イントロダクション
前回の記事でAviUtlの.exoファイルから.STRファイルを作成した。
なんだかやってやったぞという気持ちになっていたが、よくよく考えるとこれだけでは不十分だった。

テレビの字幕を見てもイエロー・グリーン・シアンなんかで色分けされていることが分かる。
これは話者=話す人によって色を変えており、誰が話しているのかの識別をしやすくしているのだ。
基本的に自分で作成している動画にそんなに頻繁には人間は登場しないのだが、一色だとなんだか物足りない気もする。
であれば進化せざるを得ないだろう。

概要
やりたいこと
Aviutlで作った.exoファイルをYouTubeに色付きでアップロードできる形にしたい。
実装イメージ
Aviutlから作成した.exoファイルをドロップすると.yttファイルが出力される。
.yttファイルってなんすか?
前回作った.strファイルは単色で位置も制御できない…
できなかった気がする…確か。なんか一番シンプルなやつだった。
対して、.yttファイルとは何か、それは公式では開示されていないがすべての機能を使えるなんかすごいやつらしい。調査された記事がすでにqiita上に存在した。この調査には敬意の念を抱くしかない。
https://qiita.com/yudai1204/items/898c368af8832443a874
この知識が、やがて多くの人たちの役に立つことを祈る。
サンプル
.yttファイルのサンプル
下記は.yttファイルのサンプルである。
別にそこまで難しくはない。
ヘッドのところに文字情報を定義してボディのところでタイムとテキスト・文字情報に指定を行うだけだ。
なんかもうちょっとテクニックを発揮するとヨルシカ「雨とカプチーノ」のような字幕になるのかもしれない。
この.yttをもってしてもモバイルとPCには体験差があるというのが残念なポイントではある。
<?xml version="1.0" encoding="utf-8" ?>
<timedtext format="3">
<head>
<!-- Define styles for blue and pink text -->
<pen id="1" fc="#0000FF" fo="255" /> <!-- Blue text -->
<pen id="2" fc="#FFC0CB" fo="255" /> <!-- Pink text -->
</head>
<body>
<!-- Blue person's subtitles from 0 to 2000 milliseconds -->
<p t="0" d="2000" p="1">こんにちは、おはようございます。タローです。</p>
<!-- Pink person's subtitles from 2000 to 5000 milliseconds -->
<p t="2000" d="3000" p="2">今回はどんな企画をやるんですかーー!!</p>
</body>
</timedtext>
プログラムソースコード①.python
# Create str file for add subtitle to my videos on YouTube
# EXOファイルをYouTubeにアップロード可能なYTTファイルに変換するためのpythonコード
# YTTファイルはSTRファイルと異なり、色・形・位置・サイズその他すべての情報を制御できる
# YouTube Timed Text
# *********************************** ライブラリ ***********************************
import sys, os, time
import binascii
import re
import threading
import glob
import xml.etree.ElementTree as ET
from xml.dom import minidom
def input_with_timeout(prompt, timeout):
print(prompt, end='', flush=True)
result = ['e'] # デフォルト値を設定
def set_input():
result[0] = input()
input_thread = threading.Thread(target=set_input)
input_thread.daemon = True
input_thread.start()
input_thread.join(timeout)
return result[0]
# 取得対象となるグループ制御を行っているレイヤを取得
def get_layer_from_dropped_file(dropped_file, criteria):
target_layer_list = []
color_code_list = []
with open(dropped_file, 'r', encoding='shift_jis') as f:
s_line = f.readlines()
for l in range(len(s_line)):
text = s_line[l]
if text == '_name=グループ制御\n':
text_layer_contents = s_line[l-4]
text_attribute_contents = s_line[l+12]
color_code = s_line[l+15]
text_attribute_contents = text_attribute_contents.replace('\n','')
layer = text_layer_contents.replace('layer=','')
layer = layer.replace('\n','')
if int(criteria) <= int(layer) and text_attribute_contents == '_name=縁取り':
layer_number = int(layer)
if layer_number not in target_layer_list:
target_layer_list.append(layer_number) # グループ制御を行っているレイヤ
# target_layer_list.append(layer_number+1) # テキスト情報を入力しているレイヤ
if color_code not in color_code_list:
color_code_list.append([layer_number,color_code])
print(s_line)
return target_layer_list, color_code_list
# Retrieve information by dropped file
# Create lists of time, text, color
# ドロップされたexoファイルからタイム・テキスト・カラー情報を取り出す
def Get_data(exo_file_list, input_value):
text_lines = []
time_lines = []
end_temp_list = []
color_temp_list = []
# target_layer = "layer={}".format(input_value)
# ドロップされたファイルのグループ制御レイヤとテキストレイヤを特定+カラーコードを特定
target_layer_list, color_code_list = get_layer_from_dropped_file(exo_file_list, input_value)
with open(exo_file_list, 'r', encoding='utf-8', errors='ignore') as f:
s_line = f.readlines()
for l in range(len(s_line)):
# グループ制御しているレイヤをループ
# 行末の改行文字を取り除く
cleaned_line = s_line[l].strip()
# レイヤー番号がtarget_layer_listに含まれるかを確認
layer_match = re.search(r'layer=(\d+)', cleaned_line)
if layer_match:
layer_number = int(layer_match.group(1))
if layer_number in [x+1 for x in target_layer_list]:
serch_text_index = l
while True:
text = s_line[serch_text_index]
a = re.search("^text=", text)
if a is None:
serch_text_index += 1
continue
# テキスト変換
text = s_line[serch_text_index].replace("text=","").strip()
b = binascii.unhexlify(text)
s = str(b.decode("utf-16"))
text_lines.append(s)
# 開始時間を取得
start_time = s_line[serch_text_index-25]
start_time = start_time.replace("start=","").strip() # "start"と空白を削除
time_lines.append(start_time)
# 終了時間を取得
end_time = s_line[serch_text_index-24]
end_time = end_time.replace("end=","").strip() # "end"と空白を削除
end_temp_list.append(end_time)
# 色の情報を取得
selected_color_codes = [color_code_list[tll] for tll in range(len(target_layer_list)) if target_layer_list[tll] == layer_number-1]
selected_color_code = selected_color_codes[0][1]
selected_color_code = selected_color_code.replace('\n','')
selected_color_code = selected_color_code.replace('color=','')
color_temp_list.append(selected_color_code)
break
# タイムとテキストのリストを再生成
time_lines_new = []
for t in range(len(text_lines)):
append_text = text_lines[t].split('\x00')[0]
# print(append_text)
if len(time_lines_new) == 0:
time_lines_new.append([time_lines[t],append_text,color_temp_list[t]])
else:
if time_lines_new[len(time_lines_new)-1][1] != append_text:
time_lines_new.append([time_lines[t],append_text,color_temp_list[t]])
# print(time_lines_new)
# 終了時間を追加で記録する
time_lines_new.append([end_temp_list[len(end_temp_list)-1], "Closing", 'FFFFFF'])
# print(time_lines_new)
sorted_time_lines = sorted(time_lines_new, key=lambda x: int(x[0]))
# print(sorted_time_lines)
return sorted_time_lines
def fix_time(result_list):
result = []
frames_per_second = 30 # 1秒あたりのフレーム数
milliseconds_per_frame = 1000 / frames_per_second # 1フレームあたりのミリ秒
# 各要素について処理
for i in range(len(result_list)):
# 現在のタイム(フレーム単位)
current_frame = int(result_list[i][0])
# 最初の要素の場合は時間を0にする
if i == 0:
current_time_ms = 0
else:
current_time_ms = current_frame * milliseconds_per_frame
# 次のタイムとの差分をミリ秒で計算
if i < len(result_list) - 1:
next_frame = int(result_list[i+1][0])
duration_ms = (next_frame - current_frame) * milliseconds_per_frame
else:
# 最後の要素の場合、持続時間はデフォルトで1秒とする
duration_ms = 1000
# 結果リストに追加
result.append([int(current_time_ms), int(duration_ms), result_list[i][1], result_list[i][2]])
return result
# YTTファイルの作成
def generate_ytt_file(data_list):
# XMLの基本構造を作成
root = ET.Element("timedtext", format="3")
head = ET.SubElement(root, "head")
# ユニークなカラーコードリストを取得
unique_colors = list({item[3] for item in data_list})
# フォント情報を生成
for i, color in enumerate(unique_colors):
pen = ET.SubElement(head, "pen", id=str(i), fc="#"+color, fo="255", ec="#FFFFFF", et="3")
# 座標情報を追加
ET.SubElement(head, "wp", id="0", ap="0", ah="0", av="0") # 左上
ET.SubElement(head, "wp", id="1", ap="4", ah="50", av="50") # ど真ん中
ET.SubElement(head, "wp", id="2", ah="50", av="95") # 下
body = ET.SubElement(root, "body")
# テキストの動的生成
for item in data_list:
p = ET.SubElement(body, "p", t=str(item[0]), d=str(item[1]), p=str(unique_colors.index(item[3])), wp="2")
p.text = item[2]
# XMLを整形して出力
rough_string = ET.tostring(root, 'utf-8')
reparsed = minidom.parseString(rough_string)
return reparsed.toprettyxml(indent=" ")
# YTTファイルを保存
def save_ytt_file(ytt_content, outputfile_path):
# ファイル名の拡張子を .ytt に変更
base, ext = os.path.splitext(outputfile_path)
if ext.lower() != '.ytt':
outputfile_path = base + '.ytt'
# ファイルに書き込み
with open(outputfile_path, 'w', encoding='utf-8') as file:
file.write(ytt_content)
print(f"ファイルが保存されました: {outputfile_path}")
def main():
outputfile_path = 'YTT_File_for_Subtitle_on_YouTube.txt'
# 字幕が書き込まれたレイヤーを入力させる
print('\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n')
# print('字幕のみのシーンを作成し、')
input_value = input_with_timeout('字幕を入力した最初のレイヤを入力してください(ex=2): ', 15)
print('字幕開始レイヤを{}と認識しました'.format(input_value))
if len(sys.argv) > 1:
exo_file_list = sys.argv[1]
outputfile_path = os.path.join(os.path.dirname(exo_file_list), outputfile_path)
else:
print('ドロップファイルがありません')
# exoファイルの中身を読み込む
# シーン:タイトルから最終タイムとその文字のリストを作成する
# print(exo_file_list)
data_list = Get_data(exo_file_list, input_value) # ドロップされたデータからカラー/テキスト/タイムを取得
result_list = fix_time(data_list) # タイム情報を修正
# srt_list = format_subtitles(result_list)
ytt_content = generate_ytt_file(result_list) # 取得したデータからXML形式のファイルを作成
save_ytt_file(ytt_content, outputfile_path)
# print(srt_list)
# textファイルとして作成したのち、SRTファイルに変換する
# create_srtfile(srt_list, ouputfile_path)
print('Process END...')
time.sleep(5)
if __name__ == '__main__':
main()
プログラムソースコード②.bat
python.exe "D:\Codes\Python_codes\Python_codes\katuoshuwadoga\Convert_EXO_to_YTT_Create_Subtitle.py" %*
Scriptの使い方
①AviUtlで字幕を作成する
この際、色はグループ制御・縁取りでつけられているものとする
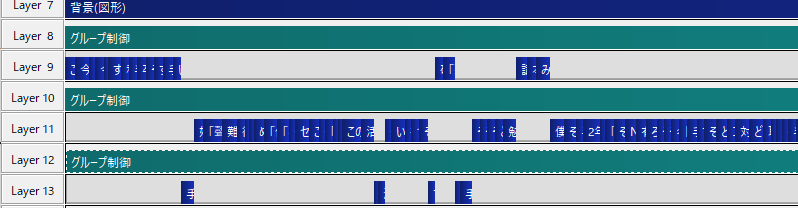
②AviUtlで.exoファイルを出力する
③.exoファイルをドロップする
④字幕を入力し始めた最初のレイヤ番号を入力する(上記だと8)
⑤.yttファイルが出力される
これから
う~ん…もうこれで字幕は十分じゃないか?
多少頑張りすぎている気もする。
字幕というのはNEONやらセムデックやらいろいろ作る機会があるのだが
中身がこれくらいシンプルだったらいろいろいじりようもあるもんだと思う。