の続きです。
用語整理
データレイヤーとは?
While the UI layer contains UI-related state and UI logic, the data layer contains application data and business logic. The business logic is what gives value to your app—it's made of real-world business rules that determine how application data must be created, stored, and changed.
アプリケーションデータとビジネスロジックを含む。ビジネスロジックはアプリに価値を与えるもので、ビジネスロジックはアプリケーションのデータがどのように作られ保存され変更されるかを決定するルールから作られる。
This separation of concerns allows the data layer to be used on multiple screens, share information between different parts of the app, and reproduce business logic outside of the UI for unit testing. For more information about the benefits of the data layer, check out the Architecture Overview page.
この分離によって複数の画面やテストなどで共有でき、ロジックをUI外でテストすることを可能にする。
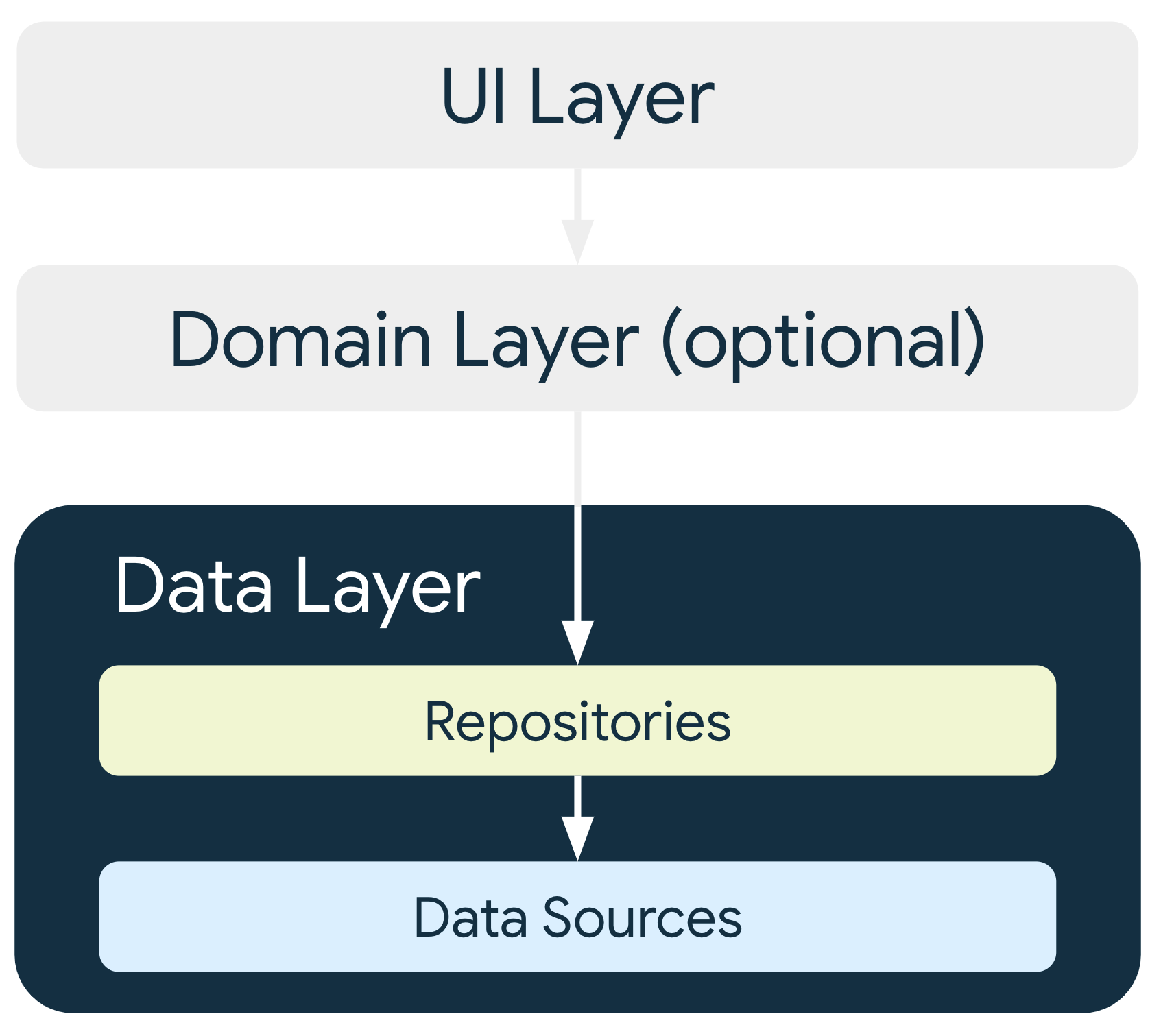
The data layer is made of repositories that each can contain zero to many data sources. You should create a repository class for each different type of data you handle in your app. For example, you might create a MoviesRepository class for data related to movies, or a PaymentsRepository class for data related to payments.
データレイヤーは複数のリポジトリから作られ、リポジトリは0〜複数のデータソースを含む。
https://developer.android.com/jetpack/guide/data-layer?hl=en より
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
Repository classes are responsible for the following tasks:
Exposing data to the rest of the app.
Centralizing changes to the data.
Resolving conflicts between multiple data sources.
Abstracting sources of data from the rest of the app.
Containing business logic.
以下を行う
- アプリの他の部分にデータを提供する
- データの変更をここに集中させる
- 複数のデータソース間の競合を解決する
- アプリの他の部分にデータソースを抽象化する
- ビジネスロジックを含む
Repositoryクラスをアプリで扱うデータの種類ごとに作らなければならない
The data layer is made of repositories that each can contain zero to many data sources. You should create a repository class for each different type of data you handle in your app. For example, you might create a MoviesRepository class for data related to movies, or a PaymentsRepository class for data related to payments.
例えばmovieに関係するものをMoviesRepositoryに、paymentsに関係するものをPaymentsRepositoryに。
なぜ?
そのようにRepositoryを定義しているため。
データソースクラスは一つのデータのソースとのみ動作する責務を持つべき
Each data source class should have the responsibility of working with only one source of data, which can be a file, a network source, or a local database. Data source classes are the bridge between the application and the system for data operations.
ファイルやネットワークやローカルデータベースなどがソースになり得る。データソースはシステムとアプリの架け橋になる。
なぜ?
特に書かれていませんが、単一責任や、関心事の分離のためだと思います。
他のレイヤーのクラスはデータソースに直接アクセスしてはならない。リポジトリーを経由する必要がある。
Other layers in the hierarchy should never access data sources directly; the entry points to the data layer are always the repository classes. State holder classes (see the UI layer guide) or use case classes (see the domain layer guide) should never have a data source as a direct dependency. Using repository classes as entry points allows the different layers of the architecture to scale independently.
なぜ?
アーキテクチャの異なるレイヤーを独立して拡張することができるため。 (多分データソースを変更したときに使っている箇所で影響を受けないようにできるとかそういうことだと思われる)
このレイヤーから排出されるデータはimmutable(変更不可能)でなければならない。
The data exposed by this layer should be immutable so that it cannot be tampered with by other classes, which would risk putting its values in an inconsistent state. Immutable data can also be safely handled by multiple threads. See the threading section for more details.
なぜ?
データを他のクラスで変更することでデータの不整合が起こる可能性があり、変更を防ぐため。またマルチスレッドの問題もあるため。
1データソースしかないときにリポジトリとデータソースを混ぜている場合は、複数データソースが必要になったときにリファクタリングすること
Note: Often, when a repository only contains a single data source and doesn't depend on other repositories, developers merge the responsibilities of repositories and data sources into the repository class. If you do this, don't forget to split functionalities if the repository needs to handle data from another source in a later version of your app.
なぜ?
データソースクラスは一つのデータのソースとのみ動作する責務を持つべきというのがあるため。 (関心事の分離)
一度行うだけの操作(One-shotな操作)にはKotlinのsuspend関数、JavaであれコールバックやRxJavaのSingleやMaybe、Completableを公開する。変更されるデータにはKotlinのFlowやコールバックやRxJavaのObservableやFlowableを公開する
One-shot operations: The data layer should expose suspend functions in Kotlin; and for the Java programming language, the data layer should expose functions that provide a callback to notify the result of the operation, or RxJava Single, Maybe, or Completable types.
To be notified of data changes over time: The data layer should expose flows in Kotlin; and for the Java programming language, the data layer should expose a callback that emits the new data, or the RxJava Observable or Flowable type.
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow<Example> = ...
suspend fun modifyData(example: Example) { ... }
}
なぜ?
特に理由は書いていませんでしたが、おそらく公開するインターフェースを必要最低限にするためそのための仕組みを使おうということだと思います。
RepositoryはRepositoryに依存するものも存在しうる
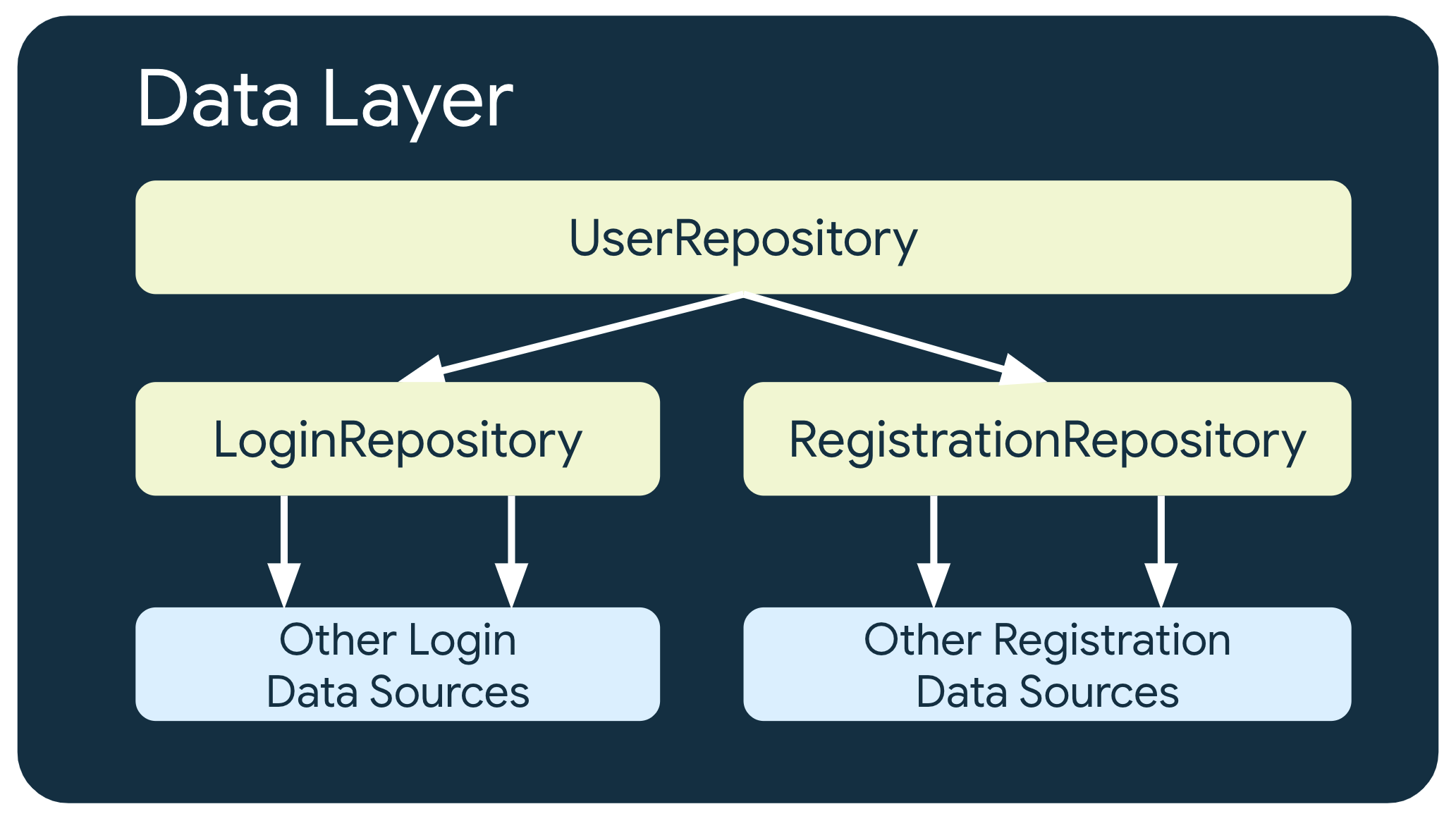
In some cases involving more complex business requirements, a repository might need to depend on other repositories. This could be because the data involved is an aggregation from multiple data sources, or because the responsibility needs to be encapsulated in another repository class.
For example, a repository that handles user authentication data, UserRepository, could depend on other repositories such as LoginRepository and RegistrationRepository to fulfill its requirements.
https://developer.android.com/jetpack/guide/data-layer?hl=en#multiple-levels より
なぜ?
関係するデータが複数のデータソースからできる集合体であったり、責任を別のリポジトリのクラスにカプセル化する必要があったりするため。
Repositoryやデータソースのメソッドはメインセーフ(メインスレッドから呼び出しても安全)であるべき
Calling data sources and repositories should be main-safe—safe to call from the main thread. These classes are responsible for moving the execution of their logic to the appropriate thread when performing long-running blocking operations. For example, it should be main-safe for a data source to read from a file, or for a repository to perform expensive filtering on a big list.
Note that most data sources already provide main-safe APIs like the suspend method calls provided by Room or Retrofit. Your repository can take advantage of these APIs when they are available.
RoomやRetrofitを使っていればすでにメインセーフになっている。
なぜ?
Repositoryやデータソースに適切なスレッドで実行する責務があるため。
データレイヤーのクラスは他のクラスから参照される限りメモリに持ち続ける
Instances of classes in the data layer remain in memory as long as they are reachable from a garbage collection root—usually by being referenced from other objects in your app.
If a class contains in-memory data—for example, a cache—you might want to reuse the same instance of that class for a specific period of time. This is also referred to as the lifecycle of the class instance.
If the class's responsibility is crucial for the whole application, you can scope an instance of that class to the Application class. This makes it so the instance follows the application's lifecycle. Alternatively, if you only need to reuse the same instance in a particular flow in your app—for example, the registration or login flow—then you should scope the instance to the class that owns the lifecycle of that flow. For example, you could scope a RegistrationRepository that contains in-memory data to the RegistrationActivity or the navigation graph of the registration flow.
アプリ全体で重要であればApplicationクラスで持っても良いし、そうでなければ、アプリのフローの中で持っても良い。
The lifecycle of each instance is a critical factor in deciding how to provide dependencies within your app. It's recommended that you follow dependency injection best practices where the dependencies are managed and can be scoped to dependency containers. To learn more about scoping in Android, see the Scoping in Android and Hilt blog post.
DIなどを活用して利用しよう。
なぜ?
データレイヤーでキャッシュして使いまわしたくなるデータが有るため。
理想的にはアプリが必要なデータだけをデータソースが返すことが望ましい(サーバーのレスポンスなど)
The data models that you want to expose from the data layer might be a subset of the information that you get from the different data sources. Ideally, the different data sources—both network and local—should return only the information your application needs; but that's not often the case.
なぜ?
メモリの消費を抑えるなど。ただそうなることはあまりないという補足がある。
データソースのクラスとビジネスモデルを分離し、ビジネスモデルではアプリが必要なデータだけをも持とう
(ここで初めてビジネスモデル = business models という単語が出てきます。おそらくいわゆるドメインモデルと言われるやつのようです。)
For example, imagine a News API server that returns not only the article information, but also edit history, user comments, and some metadata:
必要ないauthorDateOfBirthとかが入っている。
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
The app doesn't need that much information about the article because it only displays the content of the article on the screen, along with basic information about its author. It's a good practice to separate model classes and have your repositories expose only the data that the other layers of the hierarchy require. For example, here is how you might trim down the ArticleApiModel from the network in order to expose an Article model class to the domain and UI layers:
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
Separating model classes is beneficial in the following ways:
- It saves app memory by reducing the data to only what's needed.
- It adapts external data types to data types used by your app—for example, your app might use a different data type to represent dates.
- It provides better separation of concerns—for example, members of a large team could work individually on the network and UI layers of a feature if the model class is defined beforehand.
なぜ?
- 必要なものを持つことで、アプリのメモリを節約できる。
- Data型で別のものを使うなど、別のデータ型をてきおうできる
- 関心事の分離ができる。例えばモデルクラスが事前に定義されていれば、大規模なチームでUIレイヤーとネットワークで個別に作業できる
他のレイヤーもモデルクラスを同様に定義できるが、追加のクラスとロジック、ドキュメントとテストを追加する必要がある。
You can extend this practice and define separate model classes in other parts of your app architecture as well—for example, in data source classes and ViewModels. However, this requires you to define extra classes and logic that you should properly document and test.
なぜ?
実装するクラスが増えるため。
最低でもデータソースが受信するデータとアプリ内のデータを分けよう
At minimum, it's recommended that you create new models in any case where a data source receives data that doesn't match with what the rest of your app expects.
分けることによるメリット(前述)と、他のレイヤーでもモデルクラスを増やす場合のデメリットが有るため。
データレイヤーは3つのlifecycleの操作を持つことができる
Types of data operations
The data layer can deal with types of operations that vary based on how critical they are: UI-oriented, app-oriented, and business-oriented operations.
UI-oriented operations
UI-oriented operations are only relevant when the user is on a specific screen, and they're canceled when the user moves away from that screen. An example is displaying some data obtained from the database.
UI-oriented operations are typically triggered by the UI layer and follow the caller's lifecycle—for example, the lifecycle of the ViewModel. See the Make a network request section for an example of a UI-oriented operation.
UI-oriented operations、画面に必要なDBのデータを購読するなど。画面単位のライフサイクル。
App-oriented operations
App-oriented operations are relevant as long as the app is open. If the app is closed or the process is killed, these operations are canceled. An example is caching the result of a network request so that it can be used later if needed. See the Implement in-memory data caching section to learn more.
These operations typically follow the lifecycle of the Application class or the data layer. For an example, see the Make an operation live longer than the screen section.
App-oriented operations、メモリでキャッシュを保持しておくときなど、Applicationクラスのライフサイクル。
Business-oriented operations
Business-oriented operations cannot be canceled. They should survive process death. An example is finishing the upload of a photo that the user wants to post to their profile.
The recommendation for business-oriented operations is to use WorkManager. See the Schedule tasks using WorkManager section to learn more.
Business-oriented operations、プロセスが死んでもキャンセルされないようなタスクで写真のアップロードなど。WorkManagerを使って処理すべき
リポジトリやデータレイヤーではCoroutinesとFlow関してはKotlinの仕組みを使ってエラーをthrowし、UIレイヤーでキャッチする。
Interactions with repositories and sources of data can either succeed or throw an exception when a failure occurs. For coroutines and flows, you should use Kotlin's built-in error-handling mechanism. For errors that could be triggered by suspend functions, use try/catch blocks when appropriate; and in flows, use the catch operator. With this approach, the UI layer is expected to handle exceptions when calling the data layer.
The data layer can understand and handle different types of errors and expose them using custom exceptions—for example, a UserNotAuthenticatedException.
なぜ?
おそらくKotlinの仕組みでハンドリングできるからだと思われます。
Kotlin langでこのあたりを質問してGooglerから回答をもらったりしました。ちょっと個人的な意見もまざるんですが、
なぜこういう関数でResultを使いたくなるのかというとKotlinにはチェック例外がなく、なぜチェック例外がないかというと以下のように、versionabilityとscalabilityの問題があるからです。
Googlerの意見によるといろんなレイヤーですべてエラーをチェックし、もう一度投げたりするのは例外に対してばかげており、throwしてコールスタックを脱出してしまう方が良いという意見だと解釈をしました。
例えば .firstOrNull(): R?が毎回チェックしないといけないResult型とかを返してきたらちょっとうざいみたいな感じだと思います。
Rustではもっといいとか、Rustは使う側からは扱いにくいとか、Railway Oriented Programmingとかこのあたりは奥が深いです ![]()
interfaceを提供して、API実装を交換可能にしよう
Key Point: Relying on interfaces makes API implementations swappable in your app. In addition to providing scalability and allowing you to replace dependencies more easily, it also favors testability because you can inject fake data source implementations in tests.
なぜ?
Fakeを提供して、テストで入れ替え可能にするため。
Repositoryで可変変数を使う場合はMutexを使う方法がある
For simplicity, NewsRepository uses a mutable variable to cache the latest news. To protect reads and writes from different threads, a Mutex is used. To learn more about shared mutable state and concurrency, see the Kotlin documentation.
The following implementation caches the latest news information to a variable in the repository that is write-protected with a Mutex. If the result of the network request succeeds, the data is assigned to the latestNews variable.
他のスレッドからの書き込みで壊れないようにする方法としてmutexがある。
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
なぜ?
マルチスレッドで可変な状態を扱うには注意が必要なため。(不整合が起きやすい)
アプリのスコープで動かしたい操作を使うときに別のCoroutineScopeを渡して使うことができる
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/* ... */
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
}
asyncを使って別のスコープでCoroutiensの処理を行っている。
async is used to start the coroutine in the external scope. await is called on the new coroutine to suspend until the network request comes back and the result is saved to the cache. If by that time the user is still on the screen, then they will see the latest news; if the user moves away from the screen, await is canceled but the logic inside async continues to execute.
なぜ?
ユーザーが画面から離れたときに処理をキャンセルせずに処理を続行することができるため。
大きいデータセットはRoomへ、小さいデータセットはDataStoreへ、JSONのようなデータの塊はファイルへ
If the data you’re working with needs to survive process death, then you need to store it on disk in one of the following ways:
- For large datasets that need to be queried, need referential integrity, or need partial updates, save the data in a Room database. In the News app example, the news articles or authors could be saved in the database.
- For small datasets that only need to be retrieved and set (not queries or updated partially), use DataStore. In the News app example, the user's preferred date format or other display preferences could be saved in DataStore.
- For chunks of data like a JSON object, use a file.
なぜ?
特に言及はなさそうなんですが、仕組み的に適しているからではないかなと思います。
Integration testで外部リソースにアクセスするときは、置き換えて管理できるようにしよう。
Integration tests that access external sources tend to be less deterministic because they need to run on a real device. It's recommended that you execute those tests under a controlled environment to make the integration tests more reliable.
For databases, Room allows creating an in-memory database that you can fully control in your tests. To learn more, see the Test and debug your database page.
For networking, there are popular libraries such as WireMock or MockWebServer that let you fake HTTP and HTTPS calls and verify that the requests were made as expected.
なぜ?
置き換えないと、実デバイスで動かす必要があり、結果が不安定になるため。