はじめに
縁あって株式会社ABEJA様よりABEJA Platform評価用ライセンスを発行して頂き、ROLEXのDAYTONAの真贋判定を行うモデルを作成してみました。
真贋判定の対象をROLEXのDAYTONAに理由は、偽物のデータを集めやすそうだなと思ったからです。(そもそも偽物がある題材が他にパッと思いうかばかった)
本記事では、最初にモデル作成までの過程を記載して、最後にABEAJA PlatformとAI作成についての感想を記載したいと思います。
記事の中には、実際の操作の中で画面コピー撮り忘れていたものがある為、代わりの画像を用意して貼り付けたものがある事をご了承下さい。
あと、私自身はAI関係の第一線に身を置いているわけではなく、本格的なAIプロジェクトも未経験の独学中の人間です。
そういう立場からの記事であることをご了承下さい。
データの収集
まずはDAYTONAの画像データの収集です。icrawlerなど画像収集に便利なライブラリがありますが、検索ワードだけで収集するのは難しいと判断して、正規取扱店と色々香ばしいWebサイトからコツコツ画像データをダウンロードしました。
余談ですが、icawlerについてはこの記事が参考になりました。
データの蓄積
収集したデータをABEJA Platformに蓄積します。
ABEJA Platformでは「チャンネル」というところに蓄積することになりますので、チャンネルを作成します。
画面左のメニューから「DataLake」-「Channel」をクリックし、画面右上の「Create Channel」ボタンをクリック。

下図画面が出現するので、それぞれの項目に値を入力して画面右下の「Create Channel」ボタンをクリック。
- Identifier: 任意のチャンネル名
- Description: チャンネルの説明
DataLake一覧画面に戻ると、先ほど作成したチャンネルが一覧に表示されています。
Channel Nameがリンクになっているのでクリック。

右側にある「Upload」ボタンをクリック。

アップロードしたいファイルを選択するには、画面中央のグレー領域にアップロードするファイルをDrag and Drop。
もしくは、画面中央のグレー領域の中央にある「select files」ボタンをクリックして、ダイアログ画面からアップロードするファイルを開く。
アップロードするファイルが選択出来たら、画面下にある「Upload」ボタンをクリック。(下図では1つのファイルだけですが、実際は複数のファイルをアップロードしました。)
アップロードが終わったら画面右下の「Close」ボタンをクリック。
アノテーション
画像のアップロードが完了したら、アノテーションを実施します。
今回だと、アップロードした画像が本物なのか偽物なのかをラベリングします。そうすることで、この画像は本物、この画像は偽物、という教師データが作成されます。
機械学習は膨大な教師データからコンピュータが学習をする技術です。
今回の場合だと、コンピューターが教師データから本物に共通する特徴と偽物に共通する特徴を見出し、真贋判定をする能力を学習するといった感じでしょうか。
それでは、Annotation画面を起動します。
画面左のメニューから「Annotation」をクリック。

画面右上の「プロジェクト新規作成」ボタンをクリック。

「Image Classification」をクリックして、画面右下の「次へ」ボタンをクリック。
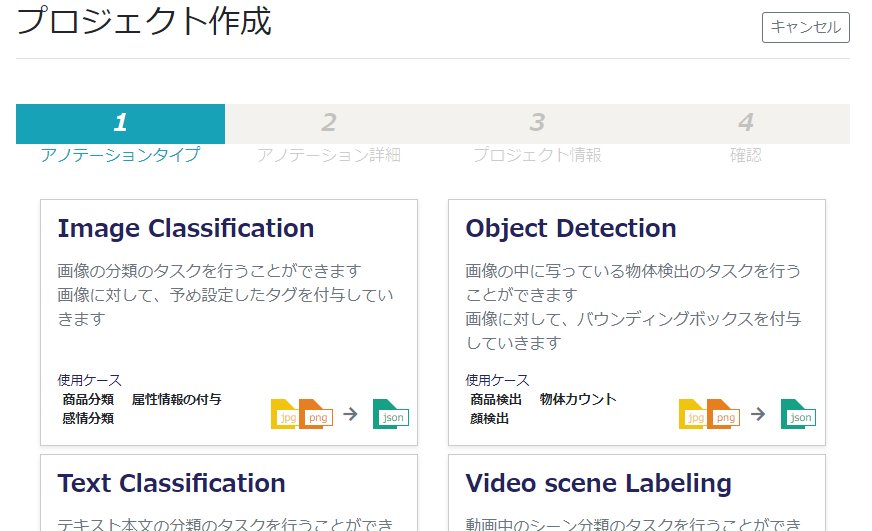
「選択方式によるアノテーション」をクリック。
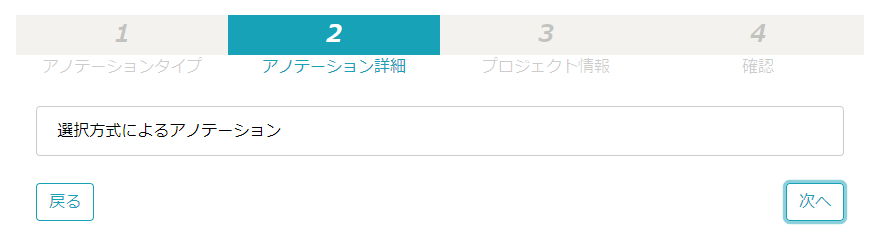
ラベリングする情報を作成します。
今回は本物と偽物のラベルデータがあればよいので、Category2を削除して、Category1を下図画面の通りに設定して、画面右下の「次へ」ボタンをクリック。
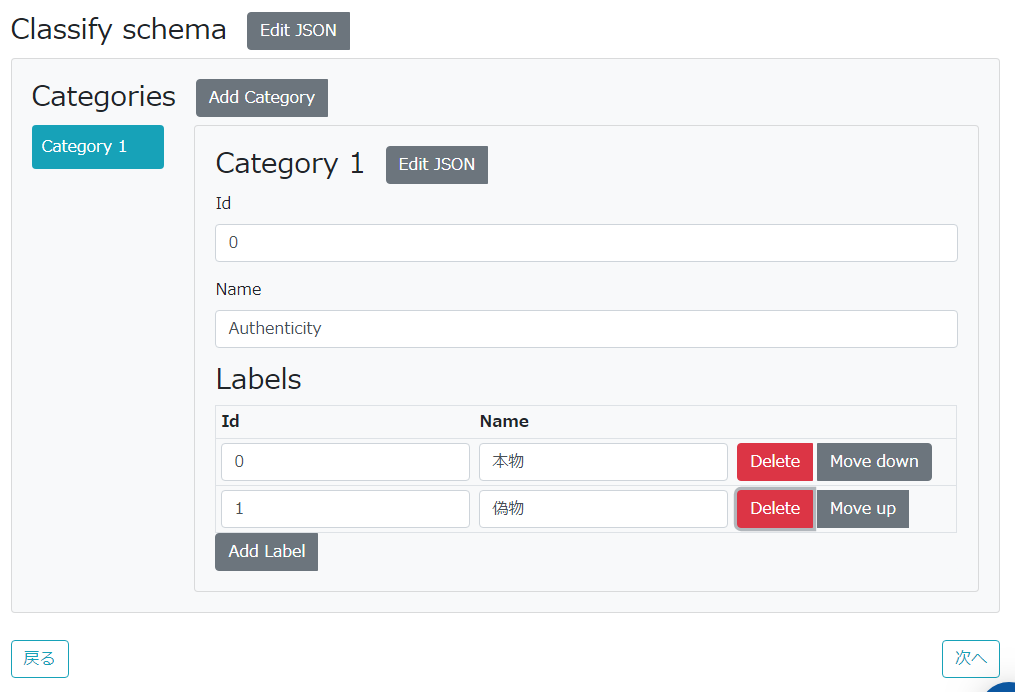
それぞれの項目に値を入力して、画面右下の「次へ」ボタンをクリック。
- プロジェクト名: 任意のプロジェクト名
- 目標データ数: 1人の担当者が何個のデータをアノテーションすればよいのかの目標
- 1データあたりのアノテーション数: 1データに対して何人以上のワーカー(アノテーション担当者)によるアノテーション作業が必要なのか(例えば
2に設定すると、1つのデータに対して2人以上のアノテーションが必要) - 入力データ用 Datalakeチャネル: アノテーションの対象となるデータが蓄積されたチャンネル
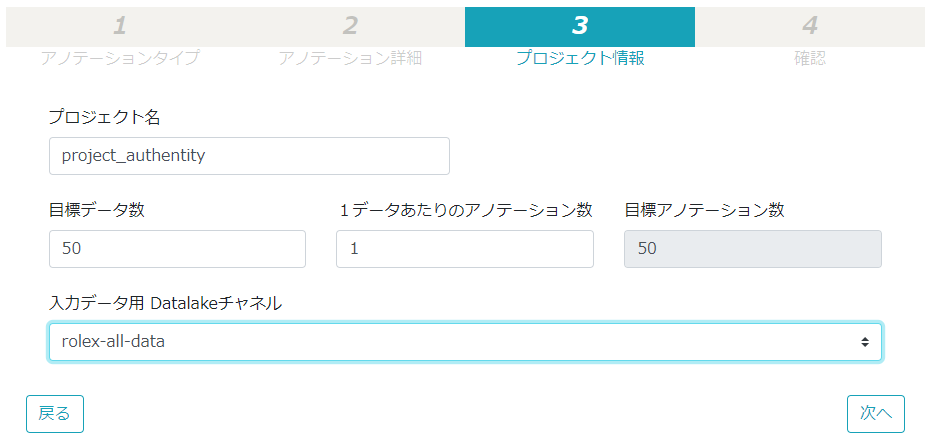
確認画面にて設定に間違いがないかをチェックして、問題が無ければ画面右下の「保存する」ボタンをクリック。
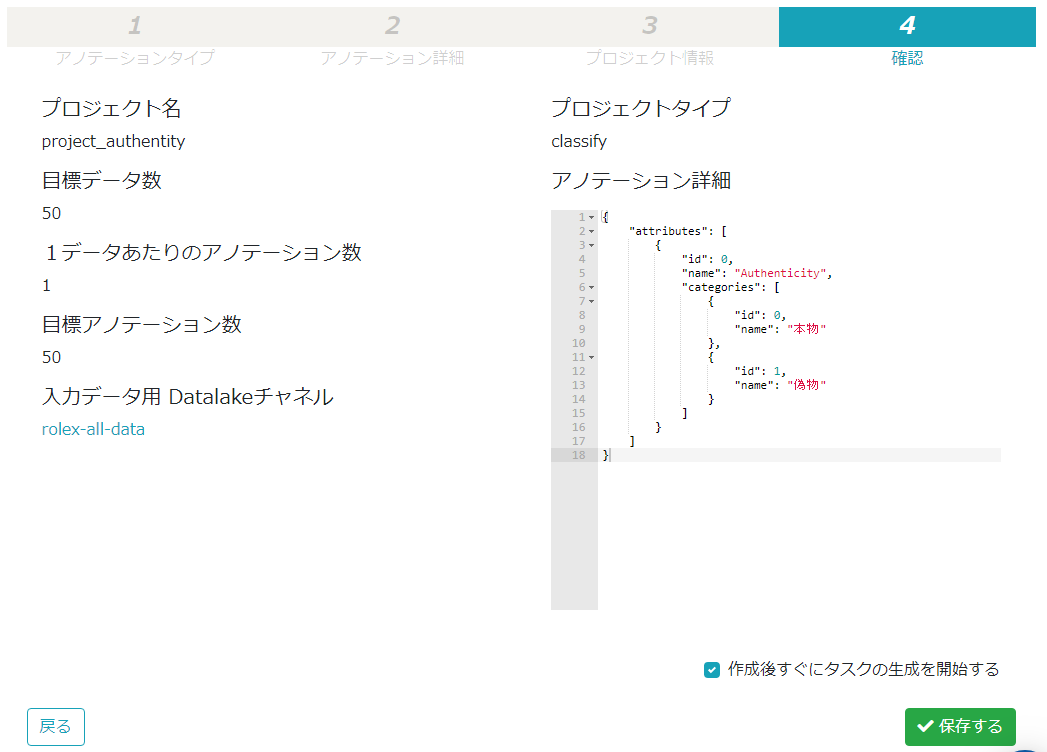
元のサマリー画面に戻ったら、サマリー一覧の中に作成したプロジェクトが表示されているので、プロジェクトの右上にある「歯車アイコン」のボタンをクリックして、メニューの中の「作業画面へ」をクリック。
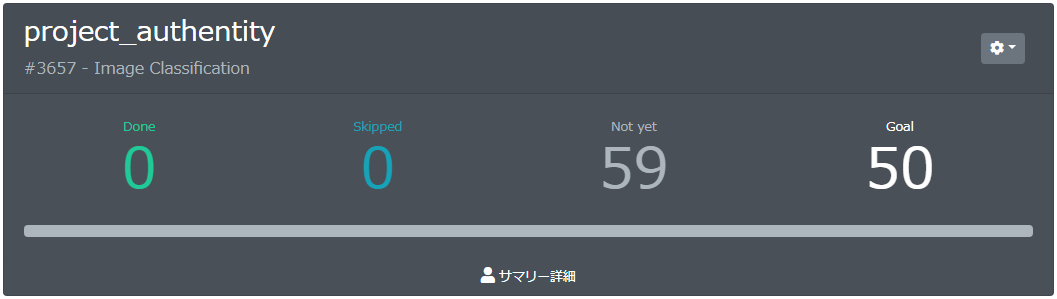
アノテーション作業画面になります。
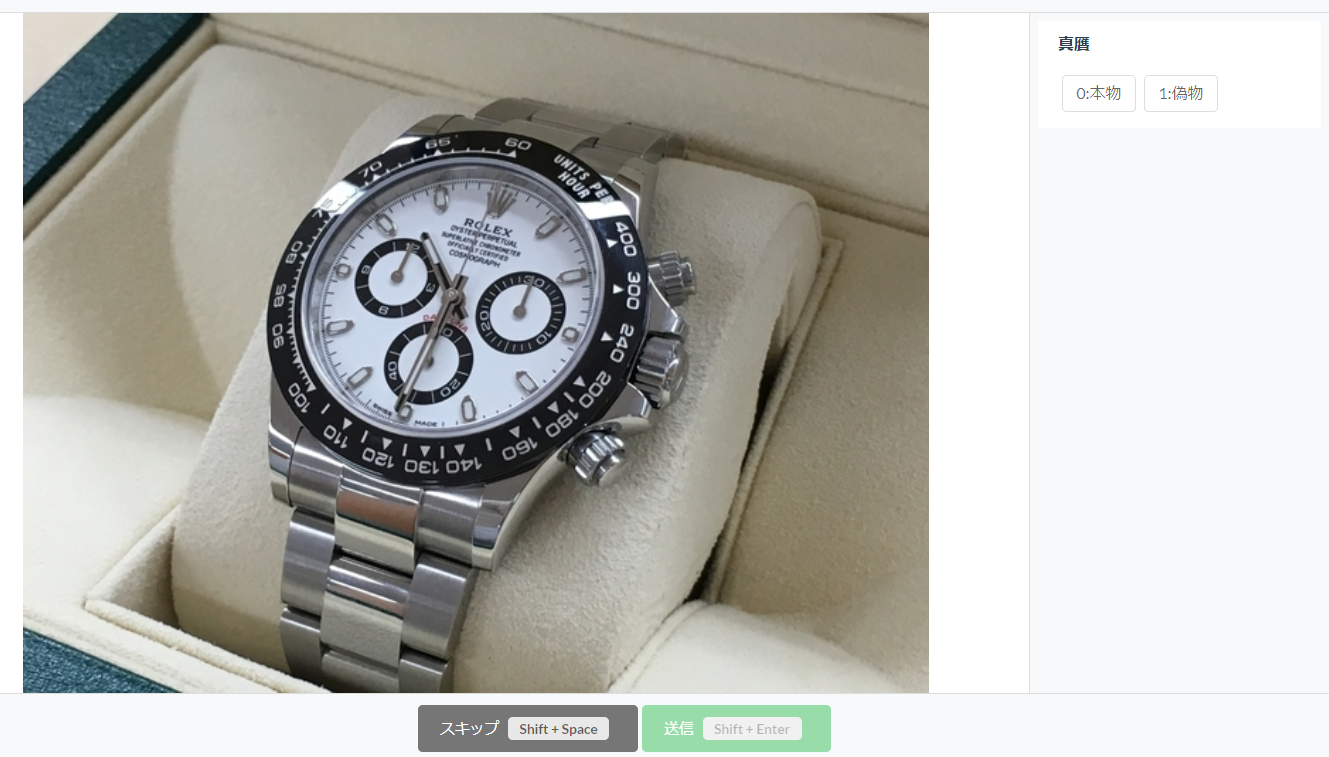
表示されている画像に対して、画面右側に表示されているラベルをクリックして、画面下側の「送信」ボタンをクリックすることで、アノテーションされていきます。
ラベルが分からないものは、画面下側の「スキップ」ボタンをクリックすることで、スキップできます。
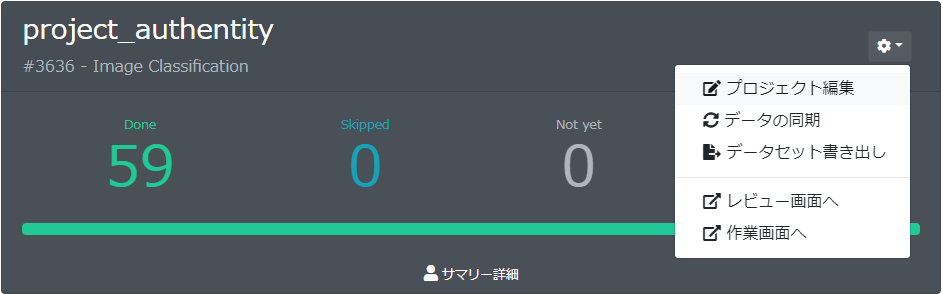
アノテーションが全て終わると、教師データをABEJA Platform上に蓄積します。
プロジェクトの右上にある「歯車アイコン」のボタンをクリックして、メニューの中の「データセット書き出し」をクリックする事で、ABEJA PlatformのDatasets上に蓄積されます。
(今回は私一人なので実施しませんでしたが、「レビュー画面へ」ボタンをクリックすると、ワーカーの作業をレビューする事も可能です)
学習(モデルの作成)
データの準備が整ったので、学習を実施します。
まずは何の学習なのかを定義する「Training Job Definition」と、実際の学習を行う「Version」を作成します。
今回の場合だと、ROLEX DAYTONAの真贋判定である事を「Job Definition」で設定し、学習に使用する機械学習プログラムとデータセットを「Version」という形で管理する感じです。(学習処理は他の機能で実行)
Training Job Definitionの作成
画面左のメニューから「Training」-「Job Definition」をクリックし、画面右上の「Create Training Job Definition」ボタンをクリック。

「Training Job Definition」に任意の値を入力。
今回はAuthentity_classification。
バージョンの作成
Training Job Definitionの画面に戻り、作成したTraining Job Definitionが一覧に表示されているので、右下の「Create Version」ボタンをクリック。

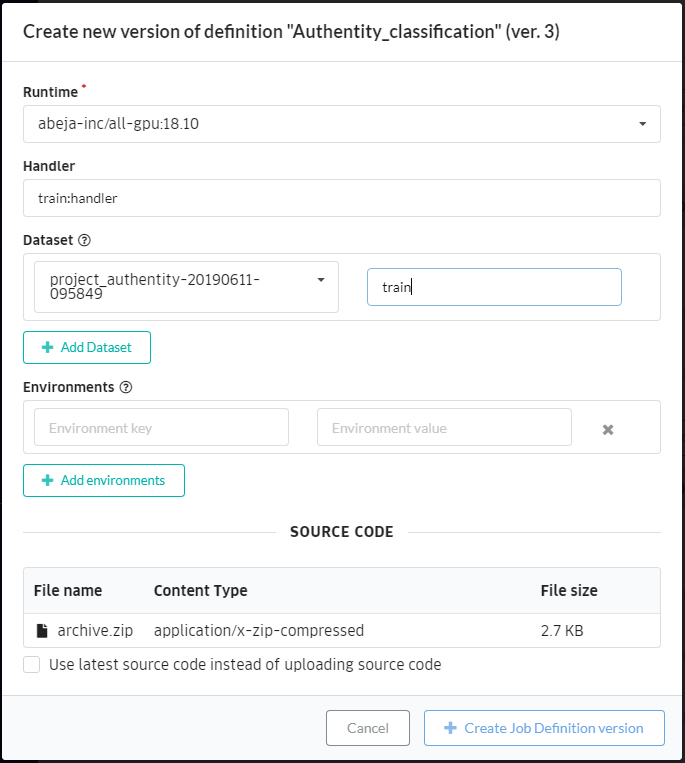
それぞれの項目に値を入力して、画面右下の「Create Job definition version」ボタンをクリック。
- Runtime: 任意のRuntime
- Handler: [機械学習プログラムのファイル名]:[学習の関数名]
- Dataset: アノテーションのデータセット書き出しで作成されたDataset
- Dataset Alias: train
- SOURCE CODE: 機械学習プログラムをzipファイルに圧縮したもの
※学習用のコードはドキュメントのサンプルコードに、一部手を加えたものを使用させていただきました。
学習ジョブの実行
Training Job Definitionの画面に戻り、作成したVersionが一覧に表示されているのが確認できます。
作成したVersionの学習を開始します。
Training Job Definition nameの右にある「Jobs」リンクをクリック。
画面右上の「Create Training Job」をクリック。

各項目を入力して、「Create Training Job」をクリック。
- Training Job Definition Version: 学習処理を実行するTraining Job DefinitionのVersion
- Instance type: 使用するインスタンスのタイプ
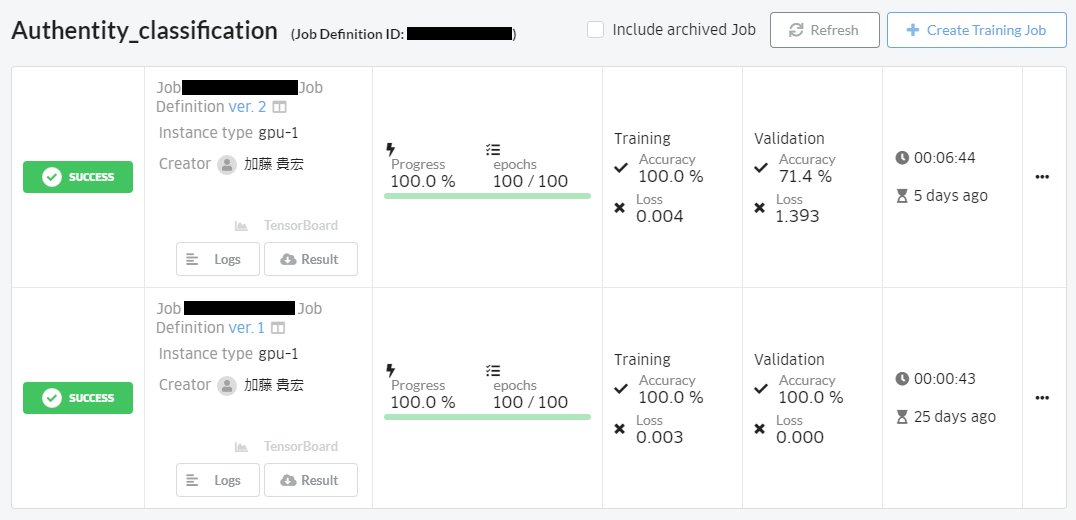
学習結果が表示されます。一番左に表示されるステータスが「SUCCESS」になったら成功です。
Modelの作成・デプロイ
作成したモデルをABEJA Platform上で動くようにします。
※一般的に機械学習のモデルは機械学習で生成された数式のことを指しますが、ABEJA PlatformのModelは機械学習で生成された数式と推論プログラムを紐付けたものを指していると思われます。この辺少し言葉の迷路に陥りますね...
Modelの作成(機械学習モデルと推論プログラムの紐付け)
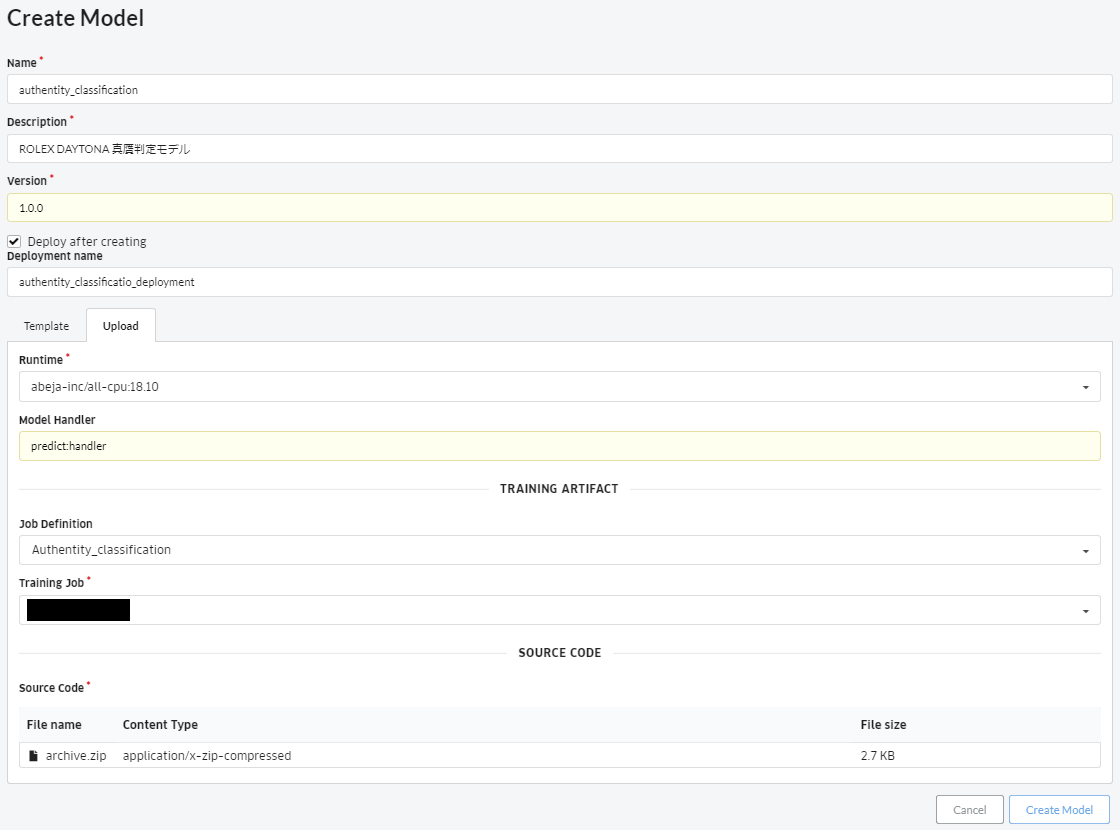
画面左のメニューから「Model」-「Model」をクリックし、画面右上の「Create Model」ボタンをクリック。

各項目を入力して、「Create Training Job」をクリック。
- Name: 任意の名前
- Description: 任意の説明
- Version: 任意のバージョン
- Deployment after creating: チェック
- Deployment name: 任意のデプロイ名
- Runtime: 任意のランタイム
- Model Handler: [機械学習プログラムのファイル名]:[推論の関数名]
- Job Definition: 推論プログラム(本項目でいうModel Handler)と紐付けるTraining Job Definitionの名前
- Training Job: Training Job Definitionのバージョン
- Source Code: 機械学習プログラムをzipファイルに圧縮したもの
※推論用のコードはドキュメントのサンプルコードに、一部手を加えたものを使用させていただきました。
HTTP Serviceの作成・モデルの動作確認
Deploymentの画面からHTTP Service(インスタンス&エンドポイント)を作成して、モデルの動作確認を行います。
画面左のメニューから「Model」-「Deployment」をクリックすると、一覧の中に先ほど作成したDeploymentが存在しますので、Deployment nameのリンクをクリック。
※先ほどのCreate Training Jobの際にデプロイを同時にするようにしていなかった場合(Deployment after creating: チェック無し)は「Create Deployment」ボタンからDeploymentを作成する必要あり

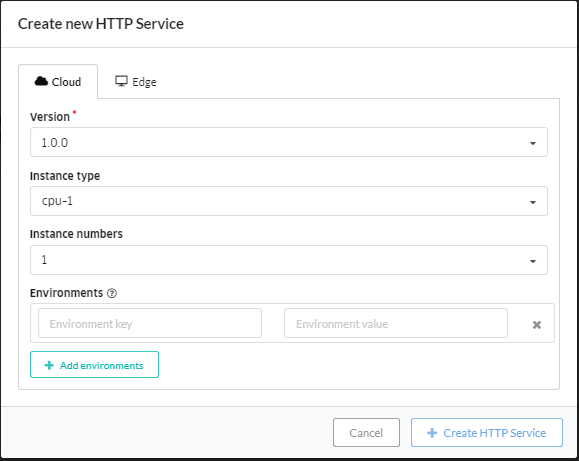
画面右上の「Create HTTP Service」をクリック。

各項目を入力して、「Create HTTP Service」をクリック。
- Version: これから作成するエンドポイントと紐付けるModelのバージョン
- Instance type: 任意のインスタンスタイプ
- Instance numbers: 任意のインスタンス数(1 - 32)
エンドポイントが作成されて一覧画面に表示されるので、「Status」が「Ready」になったら、「Check」ボタンをクリック。

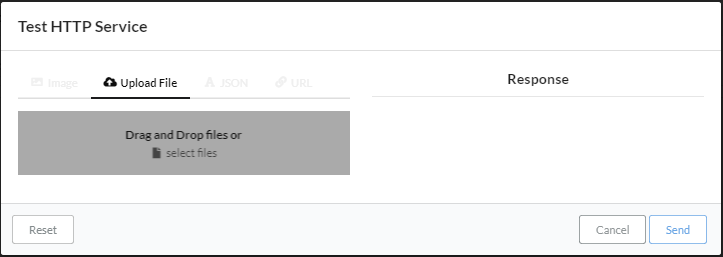
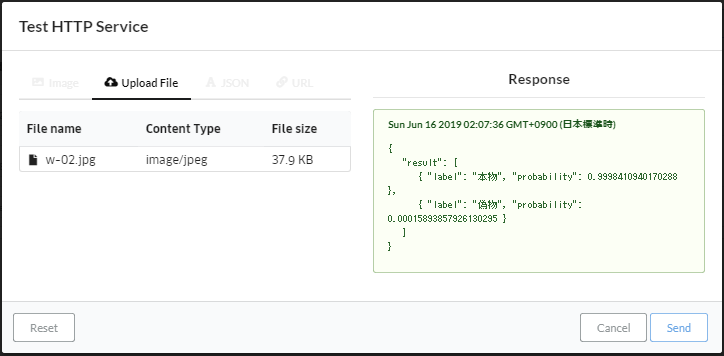
Test HTTP Service画面になったら、Upload Fileタブをクリックして、グレー領域にアップロードするファイルをDrag and Drop。
もしくは、画面中央のグレー領域の中央にある「select files」ボタンをクリックして、ダイアログ画面からアップロードするファイルを開く。
ファイルのアップロード後に「Send」ボタンをクリック。
Response項目に真贋判定の結果が返ってきました。完成です!
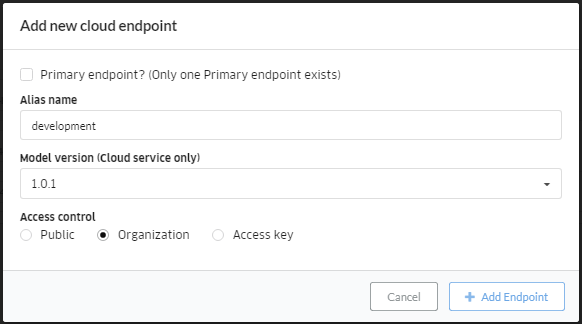
エンドポイントの追加(余談)
余談ですが、エンドポイントはHTTP Service作成時に付与されるものだけではないようです。
HTTP Serviceの画面にある「Add Endpoint」ボタンから、開発用やプロダクション用等のエンドポイントを別途作成し、自由にデプロイ済みのモデルに紐付けられるようです。
この機能を使うと、アプリ側のプログラムはそのままで、モデルのバージョンアップ等が出来そうですね。

最後に
ABEJA Platformについて
ABEJA Platformを使ってみましたが、特にABEJA Platform Annotationが非常に良くできていると感じました。
アノテーション機能は勿論、レビューや管理や進捗など、実際のプロジェクトで必要となる機能が一通り揃っており、実際のプロジェクトで培われた感じが好印象です。
また、ABEJA Platform全体を通して見ても操作が簡単で、ドキュメントを読めばモデル作成まで簡単なところも良いと思いました。データやプログラム管理、エンドポイント等が1つのサービスとしてパッケージングされていると、使い始めるまでのハードルが低くて助かります。
しかし、良いところだけがあるわけではなく、少し気になることころもありました。
全体的に細かいところが詰められていない感じがしました。エラーメッセージやバリデーションチェック等ですね。
ドキュメントも少し弱い感じです。ドキュメントにない運用をやろうとすると結構悩みました。
ただ、この辺は指摘させて頂いたので、今後は良くなっていくかと思います。
あと細かいことを言うと、用語が直感的でなかったり、既存の用語と被っているものがあるので、最初は慣れが必要だと思いました。チャンネルやモデル等ですね。
今後については、ABEJA Platform Acceleratorのリリースに期待しています。リンク先の記事を見る感じでは仮説検証用みたいですが、ノンプログラミングで機械学習が出来るのは大きいと思います。これがリリースされれば、AI構築のハードルが大きく下がると思います。
AI作成について
真贋判定ですが、実は偽物データについては「スーパーコピー」と呼ばれる見た目が本物と殆ど一緒の精度の高い偽物画像データだけを用意したせいか、大した結果は得られませんでした。これは全てをAIで解決したいと思ってハードルが高いことをやらせようとした私のミスだと思います。
真贋判定のAIを作るのであれば、精度の低い偽物をAIが判定してふるいにかけ、残った精度が高い偽物を人間が判定するといった設計にするべきだったかもしれません。巷でよく聞く「AIだけで何もかも解決しようとするのではなく、人間との二人三脚も前提に考えるべき」というやつですね。
(正直、スーパーコピーの判定は最初から無理かもしれないとは思っていましたが、AIの力を試したい誘惑に負けました。その割にはデータ数も少なすぎなんですが...)
次回はもうちょっと上手くやりたいと思います。