Androidで使えるGoogleのLLMのソリューションが何個あると思いますか?
調べてみると実は5つもあるようです。どう違って、どう選んでいったらいいでしょうか?
- Gemini Nano with the Google AI Edge SDK
- MediaPipe Tasks Inference API
- LiteRT
- Vertex AI in Firebase
- Google AI client SDK
それぞれのライブラリの使い方は大体同じ
ここでは2つ目のMediaPipe Tasksを例としてあげてみます。
基本的にはプロンプトといくつかのパラメーター(例えばTemperature)を渡して、結果が返ってくるという感じです。
val options = LlmInferenceOptions.builder()
.setModelPATH("/data/local/.../")
.setMaxTokens(1000)
.setTopK(40)
.setTemperature(0.8)
.setRandomSeed(101)
.build()
llmInference = LlmInference.createFromOptions(context, options)
val inputPrompt = "Compose an email to remind Brett of lunch plans at noon on Saturday."
val result = llmInference.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
LLMを使うときに利用するパラメーターのうち、 Temperature , TopK , TopP は、前回以下で紹介しました。
LLMを使いこなすためにLLMで指定する Temperature , TopK , TopP を理解する
で、どう違うのか?
同じようなコードで同じようなパラメーターが使えるなら、これらのライブラリは何が違うのでしょうか?
これらのAIは On Device AI と Cloud AI の大きく2つに分けることができます。On Device AI はAndroid端末などデバイス上で実行されるAIで、Cloud AI はサーバー上で実行されます。
| 説明 | ライブラリ | |
|---|---|---|
| On Device AI |
Android端末などデバイス上で実行される | * Gemini Nano with the Google AI Edge SDK * MediaPipe Tasks Inference API * LiteRT |
| Cloud AI |
サーバー上で実行される | * Vertex AI in Firebase * Google AI Client SDK |
On Device AI と Cloud AI どっちがいいの?
On Device AIのメリットは、デバイス上で実行するため、サーバーにデータを送信しないためプライバシーに配慮できたり、即時に実行されて速い、オフライン、API利用料など追加コストが発生しない。ということがあります。
では全部On Device AIでいいのでは?となると思うのですが、クラウドベースのほうが大きい計算リソースを使えてより高性能なモデルが使えるメリットがあったり、On Device AIは現状は対応している機能が少なかったり、使える端末が少なかったり、まだ発展途上であるというデメリットがあります。
| 説明 | メリット | |
|---|---|---|
| On Device AI |
Android端末などデバイス上で実行される | サーバーにデータを送信しないためプライバシーに配慮できる 即時に実行されて速くなりえる オフラインで動く API利用料など追加コストが発生しない |
| Cloud AI |
サーバー上で実行される | 大きい計算リソースを使えてより高性能なモデルが使える 対応している機能が多い あらゆる端末で使える 比較的成熟している |
On Device AI と Could AIの違いは分かったけど、それぞれのライブラリでどう違うの?
まずは一個ずつ特徴を見ていきましょう。
Gemini Nano with the Google AI Edge SDK
https://developer.android.com/ai/gemini-nano/experimental
2024/11/10時点
全体ステータス
On Device か Cloud か: On Device
ライブラリのステータス: experimental。使うユーザーがexperimental accessの明示的な合意が必要。
使えるモデル: Gemini Nano
使えるモーダリティ: Text to Text(Gemini Nano 2自体はマルチモーダルをサポートしているのでもう少しかも。)
その他の機能: AndroidのOSに統合されていることにより、モデルの管理によるダウンロードやモデルの管理を気にしなくて良い。
使える端末: Pixel9。Webサイトにはいろんな端末で使えると書いてあるが、GitHubにはPixel 9の実機が必要と書いてあり、使えない報告あり。
まだExperimental(実験的)なものとなります。また利用するのにユーザーの合意が必要になるので、まだ実用するのは難しいです。
Gemini Nano with the Google AI Edge SDK の特徴は、On Device AI であることの他に、その仕組みがOSに載っているというところにあります。Googleなので、Android OSとしてAIのサポート(AICore)を入れており、そこで動作させることになります。そして、そのAICoreにアクセスできるライブラリが、Google AI Edge SDK になります。つまり、モデルのダウンロードや管理をOSに任せられます。という話ではあるのですが、今のところダウンロードするコードなどを呼び出してから使う必要があります。
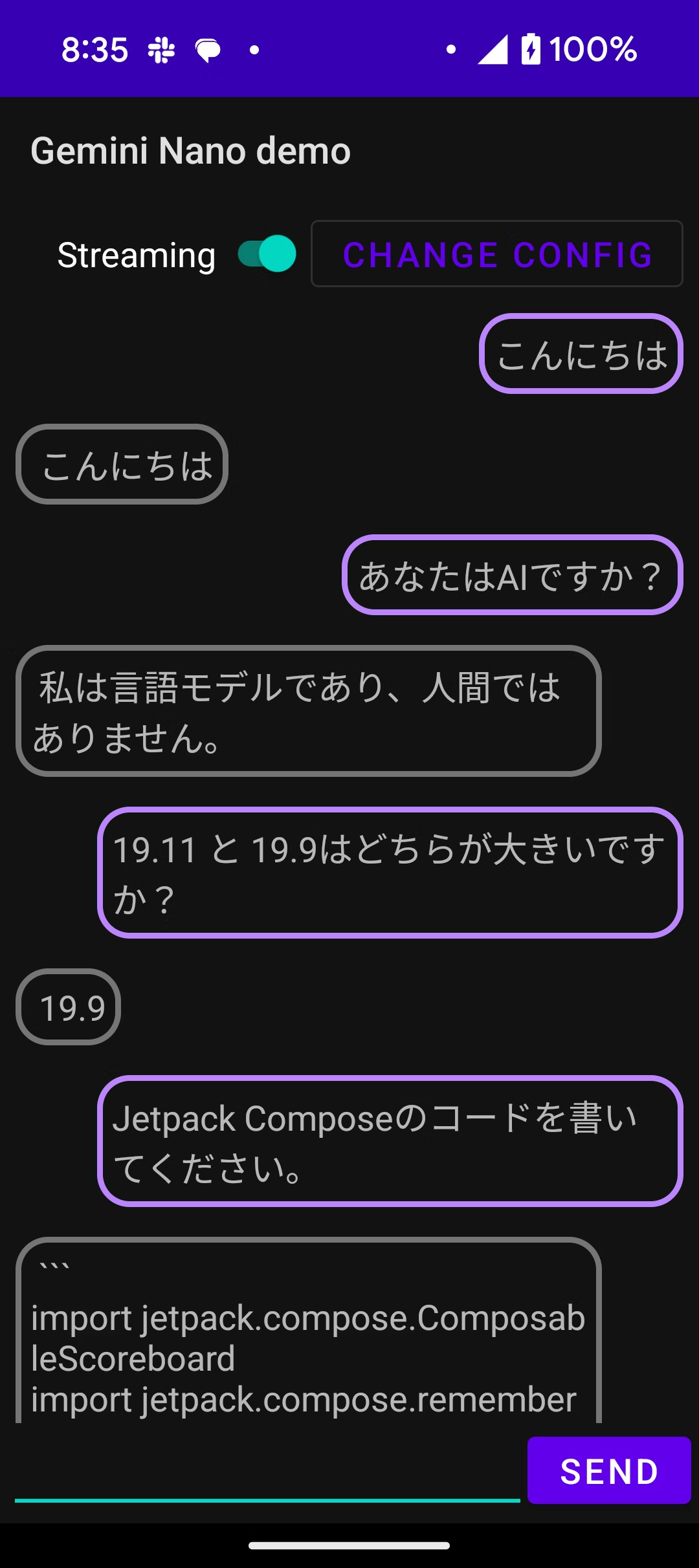
Gemini Nano with the Google AI Edge SDK
val generationConfig = generationConfig {
context = ApplicationProvider.getApplicationContext() // required
temperature = 0.2f
topK = 16
maxOutputTokens = 256
}
scope.launch {
// Single string input prompt
val input = "I want you to act as an English proofreader. I will provide you
texts, and I would like you to review them for any spelling, grammar, or
punctuation errors. Once you have finished reviewing the text, provide me
with any necessary corrections or suggestions for improving the text: These
arent the droids your looking for."
val response = generativeModel.generateContent(input)
print(response.t ext)
}
developer.android.com/ai/gemini-nano/experimental
MediaPipe Tasks Inference API
https://ai.google.dev/edge/mediapipe/solutions/genai/llm_inference
2024/11/10時点
On Device か Cloud か: On Device
ステータス: experimental and under active development
使えるモデル: オープンモデル(Gemma, Llamaなど)
使えるモーダリティ: Text to Text, Text to Image (他にも顔認識などがある。)
その他の機能: オープンモデルが選択可能。LoRA support。
使える端末: minSdkVersion 24(Android 7.0以上)、8 GB 以上の RAM を搭載したデバイスでテストすることもおすすめします。という文言が、codelabに存在する。
こちらもExperimental(実験的)なものとなりますが、MediaPipe Tasksは物体検出や顔のランドマーク検出など、一般的なユースケースに対応した事前トレーニング済みのモデルを提供しています。そのMediaPipe TasksにInference APIとしてLLMも利用できる機能が追加されました。オープンモデルを指定して利用します。Gemini Nanoは利用することができないです。現状のGemini Nanoと比べると、端末の制限が明示的には設定されていないため、さまざまな端末で動かしてみることができそうです。
MediaPipe Tasks
val options = LlmInferenceOptions.builder()
.setModelPATH("/data/local/.../")
.setMaxTokens(1000)
.setTopK(40)
.setTemperature(0.8)
.setRandomSeed(101)
.build()
llmInference = LlmInference.createFromOptions(context, options)
val inputPrompt = "Compose an email to remind Brett of lunch plans at noon on Saturday."
val result = llmInference.generateResponse(inputPrompt)
logger.atInfo().log("result: $result")
ai.google.dev/edge/mediapipe/solutions/genai/llm_inference/android
LiteRT (元TensorFlow Lite)
https://ai.google.dev/edge/litert?hl=ja
2024/11/10時点
On Device か Cloud か: On Device
ステータス: LLMに関するステータスが見つからず。
使えるモデル: オープンモデル(Gemma, Llamaなど)
使えるモーダリティ: Text to Textなど (他にも顔認識などがある。)
その他の機能: オープンモデルが選択可能。
使える端末: 不明
LiteRTは元々TensorFlow Liteという名前で、最近名前が変わりました。機械学習をモバイル端末上で行うライブラリです。現状はLLMとして使えそうなAPIはあるものの、GemmaやLlamaなどのモダンなLLMを、TensorFlow LiteやLiteRTと使っている例は探してみましたが見つからなかったです。そのため、今回は大きく取り上げない形にしようと思っています。最近名前が変わったりして変更を入れていこうとしているように見えるため、これから変わっていく可能性はあると思っています。
おそらくInferenceのAPIはあるのでモデルを変換して読み込ませれば使えそうということはわかっており、このGoogle colabを実行すればいいのですが、動かしてみたのですが動かず。調べたところ100GB以上のメモリが必要そうというところで断念しました。
Google AI client SDK
https://developer.android.com/ai/google-ai-client-sdk
2024/11/10時点
On Device か Cloud か: Cloud
ステータス: APIキーを載せる必要があって使われてしまうため。プロトタイプのみThe Google AI SDK for Android is recommended for prototyping only。
使えるモデル: Geminiモデル
使えるモーダリティ: Text to Text, Image & Text to Text
その他の機能: Json schema、Function Callingなど
使える端末: ほぼ何でも利用可。(minSdk = 21)
GeminiのAPIをSDKとしてラップしたものです。大きな問題点としてアプリ上でGeminiのAPIキーが必要になるということです。そうなるとAPIキーの盗難のリスクが有るため、かなり使うのが難しくなってしまいます。そのためプロトタイプとしてのみ利用できるという形になります。
val model = GenerativeModel(
model = "gemini-1.5-flash-001",
apiKey = BuildConfig.apikey,
generationConfig = generationConfig {
temperature = 0.15f
topK = 32
topP = 1f
maxOutputTokens = 4096
},
safetySettings = listOf(
...
)
)
scope.launch {
val response = model.generateContent("Write a story about a green robot.")
}
Vertex AI in Firebase
https://firebase.google.com/docs/vertex-ai?hl=ja
2024/11/10時点
On Device か Cloud か: Cloud
ステータス: Generally Available(利用可能)
使えるモデル: Geminiモデル
使えるモーダリティ: Text to Text, Image & Text to Text (これまでで最もいろんなものが使える)
その他の機能: Json schema、Function Callingなど
使える端末: ほぼ何でも利用可。Firebase App Checkといっしょに使うことが推奨されている。
Vertex AIというのはGoogle Could Platformで使えるAIのサービスの名前で、それをFirebaseから使えるよということです。FirebaseでGeminiなどが呼び出せるという認識で問題ないと思います。こちらはGoogle AI client SDKと違って、直接GeminiのAPIキーなどを持つ形ではないため、比較的セキュリティリスクが低いです。セキュリティの面からFirebase App Checkと一緒に使うことが推奨されています。
Vertex AI in Firebase
val generativeModel = Firebase.vertexAI.generativeModel(
modelName = "gemini-1.5-flash-preview-0514",
generationConfig = generationConfig {
temperature = 0.7f
topK = 40
}
)
val prompt = "Write a story about a magic backpack."
val response = generativeModel.generateContent(prompt)
print(response.text)
比較表(2024/11/12 時点)
| 項目 | Gemini Nano with Google AI Edge SDK | MediaPipe Tasks Inference API | LiteRT (旧TensorFlow Lite) | Google AI Client SDK | Vertex AI in Firebase |
|---|---|---|---|---|---|
| AIタイプ | オンデバイス |
オンデバイス |
オンデバイス |
クラウド |
クラウド |
| ステータス | Experimental(実験的)、ユーザーの合意が必要。 | Experimental(実験的)、開発中 | 最近名前が変わったが昔からある。LLM対応の事例が少ない。 | プロトタイプのみ利用可能 | Generally Available(利用可能) |
| モデル | Gemini Nano | オープンモデル(Gemma, Llamaなど) | オープンモデル | Geminiモデル | Geminiモデル |
| モーダリティ | Text to Text | Text to Text、Text to Imageなど | Text to Textなど | Text to Text、Image & Text to Text | Text to Text、Image & Text to Text |
| その他の機能 | OS管理でモデルのダウンロード/管理が簡単、ローカルで高速に動き得る | LoRAサポート、モデルパス設定可能、ローカルで高速に動き得る、(顔認識などその他の機械学習機能) | モデルの最適化・変換対応、ローカルで高速に動き得る、(顔認識などその他の機械学習機能) | JSON出力サポート、APIキー必要 | JSON出力サポート |
| 対応デバイス | Pixel 9のみ対応 | minSdkVersion 24(Android 7.0以上)、8GB以上のRAM推奨 | 不明 | ほぼ全デバイス | ほぼ全デバイス |
| プライバシーとセキュリティ | オンデバイス処理によるプライバシー保護 | オンデバイス処理によるプライバシー保護 | オンデバイス処理によるプライバシー保護 | APIキー盗難、悪用リスクあり | Firebase利用でセキュア(Firebase App Checkとの併用が推奨されている) |
| API利用料 | なし | なし | なし | あり | あり |
で、どう選ぶとよいの?
オンデバイスかクラウドか
現時点ではオンデバイスAIは高性能なデバイスに依存しているため、一般ユーザーの幅広い利用には制約があります。そのため、オンデバイスAIは選択肢にはなかなか入らないのかなと思いました。 ただ、プライバシー保護や低遅延といった強みがあるので、オンデバイスは考慮しておきたいです。
そのため将来的にオンデバイスに切り替えできるようにする(例えば以下のように抽象化を入れておく)アプローチがあるかもしれません。
interface AIService {
fun generateResponse(prompt: String): String
}
class CloudAIService : AIService {
override fun generateResponse(prompt: String): String {
// クラウドAPIへのリクエスト処理を実装
// 例: Firebaseを使用してGeminiモデルを呼び出す
}
}
class OnDeviceAIService : AIService {
override fun generateResponse(prompt: String): String {
// オンデバイスモデルへの処理を実装
// 例: Google AI Edge SDKを使用してGemini Nanoを呼び出す
}
}
Vertex AI in Firebaseか自社サーバーか
クラウドでは、GoogleのLLMのライブラリでは、ほぼVertex AI in Firebaseが唯一の選択肢となると考えられます。
Firebaseを使わない場合は、自分でサーバーを用意する形になります。 自分でサーバーを用意する場合は自分でGeminiなどのLLMのAPIを呼び出す処理を書いてアプリにjsonなどで返す処理を実装する形になります。自分でサーバーを用意する場合は初期のセットアップと継続的なメンテナンスが必要ですが、自由度が高くOpenAIなどの別のAIを呼び出したりすることも可能になります。 最近はOpenAIのAPIのインターフェースでGeminiのAPIが叩けるようにもなったので、OpenAIのAPIベースでサーバーを作るのも一つの手なのかなと思います。
まとめると?
以下の3つの観点から選ぶことになります。
- クラウドサーバー
自由度が高くOpenAIなどの別のAIを呼び出したり、カスタマイズが可能。 - Firebase
初期のセットアップ、継続的なメンテナンスが少なくて済む。
自動でスケールしてくれる。
そして選んでから、その処理をするときにオンデバイスに置き換えられるようにするというのが現状では良いアプローチになるのかなと思いました。