SB-AI Advent Calendar 2019 の5日目です。
よろしくお願いします。
概要
自分の顔のどのパーツがどの芸能人に似ているのかを、grad-camを使って調べます。
流れとしては、
- 数種類の芸能人を分類するモデルを作成する
- 自分の顔写真をモデルにかけて、誰に一番似ているのかを調べる
- grad-camで顔のどのパーツを根拠に分類しているのか調べる
という感じです。
分類する芸能人は、私が似ていると言われた事がある、
- NON STYLE 井上
- アンジャッシュ 渡部
- 星野 源
- 織田信成
にします。(ファンの人いたらごめんなさい)
(追記)
なお、全てのコードと詳細を(pytorch_face_gradcam)にまとめたので試してみたい方は見てみてください。
準備
顔認識の学習済みモデルを探しているときに、顔の自動切り抜きもサポートしている素敵なものを見つけたので、今回はこれを使っていきます。(facenet-pytorch)
分類モデル作成
データセット作成
まずは、分類する芸能人の画像データをChrome拡張ツールのImage Downloaderを使って収集します。今回は一人につき100枚弱集めました。
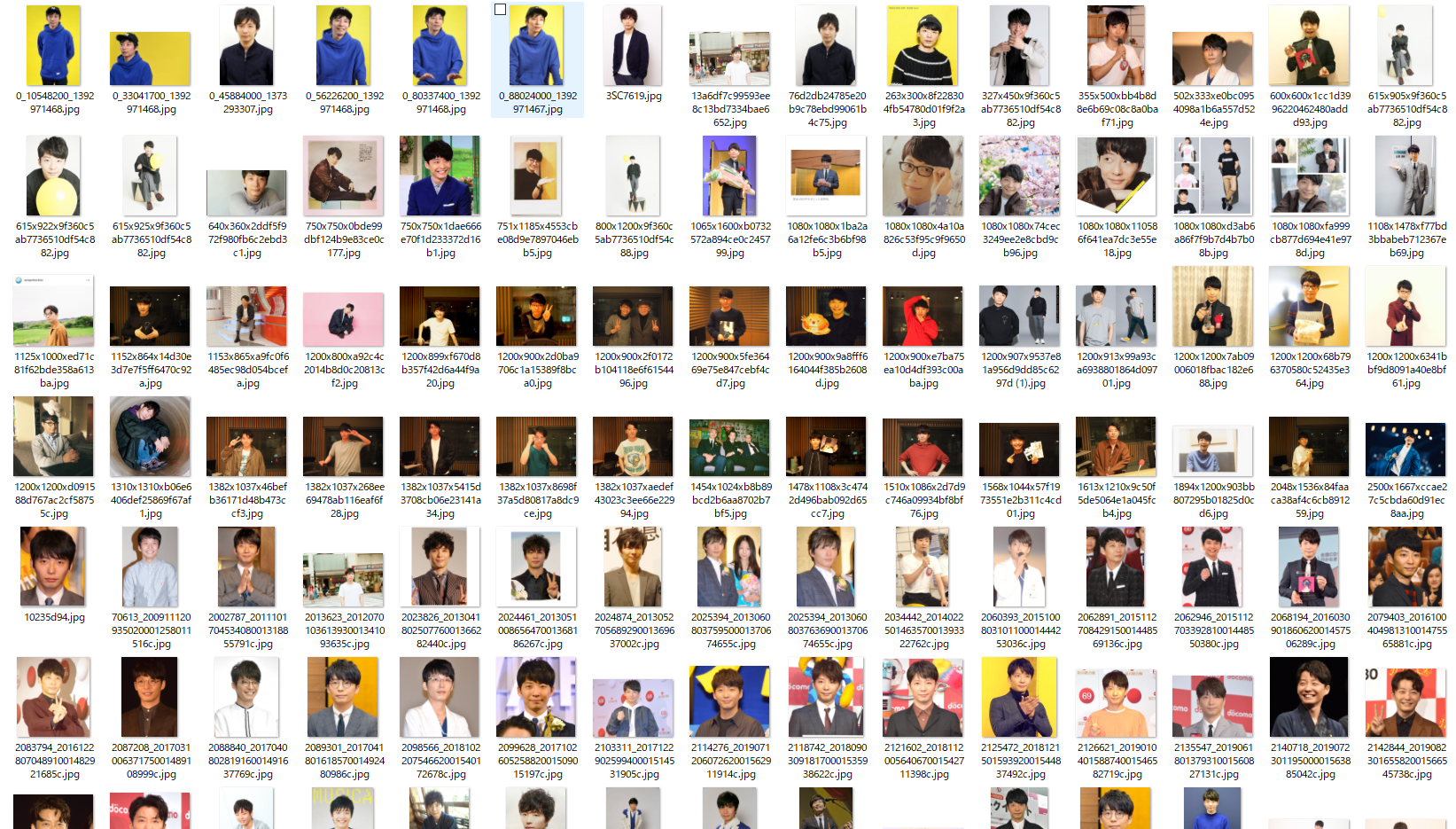
このままだと背景の影響を受けてしまうので、集めた画像から顔だけを切り出します。
顔の検出には、facenet-pytorchのMTCNNを使います。
MTCNNは入力画像と切り出した画像の保存先を渡すと、顔の検出⇒切り出し⇒保存まで自動でやってくれます。
import glob
from facenet_pytorch import MTCNN
import os
from PIL import Image
image_dir = "./images"
mtcnn = MTCNN()
for i, path in enumerate(glob.glob(os.path.join(image_dir,"*.jpg"))):
img = Image.open(path)
img_cropped = mtcnn(img, save_path="./face_cropped_images/{}.jpg".format(str(i))) # 画像と保存先を渡す

これでデータセットは完成です!
学習
今回は、VGGFace2というデータセットで学習された学習済みモデルを使います。
全結合層以外の層を凍結して、学習を進めます。
以下簡単に学習コードの説明をします。
まずは、ライブラリのインポート
一番下の行でfacenet-pytorchを読み込んでいます。
from argparse import ArgumentParser
import os
import torch
import torch.nn as nn
import numpy as np
from torch.optim import SGD, Adam
from torch.utils.data import DataLoader
import torchvision
from torchvision.transforms import *
from facenet_pytorch import MTCNN, InceptionResnetV1
ここではデータセットを読み込んでいます。
torchvisionのImageFolderにより、rootで指定したディレクトリ以下のフォルダをデータセットとして読み込みます。
また、4:1の割合でtrainデータとvalidationデータに分割しています。
def load_dataset():
transform = Compose([
transforms.Resize((160,160)),
np.float32,
transforms.ToTensor(),
prewhiten
])
data = torchvision.datasets.ImageFolder(root='./datasets', transform=transform)
train_size = int(len(data)* 0.8)
valid_size = len(data) - train_size
train_data, valid_data = torch.utils.data.random_split(data, [train_size, valid_size])
train_loader = DataLoader(train_data, batch_size=args.batch_size, shuffle=True, num_workers=4)
valid_loader = DataLoader(valid_data, batch_size=args.val_batch_size, shuffle=True, num_workers=4)
print("Load Data! train:{}, valid:{}".format(str(len(train_data)), str(len(valid_data))))
return train_loader, valid_loader
これはデータセットをtransformするときに使っているメソッドですが、データセット内の画像を正規化しています。
def prewhiten(x):
mean = x.mean()
std = x.std()
std_adj = std.clamp(min=1.0/(float(x.numel())**0.5))
y = (x - mean) / std_adj
return y
ここではモデルの読み込みや調整を行います。
まず、vggface2で学習済みのfacenet-pytorchのInceptionResnetV1モデルを読み込みます。
そして、一旦全ての層を凍結(勾配を計算させないように)します。
その後、全結合層を自分が分類したいクラス数で再定義します。
def setup_model(device):
model = InceptionResnetV1(classify=True,pretrained='vggface2')
for name, module in model._modules.items():
module.requires_grad = False # 全ての層を凍結
model.last_linear = nn.Linear(1792, 512, bias=False)
model.last_bn = nn.BatchNorm1d(512, eps=0.001, momentum=0.1, affine=True)
model.logits = nn.Linear(512, 4) # 今回は4クラスに分類
model.to(device)
return model
ここでは、引数で指定したエポック数だけ学習をまわしています。
流れとしては、trainデータで予測⇒勾配計算⇒パラメータ更新⇒validationデータで予測⇒モデル保存
となっています。
また、validationデータの予測の結果が良くなったときだけモデルを保存するようにしています。
def run(args):
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print("Use Device {}".format(device))
model = setup_model(device)
train_loader, valid_loader = load_dataset()
optimizer = Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
for epoch in range(args.epoch):
print('Starting epoch {}/{}.'.format(epoch + 1, args.epoch))
model.train()
train_loss = 0
for i_batch, data in enumerate(train_loader):
img, label = data
img = img.to(device).float()
label = label.to(device).long()
pred = model(img)
loss = criterion(pred, label)
train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss = train_loss / train_loader.__len__() * args.batch_size
print('Train Loss: {}'.format(train_loss))
model.eval()
valid_loss = 0
for i_batch, data in enumerate(valid_loader):
img ,label = data
img = img.to(device).float()
label = label.to(device).long()
pred = model(img)
loss = criterion(pred, label)
valid_loss += loss.item()
valid_loss = valid_loss / valid_loader.__len__() * args.val_batch_size
print('Validation Loss: {}'.format(valid_loss))
if args.save_better_only and epoch > 1 and prev_loss < valid_loss:
pass
else:
torch.save(model.state_dict(),
os.path.join(args.out_weight_path,'epoch{}_validloss{:.4f}_trainloss{:.4f}.pth'.format(epoch + 1, valid_loss, train_loss)))
prev_loss = valid_loss
ここでは、コマンドラインから引数を受け取り、先ほどのrunメソッドを実行しています。
--save_better_onlyをfalseで指定すると、全てのモデルを保存するようになります。
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument('--epoch', type=int, default=100,
help='number of epoch to train (default: 100)')
parser.add_argument('--batch_size', type=int, default=32,
help='input batch size for training (default: 32)')
parser.add_argument('--val_batch_size', type=int, default=8,
help='input batch size for validation (default: 8)')
parser.add_argument("--out_weight_path", type=str, default='./weights',
help="path to folder where checkpoint of trained weights will be saved")
parser.add_argument("--save_better_only", type=bool, default=True,
help="save only good weights")
args = parser.parse_args()
required_dir = [args.out_weight_path]
for path in required_dir:
if not os.path.isdir(path):
os.makedirs(path)
run(args)
予測
自分の顔写真で予測する前に、このモデルがちゃんと機能するかを確かめます。
あらかじめ、学習用データから外しておいた画像を正しく予測してくれるかを検証します。
結果を見やすくするために、jupyter notebookを使って実行しています。
予測用のコードはこんな感じです。
(追記) コード更新しました
import glob
import matplotlib.pyplot as plt
import numpy as np
import os
import torch
from PIL import Image
import torch.nn as nn
import torch.nn.functional as F
from torchvision.transforms import *
from facenet_pytorch import MTCNN, InceptionResnetV1
%matplotlib inline
def get_config():
config = {
'dataset':"./test_data",
'weight':"./weight.pth",
'classes':['星野 源','NONSTYLE 井上','織田 信成','アンジャッシュ渡部']
}
return config
def prewhiten(x):
mean = x.mean()
std = x.std()
std_adj = std.clamp(min=1.0/(float(x.numel())**0.5))
y = (x - mean) / std_adj
return y
def run(config):
device = 'cuda' if torch.cuda.is_available() else 'cpu'
resnet = InceptionResnetV1(classify=True,num_classes=4).to(device).eval()
resnet.load_state_dict(torch.load(config['weight'], map_location=torch.device(device)))
transform = transforms.Compose([
Resize(160,160),
np.float32,
ToTensor(),
prewhiten
])
print("start predict")
for path in glob.glob("{}/*".format(config['dataset'])):
img = Image.open(path)
tensor_img = transform(img).unsqueeze(0)
pred = resnet(tensor_img)
plt.imshow(img)
plt.show()
pred = F.softmax(pred[0], dim=0)
pred_label = config['classes'][torch.argmax(pred)]
for i, c in enumerate(config['classes']):
print("{} :{:.2f}%".format(c,pred[i]*100))
print("result:{}".format(pred_label))
config = get_config()
run(config)
get_configメソッドは、パスなどの設定を記述しています。
prewhitenメソッドは、学習の時と同じく画像データの正規化をするメソッドです。
runメソッドで予測を実行し、結果を表示しています。
結果はこんな感じでした。

完璧だ...!!
vggface2の学習済みモデルを使ってるため顔の特徴の取り方が上手なのだと思います。
自分の顔で予測
ここからが本題です。
自分の顔を予測します!!!!!
おおおお、面白いくらいの星野源!!
そういえば前に、「そっくりさん 有名人診断」というアプリで診断した時も星野源だったような...
grad-camでどこを重視しているのかを調べる
とりあえず、今回の4人の中では星野源に近い事が分かりました。
その上で、顔のどこらへんが似ているのかをgrad-camというものを使って調べていきます。
grad-camの詳細については触れませんが、簡単に説明すると画像のどこを重視して判断をしたかを示してくれるものです。
コードは、こちらの記事を参考にしました。(PyTorchでGrad-CAMによるCNNの可視化.)
これも実行する際にはjupyter notebookを使用してください。
(追記) コード更新しました
%matplotlib inline
import cv2
import glob
from facenet_pytorch import MTCNN, InceptionResnetV1
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import torch
import torch.nn.functional as F
from torch.autograd import Variable
from torchvision import models
from torchvision import transforms
from torchvision.transforms import *
class GradCam:
def __init__(self, model):
self.model = model
self.feature = None
self.gradient = None
def save_gradient(self, grad):
self.gradient = grad
def __call__(self, x):
image_size = (x.size(-1), x.size(-2))
feature_maps = []
for i in range(x.size(0)):
img = x[i].data.cpu().numpy()
img = img - np.min(img)
if np.max(img) != 0:
img = img / np.max(img)
feature = x[i].unsqueeze(0)
for name, module in self.model.named_children():
if name == 'block8':
feature = module(feature)
feature.register_hook(self.save_gradient)
self.feature = feature
elif name == 'last_linear':
feature = feature.view(feature.size(0), -1)
feature = module(feature)
else:
feature = module(feature)
classes = F.sigmoid(feature)
one_hot, _ = classes.max(dim=-1)
self.model.zero_grad()
one_hot.backward()
weight = self.gradient.mean(dim=-1, keepdim=True).mean(dim=-2, keepdim=True)
mask = F.relu((weight * self.feature).sum(dim=1)).squeeze(0)
mask = cv2.resize(mask.data.cpu().numpy(), image_size)
mask = mask - np.min(mask)
if np.max(mask) != 0:
mask = mask / np.max(mask)
feature_map = np.float32(cv2.applyColorMap(np.uint8(255 * mask), cv2.COLORMAP_JET))
cam = feature_map + np.float32((np.uint8(img.transpose((1, 2, 0)) * 255)))
cam = cam - np.min(cam)
if np.max(cam) != 0:
cam = cam / np.max(cam)
feature_maps.append(transforms.ToTensor()(cv2.cvtColor(np.uint8(255 * cam), cv2.COLOR_BGR2RGB)))
feature_maps = torch.stack(feature_maps)
return feature_maps
def get_config():
config = {
'dataset':"./test_data",
'weight':"./weight.pth",
'classes':['星野 源','NONSTYLE 井上','織田 信成','アンジャッシュ渡部']
}
return config
def prewhiten(x):
mean = x.mean()
std = x.std()
std_adj = std.clamp(min=1.0/(float(x.numel())**0.5))
y = (x - mean) / std_adj
return y
def run(config):
# device = 'cuda' if torch.cuda.is_available() else 'cpu'
device = 'cpu'
model = InceptionResnetV1(classify=True,num_classes=4).to(device).eval()
model.load_state_dict(torch.load(config['weight'], map_location=torch.device(device)))
grad_cam = GradCam(model)
transform = transforms.Compose([
Resize((160,160)),
np.float32,
ToTensor(),
prewhiten
])
print("start Grad-Cam")
for path in glob.glob("{}/*".format(config['dataset'])):
img = Image.open(path)
img_size = img.size
tensor_img = transform(img).unsqueeze(0)
plt.title("test image")
plt.imshow(img)
plt.show()
feature_img = grad_cam(tensor_img).squeeze(dim=0)
feature_img = transforms.ToPILImage()(feature_img)
pred_idx = model(tensor_img).max(1)[1]
print("pred: ", config["classes"][int(pred_idx)])
plt.title("Grad-CAM feature image")
plt.imshow(feature_img.resize(img_size))
plt.show()
print("--------------------")
config = get_config()
run(config)
そして、結果がこちら。
中心にめちゃくちゃ寄ってますね...
この結果をそのまま受け止めると、AIモデルは僕の鼻を特に見ていたようです。
ならば!!!
あえて、鼻に落書きをしてもう一度予測精度を見てみました。
すると、織田信成の確率がかなり高くなっていますね。
まとめ
今回はGrad-CAMを使って遊んでみました。
本当は、データオーギュメントとかモデル調整とかをしているところもっと書きたかったのですが、時間が無くて書くのを諦めました。
アドバイス・指摘・もっと似てる人などが見つかりましたら、是非気軽にコメントをください!!
追記
全てのコードと実行方法等を(pytorch_face_gradcam)にまとめたので、興味がある方は試してみてください。