はじめに
Mercari Price Suggestion Challenge(メルカリコンペ)に参加していて、最終順位は17位でした。この記事はメルカリコンペの復習記事で自分の解法について触れません。1位のチームがぶっちぎりで優勝を決めていたのですが、本質的な部分がかなりシンプルで驚きました(SparseなデータをMLPに入力)。Sparseなデータを扱う時に、線形回帰やFactorization Machinesを使うことはKaggleでは一般的ですが、MLPを使うアイデアは初めて聞きました。ここの復習では1位の解法にあったMLPといくつか気になった点を実験しました。
この実験はモデルの違いによる性能の違いを検証するのが目的で、限界までスコアを上げるような調整はしていない。そのため、特徴量設計、ハイパーパラメータ選択やニューラルネット設計には向上の余地があると思われる。
個人的に気になったのはニューラルネット系モデルだが比較のためその他のモデルもいくつか試してみた。実験を行ったのは次の5つのモデル、MLP, CNN, RNN, 線形回帰, Factorization Machines。また、それらのモデルのアンサンブルの実験も行った。
コンペ本番では、計算リソース(GPU使用不可、CPUのみなど)と実行時間に制限があり、MLPが非常に有効だった理由の1つにコンペ環境では学習速度が速いという点だ。CNNやRNNだと、複数モデルを学習してアンサンブルすることが難しかった。自分が今回気になった点は、学習時間などをあまり気にしない場合のCNNやRNNとそれらのアンサンブルの効果である。
問題
メルカリ上でユーザーが商品を出品する時に適切な出品価格を提示するモデルを作る。
コンペ本番の制約
この記事では特にここでの制約を気にしないがコンペ本番での制約を紹介しておく。
このコンペはカーネルコンペと呼ばれるもので、ソースコード全体をKaggleに提出する形式だ。ソースコードを提出するとKaggle上で実行されてスコアが算出される。そのソースコードでは前処理、学習から予測まで全てを実行する必要がある。
Kaggle上の計算リソースの制約
- CPU: 4 cores
- Memory: 16GB
- Disk: 1GB
- 制限時間: 1時間
- GPU: なし
単に複雑なモデル(Deep Learningなど)を使うと制限時間内に実行が終わらない。そのため、コンペ本番では実行速度と予測精度のバランスを取った解法を選択する必要があった。
評価方法
Root Mean Squared Logarithmic Error
$ loss = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (\log(predict + 1) - \log(price + 1))^2 } $
このloss(スコア)を最小化することが目的。
データ
(おそらく)実際のアメリカのメルカリのデータを使用している。テキストデータは基本的に英語。
- category_name: 3段階のカテゴリ
- 大まかなカテゴリ
- 詳細なカテゴリ
- より詳細なカテゴリ
- brand_name: ブランド名。例: Sony, Apple。おそらく選択式?Sonyだと、Sony、SONY、sonyなどの複数パターンがなく正規化されていた。
- name: 商品名。出品者が自由に記述できる。
- item_description: 商品の詳細。出品者が自由に記述できる。
- item_condition_id: 中古、新品など、商品の状態。(1~5)、大きい方が状態が良い。
- shipping: 送料を出品者か購入者のどちらが支払うか。1 -> 出品者が払う, 0 -> 購入者が払う。
- price: 過去の販売価格(USD)。この価格を予測するのが問題。
1つデータのサンプルを取るとこんな感じ。
- category_name: Electronics/Cell Phones & Accessories/Cell Phones & Smartphones
- brand_name: Apple
- name: iPhone 6 Plus 64GB (Space Gray)
- item_description:
iPhone is practically brand new, no scratches, dents, or cracks. The only issue is that the phone is Activation Locked, however, the phone is not listed as stolen. Other than that, the phone is fully functional and looks brand new. It comes with the brand new case in the picture ([rm] value). The IMEI of the phone is 354435060640513. I DO NOT NEED THE PHONE AND WANT TO SELL AS SOON AS POSSIBLE.***ALSO OPEN TO OFFERS AND I WILL TRY TO ANSWER ANY QUESTIONS YOU HAVE! - item_condition_id: 2
- price: 116.0
- shipping: 1
特徴量
カテゴリカルデータ
カテゴリカルデータ(category_name, brand_name, item_condition_id, shipping)は、One-hotエンコーディングしてモデルに入力する。5000~6000次元のスパースな入力になる。
テキストデータ
name, item_descriptionはユーザーが入力できるテキストデータで、モデルによって入力の仕方が異なる。入力の仕方に関わらず、name, item_descriptionはそれぞれ独立に処理して入力している。
- MLP, FM, LRに対しては、2-gramのBag of Wordsを作って、高次元なスパースデータとして入力。
- この実験では、nameとitem_descriptionでそれぞれ出現頻度が高い100000のngramのみを使っている。そのため、nameとitem_descriptionを連結した入力は200000次元になる。
- 値はbinary(0 or 1)。ngramの出現頻度に関わらず、出現していれば1、していなければ0とした。
- CNN, RNNに対しては、1単語ごとに系列データとしてそのまま入力する。
モデル
MLP (Multilayer perceptron)
今回のコンペで1位のチームはMLPを使っていて、そのおかげで大差をつけて1位を取ったみたい。
畳込みや再帰などの構造を持っていない全結合層のみで構成されたニューラルネットをここではMLPと呼んでいる。入力は、Bag of WordsとOne-hot化したカテゴリカルな特徴を連結したもの。
def build_mlp_model(input_dim):
model_input = Input(shape=(input_dim,), sparse=True)
x = Dense(192, activation='relu')(model_input)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
output = Dense(1)(x)
model = keras.Model(model_input, output)
model.compile(
loss='mean_squared_error',
optimizer=keras.optimizers.Adam(lr=3e-3)
)
return model
畳み込みニューラルネットワーク (CNN)
nameとitem_descriptionをそれぞれ独立に畳込み層に入力して、MaxPoolingを取る。そのそれぞれの出力とOne-hot化したカテゴリカルデータな入力を連結して全結合層に入力している。 (としようとしたのだが、One-hot化したカテゴリカルデータな入力をInput(sparse=True)として持っているため、そのままではMaxPoolingの出力と連結できなかった。そのため、連結前にOne-hot化したカテゴリカルデータをを一度全結合層に入力してからその出力をMaxPoolingの出力と連結した。)
def build_cnn_model(basic_input_dim, vocabulary_size_name, vocabulary_size_desc):
num_filters = 512
kernel_size = 5
basic_input = Input(shape=(basic_input_dim,), sparse=True, name='basic')
input_name = Input(shape=(MAX_LEN_NAME,), name='name')
embedding_name = Embedding(input_dim=vocabulary_size_name, output_dim=EMBEDDING_SIZE)(input_name)
cnn_name = Conv1D(filters=num_filters, kernel_size=kernel_size, activation='relu')(embedding_name)
cnn_name = GlobalMaxPooling1D()(cnn_name)
input_desc = Input(shape=(MAX_LEN_DESC,), name='item_description')
embedding_desc = Embedding(input_dim=vocabulary_size_desc, output_dim=EMBEDDING_SIZE)(input_desc)
cnn_desc = Conv1D(filters=num_filters, kernel_size=kernel_size, activation='relu')(embedding_desc)
cnn_desc = GlobalMaxPooling1D()(cnn_desc)
x = Dense(32, activation='relu')(basic_input)
x = keras.layers.concatenate([
x,
cnn_name,
cnn_desc
])
x = Dense(192, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
output = Dense(1)(x)
model = keras.Model(
inputs=[
basic_input,
input_name,
input_desc
],
outputs=output
)
model.compile(
loss='mean_squared_error',
optimizer=keras.optimizers.Adam(lr=2e-3)
)
return model
リカレントニューラルネットワーク (RNN)
nameとitem_descriptionをそれぞれ独立に再帰層に入力。その出力をCNNの場合と同様に全結合層に入力。
モデルの予測性能面では特に違いは見られなかったが、実装ではGRUクラスではなくCuDNNGRUクラスを使っている。GPUで実行する場合はこちらのほうが速いらしい。適当な計測で4~5倍ほど速かった。
def build_rnn_model(basic_input_dim, vocabulary_size_name, vocabulary_size_desc):
basic_input = Input(shape=(basic_input_dim,), sparse=True, name='basic')
input_name = Input(shape=(MAX_LEN_NAME,), name='name')
embedding_name = Embedding(input_dim=vocabulary_size_name, output_dim=EMBEDDING_SIZE)(input_name)
rnn_name = CuDNNGRU(256)(embedding_name)
input_desc = Input(shape=(MAX_LEN_DESC,), name='item_description')
embedding_desc = Embedding(input_dim=vocabulary_size_desc, output_dim=EMBEDDING_SIZE)(input_desc)
rnn_desc = CuDNNGRU(512)(embedding_desc)
x = Dense(32, activation='relu')(basic_input)
x = keras.layers.concatenate([
x,
rnn_name,
rnn_desc
])
x = Dense(192, activation='relu')(x)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
output = Dense(1)(x)
model = keras.Model(
inputs=[
basic_input,
input_name,
input_desc
],
outputs=output
)
model.compile(
loss='mean_squared_error',
optimizer=keras.optimizers.Adam(lr=2e-3)
)
return model
線形回帰 (Linear Regression, LR)
線形回帰はスパースなデータを入力したい時によく使われるモデルという印象。実装にはsklearnのRidgeを使った。RidgeはL2正則化を加えた線形回帰のこと。
入力はMLPとFMと完全に同じで、Bag of WordsとOne-hot化したカテゴリカルな特徴を連結したもの。
Factorization Machines (FM)
スパースなデータを入力したい時にKaggleではおなじみのFactorization Machines。実装にはfastFMというライブラリを使った。
入力はMLPとLRのものと完全に同じで、Bag of WordsとOne-hot化したカテゴリカルな特徴を連結したもの。
実験結果
上で述べたMLP, CNN, RNN, LR, FMの5つのモデルに対して実験した。データをtrain 95%, test 5%に分けて、trainデータで学習し、testデータに対して予測、スコア計算をする。重みの初期値などを変えて各モデル8回スコアを計算する。また、いくつかのアンサンブル法を試した。
参考までにコンペでのPrivate Learderboardのスコアをいくつか載せておく。(本番では計算リソースの制限のため、ローカルで高スコアを出すだけでは不十分で、いかに制限時間内に収めるかも重要だった。)
https://www.kaggle.com/c/mercari-price-suggestion-challenge/leaderboard
1位: 0.37758
2位: 0.38875
12位: 0.40020
17位(自分): 0.40602
~70位: 0.415~0.417
~80位: 0.420
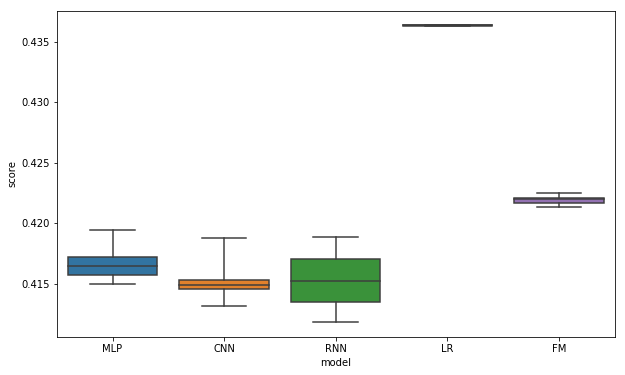
各モデルのスコア
各モデルごとに8つのスコアの平均、8つのスコアの分布の箱ひげ図を載せておく。ニューラルネットのモデルのスコアが良く、CNNとRNNがほぼ同精度で最も良い。ニューラルネットはスコアの分散が大きい、対してLR、FMはスコアの分散が小さい。
| モデル | スコアの平均 |
|---|---|
| CNN | 0.41513 |
| RNN | 0.41524 |
| MLP | 0.41663 |
| FM | 0.42192 |
| LR | 0.43637 |
アンサンブル
各モデルのaveraging
5つのモデルそれぞれで、8つの予測値の平均を取って(averaging)、そのスコアを計算した。
ニューラルネットのスコアが大きく向上している。特にMLPはこの中で最も良いスコアになっている。対して、LRのスコアは向上せず、FMのスコアの向上もニューラルネットに比べるとかなり小さい。
| モデル | averagingしたスコア | スコアの平均(前節と同じ) |
|---|---|---|
| MLP | 0.38990 | 0.41663 |
| CNN | 0.39384 | 0.41513 |
| RNN | 0.39909 | 0.41524 |
| FM | 0.42012 | 0.42192 |
| LR | 0.43637 | 0.43637 |
各モデルのaveragingをweighted averaging
各モデルのaveragingした予測値をweighted averagingしてスコアを計算した。weightは各モデルのaveraging予測値を入力として、線形回帰を使って求めた1。ここではいくつかのモデルの組み合わせた結果を載せておく。
この結果で注目したい点が2つある。1つ目は、MLPとCNNもしくはRNNをアンサンブルした場合に大きくスコアが向上している。2つ目は、"MLP, CNN"、"MLP, RNN"と比較して、"MLP, CNN, RNN"のスコアの向上が比較的小さいところである。これらを考察すると、CNNとRNNの間の多様性は小さく、MLPとCNN, RNNの間の多様性は大きいと言えそうだ。
| 組み合わせたモデル | weighted averagingしたスコア |
|---|---|
| MLP, CNN, RNN, LR, FM | 0.37773 |
| MLP, CNN, RNN, LR | 0.37829 |
| MLP, CNN, RNN, FM | 0.37887 |
| MLP, CNN, RNN | 0.37891 |
| MLP, CNN | 0.37983 |
| MLP, RNN | 0.38014 |
| CNN, RNN, LR, FM | 0.38593 |
| MLP, FM | 0.38852 |
| MLP, LR | 0.38956 |
| MLP | 0.38990 |
| CNN, RNN | 0.39099 |
| CNN | 0.39384 |
| RNN | 0.39909 |
| LR, FM | 0.41678 |
学習時間
自分のマシン上での学習時間を参考までに載せておく。公開している実装の各モデルの1モデルあたりの学習時間である。マシンスペックは、CPUがCore i9 7940X (1モデルあたりの学習には1スレッドしか使っていない)、GPUがGeForce GTX 1080 tiである。MLP, CNN, RNNはGPU、LRとFMはCPUを使った学習である。
FMの学習時間が極端に大きいが、rank=128を使ったためである。小さいrankを使うと予測性能はやや落ちるが学習時間はもっと小さくなる(ハイパーパラメータの選択が適当なだけなので、激遅モデルだと勘違いしないでほしい)。
| モデル | 学習時間 (分) |
|---|---|
| MLP | 1 |
| CNN | 6 |
| RNN | 12 |
| LR | 1.5 |
| FM | 90~100 |
その他tips
- 目的変数を標準化してから学習、予測をすると予測性能が上がる。この実装では標準化を利用している。
- ちなみに平均を0、分散調整なしでも同じ性能が出た。
- ここでの実装では、値がbinaryのBag of WordsをMLPへの入力として使用しているが、値がtf-idfのBag of Wordsを入力としたMLPも考えることができる。binary MLPとtf-idf MLPをアンサンブルすると更に予測性能を上げることができる。
参考
- この実験で使用したコード: https://github.com/takapt/kaggle-mercari-price-suggestion-challenge
- 1位を取ったチームによるMLP解法の参考コード: https://www.kaggle.com/lopuhin/mercari-golf-0-3875-cv-in-75-loc-1900-s/code
- 本番では別の実装を使ったらしい。
- この実験をやる時に参考にさせてもらった。sklearnのPipelineを使って、実装をシンプルにしている点もさすが。
-
weightは最大でも5個と比較的パラメータ数が少ないが、testデータを使ってweightを求めたので過学習している可能性がある。ちゃんとvalidationをやるならモデルとweightの学習で一切使われていないtestデータを作ったほうがいい。(また、weightに制約(sum(weight) = 1, weight >= 0)を設けていないので正確にはweighted averagingではないかも。) ↩