本文の内容は、2022年8月25日にJavier Martínezが投稿したブログ(https://sysdig.com/blog/debug-kubernetes-crashloopbackoff/)を元に日本語に翻訳・再構成した内容となっております。
CrashLoopBackOffは、Podで発生している再起動ループを表すKubernetesステートです。Pod内のコンテナが起動されますが、クラッシュして再起動されることを何度も繰り返します。
Kubernetesは、エラーを修正するチャンスを与えるために、再起動の間のバックオフ時間を長くして待機します。このように、CrashLoopBackOffはそれ自体がエラーではなく、Podが正しく起動できないようなエラーが起きていることを示しています。 KubernetesのCrashloopBackoff、図解で表すと。PodはRunning、Failed、Waitingの間でループしている。
KubernetesのCrashloopBackoff、図解で表すと。PodはRunning、Failed、Waitingの間でループしている。
なお、再起動するのは、 restartPolicy が Always(デフォルト)またはOnFailureに設定されているためです。そして、kubeletはこの設定を読み込んでPod内のコンテナを再起動し、ループを発生させています。この動作は本当に便利です。足りないリソースの読み込みが完了するまでの時間を確保し、問題を検出してデバッグすることができるからです - 詳しくは後述します。
CrashLoopの部分はこれで説明しましたが、BackOffの時間についてはどうでしょうか?基本的には、再起動の間に指数関数的に発生する遅延(10秒、20秒、40秒、...)で、上限は5分です。Podの状態がCrashLoopBackOffと表示されている場合、現在Podを再び再起動する前に表示された時間だけ待機していることを意味します。そして、それが修正されない限り、おそらく再び失敗します。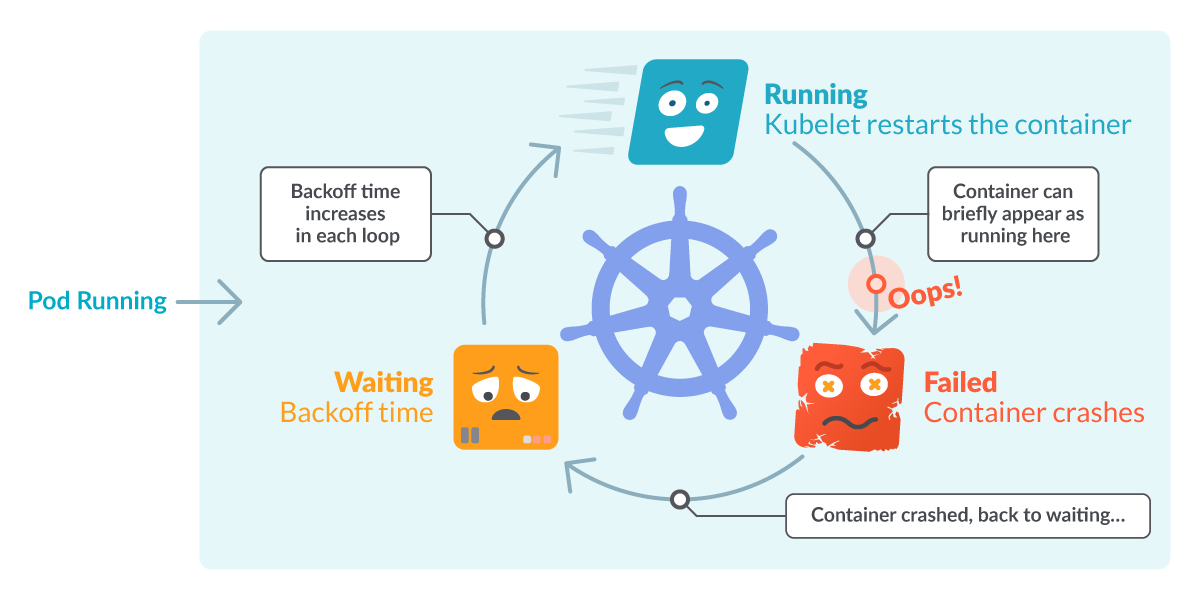 KubernetesのCrashloopbackoff、図解表現。あるPodがループしている。実行しようとするが、失敗するのでFailedの状態になる。デバッグのために少し待つと、また実行しようとする。問題が解決されないと、ループ状態になります。また失敗する。
KubernetesのCrashloopbackoff、図解表現。あるPodがループしている。実行しようとするが、失敗するのでFailedの状態になる。デバッグのために少し待つと、また実行しようとする。問題が解決されないと、ループ状態になります。また失敗する。
この記事で、把握できることは:
- CrashLoopBackOffとは何ですか?
- CrashLoopBackOffの問題を検出する方法
- CrashLoopBackOffが発生する一般的な原因
- CrashLoopBackOffをデバッグするためのKubernetesツール
- Prometheusを使ったCrashLoopBackOffの検出方法
クラスター内のCrashLoopBackOffを検出するには?
ほとんどの場合、kubectl get podsでPodをリストアップして、この状態のPodを1つ以上発見したはずです。$ kubectl get pods
NAME READY STATUS RESTARTS AGE
flask-7996469c47-d7zl2 1/1 Running 1 77d
flask-7996469c47-tdr2n 1/1 Running 0 77d
nginx-5796d5bc7c-2jdr5 0/1 CrashLoopBackOff 2 1m
nginx-5796d5bc7c-xsl6p 0/1 CrashLoopBackOff 2 1m出力から、最後の2つのPodを確認することができます。
-
READY状態ではありません (0/1) - それらのstatusは
CrashLoopBackOffを表示しています。 -
RESTARTS列には、1つ以上の再起動の表示があります。
CrashLoopBackOff として表される猶予期間があります。また、
Running や Failed の状態にある短い時間の中で、Podを見つけることができる「幸運」もあるかもしれません。 CrashloopBackoffのタイムライン。失敗するたびにBackoffTimeとRestart Countが増加する
CrashloopBackoffのタイムライン。失敗するたびにBackoffTimeとRestart Countが増加するCrashLoopBackOffが発生する一般的な理由
CrashLoopBackOffは、Podをクラッシュさせている実際のエラーではないことに注意することが重要です。STATUS カラムにループが発生していることを表示しているだけであることを思い出してください。コンテナに影響を与える根本的なエラーを見つける必要があります。実際のアプリケーションにリンクしているエラーには、次のようなものがあります:
- 設定ミス:設定ファイルのタイプミスのようなものです。
- リソースが利用できない:マウントされていないPersistedVolumeのようなもの。
- コマンドライン引数が間違っている:見つからないか、正しくないもの。
- バグと例外:これは、アプリケーションに特有のもので、何でもありです。
- 既存のポートをバインドしようとした。
- メモリ制限が低すぎるため、コンテナは Out Of Memory で強制終了した。
- liveness probesのエラーは、Podが準備完了であることをレポートしていない。
- 読み取り専用のファイルシステム、または一般的なパーミッションが不足している。
それでは、さらに深く掘り下げて、本当に原因を見つける方法を見ていきましょう。
CrashLoopBackOff状態のデバッグ、トラブルシュート、修復方法
前のセクションで、Pod が CrashLoopBackOff 状態になる理由がたくさんあることを理解しました。さて、どれが影響しているのかを知るにはどうしたらよいでしょうか?デバッグに使用できるいくつかのツールと、それをどの順番で使用するかを確認しましょう。これが最善の策になるかもしれません:
- Pod descriptionをチェックする。
- Podのログをチェックする。
- イベントをチェックする。
- デプロイメントをチェックする。
1. Pod descriptionを確認する - kubectl describe pod
kubectl describe pod コマンドは、特定のPodとそのコンテナの詳細情報を提供します。$ kubectl describe pod the-pod-name
Name: the-pod-name
Namespace: default
Priority: 0
…
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
…
Warning BackOff 1m (x5 over 1m) kubelet, ip-10-0-9-132.us-east-2.compute.internal Back-off restarting failed container
…describeの出力から、以下の情報を抽出することができます。
- 現在のPodの
StateはWaitingです。 - Waiting状態の理由は "CrashLoopBackOff "です。
- 最後の(または前の)状態は "Terminated "です。
- 最後の終了の理由は "Error"。
kubectl describe pod を使うことで、以下のような設定ミスがないか確認できます。- Podの定義
- コンテナ
- コンテナ用に引き出されたイメージ
- コンテナに割り当てられたリソース
- 引数の誤りや欠落
- ...
…
Warning BackOff 1m (x5 over 1m) kubelet, ip-10-0-9-132.us-east-2.compute.internal Back-off restarting failed container
…最後の行に、このPodに関連する直近のイベントのリストが表示されていますが、その中の1つに
Back-off restarting failed containerがあります。これは、再起動ループに関連するイベントです。複数の再起動が起こったとしても、1行だけであるべきです。2. ログを確認する - kubectl logs
特定のPodのログを確認することができます:kubectl logs mypodあるいは、そのPodに含まれるコンテナのログも見ることができます:
kubectl logs mypod -c mycontainer影響を受けるPodに間違った値がある場合、ログに有用な情報が表示されている可能性があります。
3. イベントを確認する - kubectl get events
リストで表示することができます:kubectl get eventsまた、1つのPodのイベントを全てリストアップすることも可能です:
kubectl get events --field-selector involvedObject.name=mypodこの情報は
describe pod の出力の下部にも表示されることに注意してください。4. デプロイメントを確認する - kubectl describe deployment
以下のコマンドで情報を取得することができます:kubectl describe deployment mydeploymentもし、望ましいPodの状態を定義しているでデプロイメントがあれば、その中にCrashLoopBackOffの原因となっている設定ミスが含まれている可能性があります。
すべてをまとめる
次の例では、コマンドの引数でエラーが見つかったログを掘り下げる方法を見ることができます。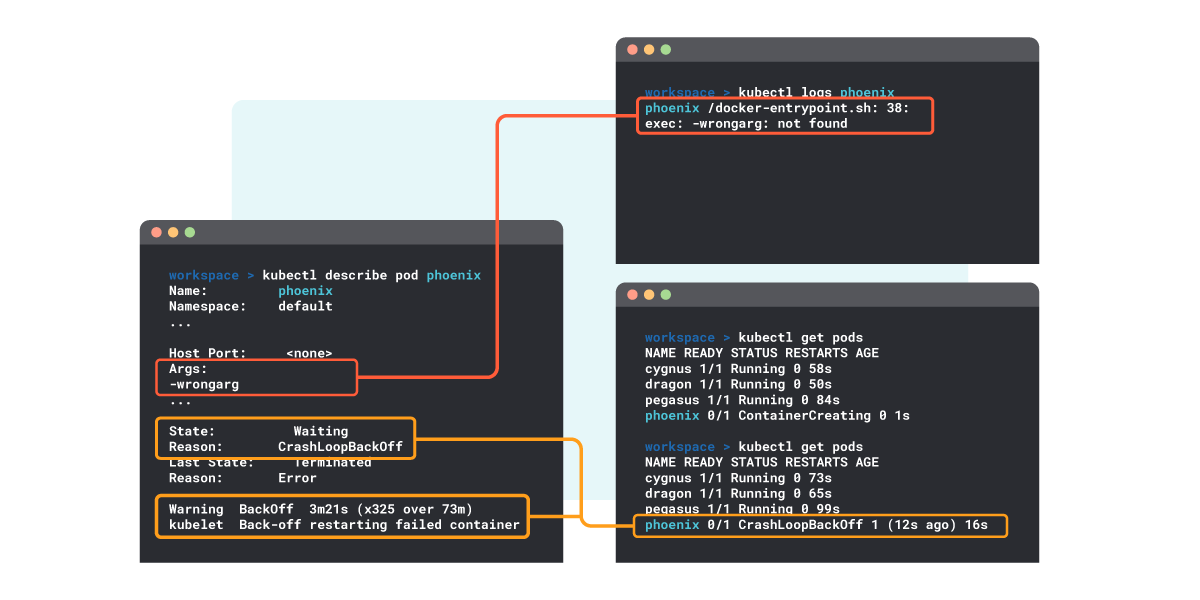 CrashloopBackoffのデバッグ。これは、いくつかのデバッグコマンドの関係で3つの端末を示しています。
CrashloopBackoffのデバッグ。これは、いくつかのデバッグコマンドの関係で3つの端末を示しています。PrometheusでCrashLoopBackOffを検出する方法
クラウド監視にPrometheusを使用している場合、CrashLoopBackOffが発生したときにアラートを出すのに役立つヒントを紹介します。以下の式を使用することで、CrashLoopBackOff
status にあるクラスター内のコンテナを迅速にスキャンできます(Kube State Metricsが必要です)。kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff"} == 1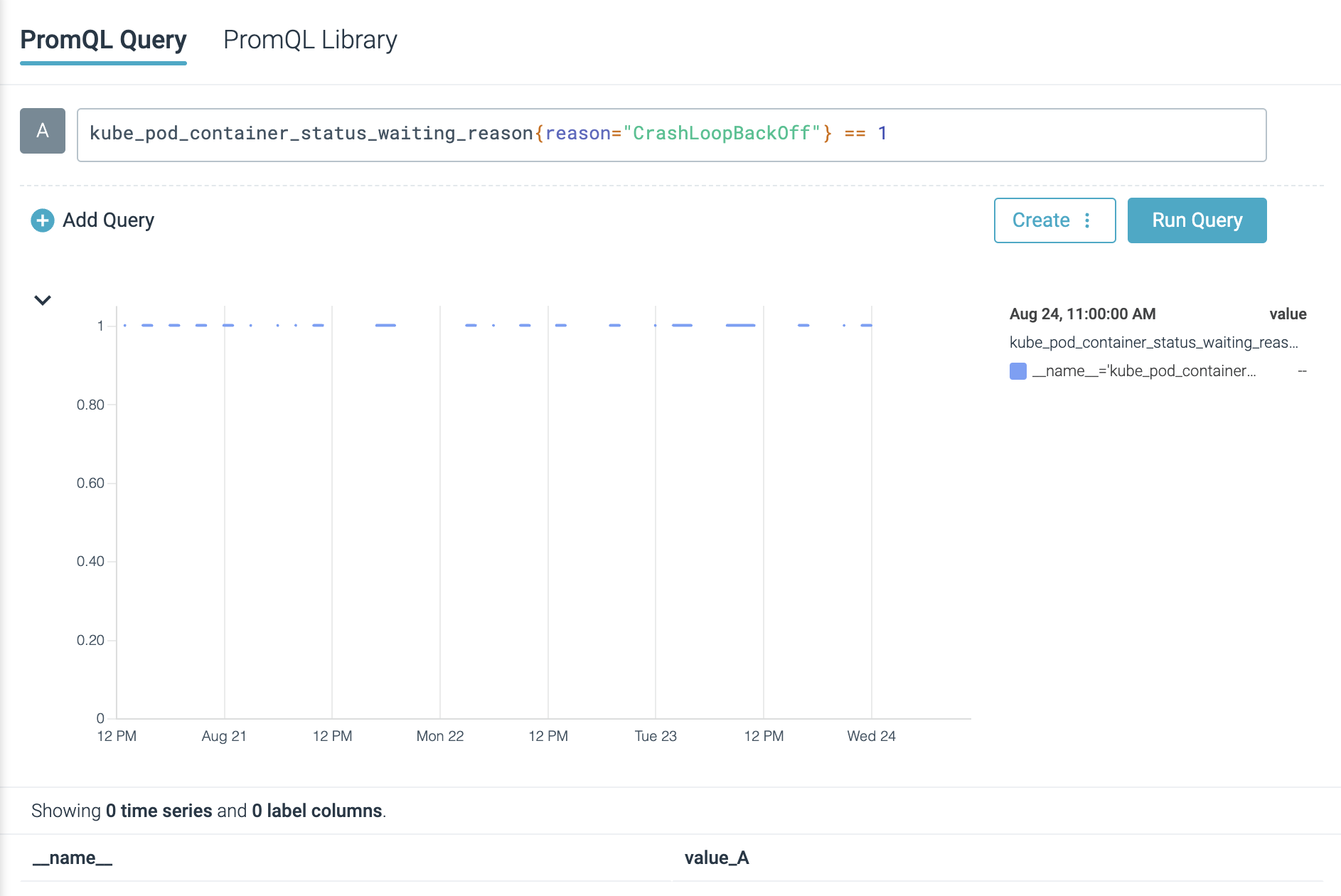
また、Podで起きている再起動の量をトレースすることも可能です:
rate(kube_pod_container_status_restarts_total[5m]) > 0
注意: クラスターで起きているすべてのリスタートがCrashLoopBackOffのステータスに関連しているわけではありません。
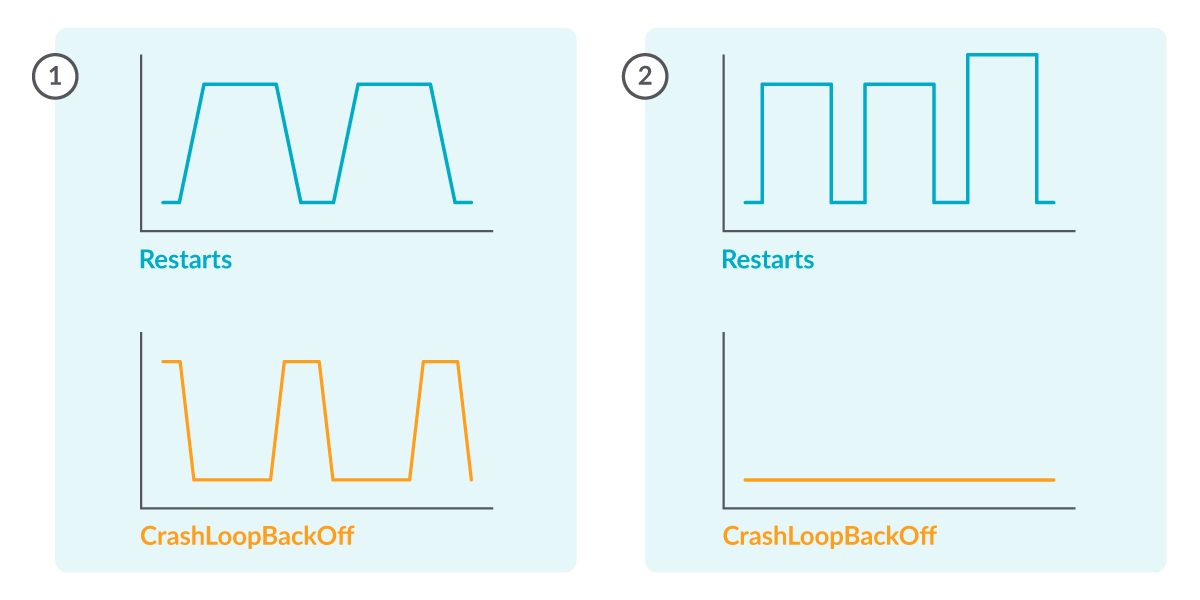
CrashLoopBackOffの期間ごとに再起動があるはずですが(1)、CrashLoopBackOffとは関係ない再起動がある可能性もあります(2)。
その後、以下のようなPrometheus Alerting Ruleを作成し、いずれかのPodがこの状態になった場合に通知を受けることができます。
- alert: CrashLoopBackOffAlert
expr: rate(kube_pod_container_status_restarts_total[5m]) > 0
for: 10m
labels:
severity: warning
annotations:
summary: Pod is in CrashLoopBackOff state
description: Pod {{ $labels.pod }} in {{ $labels.namespace }} has a container {{ $labels.container }} which is causing a CrashLoopBackOffまとめ
今回は、CrashLoopBackOffはそれ自体がエラーではなく、Podで発生している再試行ループを通知しているだけであることを確認しました。どのような状態を通過するのか、そしてそれを
kubectl コマンドで追跡する方法について見てきました。また、この状態を引き起こす可能性のある一般的な設定ミスや、デバッグに使用できるツールについても見てきました。
最後に、PodでCrashLoopBackOffイベントを追跡しアラートを出す際に、Prometheusがどのように役立つかを確認しました。
直感的なメッセージではありませんが、CrashLoopBackOffは意味のある便利な概念であり、何も恐れることはありません。
Sysdig MonitorでCrashLoopBackOffのデバッグを高速化する
Sysdig Monitorの新しいKubernetesトラブルシューティング製品であるAdvisorは、トラブルシューティングを最大10倍高速化します。Advisorは、問題の優先順位付けされたリストと関連するトラブルシューティングデータを表示し、最大の問題領域を浮上させ、解決までの時間を加速させることができます。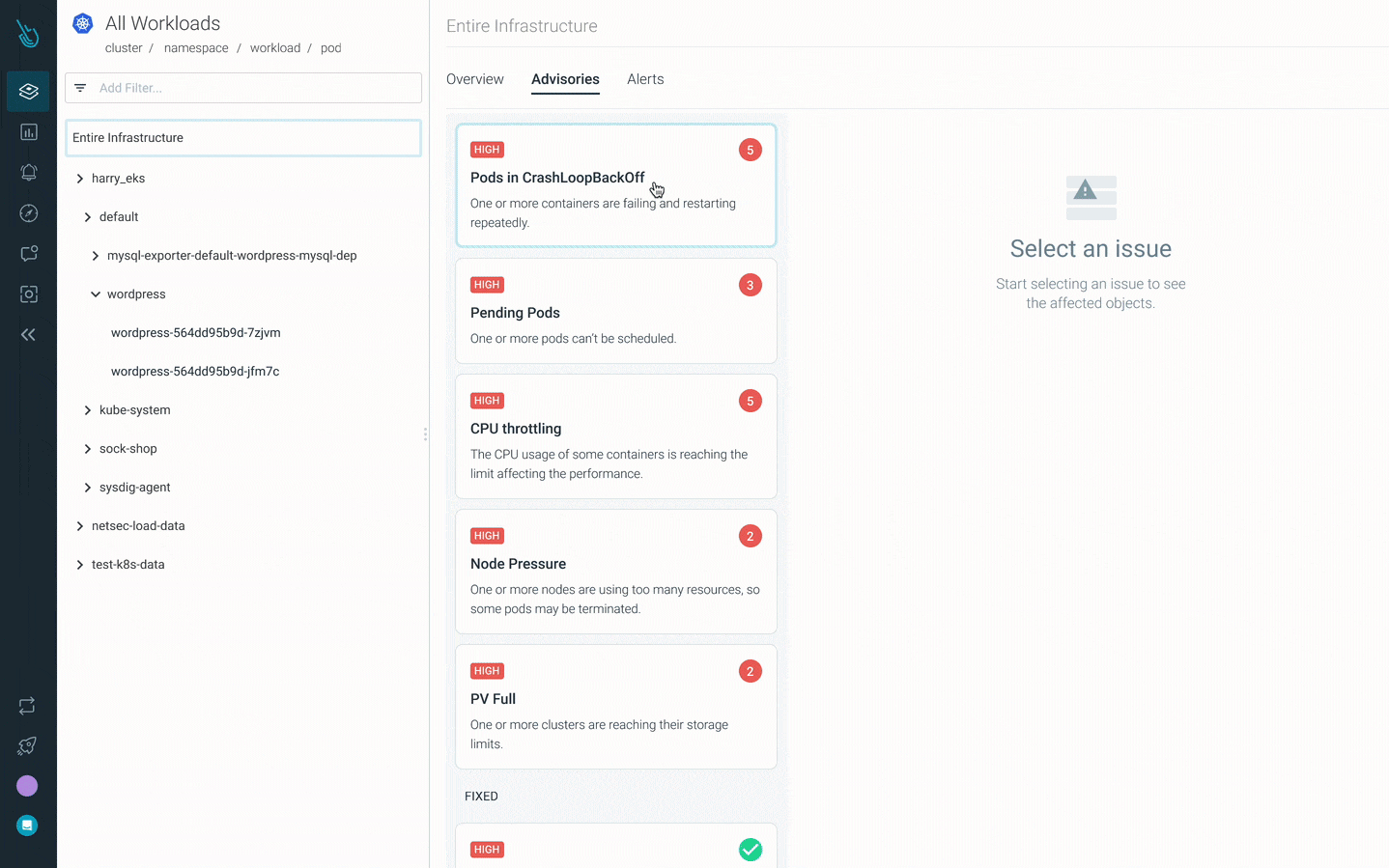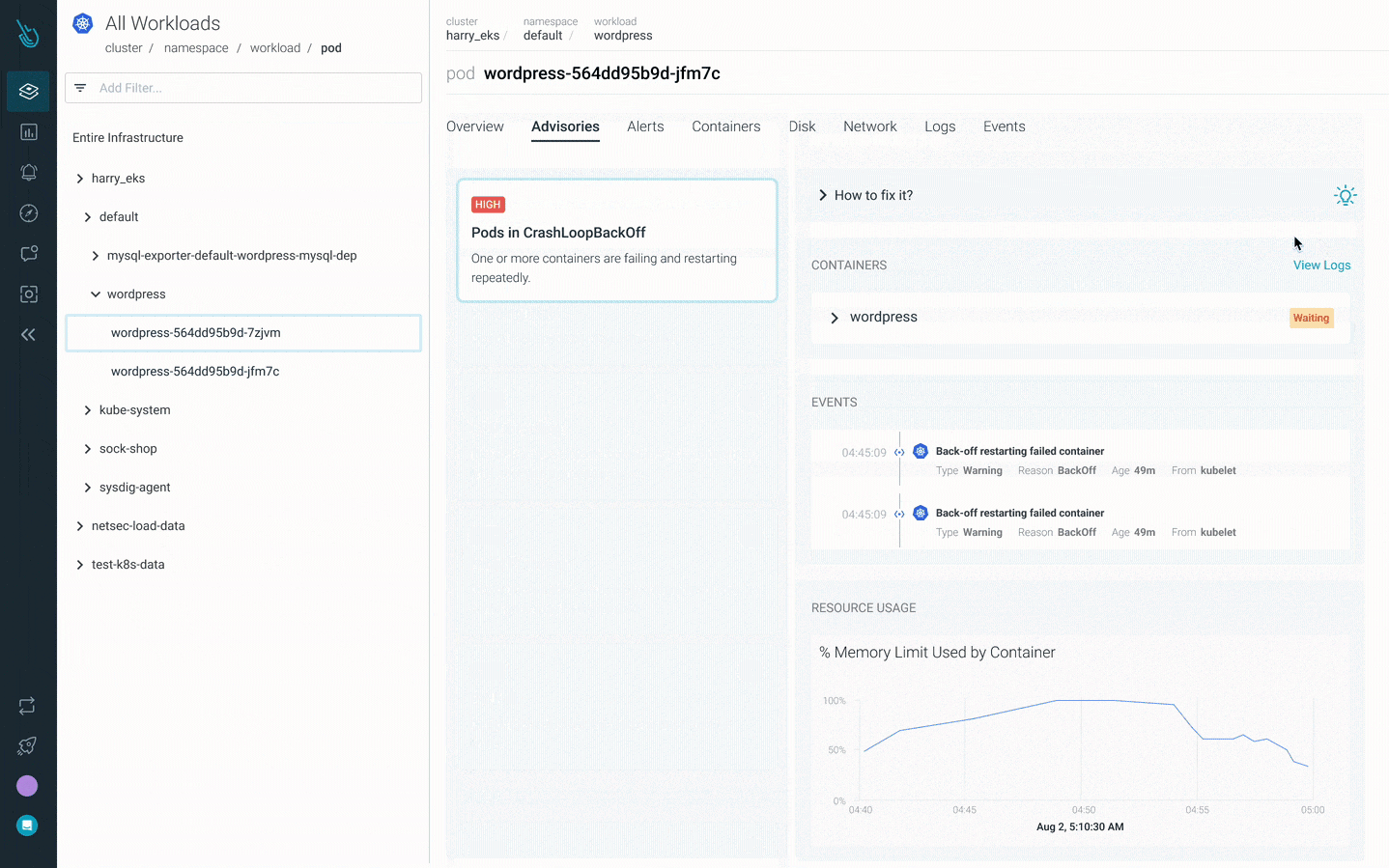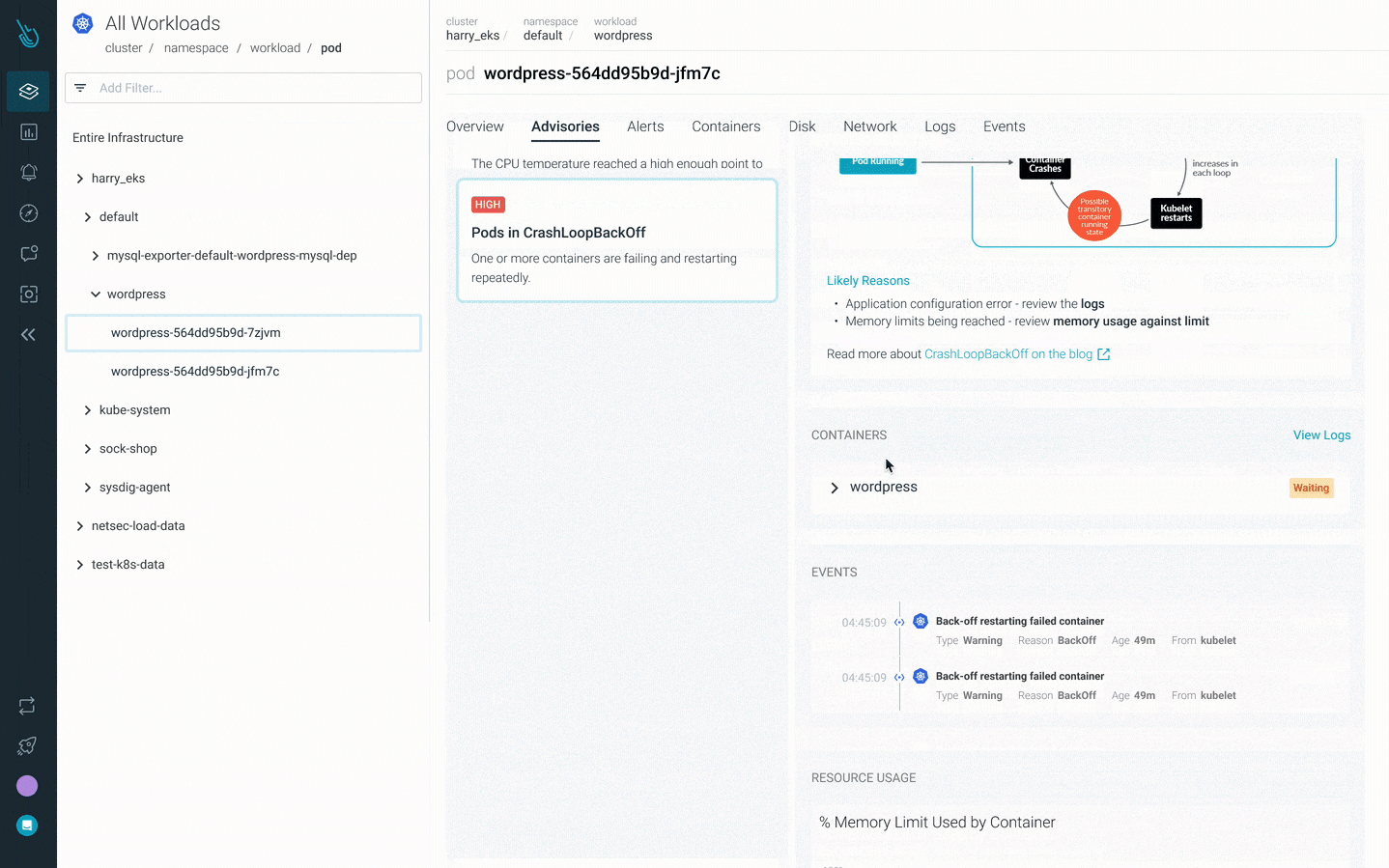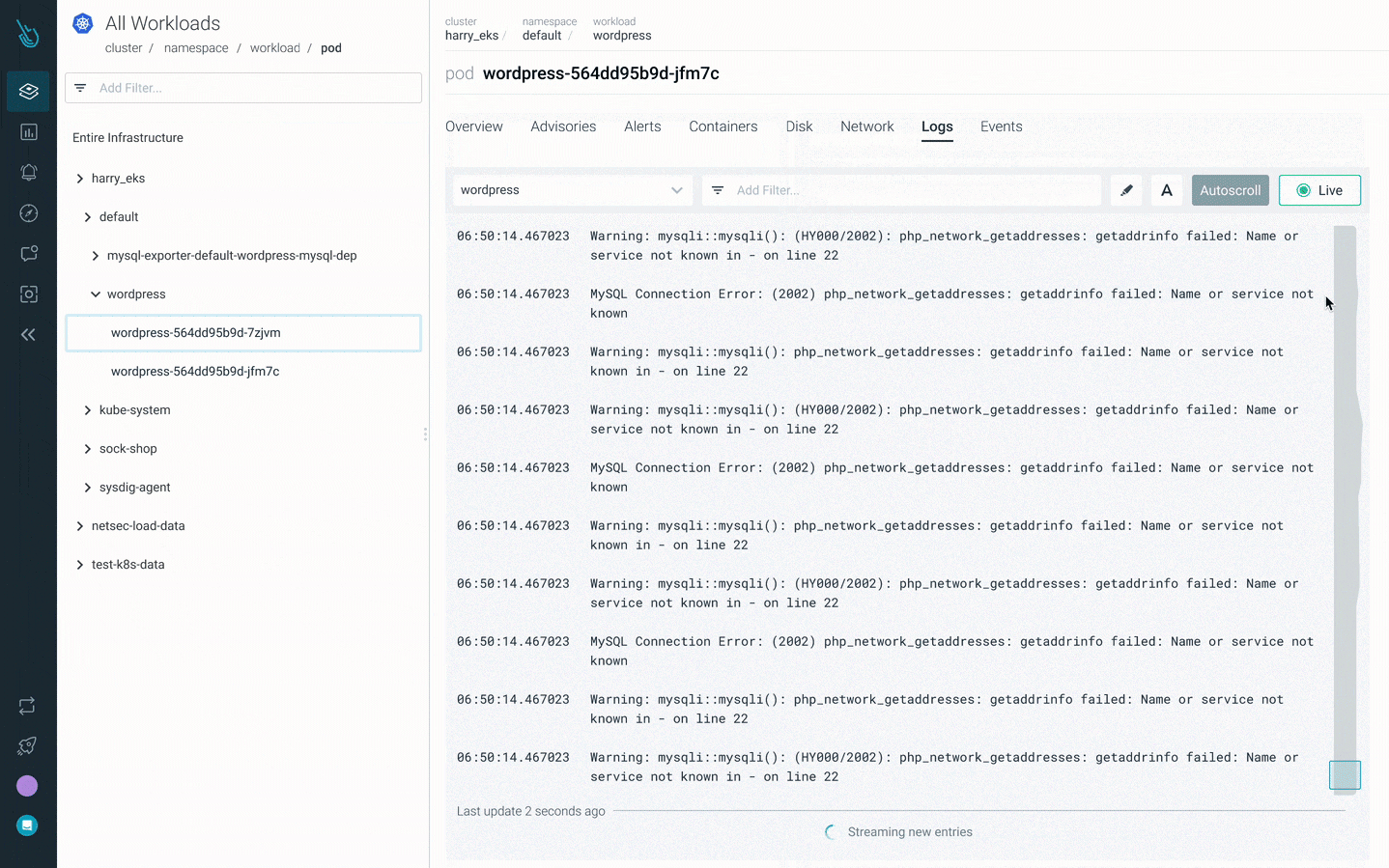 Sysdig Monitor Advisorを使用してクラッシュループバックオフをデバッグする方法
Sysdig Monitor Advisorを使用してクラッシュループバックオフをデバッグする方法