す(デフォルトは0)
# inplace=Trueとすると、元のデータフレームが変更される。
# デフォルトでは、元のデータフレームは変更されずに、新しいデーフレームが返される
# 今回は元のデータフレームを変更させている
test_df.drop(['visitors'], axis=1, inplace=True)
# 日付型へ変換
test_df['visit_date'] = pd.to_datetime(test_df['visit_date'])
# データの表示
test_df.head(10)
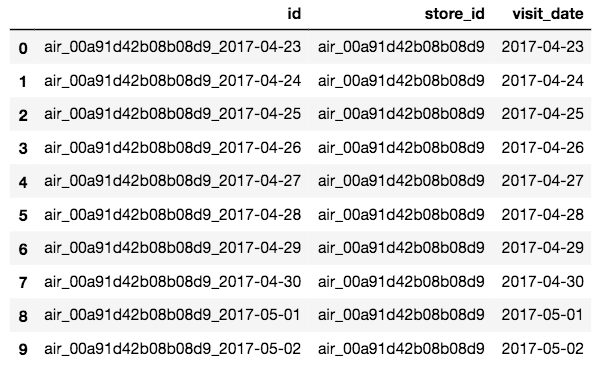
元のデータと比べると、visitors列が削除され、新たにstore_id列,visit_date列が追加されているのがわかります。
ステップ① 過去データの曜日毎の中央値(median)を算出
訓練用データの読み込みと前処理
次にair_visit_data.csvの読み込みと前処理をします。
air_visit_data.csvですが、Airレジの各レストランの日付と実客数のデータとなります。
つまり予測しなくてはいけないレストランの過去の実客数の実績データです。←重要
このデータを処理してレストラン/曜日毎の**「中央値(Median)」**を算出します。
# 実際の客数データを読み込む
air_data = pd.read_csv('air_visit_data.csv', parse_dates=['visit_date'])
air_data.head()
試しに、1つのレストランについてデータを参照してみます。
# 1つのレストランIDを取り出して、データを参照してみる
check_store_sample = air_data[air_data['air_store_id'] == 'air_00a91d42b08b08d9']
round(check_store_sample.describe(), 2)
# 日付の統計情報も出力
check_store_sample.visit_date.describe()
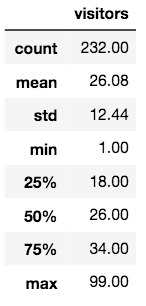

統計情報を見てみると、少ない日は1人、多い日は99人の利用者がいることがわかります。
また、このデータは2016/07/01~2017/04/22までの利用者のデータが格納されていることもわかります。
では、データの前処理を行なっていきましょう。
前処理でやる事としては、主に下記の3つです。
- 2017-01-28以降のデータの切り出し
- visit_dateを基に曜日のデータ作成(曜日をベースに予測するため)
- 曜日とレストランIDを基にグルーピングして中央値を算出
# 日付を曜日へ変換
# 予測するときに曜日をベースに予測するため
air_data['dow'] = air_data['visit_date'].dt.dayofweek
# air_dataから2017-01-28以降のデータを切り出して訓練データ「train」へ格納
train = air_data[air_data['visit_date'] > '2017-01-28'].reset_index()
# trainとtest_dfも日付を曜日へ変換して「dow」をカラム追加する
train['dow'] = train['visit_date'].dt.dayofweek
test_df['dow'] = test_df['visit_date'].dt.dayofweek
データを確認してみると、dow列が追加され、0~6までの数値(日曜~土曜)が設定されていることがわかります。
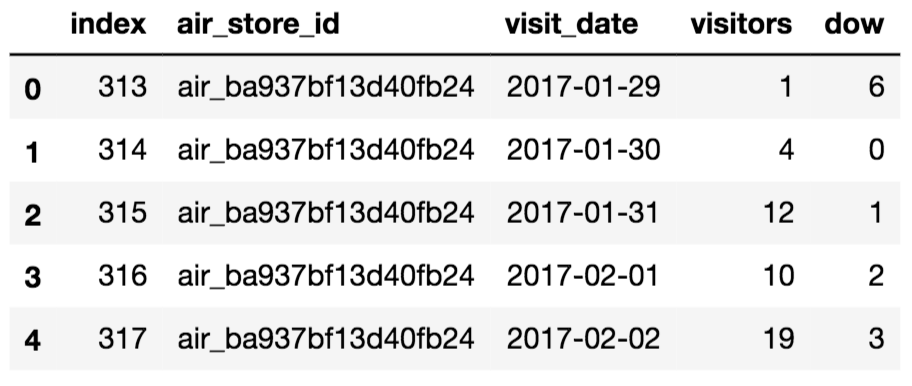
-
train
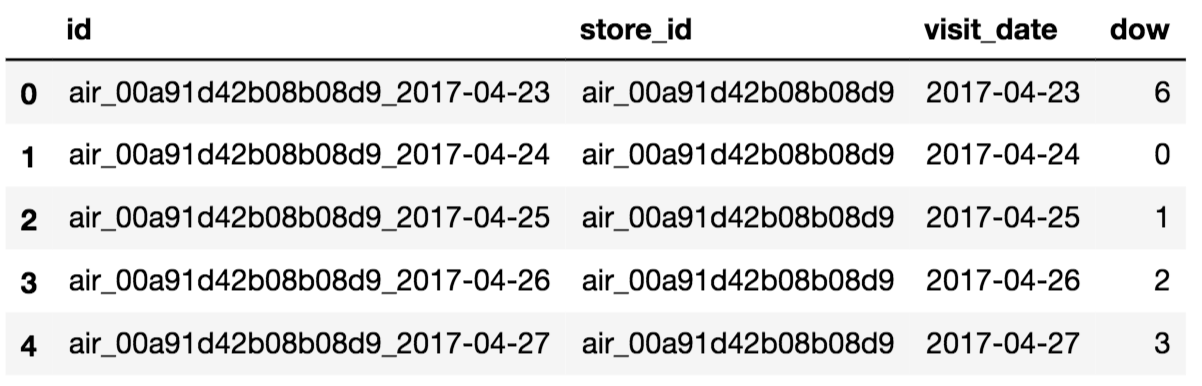
-
test_df
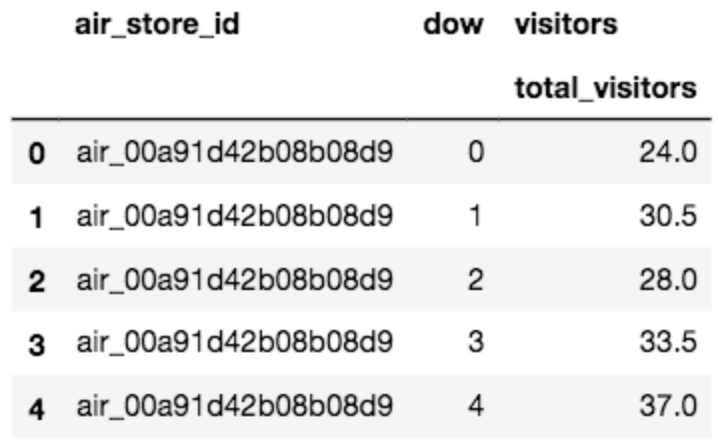
次はtrainからair_store_idとdowをグルーピングして、median(中央値)を取り出します。
# pandasのagg関数で使うリストを作成
aggregation = {'visitors' : {'total_visitors' : 'median'}}
# trainからair_store_idとdowをグルーピングしてvisitorsの中央値(median)を算出
# groupbyメソッドは、指定したカラム単位で値を集約することができる
# agg() メソッドは、辞書型のオブジェクトを渡すことでカラムに対して特定の集計をするように指示できる。
agg_data = train.groupby(['air_store_id', 'dow']).agg(aggregation).reset_index()
補足
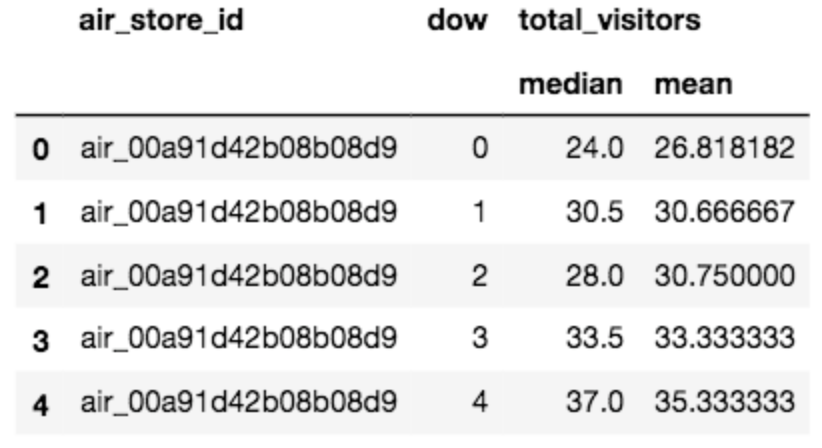
補足ですが、agg()関数では、複数の集計を同時に行うこともできます。
# 中央値と平均値をいっきに計算したい場合は下記のように記述
aggregation = {'visitors' : {'total_visitors' : ['median', 'mean']}}
agg_data = train.groupby(['air_store_id', 'dow']).agg(aggregation).reset_index()
こんな感じでリスト化されます。便利ですね。
最後にカラム名の再定義を行います。
# agg_dataのカラム名をつける
agg_data.columns = ['air_store_id', 'dow', 'visitors']
# agg_dataを確認
agg_data.head(12)
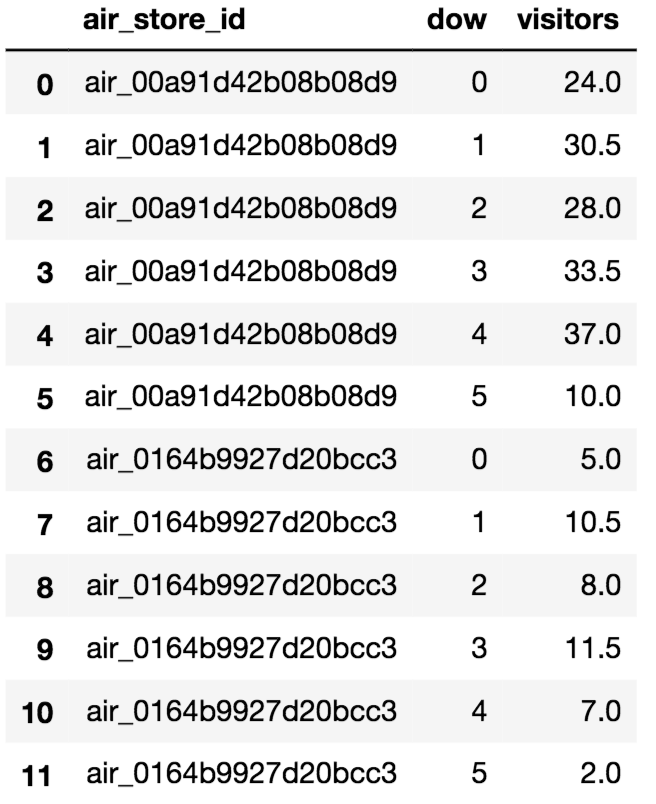
これで、レストランID, 曜日, その曜日に来た客の中央値のデータが完成しました!
基礎データフレームの生成
Kaggleへ提出するデータsample_submission.csvから前処理したtest_dfと、各レストランの実客数データair_visit_data.csvを処理して中央値を算出して作ったagg_dataをマージさせてみます。
# test_dfとagg_dataのstore_idとdowを条件にmergeさせる
merge = pd.merge(test_df, agg_data, how='left', left_on=['store_id', 'dow'], right_on=['air_store_id', 'dow'])
# idとvisitorsだけを出力データとして抽出(提出形式に合わせるタメ)
final = merge[['id', 'visitors']]
# 確認
final.head()
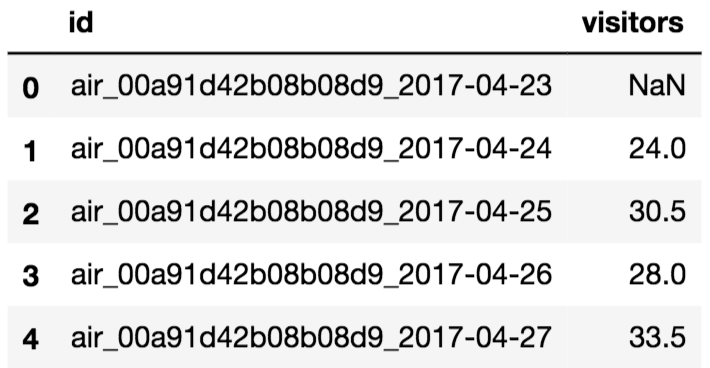
マージは成功しているようですが、NaNデータがありますね。
全体的にどのくらいNaNデータがあるか確認してみます。
def null_search(df):
for i in df.columns:
print("■■■ " + i )
print("NULL数:" + str(df[i].isnull().sum() )+
" NULL率:" + str((df[i].isnull().sum()/len(df)).round(3)) +
" データの種類数:" + str(df[i].value_counts().count()))
null_search(final)
# -> ■■■ id
# -> NULL数:0 NULL率:0.0 データの種類数:32019
# -> ■■■ visitors
# -> NULL数:1114 NULL率:0.035 データの種類数:163
1114データ、全体の約3.5%がNaNであることが分かりました。
これはよくないので、NaNのデータには0(来客0人)を設定することにします。
# fillna関数を使ってvisitorsのNaNへ0を入れておく
final.fillna(0, inplace=True)
# 念のため確認
null_search(final)
# -> ■■■ id
# -> NULL数:0 NULL率:0.0 データの種類数:32019
# -> ■■■ visitors
# -> NULL数:0 NULL率:0.0 データの種類数:164
ひとまずここまでで、予測しなくてはいけないAirレジレストランの各日付に対して、過去の曜日と実客数のデータから算出をした中央値を予測値としてもつデータが完成しました。
ステップ② 重み付き平均(加重平均)を算出
まず、他のCSVファイルもデータフレームに読み込んでおきます。
(CSVデータは冒頭のKaggleコンペページからダウンロードできます)
# 全てのCSVを一気に読み込む
# glob.glob('')に適切なファイルのパスを指定してください
dfs = { re.search('/([^/\.]*)\.csv', fn).group(1):pd.read_csv(
fn) for fn in glob.glob('./*.csv')}
for k, v in dfs.items(): locals()[k] = v
# 読み込んだファイルを確認
print('data frames read:{}'.format(list(dfs.keys())))
# -> data frames read:['air_store_info', 'date_info', 'store_id_relation', 'hpg_reserve', 'air_reserve', 'air_visit_data', 'sample_submission', 'hpg_store_info']
これで各CSVファイルのファイル名=データフレーム名として、読み込みが完了しました。
重み付き平均は「曜日」と「祝日フラグ」の項目別にまとめて出します。
祝日ですが、リクルートから提供されているdata_info.csvを少し前処理する必要がありそうです。
まずはdate_infoを確認してみます。
# data_infoの祝日フラグが1(オン)のデータを確認
date_info[date_info['holiday_flg'] == 1].head(10)
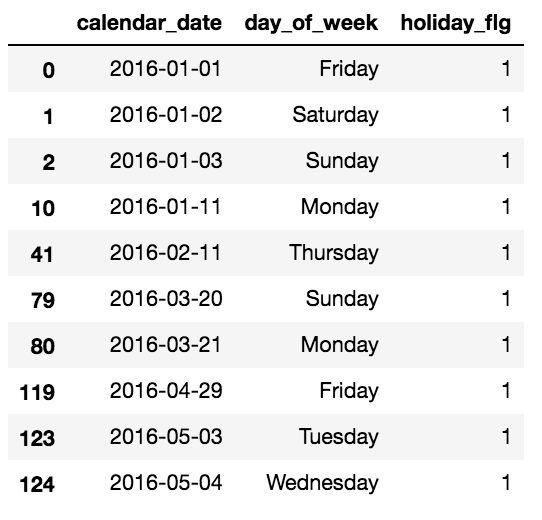
土曜日も日曜日も祝日フラグがONになってしまっているので、土日は祝日フラグをOFFにします。(これで祝日=土日ではない平日のお休みというデータとなります)
# date_infoから土日で祝日フラグが「1」のレコードを探してweekend_hdaysに格納
weekend_hdays = date_info.apply((lambda x:(x.day_of_week=='Sunday' or x.day_of_week=='Saturday') and x.holiday_flg==1), axis=1)
# date_infoの該当の箇所のフラグを1から0へ更新をする
date_info.loc[weekend_hdays, 'holiday_flg'] = 0
補足
DataFrame.apply:は DataFrame の各列もしくは各行に対して関数を適用する関数です。行/列の指定はaxisキーワードで行います。(axis=0:行、axis=1:列)
次のステップとしては、日付を基に「重み」を作成します。
日付が古いものには少ない重みを(あまり重要でない印)、予測する日付に近い(新しい日付)には多い重みを(直近日付のデータは重要な印)与えましょう。
# 該当の日付+1 ÷ 全部の日付の個数で重みを計算
# date_info.indexの値が小さい=より昔のデータ
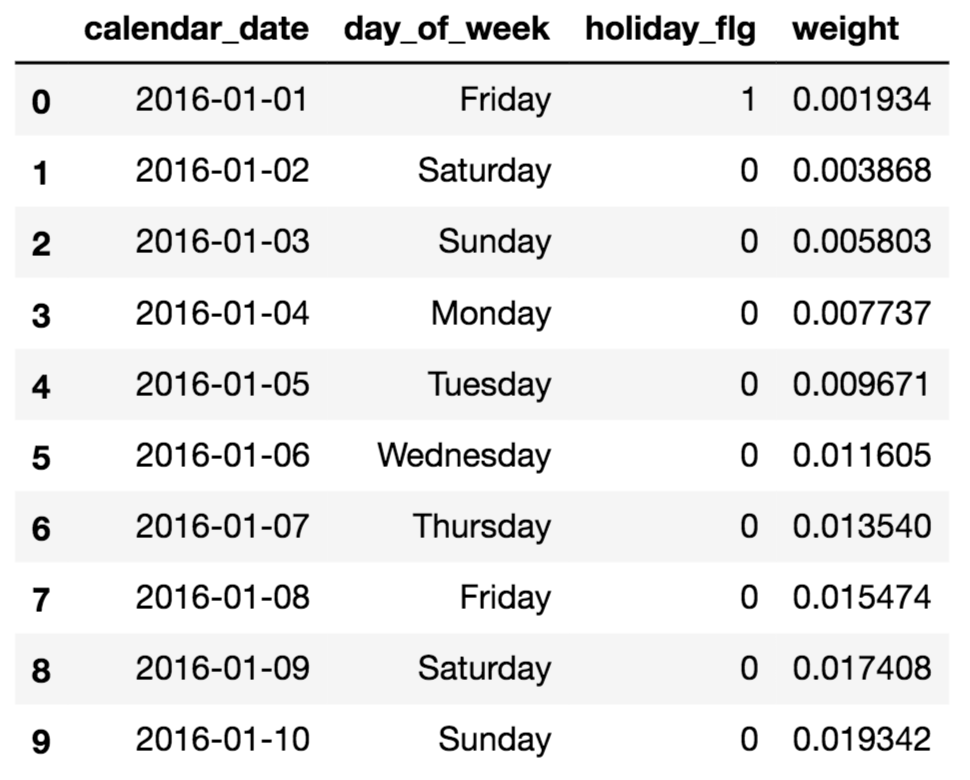
date_info['weight'] = (date_info.index + 1) / len(date_info)
# ヘッダーとテイルの情報を出して確認
date_info.head(10)
date_info.tail(10)
-
head
-
tail
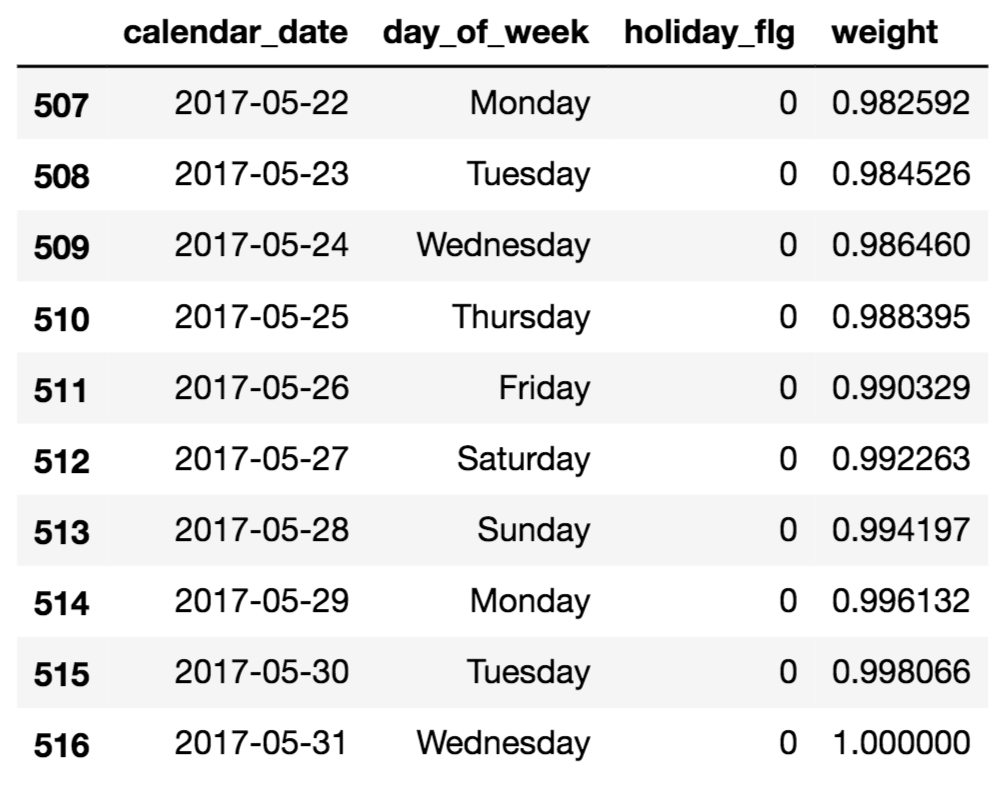
直近データの方が、weightが高くなっていることが分かります。
重みの処理もできましたので、次は実際に重み付き平均を算出します。
やり方としては、air_visit_data(Airレジの各レストランの実客数データ)に上記で算出したWeight(重み)を加えて、visitors(実客数)をnp.log1pを使って対数にして、「air_store_id」「day_of_week」「holiday_flg」(各レストランID、曜日、祝日フラグ)でグルーピングをして 重み付き平均を算出します。
まずはデータの再確認から。
air_visit_data.head()
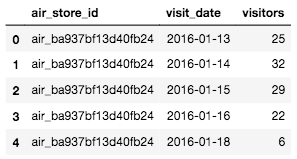
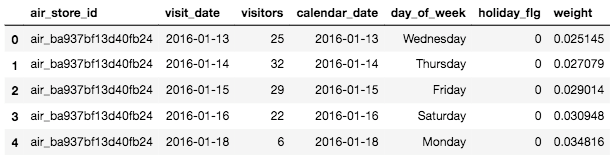
# air_visit_dataと重みを追加したdate_infoをマージさせてvisit_dataを作成
visit_data = air_visit_data.merge(date_info, left_on='visit_date', right_on='calendar_date', how='left')
visit_data.head()
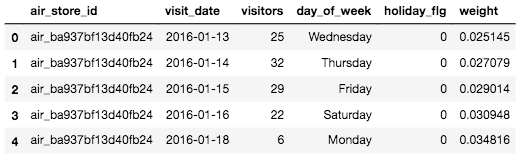
# visit_dataから不必要なcalendar_dateを落とす
visit_data.drop('calendar_date', axis=1, inplace=True)
visit_data.head()
# visit_dataの実客数にnp.log1pの対数関数を使って処理
visit_data['visitors'] = visit_data.visitors.map(pd.np.log1p)
# visit_dataの確認
visit_data.head(10)
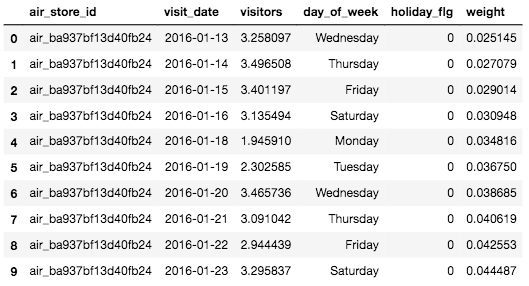
上記の通り、事前に算出した「重み(weight)」、さらに実客数をnp.log1pで処理した数値が「visitors」へ処理が加わっているのが確認できます。
これで、やっと「レスストランID」「曜日」「祝日」に応じた重み付き平均の算出が可能になりました!
では、早速計算していきましょう!
# wmean(重み付き平均)の式を格納
wmean = lambda x:( (x.weight * x.visitors).sum() / x.weight.sum() )
# グルーピングして重み付き平均を算出
visitors = visit_data.groupby(['air_store_id', 'day_of_week', 'holiday_flg']).apply(wmean).reset_index()
visitors.rename(columns={0:'visitors'}, inplace=True)
# データを確認
visitors.head(10)
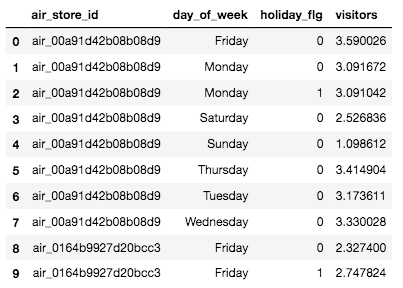
これで、レストランID、曜日、祝日フラグごとの客数の「重み平均」が算出されました。上のヘッダー情報をみてもわかりますが、index1とindex2は同じレストランID「air_00a91d42b08b08d9」で曜日も「Monday(月曜日)」と一緒ですが、祝日フラグが異なりますので、各レコードに重み平均が算出されています。
さて、次の処理として、この重み付き平均で算出した予測客数を、sample_submissionのデータのレストランIDや日付を基に客数を埋めていきましょう。(冒頭で確認したsample_submission.csvに予測しなくてはいけない日付やレストランIDが入っていたと思います。冒頭では、test_dfという名前で読み込んでいましたが、全てのCSVを一気に読み込んだところで、csvファイル名と同じデータフレーム名として読み込まれています)
では、データの再確認からいきましょう!
# データの確認
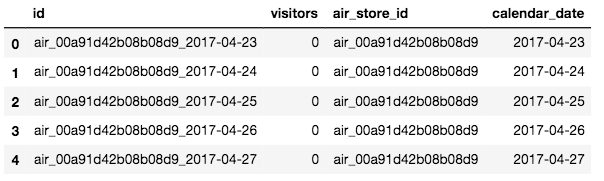
sample_submission.head()
# sample_submissionのIDをレストランIDに分ける
sample_submission['air_store_id'] = sample_submission.id.map(lambda x: '_'.join(x.split('_')[:-1]))
sample_submission.head()
# sample_submissionのIDを日付に分ける
sample_submission['calendar_date'] = sample_submission.id.map(lambda x: x.split('_')[2])
sample_submission.head()
# 重み付き平均で予測したvisitorsとsample_submissionをマージする
sample_submission.drop('visitors', axis=1, inplace=True)
sample_submission = sample_submission.merge(date_info, on='calendar_date', how='left')
sample_submission = sample_submission.merge(
visitors, on=['air_store_id', 'day_of_week', 'holiday_flg'], how='left')
# データセットを確認
sample_submission.head(10)
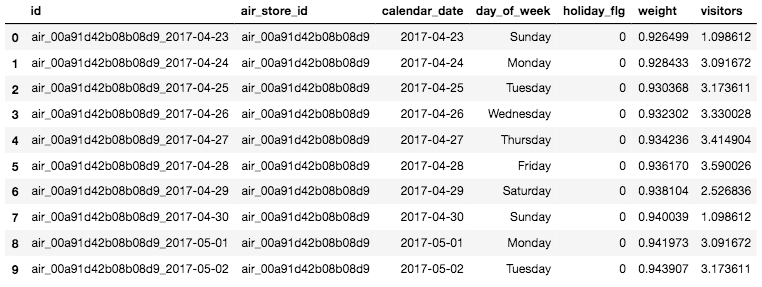
これで、事前に処理をした「重み付き平均」の客数が各レストラン毎に入りました。次に欠損データの確認と処理を行いましょう。まずは、欠損データをnull_searchで確認してみましょう。
# sampe_submissionの欠損データを確認
ull_search(sample_submission)
# -> ■■■ id
# -> NULL数:0 NULL率:0.0 データの種類数:32019
# -> ■■■ air_store_id
# -> NULL数:0 NULL率:0.0 データの種類数:821
# -> ■■■ calendar_date
# -> NULL数:0 NULL率:0.0 データの種類数:39
# -> ■■■ day_of_week
# -> NULL数:0 NULL率:0.0 データの種類数:7
# -> ■■■ holiday_flg
# -> NULL数:0 NULL率:0.0 データの種類数:2
# -> ■■■ weight
# -> NULL数:0 NULL率:0.0 データの種類数:39
# -> ■■■ visitors
# -> NULL数:668 NULL率:0.021 データの種類数:7228
visitorsで重み付き平均が入っていないレコードが668個もありますね。一番最初に重み付き平均を入れた時は過去データの「レストランID」「曜日」「祝日フラグ」に基づいて入れましたが、それに該当していないレコードが欠損していますので、今度は「祝日フラグ」の条件を除いて、「レストランID」「曜日」に基づいて重み付き平均を入れていきましょう。
# 「air_store_id」と「 day_of_week」のみで欠損データに重み平均を入れる
missings = sample_submission.visitors.isnull()
sample_submission.loc[missings, 'visitors'] = sample_submission[missings].merge(
visitors[visitors.holiday_flg==0], on=(
'air_store_id', 'day_of_week'), how='left')['visitors_y'].values
# 改めて欠損データの確認
null_search(sample_submission)
# -> ■■■ id
# -> NULL数:0 NULL率:0.0 データの種類数:32019
# -> ■■■ air_store_id
# -> NULL数:0 NULL率:0.0 データの種類数:821
# -> ■■■ calendar_date
# -> NULL数:0 NULL率:0.0 データの種類数:39
# -> ■■■ day_of_week
# -> NULL数:0 NULL率:0.0 データの種類数:7
# -> ■■■ holiday_flg
# -> NULL数:0 NULL率:0.0 データの種類数:2
# -> ■■■ weight
# -> NULL数:0 NULL率:0.0 データの種類数:39
# -> ■■■ visitors
# -> NULL数:448 NULL率:0.014 データの種類数:7228
上の条件で約200の欠損データが埋まりましたが、まだ448個あります。最後は「曜日」の条件も省いて、単純に「レストランID」にのみの重み付き平均を欠損データへ埋めておきましょう。
# 「air_store_id」のみの重み付き平均を計算して欠損データへ入れる
missings = sample_submission.visitors.isnull()
sample_submission.loc[missings, 'visitors'] = sample_submission[missings].merge(
visitors[['air_store_id', 'visitors']].groupby('air_store_id').mean().reset_index(),
on='air_store_id', how='left')['visitors_y'].values
# 改めて欠損データの確認
null_search(sample_submission)
# -> ■■■ id
# -> NULL数:0 NULL率:0.0 データの種類数:32019
# -> ■■■ air_store_id
# -> NULL数:0 NULL率:0.0 データの種類数:821
# -> ■■■ calendar_date
# -> NULL数:0 NULL率:0.0 データの種類数:39
# -> ■■■ day_of_week
# -> NULL数:0 NULL率:0.0 データの種類数:7
# -> ■■■ holiday_flg
# -> NULL数:0 NULL率:0.0 データの種類数:2
# -> ■■■ weight
# -> NULL数:0 NULL率:0.0 データの種類数:39
# -> ■■■ visitors
# -> NULL数:0 NULL率:0.0 データの種類数:7300
最後にこのsample_submissionをKaggleリクルートレストランチャレンジの提出規定の形に整えましょう。visitorsですが、現段階ではnp.log1pで対数となっていますので、np.expm1で実際の予測した客数に戻してから、カラムを規定のフォーマットに戻します。
# visitorsをnp.expm1で処理して実客数へ戻す
sample_submission['visitors'] = sample_submission.visitors.map(pd.np.expm1)
# 提出フォーマットの規定に合うように処理してsub_fileへ格納
sample_submission = sample_submission[['id', 'visitors']]
final['visitors'][final['visitors'] ==0] = sample_submission['visitors'][final['visitors'] ==0]
sub_file = final.copy()
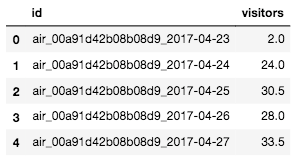
# データの確認
sub_file.head()
ステップ③ 中央値と加重平均のさらに平均を算出
現段階でfinaleのvisitorsへは、ステップ1で算出した「曜日の中央値 」が客数予測値として入っています。またsample_submissionのvisitorsへは、ステップ2で算出をした「重み付き平均」の客数予測値が入っています。
最後に、このふた通りの客数予測をさらに3つの手法で平均を算出してKaggleへデータを提出してみましょう。Aがfinal[‘visitors’]でBがsample_submission[‘visitors’]として、簡単に求めることが可能です。
各平均を求めて、それぞれ別名でcsvファイルに書き出しましょう。
| 求め方 | |
|---|---|
| 算術平均 | (A+B)/2 |
| 相乗平均 | (A×B)**(1/2) |
| 調和平均 | 2/(1/A+1/B) |
# 算術平均をnp.meanで算出
sub_file['visitors'] = np.mean([final['visitors'], sample_submission['visitors']], axis = 0)
sub_file.to_csv('sub_math_mean_1.csv', index=False)
# 相乗平均を算出
sub_file['visitors'] = (final['visitors'] * sample_submission['visitors']) ** (1/2)
sub_file.to_csv('sub_geo_mean_1.csv', index=False)
# 調和平均を算出
sub_file['visitors'] = 2/(1/final['visitors'] + 1/sample_submission['visitors'])
sub_file.to_csv('sub_hrm_mean_1.csv', index=False)
ローカルに「sub_math_mean_1.csv」「sub_geo_mean_1.csv」「sub_hrm_mean_1.csv」の三つのファイルが出力されて入れば成功です。それでは、気になる予測の結果をKaggleへ投稿して確認してみましょう!
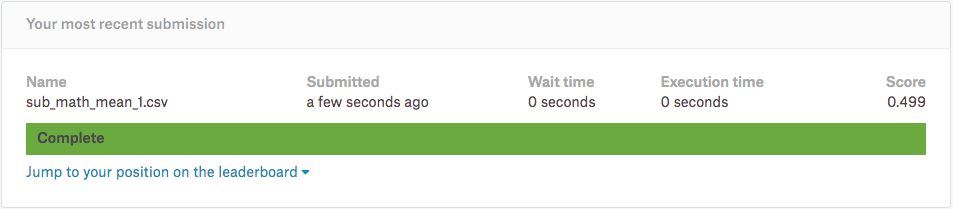
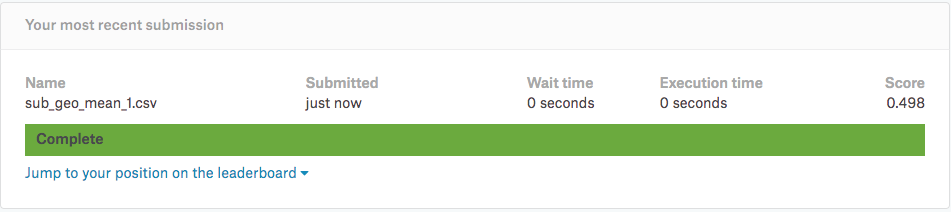
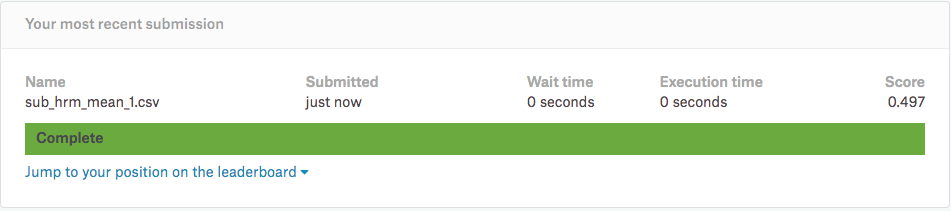
最後の処理で「調和平均」で処理をした結果が一番良いスコアがでていることが分かります。