1. はじめに
1-1 ご挨拶
初めまして、井村と申します。
Azureの案件に数年参画、資格はAZ-305、400等を取得、Azureの記事を定期的に投稿しています。
ですが、Azureに対する知識が定着していないなぁと感じる場面が多々あります。
本記事の目的は資格試験であるDP-900の試験項目を通して、知識の定着、読者の方が少しでもAzureをご理解してもらえることになります。
1-2 対象読者
- Azureに興味がある
1-3 執筆方法
資格試験の出題範囲が記載されている「試験の学習ガイド」の「評価されるスキル」について回答していきます。
試験対策、様々な技術習得を目的としてMicrosoft Learnが存在します。Microsoft Learn から「評価されるスキル」に対する回答を抜粋しつつ、その他ドキュメントも参考にしながら執筆しました。
2. 対象の「試験の学習ガイド」および「評価されるスキル」
2-1 今回の資格試験
対象の資格はDP-900にしました。現在最新バージョンである「2023年11月2日時点の評価されるスキル」を対象とします。
DP-900の説明は以下の通りになります。
この試験は、コア データの概念と関連する Microsoft Azure データ サービスに関する
知識を示す機会です。 この試験の受験者は、マイペースで進められる、
または講師による指導付きの試験 DP-900 の資料に精通している必要があります。
この試験は、クラウド内のデータを扱い始めた方を対象としています。
次のことを理解している必要があります。
・ リレーショナルおよび非リレーショナル データの概念。
・ トランザクションや分析など、さまざまな種類のデータ ワークロード。
2-2 評価されるスキル
「2023年11月2日時点の評価されるスキル」の説明は以下の通りになります。
全部で29項目になります。
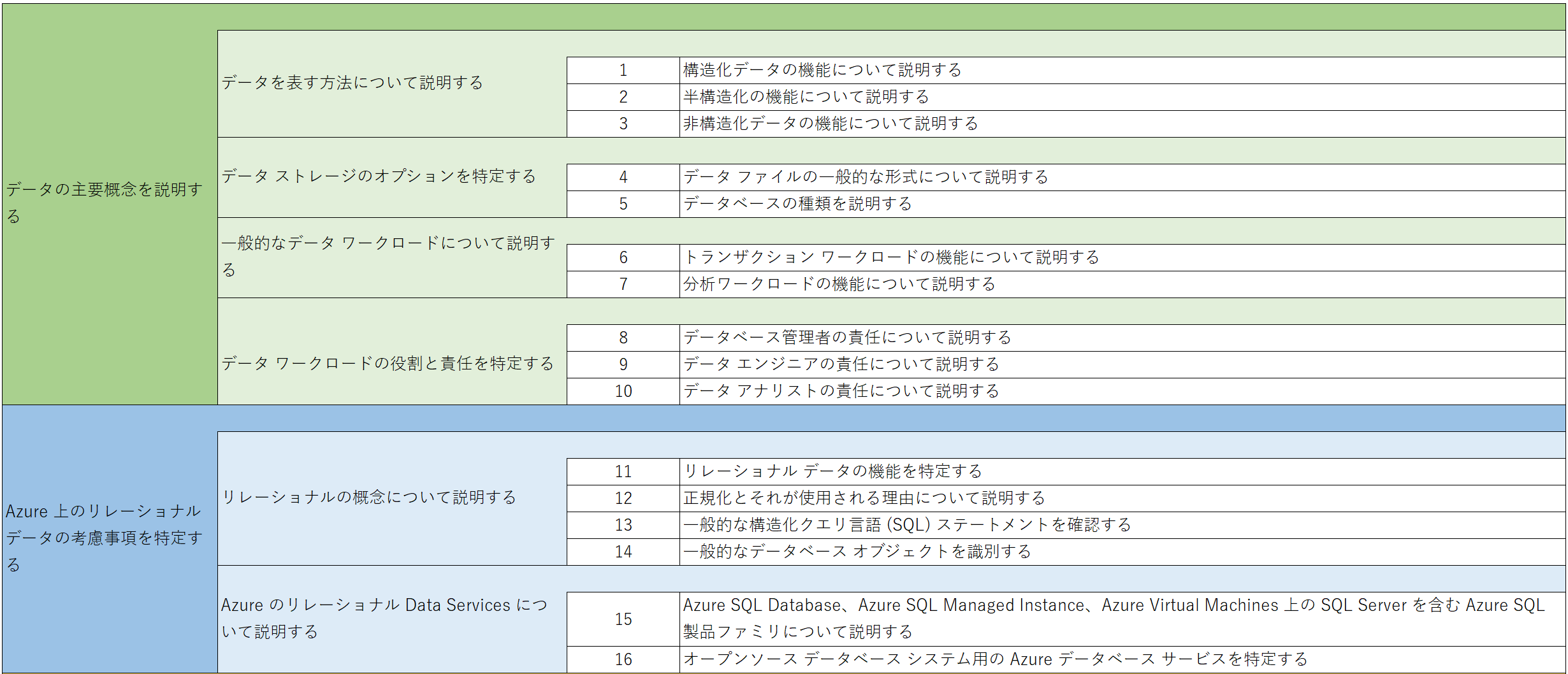
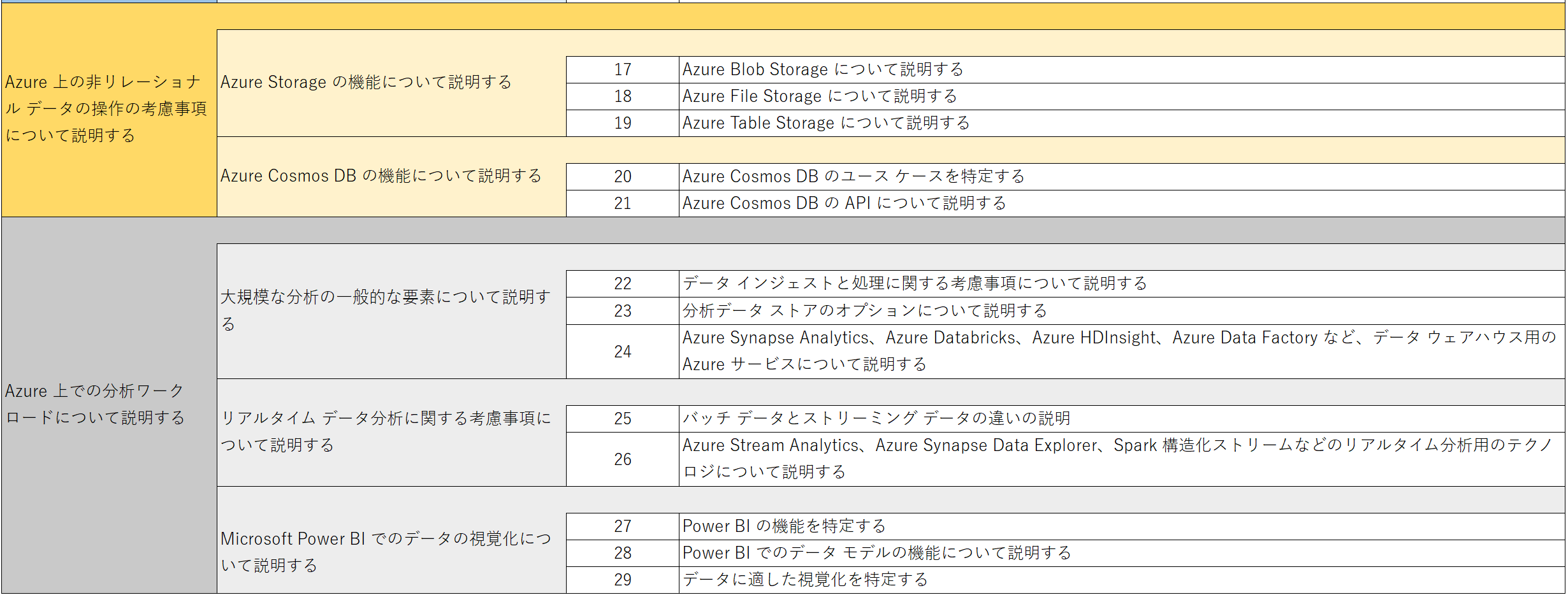
3. 説明
3-1 データの主要概念を説明する
3-1-1 データを表す方法について説明する
1. 構造化データの機能について説明する
構造化データとは固定 "スキーマ" に準拠したデータであり、すべてのデータが同じフィールドとプロパティを持っています。 最も一般的に、構造化データ エンティティのスキーマは "表形式" です。
構造化データは、多くの場合、"リレーショナル" モデルのキー値を使用して複数のテーブルが参照できるデータベースに格納されます。
2. 半構造化の機能について説明する
"半構造化" データは、ある程度の構造を持つ情報ですが、エンティティ インスタンス間の一部のバリエーションを可能にする情報です。半構造化データの一般的な形式の 1 つが、JavaScript Object Notation (JSON) です。
3. 非構造化データの機能について説明する
ドキュメント、画像、オーディオおよびビデオ データ、バイナリ ファイルには、特定の構造がない場合があります。 この種のデータは "非構造化" データと呼ばれます。
3-1-2 データ ストレージのオプションを特定する
4. データ ファイルの一般的な形式について説明する
データの格納に使用される特定のファイル形式は、次のようなさまざまな要因によって異なります。
- 格納されるデータの種類(構造化、半構造化、または非構造化)
- データの読み取り、書き込み、および処理を行う必要があるアプリケーションとサービス。
- データ ファイルを人間が判読できるようにするか、効率的なストレージと処理のために最適化する必要性。
いくつかの一般的なファイル形式については、以下になります。
- 区切りテキスト ファイル
多くの場合、データは、特定のフィールド区切り記号と行ターミネータを使用してプレーン テキスト形式で格納されます。 区切りデータの最も一般的な形式は、コンマ区切り値 (CSV) です。
FirstName,LastName,Email
Joe,Jones,joe@litware.com
Samir,Nadoy,samir@northwind.com
- JavaScript Object Notation (JSON)
JSON は、複数の属性を持つデータ エンティティ (オブジェクト) を定義するために階層ドキュメント スキーマが使用される、ユビキタス形式です。 各属性はオブジェクト (またはオブジェクトのコレクション) である場合があり、JSON を構造化と半構造化の両方のデータに適した柔軟な形式にします。
{
"customers":
[
{
"firstName": "Joe",
"lastName": "Jones",
"contact":
[
{
"type": "home",
"number": "555 123-1234"
},
{
"type": "email",
"address": "joe@litware.com"
}
]
},
{
"firstName": "Samir",
"lastName": "Nadoy",
"contact":
[
{
"type": "email",
"address": "samir@northwind.com"
}
]
}
]
}
- XML (Extensible Markup Language)
XML は、1990 年代と 2000 年代に人気があった人間が判読できるデータ形式です。山かっこ (../) で囲まれた ''タグ'' を使用して、この例に示すように、''要素'' と ''属性'' を定義します。
<Customers>
<Customer name="Joe" lastName="Jones">
<ContactDetails>
<Contact type="home" number="555 123-1234"/>
<Contact type="email" address="joe@litware.com"/>
</ContactDetails>
</Customer>
<Customer name="Samir" lastName="Nadoy">
<ContactDetails>
<Contact type="email" address="samir@northwind.com"/>
</ContactDetails>
</Customer>
</Customers>
- バイナリ ラージ オブジェクト (BLOB)
最終的には、すべてのファイルがバイナリ データ (1 と 0) として格納されますが、上述のように人間が判読できる形式であり、バイナリ データのバイトは印刷可能な文字にマップされます。しかし、一部のファイル形式では、特に非構造化データの場合、アプリケーションによって解釈され、レンダリングする必要がある未加工のバイナリとしてデータが格納されます。 バイナリとして格納される一般的なデータの種類には、画像、ビデオ、オーディオ、およびアプリケーション固有のドキュメントなどがあります。
その他、最適化された一般的なファイル形式には、Avro(行ベースの形式)、ORC(データは行ではなく列として編成)、Parquet(別の列形式のデータ形式) などがあります。
5. データベースの種類を説明する
- リレーショナル データベース
リレーショナル データベースは、構造化データの格納とクエリに一般的に使用されます。 データは、顧客、製品、販売注文などのエンティティを表すテーブルに格納されます。
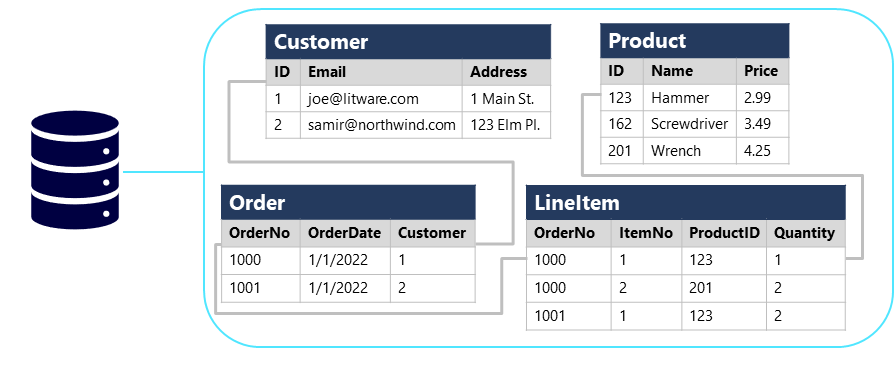
-
非リレーショナル データベース
非リレーショナル データベースは、データにリレーショナル スキーマを適用しないデータ管理システムです。 非リレーショナル データベースは多くの場合、NoSQL データベースと呼ばれます。-
キー値データベース
各レコードは一意のキーと関連する値で構成され、任意の形式にすることができます。
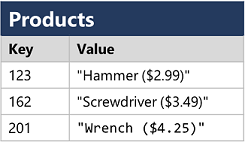
キー値データベース -
ドキュメント データベース
値が JSON ドキュメントである特定の形式のキー値データベースです (解析とクエリを実行するためにシステムが最適化されています)。
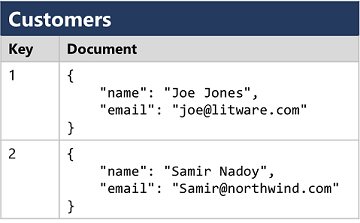
ドキュメント データベース -
列ファミリ データベース
行と列で構成される表形式データが格納されますが、列を列ファミリと呼ばれるグループに分割することができます。 各列ファミリには、論理的に相互に関連付けられた列のセットが保持されます。

列ファミリ データベース -
グラフ データベース
ノードとしてのエンティティと、その関係を定義するリンクが格納されます。
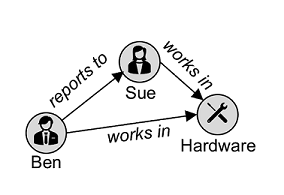
グラフ データベース
-
3-1-3 一般的なデータ ワークロードについて説明する
6. トランザクション ワークロードの機能について説明する
トランザクション システムは、組織が追跡する必要がある特定のイベントをカプセル化する "トランザクション" を記録します。トランザクションは、銀行取引システムのアカウント間での料金の移動のような金銭的なものや、商品やサービスに対する顧客からの支払いを追跡する小売システムの一部である場合があります。
トランザクション システムによって実行される作業は、多くの場合、オンライン トランザクション処理 (OLTP) と呼ばれます。
OLTP システムでは、次のような、いわゆる ACID セマンティクスをサポートするトランザクションが適用されます。
- 原子性(Atomicity)
各トランザクションは 1 つの単位として扱われ、完全に成功するか完全に失敗します。 - 一貫性(Consistency)
トランザクションでは、1 つの有効な状態から別のそれに移る場合のみ、データベースのデータを取得することができます。 - 分離性(Isolation)
同時実行トランザクションが相互に干渉することはなく、一貫性のあるデータベースの状態になる必要があります。 - 持続性(Durability)
トランザクションがコミットされると、トランザクションはコミットされたままになります。
7. 分析ワークロードの機能について説明する
分析データ処理では、通常、履歴データまたはビジネス メトリックの膨大な量を格納する読み取り専用 (または read-mostly) システムが使用されます。 分析は、特定の時点のデータのスナップショットまたは一連のスナップショットに基づいて行うことができます。
オンライン分析処理システム(OLAP)の一般的なアーキテクチャは次のようになります。
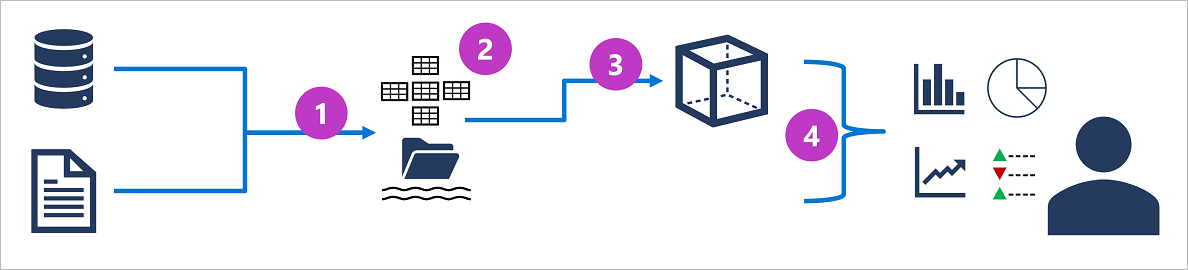
1. リストオペレーショナル データは解析用に抽出され、変換され、データ レイクに読み込まれます (ETL)。
2. データはテーブルのスキーマに読み込まれます。通常は、データ レイク内のファイルに対して表形式の抽象化を行う Spark ベースのデータ レイクハウス、または完全なリレーショナル型の SQL エンジンを備えたデータ ウェアハウスです。
3. データ ウェアハウス内のデータを集計し、オンライン分析処理 (OLAP) モデル (キューブ) に読み込む場合があります。 ファクト テーブルの集計数値 ("メジャー") は、ディメンション テーブルからの "ディメンション" の交差部分に対して計算されます。 たとえば、売上収益は、日付、顧客、製品別に合計される場合があります。
4. データ レイク、データ ウェアハウス、分析モデル内のデータに対してクエリを実行して、レポート、視覚化、ダッシュボードを生成することができます。
-
データ レイク
大量のファイル ベースのデータを収集して分析する必要がある大規模データ分析処理シナリオで一般的です。 -
データ ウェアハウス
読み取り操作用に最適化されたリレーショナル スキーマにデータを格納するための確立された方法です。主に、レポートとデータの視覚化をサポートするためのクエリが実行されます。
さまざまな種類のユーザーが、アーキテクチャ全体の異なるステージでデータ分析作業を実行する場合があります。 次に例を示します。
- データ サイエンティスト
データ レイク内のデータ ファイルを直接使用して、データの探索とモデル化を行う場合があります。 - データ アナリスト
複雑なレポートと視覚化を生成するために、データ ウェアハウス内のテーブルに直接クエリを実行できます。 - ビジネス ユーザー
レポートまたはダッシュボードの形式で、分析モデル内で事前に集計済みのデータを使用する場合があります。
3-1-4 データ ワークロードの役割と責任を特定する
8. データベース管理者の責任について説明する
オンプレミスおよびクラウドベースのデータベース システムの設計、実装、メンテナンス、および運用面を担当します。 データベースの全体的な可用性、一貫したパフォーマンス、および最適化を担当します。 利害関係者と協力し、自然災害または人為的エラーが発生した後に復旧するためのバックアップおよび復旧計画のポリシー、ツール、およびプロセスを実装します。
また、データベース管理者は、データベース内のデータのセキュリティを管理し、データに対する権限を付与し、必要に応じてユーザーにアクセスを許可または拒否する責任もあります。
9. データ エンジニアの責任について説明する
利害関係者と協力して、データ インジェスト パイプライン、クレンジングおよび変換作業、分析ワークロード用のデータ ストアを含む、データ関連のワークロードを設計および実装します。 リレーショナルおよび非リレーショナル データベース、ファイル ストア、データ ストリームなど、さまざまなデータ プラットフォーム テクノロジを使用します。
クラウド内、およびオンプレミスからクラウド データ ストアまでの範囲において、データのプライバシーを確実に維持する責任もあります。 また、データ パイプラインの管理と監視を自身で行い、予期したとおり確実にデータが読み込まれるようにします。
10. データ アナリストの責任について説明する
企業がデータ資産の価値を最大化できるようにします。 トレンドと関係を特定するためのデータの調査、分析モデルの設計と構築、およびレポートと視覚化による高度な分析機能の有効化を担当しています。
データ アナリストは、特定のビジネス要件に基づいて生データを関連する分析情報に変換し、関連する分析情報を提供します。
3-2 Azure 上のリレーショナル データの考慮事項を特定する
3-2-1 リレーショナルの概念について説明する
11. リレーショナル データの機能を特定する
リレーショナル データベースでは、現実世界のエンティティのコレクションを "テーブル" としてモデル化します。エンティティは、情報を記録する何かにすることができます。
リレーショナル テーブルは構造化データの形式であり、テーブルの各行に同じ列が含まれます。ただし、場合によっては、すべての列に値が必要になるわけではありません。
各列には、特定のデータ型のデータが格納されます。
12. 正規化とそれが使用される理由について説明する
正規化は、データの重複を最小限に抑え、データの整合性を強制適用するスキーマ設計プロセスを表します。
正規化のさまざまなレベル (または "形式") にデータをリファクタリングするプロセスの定義には、多くの複雑な規則がありますが、実用的な目的のための単純な定義は、次のとおりです。
1. 各 "エンティティ" を独自のテーブルに分離します。
2. 個別の "属性" を独自の列に分離します。
3. "主キー" を使用して各エンティティ インスタンス (行) を一意に識別します。
4. "外部キー" 列を使用して関連エンティティをリンクします。
13. 一般的な構造化クエリ言語 (SQL) ステートメントを確認する
SQL は、リレーショナル データベースとの通信に使用されます。 SQL ステートメントを使用して、データベース内のデータの更新や、データベースからのデータの取得などのタスクを実行します。
SELECT、INSERT、UPDATE、DELETE、CREATE、DROP などの SQL ステートメントを使用すると、データベースで実行するほとんどすべての処理を実現できます。 これらの SQL ステートメントは SQL 標準の一部ですが、多くのデータベース管理システムには、そのデータベース管理システム固有の処理を行うための独自の追加拡張機能も用意されています。
一般的な SQL 言語の例を次に示します。
- Transact-SQL (T-SQL)
このバージョンの SQL は、Microsoft SQL Server と Azure SQL サービスによって使用されます。 - pgSQL
この言語には、PostgreSQL で実装されている拡張機能が含まれています。 - PL/SQL
Oracle によって使用される言語です。 PL/SQL とは、手続き型言語/SQL を意味します。
SQL ステートメントの種類
SQL ステートメントは、次の 3 つの主要な論理グループにグループ化されます。
- DDL ステートメント
データベース内のテーブルやその他のオブジェクト (テーブル、ストアド プロシージャ、ビューなど) を作成、変更、および削除することができます。
| ステートメント | 説明 |
|---|---|
| CREATE | データベース内にテーブルやビューなどの新しいオブジェクトを作成します。 |
| ALTER | オブジェクトの構造を変更します。 たとえば、テーブルを変更して新しい列を追加します。 |
| DROP | データベースからオブジェクトを削除します。 |
| RENAME | 既存のオブジェクトの名前を変更します。 |
次の例では、新しいデータベース テーブルを作成します。
CREATE TABLE Product
(
ID INT PRIMARY KEY,
Name VARCHAR(20) NOT NULL,
Price DECIMAL NULL
);
- DCL ステートメント
通常、DCL ステートメントを使用して、特定のユーザーまたはグループに対する権限を許可、拒否、または取り消して、データベース内のオブジェクトへのアクセスを管理します。
| ステートメント | 説明 |
|---|---|
| GRANT | 特定のアクションを実行するためのアクセス許可を付与する |
| DENY | 特定のアクションを実行するためのアクセス許可を拒否する |
| REVOKE | 以前に許可されたアクセス許可を削除する |
次の GRANT ステートメントでは、user1 という名前のユーザーが Product テーブルのデータを読み取り、挿入、変更することができます。
GRANT SELECT, INSERT, UPDATE
ON Product
TO user1;
- DML ステートメント
テーブル内の行を操作します。 これらのステートメントによって、データの取得 (クエリ)、新しい行の挿入、または既存の行の変更を行うことができます。 不要になった行を削除することもできます。
4 つの主要な DML ステートメントは次のとおりです。
| ステートメント | 説明 |
|---|---|
| SELECT | テーブルから行を読み取る |
| INSERT | テーブルに新しい行を挿入する |
| UPDATE | 既存の行のデータを変更する |
| DELETE | 既存のファイルを削除する |
次のコードは、Customer テーブルから、 City 列の値が "Seattle" であるすべての列 (*で示されている) を選択する SQL ステートメントの例です。
SELECT *
FROM Customer
WHERE City = 'Seattle';
SQL を使用して既存の行を更新する方法を示します。 これにより、Customer テーブルの、ID 列の値が 1 である行の Address 列の値が変更されます。 他のすべての行は変更されません。
UPDATE Customer
SET Address = '123 High St.'
WHERE ID = 1;
DELETE ステートメントを使用して行を削除します。 削除元となるテーブルを指定し、削除する行を識別する WHERE 句を指定します。
DELETE FROM Product
WHERE ID = 162;
INSERT ステートメントは少し形式が異なっています。 INTO 句でテーブルと列を指定し、それらの列に格納する値のリストを指定します。 標準の SQL では、次の例に示すように、一度に 1 行を挿入する操作のみがサポートされています。
INSERT INTO Product(ID, Name, Price)
VALUES (99, 'Drill', 4.99);
14. 一般的なデータベース オブジェクトを識別する
テーブルに加えて、リレーショナル データベースには、データ編成の最適化、プログラムのアクションのカプセル化、アクセス速度の向上に役立つ、他の構造体を含めることができます。
- ビュー
SELECT クエリの結果に基づく仮想テーブルです。 ビューは、基になる 1 つ以上のテーブル内の指定された行のウィンドウと考えることができます。 たとえば、注文と顧客データを取得する Order と Customer のテーブルのビューを作成して、注文の配送先住所を簡単に特定できる単一のオブジェクトを提供できます。
CREATE VIEW Deliveries
AS
SELECT o.OrderNo, o.OrderDate,
c.FirstName, c.LastName, c.Address, c.City
FROM Order AS o JOIN Customer AS c
ON o.Customer = c.ID;
ビューに対してクエリを実行し、テーブルとほぼ同じ方法でデータをフィルター処理できます。 次のクエリでは、シアトルに住んでいる顧客の注文の詳細が検索されます。
SELECT OrderNo, OrderDate, LastName, Address
FROM Deliveries
WHERE City = 'Seattle';
- ストアド プロシージャ
コマンドで実行できる SQL ステートメントを定義します。 ストアド プロシージャは、アプリケーションがデータを操作するときに実行する必要があるアクションのプログラム ロジックをデータベースにカプセル化するために使用されます。
パラメーターを使用してストアド プロシージャを定義して、特定のキーまたは条件に基づくデータに適用する必要がある共通するアクションに対して、柔軟なソリューションを作成できます。 たとえば、次のストアド プロシージャを定義して、指定した製品 ID に基づいて製品の名前を変更できます。
CREATE PROCEDURE RenameProduct
@ProductID INT,
@NewName VARCHAR(20)
AS
UPDATE Product
SET Name = @NewName
WHERE ID = @ProductID;
製品の名前を変更する必要が生じたら、ストアド プロシージャを実行して、製品の ID と新しく割り当てる名前を渡します。
EXEC RenameProduct 201, 'Spanner';
- インデックス
テーブル内でのデータ検索に便利です。 データベースにインデックスを作成する場合は、テーブルの列を指定します。インデックスによって、テーブル内の対応する行へのポインターも含めて、このデータのコピーが並べ替えられた順序で格納されます。 WHERE 句でこの列を指定するクエリをユーザーが実行すると、データベース管理システムは、このインデックスを使用してテーブル全体を 1 行ごとスキャンする場合よりも速くデータを取り込むことができます。
たとえば、次のコードを使用して、Product テーブルの Name 列にインデックスを作成できます。
CREATE INDEX idx_ProductName
ON Product(Name);
行が少ないテーブルの場合、インデックスの使用は、単にテーブル全体を読み取り、クエリによって要求された行を見つけるほど効率的ではない可能性があります。 ただし、テーブルに多数の行がある場合、インデックスによってクエリのパフォーマンスが大幅に向上する可能性があります。
3-2-2 Azure のリレーショナル Data Services について説明する
15. Azure SQL Database、Azure SQL Managed Instance、Azure Virtual Machines 上の SQL Server を含む Azure SQL 製品ファミリについて説明する
Azure SQL は、Azure の Microsoft SQL Server ベースのデータベース サービス ファミリの総称です。
-
Azure Virtual Machines (VM) 上の SQL Server
SQL Server がインストールされた Azure で実行されている仮想マシン。 -
Azure SQL Managed Instance
基盤となるハードウェアとオペレーティング システムを抽象化しながら、オンプレミスの SQL Server インスタンスとほぼ 100% の互換性を提供するサービスとしてのプラットフォーム (PaaS) オプション。 -
Azure SQL Database
クラウド向けに設計された、フル マネージドの拡張性の高い PaaS データベース サービス。 -
Azure SQL Edge
時系列データのストリーミングを操作する必要のある、モノのインターネット (IoT) シナリオ向けに最適化された SQL エンジン。
| Azure VM での SQL Server | Azure SQL Managed Instance | Azure SQL データベース | |
|---|---|---|---|
| クラウド サービスの種類 | IaaS | PaaS | PaaS |
| SQL Server の互換性 | オンプレミスの物理および仮想化されたインストールと完全に互換性があります。 アプリケーションとデータベースは、変更せずに簡単に "リフト アンド シフト" 移行することができます。 | SQL Server とのほぼ 100% の互換性。 ほとんどのオンプレミス データベースは、Azure Database Migration Service を使用して最小限のコード変更で移行できます | SQL Server のデータベースレベルのほとんどのコア機能がサポートされます。 オンプレミス アプリケーションが依存している一部の機能は使用できない可能性があります。 |
| アーキテクチャ | SQL Server インスタンスは、仮想マシンにインストールされます。 各インスタンスで複数のデータベースをサポートできます。 | 各マネージド インスタンスで複数のデータベースをサポートできます。 さらに、''インスタンス プール'' を使用すると、より小さなインスタンス間でリソースを効率的に共有できます。 | 専用の管理対象 (論理) サーバーで ''単一データベース'' をプロビジョニングできます。または、''エラスティック プール'' を使用して複数のデータベース間でリソースを共有し、オンデマンドのスケーラビリティを利用できます。 |
| 可用性 | 99.99% | 99.99% | 99.995% |
| 管理 | オペレーティング システムと SQL Server の更新、構成、バックアップ、およびその他のメンテナンス タスクを含む、サーバーのすべての側面を管理する必要があります。 | 完全に自動化された更新、バックアップ、および回復。 | 完全に自動化された更新、バックアップ、および回復。 |
| ユース ケース | このオプションは、オンプレミスの SQL Server ソリューションを移行または拡張し、サーバーとデータベースの構成のすべての側面の完全な制御を保持する必要がある場合に使用します。 | 特に既存のアプリケーションに対して最小限の変更が必要な場合は、ほとんどのクラウド移行シナリオでこのオプションを使用します。 | このオプションは、新しいクラウド ソリューションで、またはインスタンスレベルの依存関係が最小限のアプリケーションを移行する場合に使用します。 |
16. オープンソース データベース システム用の Azure データベース サービスを特定する
-
Azure Database for MySQL
MySQL Community Edition に基づく、Azure クラウド内の MySQL の PaaS サービス。利点は以下のとおり。- 組み込みの高可用性。
- 予測可能なパフォーマンス。
- 需要に迅速に応える簡単なスケーリング。
- 保存中データと転送中データのセキュリティ保護。
- 最大 35 日間の自動バックアップとポイントインタイム リストア。
- エンタープライズ レベルのセキュリティおよび法律への準拠。
-
Azure Database for MariaDB
MariaDB Community Edition に基づく、Azure クラウド内の MariaDB の PaaS サービス。利点は以下のとおり。- 追加コストなしの組み込みの高可用性。
- 包括的な従量課金制の料金を使用した、予測可能なパフォーマンス。
- 必要に応じて、数秒以内でスケーリング。
- 保存中および転送中の機密データのセキュリティ保護。
- 自動バックアップと最大 35 日間のポイントインタイム リストア。
- エンタープライズグレードのセキュリティとコンプライアンス。
-
Azure Database for PostgreSQL
Azure クラウド内の PostgreSQL の PaaS サービス。利点は以下のとおり。- 組み込みの高可用性。
- 保存中データと転送中データのセキュリティ保護。
- 最大 35 日間の自動バックアップとポイントインタイム リストア。
- 数秒以内でのパフォーマンスの調整とスケール。
- サーバーを停止/開始して TCO を削減する。
- Azure メトリックは 1 分間隔で、 30 日間の履歴が保持。
- 組み込みの PgBouncer
3-3 Azure 上の非リレーショナル データの操作の考慮事項について説明する
3-3-1 Azure Storage の機能について説明する
17. Azure Blob Storage について説明する
Azure Blob Storage は、大量の非構造化データをバイナリ ラージ オブジェクト (BLOB) としてクラウドに格納できるサービスです。BLOB が "コンテナー" に格納されます。 コンテナーは、関連する BLOB をまとめてグループ化します。BLOB を仮想フォルダーの階層に整理できますが、フォルダー レベルの操作を実行してアクセスを制御したり、一括操作を実行したりすることはできません。
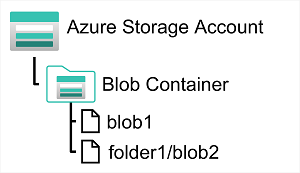
Azure Blob Storage では、次の 3 つの異なる種類の BLOB がサポートされています。
- ブロック BLOB
ブロックのセットとして処理されます。 各ブロックのサイズは可変で、最大 4000 MiB です。 1 つのブロック BLOB で最大190.7 TiB (4000 MiB X 50,000 ブロック) を格納でき、最大サイズは 5000 MiB を超えます。 ブロックは、個別の単位として読み取りや書き込みのできる最小のデータ量です。 ブロック BLOB は、あまり変更されない不連続で大きなバイナリ オブジェクトを格納するのに最適です。 - ページ BLOB
固定サイズ 512 バイトのページのコレクションとして編成されます。 ページ BLOB は、ランダムな読み取りおよび書き込み操作をサポートするように最適化されています。必要に応じて、1 ページのデータをフェッチしたり格納したりできます。 ページ BLOB では最大 8 TB のデータを保持できます。 Azure では、仮想マシン用の仮想ディスク ストレージを実装するために、ページ BLOB が使用されてします。 - 追加 BLOB
追加操作をサポートするために最適化されたブロック BLOB です。 追加 BLOB の末尾にのみブロックを追加できます。既存のブロックの更新または削除はサポートされていません。 各ブロックのサイズは可変で、最大値は 4 MB です。 追加 BLOB の最大サイズは、195 GB 強です。
Blob Storage には 4 つのアクセス層が用意されており、アクセスの待機時間とストレージ コストのバランスを取ることができます。
-
ホット層
既定値であり、頻繁にアクセスされる BLOB に使用します。 BLOB データは、高パフォーマンスのメディアに格納されます。 -
クール層
パフォーマンスが低く、ホット層と比較してストレージ料金が安くなります。 アクセス頻度の低いデータにはクール層を使用します。 -
コールド ストレージ層
アクセス頻度が低く、90 日間以上保管されるデータの格納に適しています。 -
アーカイブ層
ストレージ コストは最も安くなりますが、待機時間は長くなります。 アーカイブ層は、失われてはならないけれども、必要になることはあまりない、履歴データ用に意図されています。アーカイブ層の BLOB は、実質的にオフライン状態で格納されます。 ホット層とクール層の一般的な読み取り待機時間は数ミリ秒ですが、アーカイブ層では、データが使用可能になるまでに数時間かかることがあります。
Azure DataLake Storage Gen2 は分析データ レイク用の階層データを格納するためサービスであり、"ビッグデータ" 分析ソリューションによって使用されます。
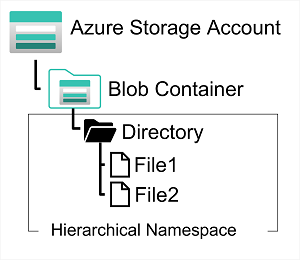
Hadoop in Azure HDInsight、Azure Databricks、Azure Synapse Analytics などのシステムでは、Azure Data Lake Store Gen2 でホストされた分散ファイル システムをマウントし、それを使って膨大な量のデータを処理することができます。
Azure Data Lake Store Gen2 ファイル システムを作成するには、Azure Storage アカウントにある "階層型名前空間" のオプションを有効にする必要があります。
18. Azure File Storage について説明する
Azure Files は、オンプレミスの組織でよく見られるドキュメントや他のファイルを複数のユーザーが使用できるようにするためのクラウドベースのネットワーク共有を作成する方法です。組織はハードウェアのコストとメンテナンスのオーバーヘッドをなくし、ファイルの高可用性とスケーラブルなクラウド ストレージの恩恵を受けることができます。
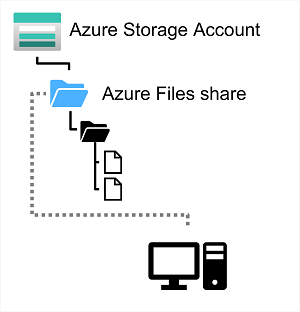
Azure File Storage はストレージ アカウント内に作成します。 Azure Files を使用すると、1 つのストレージ アカウントで最大 100 TB のデータを共有できます。 1 つのファイルの最大サイズは 1 TB ですが、各共有のサイズをこの値以下に制限するようにクォータを設定できます。 現在、Azure File Storage では共有ファイルあたり最大 2000 のコンカレント接続がサポートされています。
Azure File Storage には、2 つのパフォーマンス レベルがあります。 Standard レベルではハード ディスク ベースのハードウェアがデータセンターで使用され、Premium レベルではソリッド ステート ディスクが使用されます。
Azure Files は以下のネットワーク ファイル共有プロトコルがサポートされています。
- サーバー メッセージ ブロック (SMB) ファイル共有
複数のオペレーティング システム (Windows、Linux、macOS) で一般的に使用されます。 - ネットワーク ファイル システム (NFS) 共有
一部の Linux および macOS バージョンで使用されます。 NFS 共有を作成するには、Premium レベルのストレージ アカウントを使用し、共有へのアクセスを制御できる仮想ネットワークを作成して構成する必要があります。
19. Azure Table Storage について説明する
Azure Table Storage は、"キーと値" データ項目を含むテーブルを使用する NoSQL ストレージ ソリューションです。
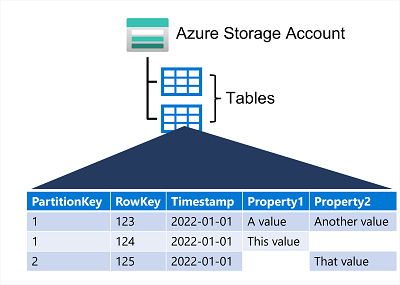
Azure Table を使用すると、半構造化データを格納できます。 テーブル内のすべての行には、一意のキー (パーティション キーと行キーで構成される) が必要です。また、テーブル内のデータを変更すると、"タイムスタンプ" 列に、変更が行われた日時が記録されます。
高速にアクセスできるように、Azure Table Storage ではテーブルがパーティションに分割されています。 パーティション分割は、共通のプロパティつまり "パーティション キー" に基づいて、関連する行をグループ化するためのメカニズムです。 同じパーティション キーを共有する行は、一緒に格納されます。 パーティション分割は、データの整理に役立つだけでなく、次のようにスケーラビリティとパフォーマンスを向上させることもできます。
3-3-2 Azure Cosmos DB の機能について説明する
20. Azure Cosmos DB のユース ケースを特定する
-
Azure Cosmos DB
Azure Cosmos DB は、複数の API (アプリケーション プログラミング インターフェイス) がサポートされます。API があることで開発者はさまざまな種類の一般的データ ストアのプログラミング セマンティクスを使用し、Cosmos DB データベースのデータを操作できます。 内部データ構造は抽象化され、開発者は Cosmos DB を使用し、なじみのある API でデータを格納したり、問い合わせたりできます。
インデックスとパーティション分割を使用して読み取りと書き込みを高速にし、大量のデータにスケーリングできます。 複数リージョンの書き込みを有効にし、選択した Azure リージョンを Cosmos DB アカウントに追加できます。それにより、グローバルに分散されたユーザーがそれぞれのローカル レプリカ内のデータを処理できます。 -
ユースケース
- IoT とテレマティクス
これらのシステムでは、通常、頻繁に発生するアクティビティによって大量のデータが取り込まれます。 Cosmos DB では、この情報をすばやく受け取って格納できます。 その後、Azure Machine Learning、Azure HDInsight、Power BI などの分析サービスで、このデータを使用できます。 また、データがデータベースに到着するとトリガーされる Azure Functions を使用して、リアルタイムでデータを処理できます。
- IoT とテレマティクス
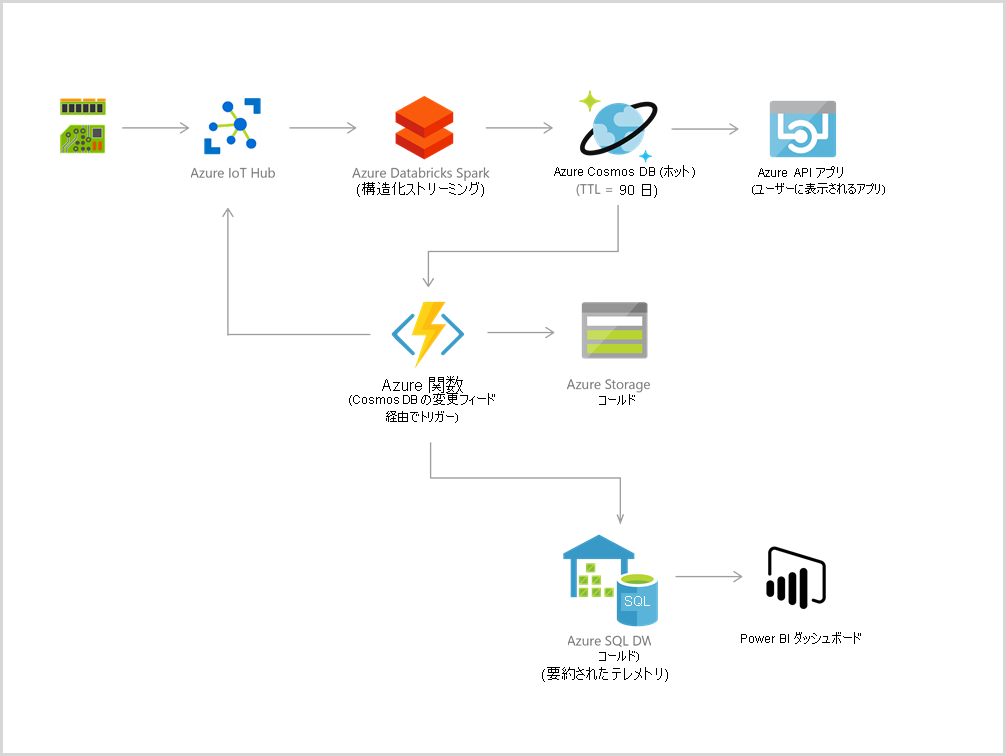
- 小売とマーケティング
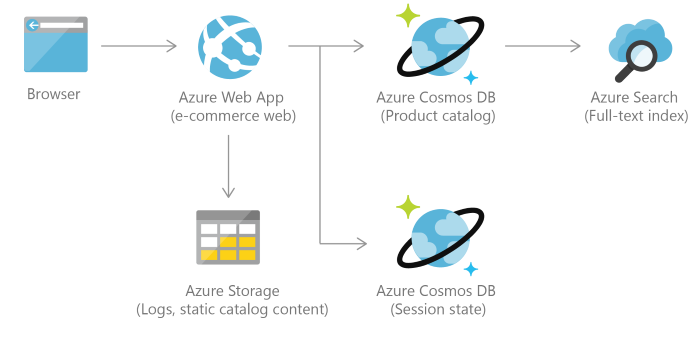
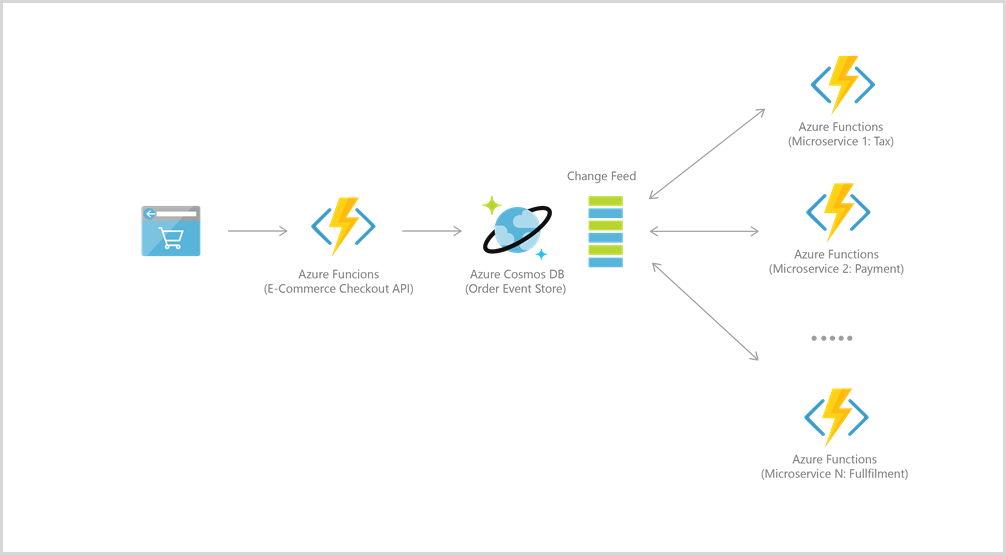
Microsoft では、Windows Store および Xbox Live の一部として実行される独自の eコマース プラットフォームに CosmosDB が使用されています。 また、カタログ データの格納用と、注文処理パイプラインでのイベント ソーシング用に、小売業界でも使用されています。
- ゲーム
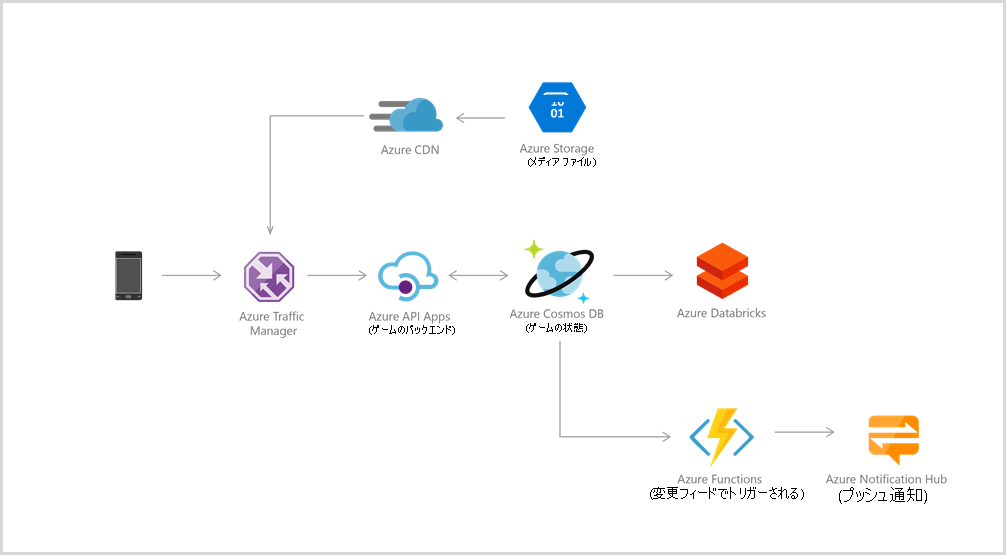
データベース層は、ゲーム アプリケーションの重要なコンポーネントです。 最近のゲームはモバイル/コンソール クライアントでグラフィック処理を行いますが、ゲーム内統計、ソーシャル メディア統合、スコアボードなどの個人向けにカスタマイズされたコンテンツの配信は、クラウドに依存しています。 多くの場合、ゲームでは、魅力的なゲーム内エクスペリエンスを提供するために、読み取りと書き込みに対して 1 桁ミリ秒の待機時間が要求されます。 ゲーム データベースは高速であることが必要であり、新しいゲームのリリース時や機能の更新時に、要求レートの急増に対処できる必要があります。
- Web アプリケーションとモバイル アプリケーション
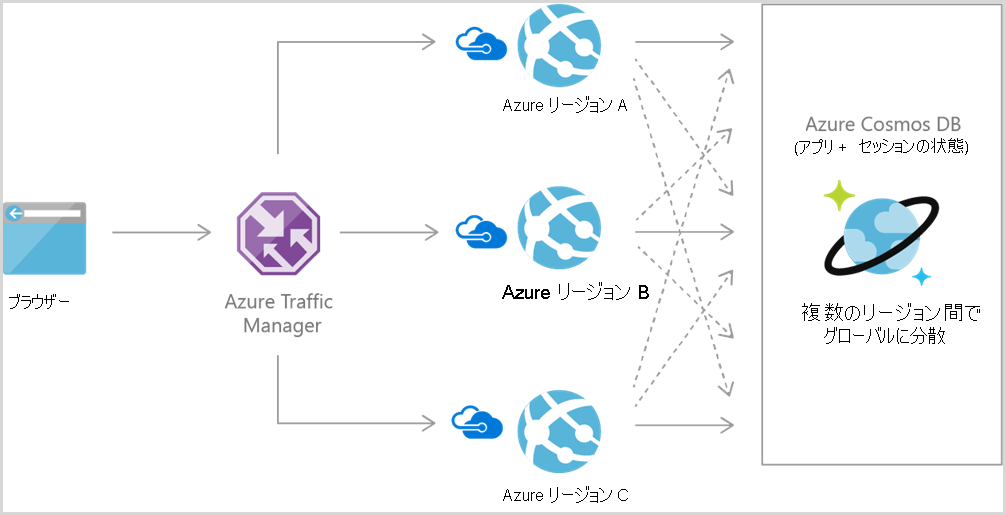
Azure Cosmos DB は一般に Web およびモバイル アプリケーション内で使用され、ソーシャル インタラクションのモデル化、サード パーティ サービスとの統合、および豊富な個人別のエクスペリエンスの構築に適しています。 Cosmos DB SDK を使用すると、一般的な Xamarin フレームワークを使用して、iOS および Android のリッチなアプリケーションを構築できます。
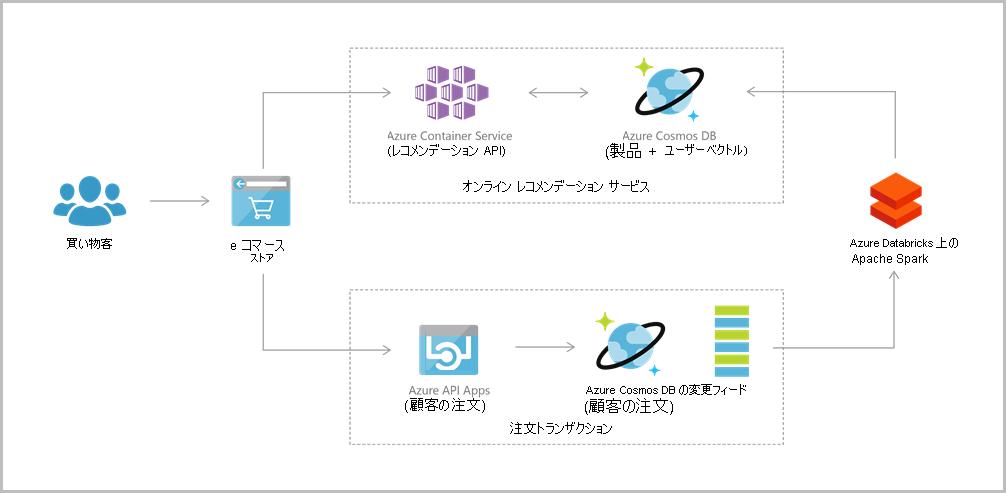
21. Azure Cosmos DB の API について説明する
Azure Cosmos DB は、リレーショナルと非リレーショナル両方のワークロードをサポートします。
開発者は、PostgreSQL、MongoDB、Apache Cassandra など、好みのオープンソース データベース エンジンを使って、アプリケーションの構築と移行を迅速に行うことができます。 新しい Cosmos DB インスタンスをプロビジョニングするときに、使用するデータベース エンジンを選びます。
- Azure Cosmos DB for NoSQL
ドキュメント データ モデルを使用するための Microsoft のネイティブな非リレーショナル サービスです。 それは、JSON ドキュメント形式でデータを管理し、NoSQL データ ストレージ ソリューションであるにもかかわらず、SQL 構文を使ってデータを操作します。
顧客データを含む Azure Cosmos DB データベースに対する SQL クエリは、次のようになります。
SELECT *
FROM customers c
WHERE c.id = "joe@litware.com"
次に示すように、このクエリの結果は、1 つ以上の JSON ドキュメントで構成されます。
{
"id": "joe@litware.com",
"name": "Joe Jones",
"address": {
"street": "1 Main St.",
"city": "Seattle"
}
}
- Azure Cosmos DB for MongoDB
MongoDB は、データがバイナリ JSON (BSON) 形式で格納される一般的なオープン ソース データベースです。
MongoDB クエリ言語 (MQL) では、開発者が "オブジェクト" を使用して "メソッド" を呼び出す、オブジェクト指向のコンパクトな構文が使用されます。 たとえば、次のクエリでは、find メソッドを使用して、db オブジェクト内の products コレクションに対してクエリを実行します。
db.products.find({id: 123})
このクエリの結果は、次のような JSON ドキュメントで構成されます。
{
"id": 123,
"name": "Hammer",
"price": 2.99
}
- Azure Cosmos DB for PostgreSQL
PostgreSQL のネイティブなグローバル分散リレーショナル データベースであり、高度にスケーラブルなアプリを構築できるようデータを自動的にシャード化します。
たとえば、次のような製品のテーブルを定義できます。
| ProductID | ProductName | Price |
|---|---|---|
| 123 | Hammer | 2.99 |
| 162 | Screwdriver | 3.49 |
その後、次のような SQL を使ってこのテーブルのクエリを実行し、特定の製品の名前と価格を取得できます。
SELECT ProductName, Price
FROM Products
WHERE ProductID = 123;
このクエリの結果には、次のような製品 123 の行が含まれます。
| ProductName | Price |
|---|---|
| Hammer | 2.99 |
- Azure Cosmos DB for Table
Azure Table Storage と同様に、キー値テーブル内のデータを操作するために使われます。たとえば、次のように Customers という名前のテーブルを定義できます。
| PartitionKey | RowKey | Name | |
|---|---|---|---|
| 1 | 123 | Joe Jones | joe@litware.com |
| 1 | 124 | Samir Nadoy | samir@northwind.com |
その後、言語固有の SDK の 1 つで Table API を使って、サービス エンドポイントを呼び出し、テーブルからデータを取得できます。 たとえば、次の要求は、上のテーブルの Samir Nadoy のレコードを含む行を返します。
https://endpoint/Customers(PartitionKey='1',RowKey='124')
- Azure Cosmos DB for Apache Cassandra
列ファミリ ストレージ構造を使用する一般的なオープンソース データベースである Apache Cassandra と互換性があります。 列ファミリは、リレーショナル データベースのテーブルに似たテーブルです。ただし、すべての行に同じ列が含まれる必要はありません。
たとえば、次のような Employees テーブルを作成できます。
| id | Name | Manager |
|---|---|---|
| 1 | Sue Smith | |
| 2 | Ben Chan | Sue Smith |
Cassandra では、SQL に基づく構文がサポートされています。そのため、クライアント アプリケーションでは、次のように Ben Chan のレコードを取得できます。
SELECT * FROM Employees WHERE ID = 2
- Azure Cosmos DB for Apache Gremlin
グラフ構造のデータで使われます。この構造のエンティティは、接続されたグラフ内のノードを形成する頂点として定義されます。 次のように、ノードは、リレーションシップを表す "エッジ" によって接続されます。
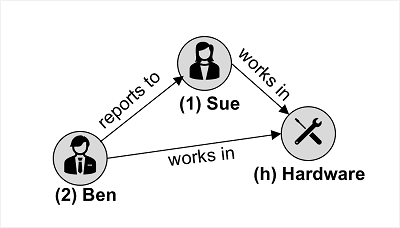
図の例は、2 種類の頂点 (従業員と部署) と、それらを接続するエッジ (従業員 "Ben" が従業員 "Sue" に報告を行い、両方の従業員が "ハードウェア" 部門で働く) を示しています。
Gremlin 構文には、頂点とエッジで動作する関数が含まれており、グラフでのデータの挿入、更新、削除、クエリを実行できます。 たとえば、次のコードを使用して、ID 1 の従業員 (Sue) に報告を行う Alice という名前の新しい従業員を追加できます。
g.addV('employee').property('id', '3').property('firstName', 'Alice')
g.V('3').addE('reports to').to(g.V('1'))
次のクエリは、ID 順にすべての "従業員" の頂点を返します。
g.V().hasLabel('employee').order().by('id')
3-4 Azure 上での分析ワークロードについて説明する
3-4-1 大規模な分析の一般的な要素について説明する
22. データ インジェストと処理に関する考慮事項について説明する
1 つ以上のトランザクション対応のデータ ストア、ファイル、リアルタイム ストリーム、その他のソースからのデータが、分析データストアであるデータ レイクまたはリレーショナル データ ウェアハウスに読み込まれます。
読み込み操作には、通常、"抽出、変換、読み込み" (ETL) または "抽出、読み込み、変換" (ELT) のプロセスが含まれ、それによってデータは分析用にクリーンアップ、フィルター処理、再構築され、結果のデータ構造は分析クエリ用に最適化されます。
データ処理は、多くの場合、マルチノード クラスターを使用して大量のデータを並列処理できる分散システムによって実行されます。
データ インジェストには、静的データのバッチ処理と、ストリーミング データのリアルタイム処理の両方が含まれます。
23. 分析データ ストアのオプションについて説明する
分析データ ストアには、2 つの一般的な種類があります。
-
データ ウェアハウス
データ ウェアハウス は、トランザクション ワークロードではなくデータ分析用に最適化されたスキーマにデータが格納されるリレーショナル データベースです。
一般に、トランザクション ストアのデータは、中心になる "ファクト" テーブルに数値が格納されたスキーマに変換されます。それらのテーブルは、データ集計の基準となるエンティティを表す 1 つ以上の "ディメンション" テーブルに関連付けられます。
この種のファクトおよびディメンション テーブル スキーマは、"スター スキーマ" と呼ばれますが、ディメンション テーブルに関連した他のテーブルを追加してディメンション階層を表すことで、"スノーフレーク スキーマ" に拡張されることがよくあります -
データ レイクハウス
データ レイク はファイル ストアであり、通常は分散ファイル システム上でハイ パフォーマンスのデータ アクセスを実現します。 格納されているファイルに対するクエリを処理し、レポートと分析用のデータを返すために、Spark や Hadoop などのテクノロジがよく使用されます。
データ レイクは、ストアへのデータ書き込み時にスキーマを適用する必要なく分析対象の構造化データ、半構造化データ、非構造化データの組み合わせをサポートするために最適です。
データ レイクとデータ ウェアハウスの機能を組み合わせて "レイク データベース" または "データ レイクハウス" に取り入れたハイブリッド アプローチを使用できます。
データ レイクに生データがファイルとして格納され、基になるファイルがリレーショナル ストレージ レイヤーで抽象化されて、テーブルとして公開されます。それに対して SQL を使用してクエリを実行できます。
24. Azure Synapse Analytics、Azure Databricks、Azure HDInsight、Azure Data Factory など、データ ウェアハウス用の Azure サービスについて説明する
-
Azure Synapse Analytics
Synapse Analytics は、Azure で単一の統合された分析ソリューションを作成する場合に最適な選択肢です。- スケーラブルなハイ パフォーマンスの SQL Server ベース リレーショナル データ ウェアハウスに備わるデータの整合性と信頼性に、データ レイクとオープンソース Apache Spark の柔軟性を組み合わせることができます。
- Azure Synapse Data Explorer プールを使用したログおよびテレメトリ分析のネイティブ サポートと、データ インジェストと変換のための組み込みデータ パイプラインも含まれています。
-
Azure Databricks
Databricks プラットフォームを利用できる Azure サービスです。Databricks は Apache Spark 上に構築された包括的なデータ分析ソリューションであり、ネイティブの SQL 機能のほか、データ分析とデータ サイエンスのためのワークロード用に最適化された Spark クラスターを提供します。 -
Azure HDInsight
オープンソース データ分析クラスターの種類を複数サポートする Azure サービスです。 Azure Synapse Analytics や Azure Databricks ほどユーザー フレンドリではありませんが、分析ソリューションが複数のオープンソース フレームワークに依存している場合、または既存のオンプレミス Hadoop ベース ソリューションをクラウドに移行する必要がある場合には、適したオプションになります。
3-4-2 リアルタイム データ分析に関する考慮事項について説明する
25. バッチ データとストリーミング データの違いの説明
データを処理するには、2 つの一般的な方法があります。
-
バッチ処理
複数のデータ レコードが収集されて格納された後、1 回の操作でまとめて処理されます。 -
ストリーム処理
データのソースが常に監視されており、新しいデータ イベントが発生するとリアルタイムで処理されます。 -
バッチ データとストリーミング データの違い
バッチ処理とストリーミング処理には、データを処理する方法以外にも違いがあります。-
データ スコープ
バッチ処理では、データセット内のすべてのデータを処理できます。 ストリーム処理では、通常、受信した最新のデータ、またはローリング期間内 (最後の 30 秒など) にのみアクセスできます。 -
データ サイズ
バッチ処理は、大規模なデータセットを効率的に処理する場合に適しています。 ストリーム処理は、個々のレコードまたは少数のレコードで構成される "マイクロバッチ" を対象としています。 -
パフォーマンス
待機時間は、データの受信と処理にかかった時間です。 通常、バッチ処理の待機時間は数時間です。 通常、ストリーム処理は直ちに実行され、待機時間は数秒または数ミリ秒です。 -
分析
通常、複雑な分析を実行する場合はバッチ処理を使用します。 ストリーム処理は、単純な応答関数、集計、またはローリング平均などの計算に使用されます。
-
26. Azure Stream Analytics、Azure Synapse Data Explorer、Spark 構造化ストリームなどのリアルタイム分析用のテクノロジについて説明する
-
Azure Stream Analytics
ストリーミング データの複合イベント処理と分析のためのサービスです。- Azure Event Hub、Azure IoT Hub、Azure Storage Blob コンテナーなどの "入力" からデータを取り込みます。
- "クエリ" を使用してデータ値の選択、プロジェクション、集計を行うことでデータを処理します。
- Azure Data Lake Gen 2、Azure SQL Database、Azure Synapse Analytics、Azure Functions、Azure イベント ハブ、Microsoft Power BI などの "出力" に結果を書き込みます。
-
Azure Synapse Data Explorer
ログとテレメトリ データから分析情報を引き出すための対話型クエリ エクスペリエンスをお客様に提供します。 既存の SQL および Apache Spark 分析ランタイム エンジンを補完するために、Data Explorer の分析ランタイムは、効率的なログ分析用に最適化されています。 -
Spark Structured Streaming
Spark を使うと、複数のクラスター ノードで並列にコード (通常は、Python、Scala、または Java で書かれたもの) を実行し、非常に大量のデータを効率よく処理できます。 Spark は、バッチ処理とストリーム処理の両方に使用できます。
Spark でストリーミング データを処理するには、Spark Structured Streaming ライブラリを使用できます。このライブラリでは、データの連続的なストリームを取り込み、処理して、結果を出力するためのアプリケーション プログラミング インターフェイス (API) が提供されています。
ストリーミング データを Spark ベースのデータ レイクや分析データ ストア内に組み込む必要がある場合には、Spark Structured Streaming がリアルタイム分析のための最適な選択肢となります。
3-4-3 Microsoft Power BI でのデータの視覚化について説明する
27. Power BI の機能を特定する
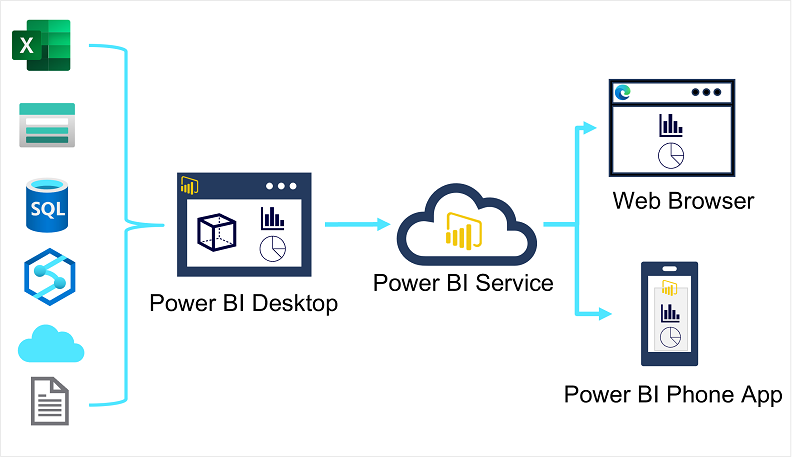
-
Power BI Desktop
データ視覚化ソリューションを作成するサービス。様々なソース データを分析データ モデルで組み合わせて整理したり、対話型の視覚化データを含むレポートを作成できます。
レポートを作成後、Power BI Serviceにパブリッシュします。 -
Power BI Service
Power BI Service はクラウド サービスです。 Web ブラウザーを使用して、このサービスでデータの基本的なモデリングとレポート編集を直接行うこともできますが、これの機能は Power BI Desktop ツールと比較して制限があります。 このサービスを使用して、レポートがあるデータ ソースの更新をスケジュールしたり、レポートを他のユーザーと共有することができます。 関連するレポートを 1 つの使いやすい場所にまとめるダッシュボードとアプリを定義することもできます。 -
Power BI Mobile
Power BI Serviceの成果物をモバイルアプリから使用できます。
28. Power BI でのデータ モデルの機能について説明する
分析モデルを使用すると、分析をサポートするためにデータを構造化できます。 モデルは、関連するデータ テーブルに基づいており、分析またはレポートの対象である数値 ("メジャー" と呼ばれる) と、それらを集計するエンティティ ("ディメンション" と呼ばれる) を定義します。概念的には、モデルは多次元構造を形成します。これは一般に "キューブ" と呼ばれます。この構造では、ディメンションが交差するポイントは、それらのディメンションの集計メジャーを表します。
-
テーブルとスキーマ
"ディメンション" テーブルは、数値メジャーを集計するエンティティ (製品や顧客など) を表します。
モデルのさまざまなディメンションによって集計される数値メジャーは、"ファクト" テーブルに格納されます。
たとえば、Sales テーブルは、個々の商品の売上トランザクションを表し、販売数量と収益の数値を含めます。 -
属性階層
分析モデルについて最後に考慮すべき事項は、階層ディメンション内の異なるレベルで集計された値をすばやく "ドリルアップ" または "ドリルダウン" できる属性 "階層" の作成です。 Product テーブルでは、各カテゴリに複数の名前付き製品が含まれる階層を形成できます。Customer テーブルでは、各都市の複数の名前付き顧客を表す階層を形成できます。最後に、Time テーブルで、年、月、日の階層を形成できます。 モデルは、階層の各レベルに対して事前に集計された値を使用して構築できます。たとえば、年別の売上合計を表示し、ドリルダウンして月別の売上合計の詳細な内訳を表示することで、分析の範囲をすばやく変更できます。 -
Microsoft Power BI での分析モデリング
Power BIはファクトおよびディメンション テーブル間のリレーションシップの作成、階層の定義、テーブル内のフィールドのデータ型と表示形式の設定、その他のデータ プロパティの管理などにより、分析用に充実したモデルを定義できるようになります。
29. データに適した視覚化を特定する
一般的なデータの視覚化について説明しますが、完全な一覧を示すわけではありません。
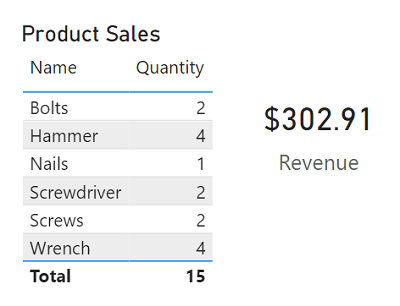
- テーブルとテキスト
テーブルは、関連する多くの値を表示する必要がある場合に便利な方法で、カード内の個々のテキスト値は重要な数値やメトリックを示すのに便利です。
- 横棒グラフおよび縦棒グラフ
横棒グラフおよび縦棒グラフは、個別のカテゴリの数値を視覚的に比較するのに適した方法です。
- 折れ線グラフ
折れ線グラフも、分類された値を比較するために使用でき、傾向 (多くの場合、時系列に沿ったもの) を調べる必要がある場合に便利です。
- 円グラフ
円グラフは、分類された値を全体に占める比率として視覚的に比較するために、ビジネス レポートでよく使用されます。
- 散布図
散布図は、2 つの数値的な大きさを比較し、それらの間の関係あるいは相関関係を特定する場合に便利です。
- Maps
マップは、異なる地域や場所の値を視覚的に比較するための優れた方法です。
4. 終わりに
本記事を最後まで読んで頂きましてありがとうございます。
リレーショナルデータベース以外にもたくさんのデータベースがあります。普段触れないサービスではありますが、知識のアップデートは必要ですね。
最後の総復習はMicrosoft 認定資格のプラクティス評価にかぎります。