PESPAというアーキテクチャについて、みなさんご存じでしょうか?
これはWebにおける次世代のアーキテクチャを表しており、MPAやPEMPA、そしてSPAの欠点を解決し、シンプルかつプログレッシブエンハンスメントなアーキテクチャとなっている素晴らしいアーキテクチャのひとつとなっています。
そう、Remixフレームワークが採用しているアーキテクチャです。
このPESPAという概念について、Kent C.Doddsさんが、2022年の10月21日に投稿し話題を呼びました。
日本ではあまりまだ浸透していない概念ということもあり、本当に素晴らしいアーキテクチャと思想を兼ね備えていることから、今回その記事を翻訳しました。
みなさんがこれから開発していくアプリケーションに、ぜひこのアーキテクチャを採用していただきたいと願っております。
この記事は、あくまで翻訳であり、意訳の部分も含まれているため間違っている箇所も存在する可能性があります。あらかじめご了承ください。間違っている箇所があれば指摘していただけると幸いです。
はじめに
今日、Webを構成しているHTTP、HTML、CSS、そしてJavaScriptは25年以上前に誕生・標準化された技術です。
そして、現在一般的に広く開発者によって採用されている最も一般的なアーキテクチャは、SPAと呼ばれるシングルページアプリです。
そう、私たちはWebアプリを構築する場合、当時と比べて新しくより洗練されたアーキテクチャへと移行を続けています。
広く一般的に使われている<a>要素や、<form>要素は当然昔からあるものです。リンクはブラウザがサーバーから何かを取得するために存在します。フォームは、ブラウザがサーバーに何かを送信するために存在します。
これらの双方向通信が仕様の一部としてはじまりから存在することによって、どんなに時間が経とうとも、Web上に存在する強力なアプリケーションを永遠と構築することが可能となっているのです。
ここで、主要なアーキテクチャを普及した年代に沿って紹介します。
- マルチページアプリ (MPA)
- プログレッシブリー・エンハンスド・マルチページアプリ(PEMPAまたの名を"JavaScript Sprinkles")
- シングルページアプリ(SPA)
- そして次の世代へ
ウェブの開発におけるさまざまなアーキテクチャには、時代時代の歴史的背景も含め、それぞれの利点や問題点が存在します。しかし、どんなアーキテクチャを採用しようとも、サーバー上でコードを動作させるという必要性から免れることはできません。(※Wordleのようなゲームは除きます)。
そして、それぞれのアーキテクチャを特徴づけているものの1つは、コードがどこに存在しどこで動いているのかというものです。
それでは、それぞれのアーキテクチャにおけるコードの場所が時代の移り変わりと共にどのように変化してきたのかをサンプルと共に見ていきましょう。それぞれの例では、以下の点に着目して思考を巡らせてみようと思います。
- 永続性
- データベースからのデータの保存と読み込みについて
- ルーティング
- URLに基づくトラフィックの誘導
- データ取得
- 永続的な対象からのデータの取得
- データの変更
- 永続的な対象に存在するデータの変更
- UIフィードバック
- ユーザーの操作に対する応答
もちろん、上記の内容以外にもWebアプリケーションはさまざまな要素から構成されていますが、上記で説明した内容は最も開発者がそれらに比べて時間を割いている部分であり、最も進化を続けている項目でもあります。
プロジェクトの規模や、チームの構成によっては、全て携わる場合もあれば、一部のみ携わる場合ももちろんあると認識しています。
それを理解した上で、以下の記事をご覧いただけると幸いです。
マルチページアプリ (MPAs)
MPAは最も初期に登場したアーキテクチャであり、当時のブラウザが持つ機能において唯一機能するアーキテクチャでもありました。
![]()
MPAでは、書かれたコードのすべてがサーバーに存在していました。
そして、ユーザーが所有するブラウザによってユーザーからのUIフィードバックに関するコードは動作していました。
MPAをアーキテクチャの側面からみた時の振る舞い
ドキュメントリクエスト

ユーザーがブラウザのアドレスバーにURLを入力することで、ブラウザはサーバーに対してリクエストを送信します。
この時、永続性に関するコードからデータを取り出す関数をルーティング・ロジック部分によって呼び出します。
そして、レンダリングロジックによってその取得されたデータはクライアントに送信するHTMLレスポンスの中身を決定づける重要な役割を果たします。このプロセスがサーバー上で行われている間、ブラウザでは普段ファビコンが表示される箇所によって保留状態であることが説明されます。(UIフィードバック)
リダイレクトミューテーションリクエスト

POSTメソッドなどを使って、フォームの内容を送信した時、ブラウザはその内容をシリアライズしたのちにサーバーに対して送信します。
そしてサーバー側では、ルーティングロジックによって、永続性に関するデータの変更を行う関数を呼び出すことでデータベースの更新を行います。
最終的にサーバーはクライアントに対してリダイレクトによってレスポンスを返します。このお陰でブラウザは新しい状態を取得しようとしてGETリクエストをサーバーに対して行うため、新しいUIの状態を画面に表示することが可能となります。フォームの送信からリダイレクトの完了まで、ブラウザでは先ほどと同じようにUIフィードバックを行い、保留中であることを説明します。
POSTリクエストの送信時に、どうしてリダイレクトを使ってレスポンスを返すのかというと、ブラウザ側で戻るボタンが押下された時に、再びフォームの送信が起きてしまうことを防ぐためというのが最大の理由です。
もちろんリダイレクトによって、再度GETリクエストが送信されてUIが新しい状態になるということもリダイレクトが使われる理由の一つです。
MPAの良いところと悪いところ
MPAが一番良いところは、そのメンタルモデルが持つシンプルさにあります。しかし、当時はまだこのシンプルさにほとんどの人が気づいておらず、大きな評価を得ることはできませんでした。
もちろんリクエストの中には、状態管理や複雑なフローを実現するためにクッキーを使って処理することもありましたが、ほとんとの場合はすべてがリクエストとレスポンスのサイクルの中で行われていました。
しかし、このアーキテクチャには惜しい箇所がいくつかありました。
1. ページ全体の更新
例えばフォーカスの管理はこの機能によって実現が難しくなります。
そして、ツイートのいいねなどの機能を実現しようとすると、その度にページ全てが更新をかけられるため、あまりに実用的でない実装になってしまいます。
また、アニメーションを使ったページの遷移は不可能となります。
2. UIフィードバックコントロール
ブラウザ上で表示されていたファビコンが、保留中の際にスピナーに変わることがUIフィードバックとされていました。もちろんこれでも十分かもしれませんが、より良いUXにはあまりに程遠いものとなっています。
良いとされているUXの多くは、ユーザーが操作したUIに視覚的に一番近くでフィードバックを行います。
そして、デザイナーはブランディングを行うためのカスタマイズを好みますので、この時のUIフィードバックコントロールでは、それは叶わなくなってしまいます。
もちろん、オプティミスティックUIにも対応できません。
これは注目すべきことなのですが、実は近日公開が予定されているページ遷移APIによってWebプラットフォームにおける多くのユースケースで改善が見込まれています。これにより、MPAがより有効な選択肢となってくることが想定されているのです。
しかし、今日におけるほとんどのWebアプリケーションでは、それでもまだMPAは十分なアーキテクチャとは断言することができません。
当時、これらの問題は標準化委員会の頭から抜け落ちていており、かつそのユーザーたちはより直接的な解決策を求めていたのです。
プログレッシブリー・エンハンスド・マルチページアプリ(PEMPAs)
プログレッシブ・エンハンスメントとは、すべてのWebブラウザ上で機能的にアクセスできるWebアプリケーションを開発し、加えてブラウザごとに実装されている追加機能を活用することで、ユーザー体験を向上させるという概念です。
例えば、ブラウザ機能に代表されるのが、XMLHTPRequestです。
信じられないかもしれませんが、これは当初1998年に、マイクロソフトのOutlook Web Accessチームによって開発されました。その後2016年に標準化を果たします。
2005年、Ajaxが言葉として普及したことにより、多くの開発者がブラウザでHTTPリクエストを行うという選択肢を選ぶようになりました。
これにより、UIがその場で更新できるようになり、ちょっとしたデータ以上のものをわざわざサーバーに取りに行く必要がないという思想が広まりました。これは結果的に、我々開発者に対して、プログレッシブリー・エンハンスド・マルチページアプリの開発を可能としました。
![]()
そして私たちは、ブラウザ上でのUIフィードバックに対して責任を持つだけでなく、今までサーバーでのみ意識すればよかったルーティングロジック、データ取得ロジック、データ変更ロジック、そしてレンダリングロジックまでもをクライアント側にて実装するという責務を負うことになっていくのです。
そして、ここにプログレッシブ・エンハンスメントの本質があります。
そもそも、プログレッシブ・エンハンスメントのコンセプトは、アプリは基本的な部分において機能的であるべきであり、ユーザー体験(UX)を高めるという文脈においてJavaScriptを使用するということを意味しています。
この考え方が生まれた2000年代前半は、ユーザーが使用するブラウザがAJAXを使用できるブラウザであるかどうか、もしくはアプリの使用前にJavaScriptをダウンロードできる高速なブロードバンド回線を使用しているかどうかを保証するすべは存在しませんでした。
そういった事情から、従来のMPAアーキテクチャを維持したまま、UXを向上させる目的でのみJavaScriptを使用するという制約を課す必要があったのです。
永続性に関する処理を除いて、もちろんどの程度のUXについて語るかにも依りますが、実際にはほとんどすべてのカテゴリに属するコードをクライアント側に書く必要があるのです。
オフラインモードにおいては、永続性に関する処理も必要となりますが、これは業界標準のプラクティスには該当しないと判断し、この表に含めることはしませんでした。
加えて、クライアントからのAJAXリクエストをサポートするためにバックエンドにもコードを追加する必要がありました。ということは、ネットワークを挟んだクライアントとサーバーの両側でそれまで以上に多くの作業をしないといけない必要性に迫られることになりました。
この時代では、jQueryやMooToolsなどが隆盛を誇っていました。
PEMPAをアーキテクチャの側面からみた時の振る舞い
ドキュメントリクエスト

PEMPAではユーザーが初めてドキュメントを要求したタイミングでMPAと同じ処理が行われます。しかし、PEMPAでは、<script>タグを通してクライアントサイドのJavaScript読み込まれ、MPAのみでは実現できなかった拡張的な機能を提供を行います。
クライアントサイド・ナビゲーション

クライアントサイド・ナビゲーションでは、ユーザーがhref属性を持つアンカー要素をクリックすると、クライアントサイドに存在するデータ取得ロジックが、MPAでも問題になっていたページ全体の更新を防ぎます。そして、JavaScriptを使用して、ブラウザ上のURLを更新します。
次に、クライアントサイドに存在するルーティングロジックが、UIの更新箇所や更新可否を判断し、データ取得ロジックがサーバーに存在するエンドポイントに対してリクエストを送っている間、UIフィードバックを行います。このUIフィードバックでは、保留中の状態をわかりやすい形で表示できるようJavaScriptを使い手動で行います。
サーバーサイドでは、ルーティングロジックからデータ取得に関する関数を呼び出して、永続性に関する対象からデータを取得し、その内容をXMLまたはJSON形式で送信します。
クライアントサイドでは、そのデータを使用して、レンダリングロジックによって最終的なUIの更新を行います。
インライン・ミューテーション・リクエスト

リダイレクト・ミューテーション・リクエスト

ユーザーがPOSTメソッドなどでフォームの内容を送信すると、クライアントサイドのデータ変更ロジックが、まずはデフォルト動作のページ全体更新とデフォルト動作のPOSTメソッドでの送信を一旦阻止します。
そして、JavaScriptを用いてフォームの内容をシリアライズしたものをサーバーサイドのエンドポイントに対して送信します。
サーバーサイドのルーティングロジックは、データの変更を行う関数を呼び出し、永続性に関する対象のデータの更新を行います。その後更新されたデータをレスポンスとしてクライアントサイドに返します。
クライアントサイドのレンダリングロジックでは、帰ってきた更新後のデータを用いて、必要であればそれに応じてUIの内容を更新します。
状況に応じて、データの更新後に、クライアントサイドのルーティングロジックがユーザーを別の場所に遷移させ、上記の画像のように同じような一連のフローを引き起こさせる場合もあります。
PEMPAの良いところと悪いところ
ご覧の通り、今までサーバーサイドのみに集中していた実装を、クライアントサイドにも導入し、UIフィードバックに対して責任を持つことで、当初MPAが抱えていた現実的な問題を確実に解決することができるようになりました。
結果的に、MPAの時代以上にアプリをよりコントールしやすくなり、さらにはよりカスタマイズされたような感覚を与えるアプリの開発ができるようになったのです。
しかし、当然ながらこれにも問題はあります。
それは、ユーザーが求めている体験を提供しようとするあまり、ルーティングロジック、データ取得ロジック、データ変更ロジック、そしてレンダリングロジックまでもをクライアントサイドで担う必要が出てきたのです。
これに起因して、いくつかの問題が存在します。
1. デフォルト動作の阻止
実は、ルーティングやフォームの内容を送信するといった文脈において、我々開発者はブラウザが行う仕事ほど素晴らしい仕事を行うことができていません。ページ上で表示されているデータの更新は、今では大きな関心ごとの一つとなり、クライアントサイドにおけるコード量の大半をしめることとなっています。
そして、レースコンディション、フォームの再送信、エラー処理とった場所にバグが潜む原因を作り出してしまっているのです。
2. カスタムコード
PEMPAよりも前の時代では、考える必要も書く必要もなかったコードの管理をしないといけなくなってきました。相関関係が因果関係であることを暗に意味するものではありませんが、一般的に考えてコード量が増えるということはその分バグも多くなるということ意味しています。
3. コードの重複
レンダリングロジックという文脈において、クライアントとバックエンドにおいて多くのコードの重複が発生してしまいます。これはフロントエンドとバックエンドにおいて、可能な限り同じようにUIを更新する必要があるためです。
そして、バックエンドが持っているUIと同じものをフロントエンドでも利用できるようにしないといけないのに加え、通常バックエンドとクライアントサイドでは異なる言語で実装されることが普通となっています。
その結果、基本的にはコードの共有は不可能となるため、重複が発生してしまうのです。
可能な限り同じようにUIを更新するということに関して、具体的にどういう難しさがあるのかを説明します。
例えば、クライアントサイドで発生するインタラクションによってクライアントサイドのコードが実行されUIが更新される状態をそれがページ全体更新の時でも実現可能にしないといけないという意味を表しています。
これは実現が困難であることは間違いありません。
4. コードの整理
PEMPAアーキテクチャを採用した場合、コードの整理が難しくなってしまうことを避けることはできません。
なぜかというと、PEMPAでは、データの保存方法やUIのレンダリングが統一されていないため、開発者はあらゆる場所でDOMを手動で更新する可能性を生み出してしまいます。結果的にコードの追跡を非常なレベルで困難にしており、開発効率を下げる結果となってしまいました。
5. サーバーとクライアントの間接性
サーバーサイドから公開されているAPIルートとそれに依存しているクライアントサイドのデータ取得ロジックやデータ更新ロジックにおけるコードとの間には間接性が存在しています。
つまり、ネットワークを境に、どちらか一方に変更を加えてしまうと、もう一方のコードの変更も必要になってしまいます。
変更箇所を辿るには、一連のファイルをかき分けながら進んでいく必要があり、コードが正しく動作することの保証がより一層難しくなったのです。
つまり、ネットワークを川に例えると、狐が川を越えることで匂いを消し、猟犬に嗅ぎつかれないようにするの同じように、ネットワークは間接性を引き起こしてしまう障害物となってしまうのです。
私事で恐縮ですが、僕がWeb開発の世界に足を踏みれたのはこのPEMPAが台頭していた事態です。懐かしさと震えるような恐怖が入り混じる混沌としていた頃の記憶が蘇ります。
シングルページアプリ(SPAs)
バックエンドからUIコードを削除することで、重複に関する問題が解決するということに気づくのに、そう多くの時間はかかりませんでした。

お分かりになる通り、PEMPAとの唯一の違い、それはバックエンドからレンダリングロジックが消失していることです。
これは、バックエンドはAPIのルーティングの処理に集中することで、レンダリングロジックと一部のルーティングロジックが削除されたのです。
この考え方広まった背景として、Backbone、Knockout、Angular、Ember、React、Vue、そしてSvelteなどが登場したということが主に挙げられます。
つまり、2023年現在のWeb業界やフレームワークのほとんどすべてが採用しているアプローチがこのSPAということの証明でもあります。
SPAをアーキテクチャの側面からみた時の振る舞い
ドキュメントリクエスト

SPAでは、バックエンドでレンダリングロジックを持たなくなったため、すべてのドキュメントリクエストはCDNなどを含む静的ファイルサーバーによって応答が行われるようになりました。
SPAがまだ出始めの頃は、<body>の中に<div id="root"></div>を含めるだけの空のHTMLファイルが使用され、目的としてはアプリケーションを文字通りマウントするために存在していました。
しかし、最近のフレームワークでは、スタティック・サイト・ジェネレーション(SSG)と呼ばれる技術を使うことで、ビルドの段階でレンダリングも行うことができるようになっています。
クライアントサイド・ナビゲーション

インライン・ミューテーション・リクエスト

リダイレクト・ミューテーション・リクエスト

XMLHttpRequestの代わりにfetchが使われるようになったこと以外、リクエストの処理方法はPEMPAの場合と変わりません。
SPAの良いところと悪いところ
今までSPAのふるまいを見てきて分かる通り、PEMPAと比べて酷くなっている部分は、ドキュメントリクエスト時における振る舞いです。
どうしてこのようなことになってしまったのでしょうか?
PEMPAからSPAに移行した際、最大の動機となったのはコード重複の解消による開発体験(DX)の向上でした。コードの重複という問題が存在しないだけで、当時の開発者にとっては最大のメリットだったのです。
やがてDXはUXへのインプットにつながり、私たち開発者はさまざまな手段を用いてSPAへの変更を正当化させていきました。
しかし、結局のところ、SPAが私たち開発者にもたらしたものは、DXの向上だけであり、本質的な部分の解決には至ることができませんでした。
当時の認識では、CDNはサーバがHTMLドキュメントを生成するのに比べて、より早くレスポンスを返すことができ、かつSPAは知覚的なパフォーマンスに大きく寄与すると個人的に考えていました。
しかし、これらの問題は、最新のインフラストラクチャーのおかげでほぼ解消されつつあり、現実の環境では思い描いていたシナリオ通りには進まず、SPAでは大きな変化をもたらすことはできませんでした。
そして、悲しい現実問題として、SPAにはまだPEMPAの頃と同じ問題が山積されています。一方で、それらの問題を管理するためのツール群も進化を遂げていることを忘れてはいけません。
もっと深刻なことに、SPAは新しい問題を生み出してしまいました。
1. バンドルサイズ
お分かりの通り、少し大きくなりすぎました。
JavaScriptがWebページのパフォーマンスに与えている影響については、こちらのWeb Almanacにて公開されている記事で詳しく解説されています。
2. ウォーターフォール
データを取得するためのコードが、すべてJavaScriptバンドルの中に存在しています。そのため、データの取得が行われる前に、そのバンドルのダウンロードを行わないといけなくなってしまいました。
さらに、バンドルに対してコード分割や遅延ロードいった技術を活用することになるため、次のような依存関係が発生してしまいます。
この依存関係は、最終的にUXの大きな低下に繋がる結果となってしまいます。もちろん、静的コンテンツであれば、これらの問題から回避することができます。しかし、SSGの提供者が取り組んでいる諸々の問題や制限などがあり、それらのベンダー特有の問題に対する解決策を値段をつけて喜んで売りつけてくるという問題も現実的な側面として存在します。
3. ランタイム・パフォーマンス
SPAでは、クライアントサイドでJavaScriptの実行機会が増え、その量はとてつもない量になるため、性能の低いデバイスではパフォーマンス上の問題が発生してしまいます。
これは、かつて堅牢なサーバーによって実行されていた作業を、手元の小さなコンピューターで実行することが期待されていることのあらわれであり、大きな問題のひとつなっています。
もちろん、かつて人類はそれよりももっと少ない電力で人々を月に送り込むことに成功してきましたが、そんなことは関係なく、これはこれで大きな問題なのです。
4. 状態管理
これは、SPAにおいてとてつもなく大きな問題となりました。
その証拠として、状態管理を解決するために存在するライブラリは想像を絶することでしょう。
SPAが登場するよりも前のアーキテクチャでは、たとえばMPAでは、DOMに状態をレンダリングし、それを参照または変更させるだけでした。
現在は、JSONを受け取り、データが更新されたことをバックエンドに知らせ、なおかつその状態を表すメモリ内の状態も最新の状態に維持しなくてはなりません。これはソフトウェアで最も難しいとされるキャッシュにが抱える問題とまったく同じ問題を抱えてしまうことにつながっています。
一般的なSPAでは、状態管理に関するコードが全体の3割から5割を占めています。
具体的な引用は持ち合わせていませんが、これがおそらく事実なのであろうことは、あなたの経験から推測可能だろうと思います。
状態管理に関するライブラリは、これらの問題を解決またはその影響を軽減させるために今日まで作られ続けてきました。
もちろん便利な側面を持ち合わせている一方、使用する側における疲労の蓄積も見てとれることが多くなりました。
ここまでに紹介された手法は、2010年代半ばから、デファクトスタンダードとしてその存在を確立してきましたが、2020年代に入り、それらを越える新しいアイデアがちらほらと登場してきました。
プログレッシブリー・エンハンスド・シングルページアプリ(PESPAs)
MPAが持つメンタルモデルのシンプルさはどのアーキテクチャも太刀打ちできません。そして、SPAが持つ機能は他のアーキテクチャと比べてより強力な機能となっています。
しかし、MPAからSPAへの変遷を辿ってきた開発者からしてみれば、この10年間で失ってしまったそのシンプルさがとても懐かしく思えて仕方ないことでしょう。
そもそも、SPAへの移行のきっかけとなったのが、PEMPAと比較した時のDXの向上です。この事実を踏まえた時、開発者が抱えるその嘆きはとても興味深いものを表しています。
もしも、SPAとMPAを1つのアーキテクチャとして統合することができ、そして両方が持ち合わせる長所を生かすことができるようになれば、そこで誕生するアーキテクチャはシンプルかつ高性能なものであると言い切ることができるはずです。
そう、それこそがまさに、**プログレッシブリー・エンハンスド・シングルページアプリ(PESPA)**なのです。
思い出してください。プログレッシブ・エンハンスメントとは、クライアントサイド上のJavaScriptはあくまで拡張機能的な位置付けであり、それがなくても動く機能的なアプリという基盤の考え方です。
つまり、プログレッシブ・エンハンスメントをコアの原理として可能にするフレームワークが、その原理を推奨するのであれば、そのフレームワークを通して開発されるアプリケーションの基盤はMPAのシンプルなメンタルモデルという強力な基盤に基づいていると断言することができます。
つまり、シンプルなメンタルモデルに基づいているというのは、リクエストとレスポンスのサイクルというコンテキストに沿って物事を考えるという、とてもシンプルなメンタルモデルを意味しているのです。
これにより、SPAが抱えていた問題点のほとんどすべてを解消することができるようになっています。
まず上記の内容を実現するために、PESPAは「ブラウザの動作をエミュレート」することで、デフォルトの動作を阻止しています。
つまり、「ブラウザの動作をエミュレートする」とは、ブラウザがリクエストを行うのか、それともJavaScriptによってフェッチリクエストを代わりに送信するのかの有無に関わらず、サーバーサイドのコードは同じように動作することを保証するという意味を表しています。
なので、PESPAがブラウザの動作をエミュレートしたとしても、サーバーサイドのコードを所持しながら、シンプルなメンタルモデルを残りのコードに対して維持することができるようになります。
そして、PESPAではデータを常に最新の状態に保ちます。これを行うために、ページ上で表示されているデータに変更が発生した場合は再度検証を行うというブラウザのデフォルトの動作のエミュレートを行うことが重要なポイントとなります。
従来のMPAでは、この動作を行う際に、ページ全体の再読み込みが行われてしまいますが、PESPAでは、この再検証はフェッチリクエストを通して行われます。
PEMPAには、コードの重複という大きな問題があったことをみなさんは覚えていますでしょうか?
PESPAでは、バックエンドのUIを実現するためのコードとフロントエンドのUIを実現するためのコードを完全に同じものにすることで、この問題を解決することに成功しました。
つまりPESPAでは、サーバーでレンダリングを行い、クライアントでインタラクティブに動作し更新のハンドリングまでも行うひとつのUIライブラリを使用することでコードの重複を防いでいるのです。

上記の画像を見ると、データ取得、データ変更、レンダリングを表す小さい箱がクライアント側にあることに気づくと思います。
これらの小さな箱は、拡張機能の部分を表しており、たとえば、ペンディング状態やオプティミスティックUIなどの機能はサーバーサイドではなくクライアントサイドに置かれるべきコードなので、クライアントだけで実行されるコードがいくつか用意されているということを意味しています。
これは、最新のUIライブラリでは、コロケーションといって関連するコードやコンポーネントを同じファイルやモジュールにまとめて置ける機能が実現されているため、十分にそのような構成に対応することが可能となっていることで実現されています。
PESPAをアーキテクチャの側面からみた時の振る舞い
ドキュメント・リクエスト

PESPAで行われるドキュメント・リクエストは、実質的にはPEMPAのそれと同じです。アプリの基本的な動作に欠かせない最初のHTMLがサーバーから送信され、UXを向上させるためにJavaScriptが読み込まれるといった形です。
クライアント・サイドナビゲーション

ユーザーがリンクをクリックした時、デフォルトの動作であるページ全体の再読み込みを防ぎます。代わりにルーターが、新しいルートに必要なデータとUIを決定し、新しいルートに必要なデータ取得を実行して、そのルートのための適切なUIをレンダリングします。
インライン・ミューテーション・リクエスト

リダイレクト・ミューテーション・リクエスト

インライン・ミューテーションとリダイレクト・ミューテーションの画像が同じことにみなさんはお気づきになられましたか?
そうです、これは偶然なんかではありません。
PESPAを使ったミューテーションは、フォームの内容の送信によって行われます。もう、onClick + fetchなんていうナンセンスなことはしません。
ただし、ユーザーのセッションがタイムアウトしたときに、ログイン画面にリダイレクトさせるようなプログレッシブ・エンハンスメントには、そのような命令的なミューテーションが存在しても問題はありません。
ユーザーがフォームの内容を送信した時、デフォルトの動作を阻止します。ミューテーションを実行するコードは、フォームの内容をシリアライズし、フォームのアクションに関連づけられたルート(デフォルトでは現在のURLと同じルート)に対してリクエストを送信します。
バックエンドに存在するルーティングロジックは、関連付けれているアクションコードを呼び出します。そして永続的な対象に対するコードとやり取りをして更新を行い、成功したレスポンスまたはリダイレクトを送り返します。
成功したレスポンスには、「いいね」とつぶやくことなどが含まれ、この場合のリダイレクトには、新しいGitHubリポジトリを作成するなどが含まれます。
リダイレクトが行われる時、ルーターは、そのルートのコード・データ・アセットを並行して読み込み、レンダリングロジックをトリガーします。
リダイレクトではない場合は、ルーターが現在のUIのデータを再検証した上で、レンダリングロジックをトリガーしてUIの更新を行います。
ルーターは、インライン・ミューテーションとリダイレクトの両方に関与しているので、どちらの種類に対しても同じメンタルモデルを提供しているのです。
PESPAの良いところと悪いところ
PESPAは、これまで紹介してきたアーキテクチャに内在していた大量の問題を解決しています。
ひとつずつ、確認していきましょう。
PESPAが解決したMPAの問題点
1. ページ全体の更新
PESPAは、ブラウザのデフォルトの動作を阻止し、代わりにクライアントサイドでJavaScriptを使ってブラウザのエミュレートを行います。
この点だけ見れば、コードを書く際には何の変化もなさそうにみえますが、ユーザーの視点から見れば、はるかに改善された体験を提供しています。
2. UIフィードバックコントロール
PESPAはブラウザのデフォルトの動作を阻止し、代わりにフェッチリクエストを行います。つまり、ネットワークリクエストを完全に制御下に置くことができ、UIにとって最も適した方法によってユーザーに対してフィードバックを提供することが可能となっているのです。
PESPAが解決したPEMPAの問題点
1. デフォルトの動作を防ぐ
PESPAの中心的な側面とは、ルーティングやフォームの動作に関して、ブラウザが行うものとほぼ同じように動作することが保証されていることです。
これによって、MPAのメンタルモデルを提供することが可能となっているのです。
- フォームの再送信によるリクエストのキャンセル。
- 順序から外れたレスポンスを適切処理しレースコンディションの問題を回避。
- エラーを表面化させることで、消えないスピナーの問題を回避
もっとありますが、これらはすべてPESPAをPESPAたらしめている部分となっています。
これこそが、フレームワークが本当に役に立つ場面となります。
2. カスタムコード
クライアントサイドとサーバーサイドの間でコードを共有し、ブラウザのデフォルトの動作をエミュレートするという適切な抽象化を行うことで、最終的に開発者が書かなければならないコードの量を大幅に削減することに成功しています。
3. コードの重複
PESPAのアイデアの一つに、サーバーサイドとクライアントサイドがレンダリングロジックにて全く同じコードを使用するというものがあります。
これにより、重複が発生することはありません。
これにより、クライアントサイドのインタラクションを作成し、クライアントサイドにて更新されるUIがページを更新した時と全く同じUIであることを保証します。
そのため、開発者自身が努力や配慮を行うことなく、常にこの問題に対応することが可能となっています。
4. コード構成
PESPAにおけるブラウザのエミュレートがもたらすメンタルモデルによって、アプリケーションの状態管理は必要なくなりました。そのため、コード構成がとてもシンプルになりました。
また、ネットワークを挟んだサーバーサイドとクライアントサイドの両側で、同じようにレンダリングロジックが処理されるため、無造作なDOMの変化を引き起こすことはないことが保証されています。
5. サーバーサイドとクライアントサイドの間における間接性
PESPAがブラウザの動作をエミュレートすることで、フロントエンドとバックエンドのコードのコロケーションが可能となったため、間接性が解消され、生産性が大幅に向上しました。
PESPAが解決したSPAの問題点
1. バンドルサイズ
PESPAに移行するためには、サーバーが必要となりますが、これはコードの大半をバックエンドに移動させることを意味しています。
これによって、本当にUIにとって必要なのは次の3点のみとなりました。
- サーバーサイドとクライアントサイドの両方で実行可能な小さなUIライブラリ
- UIインタラクションとフィードバックを処理すための数行のコード
- そして、コンポーネントのコード
そして、URL(ルート)ベースでコード分割できるおかげで、何百KBというJSを持つWebページにやっと別れを告げることができるようになりました。
加えて、プログレッシブ・エンハンスメントのおかげで、JavaScriptが完全に読み込まれる前にアプリが動作することが保証されます。
さらに加えて、JavaScriptフレームワークでは、クライアントサイドで必要なJavaScriptの量をさらに削減するための取り組みが今現在も行われています。
2. ウォーターフォール
PESPAの重要な点は、コードを実行しなくても、指定されたURLのコード、データ、アセット要件を特定することができることにあります。
つまり、コードの分割に加えて、PESPAはコード、データアセットの取得を一度にトリガーすることができます。一個の処理が終わるのを待ってから次の処理を行うといった必要はないのです。
また、PESPAではユーザーが他のルートへのナビゲーションを開始する前に、あらかじめそれらをフェッチしておくことで、それらが必要になったときに、ブラウザがすぐにそれらを引き渡します。これにより、アプリの体験を瞬時に感じることができるようになります。
3. ランタイム・パフォーマンス
PESPAでは、この分野において2つの利点を有しています。
- 多くのコードをサーバに移すことで、デバイスが最初に実行するコードの量を少なくできる
- プログレッシブ・エンハンスメントのおかげで、JavaScriptの読み込みと実行が終わる前にUIが使える状態になっている
4. 状態管理
ブラウザのデフォルトの動作のエミュレートは、MPAのメンタルモデルです。これのおかげで、PESPAのコンテキストでは、アプリケーションの状態管理をほとんど気にする必要がなくなりました。
その証拠として、PESPAに沿って開発されたアプリケーションのほとんどは、JavaScriptなしで動作するはずです。
PESPAは、ミューテーションが完了すると、自動的にページ上に存在するデータの再検証を行います。
MPAでは、ページ全体の再読み込みによってこれらの再検証を実現していました。
注意点として、PESPA(プログレッシブ・エンハンスメント)は、クライアントサイドのJavaScriptがある場合とない場合でまったく同じように動作するわけではないことを強調させてください。
というのも、プログレッシブ・エンハンスメントのゴールはそこにはないのです。
単純に、アプリのほとんどがJavaScriptがない状態で動作することが望ましいとされているだけなのです。
加えて、JavaScriptを使わないというUXにこだわるからというだけでもありません。
プログレッシブ・エンハンスメントを採用することで、UI側のコードを大幅に簡素化することができるようになることが1番の目標なのです。
もちろん、アプリケーションによっては、クライアントサイドのJavaScriptが必要な場合もあります。けれども、そのような場合でも、PESPAの主なメリットをきちんと享受することが可能となっているのです。
PESPAをPESPAたらしめるもの
- 機能的であることがベースライン
- JavaScriptはあくまで拡張機能的な役割のために存在するのであり、有効にしないといけないものではない
- 遅延ローディング
- インテリジェント・プリフェッチング(JavaScriptコード以上の体験)
- サーバーサイドにコードを移行させる
- PEMPAの時のような手作業によるUIコードの重複が発生しない
- 透明性のあるブラウザのエミュレート
PESPAの短所については、まだまだ模索中です。
ここで、いくつかの考えと、PESPAを知った当初の反応を示しておきます。
SPAやSSGに慣れている開発者の多くは、サーバーサイドのコードがアプリケーションの中核を担ってしまうことになり、嘆き悲しむかもしれません。
しかし、現実のアプリケーションを開発しようとすると、サーバーサイドのコードを避けることは絶対にできません。
確かに、サイト全体を一度ビルドしてから、CDN上におくことができるユースケースもあります。ありますが、我々開発者が本業の仕事で取り組まないといけないほとんどのアプリは、残念ながらこれらのカテゴリーには該当しません。
これと関連して、人々はこれに起因するサーバーのコストについても心配しています。SSGを使って一度アプリを作ってしまえば、あとはCDNを通してほぼ限界のない数のユーザーに非常に低コストで提供ができる、という考え方を持っているのです。
これらの批判には2つの欠点が存在します。
まず1つ目は、おそらく我々開発者はアプリの内側で、APIを叩いているため、いずれにせよ高価なサーバサイドのコードをたくさんトリガーすることになるはずです。
次に、CDNはHTTPキャッシュの仕組みをサポートしています。つまり、本当にSSGを使いこなせているのであれば、高速なレスポンスとレンダリングサーバーが取り組まないといけない処理の量の制限という両方を実現するために、間違いなくその仕組みを利用することができるはずなのです。
また、SPAから移行する際によくある問題点として、サーバーサイドでのレンダリングという問題に対処しなければならないことが挙げられると思います。
これらのモデルは、クライアントだけでコードを実行するということに慣れきってしまっている開発者にとっては、間違いなく異なるモデルであると感じると思います。ですが、この点が考慮されているツールを使用するのであれば、ほとんどの問題は取り越し苦労に終わると思いますし、問題にすらなりません。
もちろん、そうでない場合には間違いなく問題として残りますが、SPAからPESPAに移行する過程で、特定のコードをクライアントサイドでのみ実行するように強制するという合理的な解決策がきちんと存在するので大丈夫です。
このように、まだPESPAの欠点を見つけ出すことはできていません。しかし、欠点が見つかったとしても、それらとのトレードオフに見合うだけのメリットがPESPAにはあるのだろうと考えています。
また、既存のツールでもPESPAアーキテクチャに沿った機能がかなり前から備わっていたものもあります。ありますが、レンダリングロジックにおけるコードをサーバーサイドとクライアントサイドの両方で共有しながら、プログレッシブ・エンハンスメントに焦点を当てたことが画期的なことであるということを改めて主張させていただきます。
この記事では、プラットフォームが可能としている機能だけではなく、デファクトスタンダードのアーキテクチャを実証することに主眼を置いています。
PESPAの実装: Remix
そして、PESPAの先導役となっているのが Remix です。Remixは、Web標準と最新のUXにレーザーフォーカスを当てたWebアプリケーションフレームワークです。
私が説明した、PESPAの構成要素として必要なものすべてをそのまま提供している最初のフレームワークです。
他のフレームワークもこのRemixのリードに追いつくことが可能であり、すでに追随し順応しているものも存在します。特に、SvelteKitとSolidStartは、PESPAの原則を実装に取り入れていることを確認しています。
今後、さらに多くのフレームワークがこの流れに追随してくることが予想されています。
再度になりますが、メタフレームワークなどはかなり前から、PESPAのアーキテクチャ実現できていました。しかし、RemixはこのPESPAアーキテクチャを最前線に掲げています。他のフレームワークはそれに続く形となっています。

Remixはネットワーク全体のブリッジとして機能します。Remixがなければ、完全なPESPAを実現するために、開発者自らこの機能を実装しないといけません。
また、Remixは規約ベースと設定ベースのルーティングを組み合わせることでルーティングを処理しています。またRemixは、データの取得と変更(Twitterの「いいね!」ボタンのような動作)、保留状態やオプティミスティックUIを実装するためのUIフィードバックなどなど、プログレッシブ・エンハンスメントの部分についてもサポートしています。
Remixに組み込まれているネストされたルーティングのおかげで、より良いコードの整理を実現することができます。
このネストされたルーティングの機能は、Next.jsが同じように追求している機能の1つです。
PESPAアーキテクチャでは、ネストされたルーティングは特に必要ではありません。しかし、ルートベースのコード分割は重要な部分のひとつです。
さらに、ネストされたルーティングによって、よりきめ細かいコードの分割が可能となるため、とても重要な要素であると言えるのです。
Remixは、PESPAアーキテクチャを採用することで、より良いエクスペリエンスをより早く、そしてより楽しく構築できることを実証してくれています。
そして、最終的には次のような状況に辿り着きます。
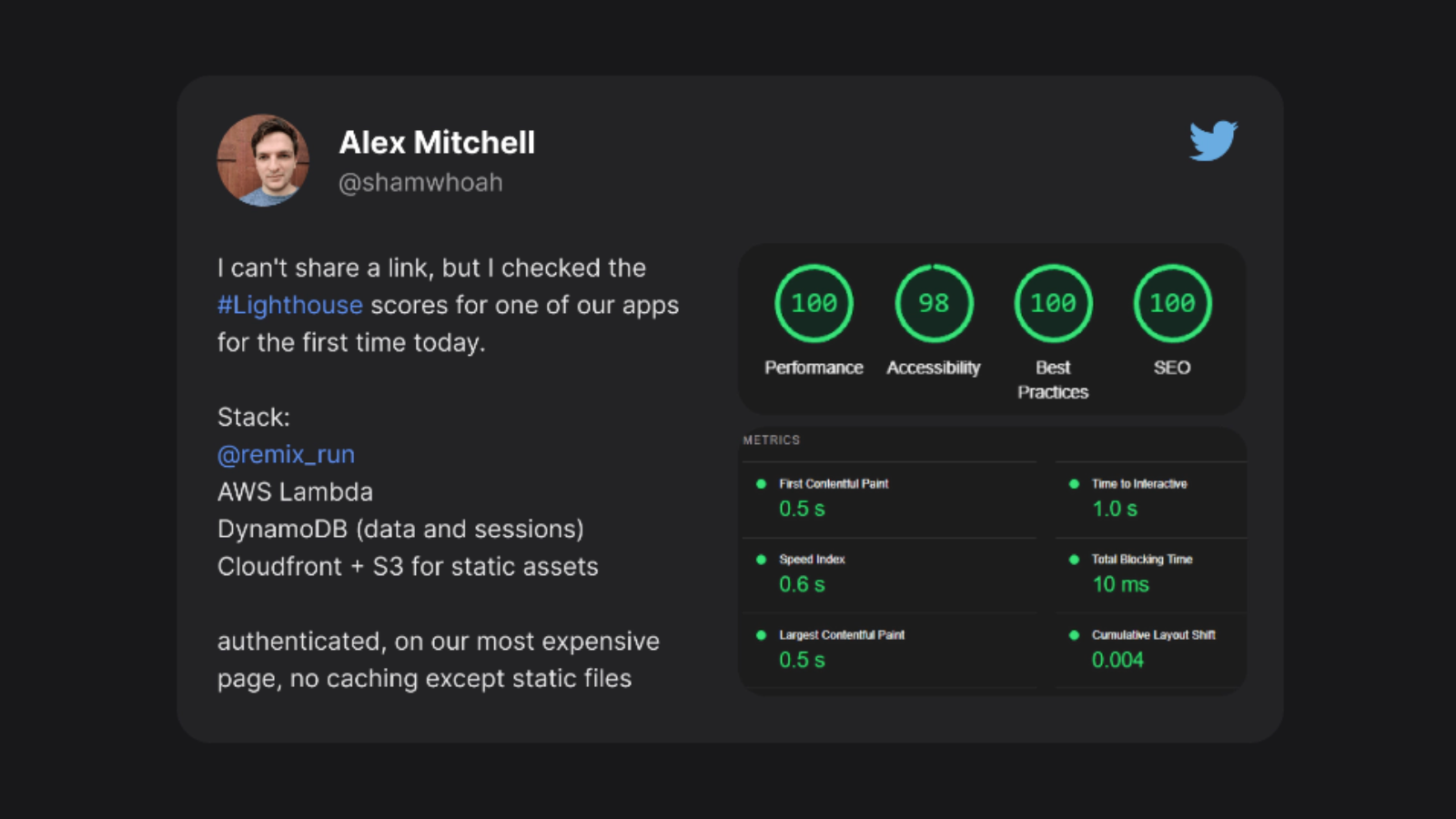
このようにがんばらずとも、パーフェクトなlighthouseのスコアを得ることができます!
まとめ
個人的な考えとして、このPESPAへの移行は大賛成です。
より良いUXとDXをの両方を同時に手に入れることができるのは、今日の大勝利である確信しています。これはとても重要なことだと思いますし、一方将来についてもどうなるのか楽しみで仕方ありません。
この記事を読み終えたあなたへのボーナスとして、TodoMVCアプリを使って時代を超えて動き回るこれらのコードの全てを実演してくれるリポジトリを作成しました!
ここにそのリポジトリが存在します!kentcdodds/the-webs-next-transformation
そして、このEpicWeb.devであなたに教えることにとても興奮しています。ウェブをより良いものにしましょう🎉。
乾杯!
原文