前置き
前回の記事の続きで、今回は2022年MLB大谷翔平選手のスイーパーの被打率をPythonで求めてみたいと思います。
Pythonコードの実行
読み込む元データについては前回の記事と同様のものを使用します。詳細はそちらを参照していただくとして、今回はその説明は割愛します。
polarsについて、実行環境にインストール済みとの前提で以下のコードを実行します。
import polars as pl
columns = ["pitch_name","player_name","events"]
df_mlb_pitch_data=pl.read_csv("./data/mlb_all_pitcher_data.csv",columns=columns) # データの読み込み
df_mlb_pitch_data.head(10)
出力は以下のようになります。カラムについて、"player_name"が"投手名"、"pitch_name"は"変化球名"というのはわかりますが、"events"はバッターが打った結果??ということなのでしょうか?
| player_name | events | pitch_name |
|---|---|---|
| Stephens, Jack… | "field_out" | "Sinker" |
| Stephens, Jack… | null | "4-Seam Fastbal… |
| Stephens, Jack… | null | "4-Seam Fastbal… |
| Stephens, Jack… | null | "Changeup" |
| Stephens, Jack… | "field_out" | "Curveball" |
| Stephens, Jack… | null | "4-Seam Fastbal… |
| Stephens, Jack… | null | "Curveball" |
| Stephens, Jack… | null | "Curveball" |
| Stephens, Jack… | "field_out" | "Sinker" |
| Stephens, Jack… | null | "Sinker" |
さて、今回は大谷翔平選手の被打率を求めるのでしたね。そのため、読み込んだデータフレームの"投手名"が大谷翔平選手の行のみに絞り込みを行いましょう。コードは以下です。
df_ohtani_pitch_data = df_mlb_pitch_data.filter(pl.col("player_name") == "Ohtani, Shohei") # 大谷翔平の行に絞る
df_ohtani_pitch_data.head()
| player_name | events | pitch_name |
|---|---|---|
| "Ohtani, Shohei… | "strikeout" | "Sweeper" |
| "Ohtani, Shohei… | null | "Sweeper" |
| "Ohtani, Shohei… | null | "Sweeper" |
| "Ohtani, Shohei… | "sac_fly" | "Curveball" |
| "Ohtani, Shohei… | "double" | "Sweeper" |
ここで、さっき気になった"events"のユニークな要素の個数をvalue_countメソッドを使って
を見てみます。
※なぜ大谷翔平選手のみに抽出した後に行うかというと、その方が"events"の要素が少なく済んだからです。
df_ohtani_pitch_data["events"].value_counts()
以下が上記コードの出力。
| events | counts |
|---|---|
| "triple" | 2 |
| "strikeout" | 219 |
| "caught_stealing" | 1 |
| "fielders_choice" | 2 |
| null | 1968 |
| "double" | 23 |
| "force_out" | 10 |
| "hit_by_pitch" | 2 |
| "double_play" | 1 |
| "field_error" | 4 |
| "grounded_into_dp" | 10 |
| "catcher_interfere" | 1 |
| "sac_fly" | 3 |
| "single" | 85 |
| "walk" | 44 |
| "field_out" | 240 |
| "home_run" | 14 |
公式のカラム説明で"events"の説明は"Event of the resulting Plate Appearance."となっていて、日本語訳したのですがピンときませんでした。
そこでチャットGPTに聞いていると、
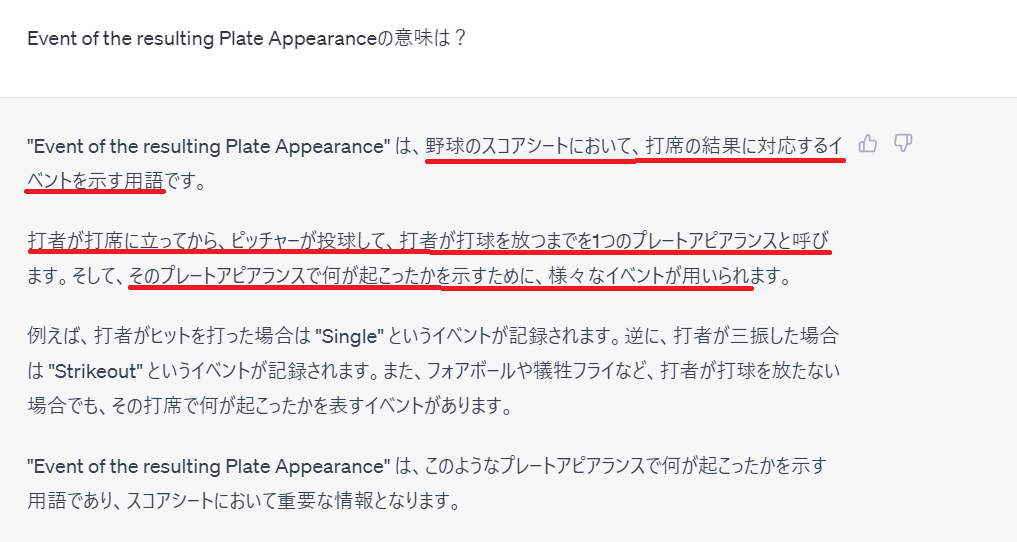
なんと、超明快な回答が得られてしまいました!!!
つまり、"events"とはバッターのあるときの打席の結果というわけですね。
今回はググるよりチャットGPTの説明に頼ってしましました。
チャットgp便利で、凄すぎ。。
さて、本題に戻りますが、求めたいのは大谷翔平選手のスイーパーの被打率でしたね。
こちらもチャットGPTに聞いたら以下の大変わかりやすい回答が得られました。
野球の被打率(ひだりつ)とは、投手が投げた球を打者が打ち、安打となった割合のことを指します。つまり、投手が投げた球のうち、打者に打たれた球の割合を示す指標です。
具体的には、被打率は以下のように計算されます。
被打率 = 安打数 ÷ 打数
安打数は、投手が投げた球を打者が打ち、ヒットや二塁打、三塁打、本塁打になった回数です。打数は、投手が投げた球を打者が打った回数を表します。
例えば、投手が100球投げて、打者が30回打った場合、そのうち20回が安打となったとすると、その投手の被打率は 20 ÷ 30 = 0.667(小数第3位まで)となります。
被打率は安打数を打数で割れば求まるとのことで、ますは安打のみのデータフレームを以下のコードで抽出します。
df_ohtani_pitch_hits_data = df_ohtani_pitch_events_data.filter((pl.col("events")=="single")|(pl.col("events")=="double")|(pl.col("events")=="triple")|(pl.col("events")=="home_run"))
df_ohtani_pitch_hits_data
| events | counts |
|---|---|
| triple | 2 |
| double | 23 |
| home_run | 14 |
| single | 85 |
次に打数のみのデータフレームを以下のコードで抽出します。
df_ohtani_pitch_at_bat_data = df_ohtani_pitch_events_data.filter(~(pl.col("events")=="walk")&~(pl.col("events").is_null()))
df_ohtani_pitch_at_bat_data
| events | counts |
|---|---|
| "field_error" | 4 |
| "fielders_choice" | 2 |
| "grounded_into_dp" | 10 |
| "force_out" | 10 |
| "triple" | 2 |
| "double_play" | 1 |
| "double" | 23 |
| "strikeout" | 219 |
| "home_run" | 14 |
| "catcher_interf" | 1 |
| "caught_stealing" | 1 |
| "hit_by_pitch" | 2 |
| "field_out" | 240 |
| "single" | 85 |
| "sac_fly" | 3 |
安打数のデータフレームと打数のデータフレームがそれぞれ出来上がったので、その合計を求めてみます。
安打数の合計は以下のように、
at_bat = df_ohtani_pitch_at_bat_data["counts"].sum()
# 出力結果
617
打数の合計は以下のように求めることができます。
hits = df_ohtani_pitch_hits_data["counts"].sum()
# 出力結果
124
「被打率 = 安打数 ÷ 打数」なので、安打数を打数で割ります。
# 被打率を求める
hits / at_bat
# 出力結果
0.20097244732576985
結果、大谷翔平選手のスイーパーの被打率はおよそ.201(2割0分1厘)くらいということがわかりました。
また、以下が2022年の大谷翔平選手の変化球の投球割合を円グラフで表した結果を示します。

変化球の投球割合としては、大谷翔平選手はスイーパーを多投していることがわかります。
(確かに去年、今年はスイーパー投げる割合増えたなと体感的に感じています。。)
メジャーリーグの2022年の平均打率は.243(2割4分3厘)くらいだそうで、それを明確に下回る大谷翔平選手のスイーパーは大変優れていることがわかりますね!!
https://www.nikkansports.com/baseball/mlb/column/shikama/news/202210080000153.html
(参考程度に円グラフを求めるコードは一応以下に記載します。。)
import matplotlib.pyplot as plt
# データの並び替え
df_sorted = df_change_ohtani.select(pl.col("count", "pitch_name").sort_by("count"), descending=True)
# カスタムカラーマップの作成
cmap = plt.get_cmap("tab20c")
colors = [cmap(i) for i in range(len(df_sorted['pitch_name']))]
# 円グラフの描画
fig, ax = plt.subplots()
wedges, labels, autopct = ax.pie(df_sorted['count'], labels=df_sorted['pitch_name'], colors=colors,
autopct='%1.1f%%', textprops={'fontsize': 10})
ax.axis('equal')
# 数値ラベルの設定
for w in wedges:
w.set_linewidth(0.5)
w.set_edgecolor('white')
for l in labels:
l.set_fontsize(12)
for a in autopct:
a.set_fontsize(12)
if float(a.get_text().replace('%', '')) < 5:
a.set_text('')
plt.show()
終わりに
今回は大谷翔平選手のスイーパーの被打率をPythonで求めてみました。
次にこれまでの結果を踏まえ、MLB全投手のスイーパーの被打率を求め、スイーパーの被打率を目的変数、スライダ―の平均球速、横の変化量の平均、縦の変化量の平均の3つを説明変数として重回帰分析を行ってみたいと思います。