OpenCVの勉強、第3回です。
前回は予め準備されているカスケード分類器を使ってオブジェクト検出をしましたが、
今回はカスケード分類器を自作してみたいと思います。
目標
テニスボールを検出できるカスケード分類器を作る。
作業フォルダの準備
分類器を作成する作業フォルダの作成と、必要なファイルの準備をします。
<DIR> cascade
<DIR> neg
<DIR> pos
<DIR> vec
opencv_annotation.exe
opencv_createsamples.exe
opencv_ffmpeg346_64.dll
opencv_interactive-calibration.exe
opencv_traincascade.exe
opencv_version.exe
opencv_version_win32.exe
opencv_visualisation.exe
opencv_world346.dll
opencv_world346d.dll
フォルダ
まず親フォルダを作成(私の場合はD:\opencvcascadeとしました)。
その中に「cascade」「neg」「pos」「vec」というフォルダを作成します。
ファイル
exeファイルとdllファイルは、学習済みの分類器をOpenCVの公式サイトからダウンロードします。
- 上部にある「Releases」から、OpenCV - 3.4.6(※)の「Win Pack」をダウンロード
- ダウンロードしたファイルを解凍
- \opencv346\build\x64\vc15\binの中に必要なファイルが入っていますので、exeファイルとdllファイルを作業フォルダにコピーしてください。
※OpenCV – 4.1.0以降は、「opencv_createsamples.exe」と「opencv_traincascade.exe」が入っていないため、OpenCV3以前のものをダウンロードします。
画像ファイルの準備
機械学習をするための画像ファイルを準備します。
精度を高めようとすると、正解データ7000枚、不正解データ3000枚程度が必要らしいですが、この場は分類器作成の手順を優先して、正解データ約70枚、不正解データ約60枚で進めたいと思います。
不正解画像
negフォルダの中に、正解を含まない画像を保存します。正解を含まなければ何でもいいです。
私はオンラインプログラミング教室で配布された犬猫画像を保存しました。
正解画像
posフォルダの中に、正解画像を保存します。
(この後の作業で、poslistにファイル名と正解の場所を記入するという作業があります。画像ファイルの大きさが1枚毎に違ったり、画像の中にテニスボール以外のものが入っていると場所の指定が面倒なので、全て200px × 200pxのサイズにトリミングして保存しました)

画像ファイルリストの作成
ネガリスト
コマンドプロンプトでnegディレクトリに移動。
以下コマンドを実行すると、neglist.txtが生成されます。
dir *.jpg /b > neglist.txt
neglistはフルパスで記載しないとエラーが出るらしいので、全てフルパスを追記します。
neglist.txt
D:\opencvcascade\neg\cat-001.jpg ←(一行ずつフルパスを追記する)
D:\opencvcascade\neg\cat-002.jpg
D:\opencvcascade\neg\cat-003.jpg
ポジリスト
コマンドプロンプトでposディレクトリに移動。
以下コマンドを実行すると、neglist.txtが生成されます。
dir *.jpg /b > poslist.txt
poslistはファイル名と正解の対象物の数と位置(x軸、Y軸の範囲)を記入する必要があります。
poslist.txt
01.jpg 1 0 0 200 200 ←(対象物の数、x軸、Y軸の範囲を追記する)
02.jpg 1 0 0 200 200
02.jpg 1 0 0 200 200
今回使った画像ファイルは事前に、テニスボールを中心に置いて200px × 200pxのサイズにトリミングしたため、対象物の位置はx軸-0px-200px、y軸-0px-200pxとしています。
精度をあげようと思ったら、正確に対象物の座標を指定してあげる必要があります。
opencv_createsamplesによるベクトルファイルの作成
createsamplesコマンドを使用することで、1枚の画像から角度やサイズを変更した大量のサンプルを自動生成することが出来ます。
コマンドプロンプトで親ディレクトリ(私の場合はD:\opencvcascade)に移動。
以下コマンドを実行すると、vecフォルダ内にpositive.vecファイルが生成されます。
opencv_createsamples.exe -info pos/poslist.txt -vec vec/positive.vec -num 1000 -maxidev 40 -maxxangle 0.8 -maxyangle 0.8 -maxzangle 0.5
| オプション名 | 用途 | ここでのパラメータ |
|---|---|---|
| -info | 正解画像リストファイル | pos/poslist.txt |
| -vec | ベクトルファイル保存場所 | vec/positive.vec |
| -num | 生成する画像数 | 1000 |
| -maxidev | 最大明度差 | 40 |
| -maxxangle | 最大回転角度 | 0.8 |
| -maxyangle | 最大回転角度 | 0.8 |
| -maxzangle | 最大回転角度 | 0.5 |
traincascadeによるカスケード分類器の作成
ここまで下準備を終えたら、ようやくcascade分類器の作成です。
以下コマンドを実行すると、cascadeフォルダ内にファイルが生成されます。
opencv_traincascade.exe -data cascade -vec vec/positive.vec -bg neg/neglist.txt -numPos 70 -numNeg 60
| オプション名 | 用途 | ここでのパラメータ |
|---|---|---|
| -data | 生成した分類器を保存するフォルダ | cascade |
| -vec | ベクトルファイル保存場所 | vec/positive.vec |
| -bg | ネガティブ画像のリストが記述されたテキストファイル | neg/neglist.txt |
| -numPos | 使用するポジティブ画像の数 | 70 |
| -numNeg | 使用するポジティブ画像の数 | 60 |
実行すると、計算が始まり、コマンドプロンプトには以下のように表示されます。
PARAMETERS:
cascadeDirName: cascade
vecFileName: vec/positive.vec
bgFileName: neg/neglist.txt
numPos: 70
numNeg: 60
numStages: 20
precalcValBufSize[Mb] : 1024
precalcIdxBufSize[Mb] : 1024
acceptanceRatioBreakValue : -1
stageType: BOOST
featureType: HAAR
sampleWidth: 24
sampleHeight: 24
boostType: GAB
minHitRate: 0.995
maxFalseAlarmRate: 0.5
weightTrimRate: 0.95
maxDepth: 1
maxWeakCount: 100
mode: BASIC
Number of unique features given windowSize [24,24] : 162336
===== TRAINING 0-stage =====
<BEGIN
POS count : consumed 70 : 70
NEG count : acceptanceRatio 60 : 1
Precalculation time: 0.127
+----+---------+---------+
| N | HR | FA |
+----+---------+---------+
| 1| 1| 1|
+----+---------+---------+
| 2| 1| 0.366667|
+----+---------+---------+
END>
Training until now has taken 0 days 0 hours 0 minutes 0 seconds.
===== TRAINING 1-stage =====
<BEGIN
POS count : consumed 70 : 70
NEG count : acceptanceRatio 60 : 0.461538
Precalculation time: 0.127
+----+---------+---------+
| N | HR | FA |
+----+---------+---------+
| 1| 1| 1|
+----+---------+---------+
| 2| 1| 1|
+----+---------+---------+
| 3| 1| 0.433333|
+----+---------+---------+
END>
Training until now has taken 0 days 0 hours 0 minutes 0 seconds.
枚数が少ないせいか、20回のTRAININGで26秒で生成が終わりました。
cascadeフォルダの中を見てみると、cascade.xmlというファイルが生成されていますので、これを使ってオブジェクト検出をしていきます。
(他にもStageXXというファイルが生成されていますが、それは使いません)
検証
では、自分で作成した分類器でオブジェクト検出をしてみましょう。
pythonプログラムはOpenCVの勉強②で使ったものを一部修正して使います。
import cv2
# 入力画像の読み込み(テスト用画像ファイル)
img = cv2.imread("tennisball.jpg")
# カスケード型識別器(自作した分類器)
cascade = cv2.CascadeClassifier("cascade.xml")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# face→ballに変更(そのままでもいいですけど)
ball = cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=3, minSize=(30, 30))
# 顔領域を赤色の矩形で囲む
for (x, y, w, h) in ball:
cv2.rectangle(img, (x, y), (x + w, y+h), (0,0,200), 3)
# 結果画像を保存
cv2.imwrite("result_tennisball.jpg",img)
# 結果画像を表示
cv2.imshow('image', img)
cv2.waitKey(0)
- 上記のpythonファイル(tennisball.py)
- 分類器(cascade.xml)
- テスト用の画像ファイル(tennisball.jpg)
上記のファイルを同じフォルダに保存し、pythonファイルを実行してみましょう。
$ python tennisball.py
結果
これは手前の2つのボールは検出できました(少しズレてますが)

これはボールは検出できたようですが、その他多数いろんなものも検出されちゃってます
(これはこれで何かカッコいいのですが)
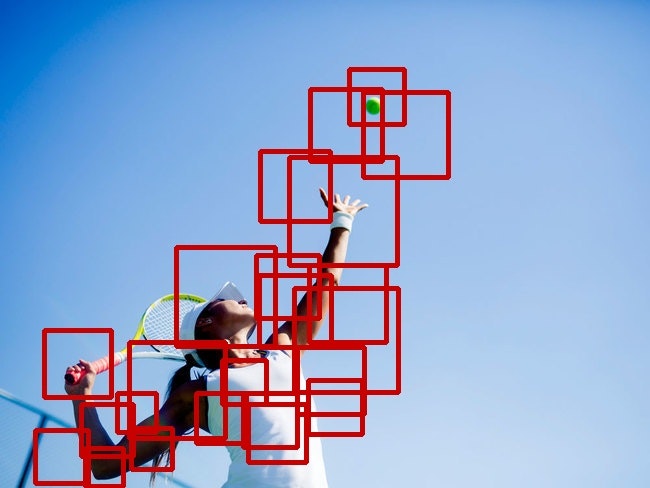
キウイとテニスボールって似てますもんね(笑)

テニスボールは特徴量が少なく、サンプルの画像数も少なかったせいか、分類器の精度はイマイチでしたが、作成方法はわかりました。