手書教育漢字データベースETL8
以前、MNISTという手書き数字のバイナリデーターを画像化しました。今回は日本語手書き文字ETL8Bの画像化してみます。MNISTはグレースケールでしたが、ETL8では2値化したデータを使用します。
あえて白黒画像の2値化したデーターを使うのは、OpenCvでニューラルネットワークの訓練画像で使う際に、2値化する作業が省けるためです。
前もって産総研という団体のページからETL-8B2というファイルをダウンロードしておきます。
データーファイルは、ETL8B2C1/ETL8B2C2/ETL8B2C3の三つに分かれています。どのようなデーター構造になっているか見てみましょう。
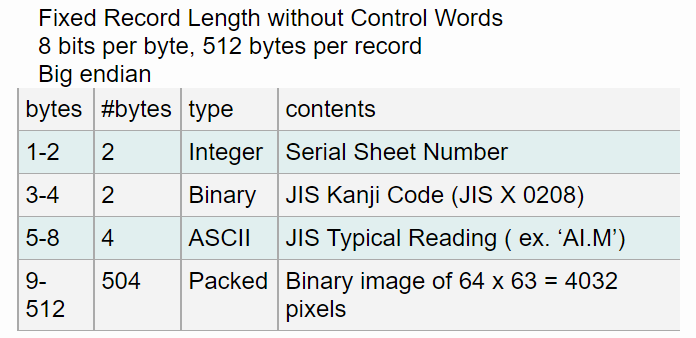
文字データーは、先頭の8バイトまでは画像の情報が格納されているようです。先頭2バイトはシート番号、次の2バイトは漢字コード、次の4バイトは読み方、そして最後の504バイトに日本語手書き文字の2値化データーが入っています。この後に5万件以上のデーターが入っています。ただしファイル最初の512バイト1文字分はダミー(空)の文字タイルが入っており、プログラム上でダミーは読み飛ばします。
プログラム作成
データを読み込み画像化するプログラムを作成するため次の構成にしました。
- Windows10
- Visual Studio 2017
- C++/CLI
2値化したバイナリーデータはビックエンディアンで保存されています。機械学習ではWindowsは少数派だからでしょう。MNISTのときもそうでした。
Windowsマシンならリトルエンディアンで読まないとおかしな画像になってしまいます。1バイトの8ビットを解読するときに後ろから手前に読むと正しいデーターとなります。メモリーの奥7番目から0番目まで読ませる必要があります(下のコード)。
データーを読むためReadSbyteという関数を使用します。1バイト読み1バイトストリームの位置を進めるという関数です。
int bit[8];
for (int y = 0; y < 63; y++) {
int count = 0;
for (int x = 0; x < 8; x++) {
Byte pbyte = pixelReader->ReadSByte();
for (int i = 7; i > -1; i--) {
bit[i] = ((pbyte >> i) & 0x01);
charImage[n].pixels[count][y] = bit[i];
count++;
}
}
画像出力
データーを読み込んだらStruct構造の入れ物に格納し、BITMAPイメージで出力します。画像サイズは63×64ピクセルです。
Bitmap^ bmpImage = gcnew Bitmap(width, height);
for (int y = 0; y <height; y++) {
for (int x = 0; x < width; x++) {
int colorDep = image.pixels[x][y];
if (colorDep == 1) { colorInt = 0; }
else { colorInt = 255; }
bmpImage->SetPixel(x, y, System::Drawing::Color::FromArgb(colorInt, colorInt, colorInt));
}
}
画像は、bmp,png,jpg,tiff,exif,gifの各画像ファイルに変換可能です。コード内で保存先を指定する際に、拡張子を画像処理に合ったものにします。データーファイルETL8B2C1とC3の初めの100文字分を画像化してみました(下画像)。


ETL8の概要
ETL8はOCRに使用されるくらい本格的なものです。非商業利用の場合ダウンロードして使用する際に料金はかからないですが、商用の場合、料金が発生するようです。以下に産総研のホームページから引用します。
★ETL8作成経緯
ETL8は、 日本電子工業振興協会OCR用手書文字専門委員会において、 昭和55年(1980年)に、 OCRユーザ・メーカ・名古屋大学・その他、 1600人の方々から収集したOCRシートを、 電子技術総合研究所において、 TOSBAC-40C観測システムにより観測したデータベースで、 教育漢字881字種、平仮名75字種が納められています。
[著作権] 本データベースの著作権は独立行政法人産業技術総合研究所が保有しています。
[使用目的] 本データベースは非商用目的に限り無料で使用出来ます。商用使用を目的とする場合は条件についてお問い合わせください。
OCRシート仕様
筆記者はなんと1600人というからかなり本格的。産業用に作成されたことがわかります。
OCRデータ収集用紙e8sht01 : A4判, 83kg OCR用紙(特種製紙)(10種)
ドロップアウト・カラー : No.114レディッシュオレンジ 50%スクリーン(大日本印刷)
文字枠 : 横 10mm、縦 10mm 文字枠ピッチ : 横 12.7mm、縦 15.24mm
文字枠数 : 13 x 16 = 208
対象文字 (計 956文字)
教育漢字 : 881 (昭和23年内閣告示第1号「当用漢字別表」による)
ひらがな : 75
OCRシート収集
記入上の制限 : 「手書き漢字OCR用紙記入のお願い」e8instで指定
筆記者数 : 延べ 1,600人(原則として一人10シート書いていますが複数人で10シートを書いたケースがあるため延べ表記になっています)
全サンプル数 : 152,960
データ収集 : 日本電子工業振興協会 OCR手書文字専門委員会、名古屋大学
観測装置
入力装置 : 128x1点フォトダイオード・アレイセンサ (ADC 6bit)(半導体アレイ レチコン社製 RL-128EC)
標本化間隔 : 0.108mm x 0.1016mm
濃度レベル : 16 (4bit ← 6bit)
標本点数 : 128 x 127 = 16,256 pixels
データベース作成
観測場所 : 電子技術総合研究所
使用計算機 : TOSBAC-40C(プログラム:)
作成年月 : 1980年2月
観測期間 : 1980年2月~??月