sktimeとはなにか
A unified framework for machine learning with time series
Google翻訳:時系列を使用した機械学習の統合フレームワーク
sktimeはお馴染みのsklearnの時系列バージョンという位置づけでいいと思います。時系列系のPythonライブラリと言えば、Prophetやstatsmodelsが有名どころなのかなと思ったりしてて、sktimeの情報があんまりなさそうなので、簡単にですがsktimeについて紹介できればと思っています。
時系列ライブラリ他
時系列ライブラリをほかにも探してみたら意外と知らないものがたくさん出てきたので、さらっと探せた分だけご紹介しておきます。
※2022/09/30時点の情報
| lib | GitHub | Stars | Issues |
|---|---|---|---|
| Merlion | https://github.com/salesforce/Merlion | 2,272 | 10 |
| 👑Prophet | https://github.com/facebook/prophet | 14,951 | 252 |
| Alibi-Detect | https://github.com/SeldonIO/alibi-detect | 1,514 | 87 |
| Kats | https://github.com/facebookresearch/Kats | 3.988 | 27 |
| statsmodels | https://github.com/statsmodels/statsmodels | 7,778 | 2,259 |
| GluonTS | https://github.com/awslabs/gluonts | 2,995 | 238 |
| RRCF | https://github.com/kLabUM/rrcf | 401 | 24 |
| STUMPY | https://github.com/TDAmeritrade/stumpy | 2,377 | 41 |
| Greykite | https://github.com/linkedin/greykite | 1,598 | 7 |
| pmdarima | https://github.com/alkaline-ml/pmdarima | 1,252 | 27 |
| AutoTS | https://github.com/winedarksea/AutoTS | 590 | 9 |
| Darts | https://github.com/unit8co/darts | 4,712 | 168 |
| Tsfresh | https://github.com/blue-yonder/tsfresh | 6,657 | 52 |
思ったより多かった、、、 スターが一番多かったProphetには👑つけておきました
sktimeの内部の実装について
sklearnをふんだんに使った実装になっており、インターフェースもsklearnを使っていればすぐに使いこなせそうな雰囲気があります。READMEを見てみると
sktime also provides interfaces to related libraries, for example scikit-learn, statsmodels, tsfresh, PyOD and fbprophet, among others.
Google翻訳:sktime は、scikit-learn、statsmodels、tsfresh、PyOD 、 fbprophetなどの関連ライブラリへのインターフェースも提供します。
なるほど。ほかの時系列ライブラリともうまくやっていけるみたいですね(先ほど頑張ってググった甲斐があったもんです)
ちらっとですが、APIドキュメントを呼んだところ予測系のAPIはstatsmodelsのラップ関数のようになっており、特段目新しいものがある気はしませんでした。ただ、時系列分類や時系列クラスタリングという、見慣れない単語が目につきました。
※多変量自己回帰モデルの例

sktimeは時系列データの分類問題を解くことができる
先ほど目についた時系列の分類問題について少しドキュメントを見ていこうと思います。sktimeは時系列分析における回帰分析に加えて、時系列データのクラスタリングや分類問題を解くことができるらしいです。時系列データを分類するとかいう発想がなかったので、これは面白そうといった感じです。ちょうどユーザガイドにサンプルコードがあるのでこれに従ってちょっと遊んでみましょう!
時系列分類(TSC)
時系列分類とは、例えば心電図の読み取り値に足して患者が病気かどうかを予測したりします。
ユーザガイドは尖頭器の分類を行うようです。年代によって尖頭器の形が異なるようで、尖頭器が分類できるといろいろ助かる人もいるみたいです。
尖頭器(せんとうき、英語: projectile point)とは、先端を鋭く尖らせた打製石器のこと。旧石器時代に現れる。 wiki

画像を時系列データに変換する
尖頭器は画像データですが、どうやって時系列データに変換しているのでしょうか?
Converting images into time series for data miningに二種類の方法が紹介されています。今回の尖頭器の例は radial scanning という手法を用いてそうです。
radial scanning は画像が円形になっているものに適用できます。ここでは尖頭器を例にとってどのように画像から時系列データを作成するかを見ていきます。
stepA. 尖頭器の輪郭を見つけます
stepB. 尖頭器の中心から輪郭上の各点までの距離を求めます
stepC. 最後にそれらの距離をプロットします
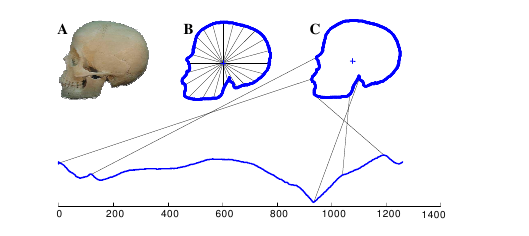
Converting images into time series for data miningより画像を引用
このようにすることで画像から時系列データを作成することができました。The UCR/UEA time series classification archive内のデータセットの多くがすべて同じ長さの時系列データであるというのは、このような変換を行っているからだと考えられます。
実際に分類問題をsktimeを使って解いてみる
ユーザガイドのサンプルコードを引用して適宜コメントを入れながら、sktimeってどんなもんなんやろなってことを見ていきたいと思います。
※シードを設定してないのでaccuracyに再現性がありません。参考程度にしてください。
まずはデータセットを読み込みます。load_arrow_headは尖頭器のデータセットですね。デフォルトで学習データが36、テストデータが175のデータに分割されています。
return_typeにpd-multiindexを入れるとpandasのデータフレームとしてデータを受け取れたり、データの受け取り型を指定することができます。
import matplotlib.pyplot as plt
from sktime.datasets import load_arrow_head
arrow_train_X, arrow_train_y = load_arrow_head(split="train", return_type="numpy3d")
arrow_test_X, arrow_test_y = load_arrow_head(split="test", return_type="numpy3d")
plt.title(" First instance in ArrowHead data")
plt.plot(arrow_train_X[0, 0])
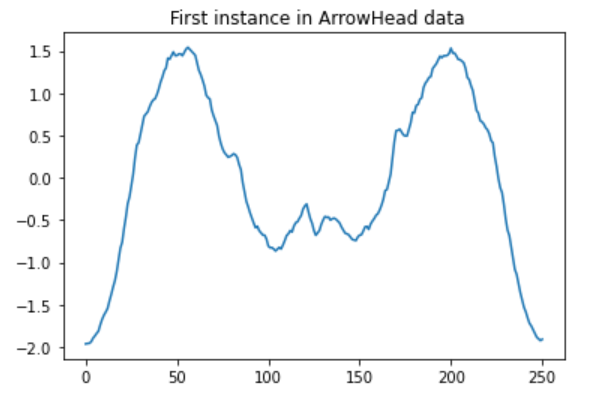
では読み込んだ尖頭器のデータをまずは普通のランダムフォレストに入れてみましょう。通常の分類器では系列情報を考慮しないで、分類を行うのでいい精度は見込めないでしょう。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
classifier = RandomForestClassifier(n_estimators=100)
arrow_train_X_2d, arrow_train_y_2d = load_arrow_head(
split="train", return_type="numpy2d"
) # sklearnようにデータのサイズをnumpy2dに変更している
arrow_test_X_2d, arrow_test_y_2d = load_arrow_head(split="test", return_type="numpy2d")
classifier.fit(arrow_train_X_2d, arrow_train_y_2d)
y_pred = classifier.predict(arrow_test_X_2d)
accuracy_score(arrow_test_y_2d, y_pred) # 0.6971428571428572
今度はsktimeの分類器を使ってみましょう。使用するのはROCKET: Exceptionally fast and accurate time series classification using random convolutional kernelsで紹介されているものです。どんなことをしてるのかはまだ見れてないのでよくわかりません(今度記事出すかもしれません)
ユーザガイドには比較的高速で正確な分類器だと紹介されています。
from sktime.classification.kernel_based import RocketClassifier
rocket = RocketClassifier()
rocket.fit(arrow_train_X, arrow_train_y)
y_pred = rocket.predict(arrow_test_X)
accuracy_score(arrow_test_y, y_pred) # 0.8171428571428572
accuracyを比べてみると確かに、sktimeのほうがsklearnの分類器を使った場合より数値がいいですね。
最後にパイプラインについて少し触れていたので、そこを紹介して終わりたいと思います。機械学習にはデータに対して様々な前処理を行いその後、推定器に値を渡して推定を行うという流れを何回も繰り返さないといけません。sklearnにはPipelineというクラスがあり、それらの一連の処理を簡単に行ってくれるラッパークラスがあります。
下記コードのmake_pipeline(tsfresh_trafo, randf)をご覧ください make_pipelineは引数に変換器と推定器を受け取ります。但し、最後の引数は推定器でなくてはなりません。
from sklearn.ensemble import RandomForestClassifier # 推定器
from sktime.pipeline import make_pipeline # パイプライン
from sktime.transformations.panel.tsfresh import TSFreshFeatureExtractor # 変換器
tsfresh_trafo = TSFreshFeatureExtractor(default_fc_parameters="minimal")
randf = RandomForestClassifier(n_estimators=100)
pipe = make_pipeline(tsfresh_trafo, randf)
pipe.fit(arrow_train_X, arrow_train_y)
y_pred = pipe.predict(arrow_test_X)
accuracy_score(arrow_test_y, y_pred) # 0.6571428571428571
sklearnのパイプラインと同様のことがsktimeにも実装されています。pipe_sktime = square * rocketを見てください。sktimeでは、変換器*推定器の形でパイプラインを構成することができます。
from sktime.classification.kernel_based import RocketClassifier # 推定器
from sktime.pipeline import make_pipeline # パイプライン
from sktime.transformations.series.exponent import ExponentTransformer # 変換器
square = ExponentTransformer(power=2)
rocket = RocketClassifier()
pipe_sktime = square * rocket
pipe_sktime.fit(arrow_train_X, arrow_train_y)
y_pred = pipe.predict(arrow_test_X)
accuracy_score(arrow_test_y, y_pred) # 0.8342857142857143
おわりに
時系列データの分類というのは今まで触れたことが無かったのですごくおもしろかったです。sktimeのドキュメントはかなり読みやすい部類なのではと思います。サンプルコードに対しての注釈も多く、引用元がわかりやすいので読んでいて楽しいドキュメントでした。
今後は、sktimeに用いられている分類器の実装や、画像を時系列データに変換する処理についてもっと詳しく調べていきたいと思います。