データレイク上の非構造データを対応すべく、Snowparkは日々アップデートがなされている。この記事では、Snowflake上にある画像データを対象に、Snowflakeのウェアハウスを使用し、画像分類タスクを実行する。
内容
Snowpark(Python UDF)を使用し、内部ステージにある画像ファイルに対して、画像分類タスクを実施する。

購読の対象者
コードレベルで説明するため、開発者寄りの記事となっている。もし、Snowflakeにおける非構造データの扱い方など概要レベルで知りたい場合には、こちらの記事を読まれることをお勧めする。
個人的な所感
- 今までは非構造データにおけるメタデータの管理しかできなかったが、ステージ上のファイルオブジェクトを処理できるように拡張され、データレイクとウェアハウスの統合に向けた第一歩のように感じた
- Transformersライブラリが便利で面白い
- 性能面が気になった。今回のケースでDeep Learningベースの処理であるため、GPUインスタンスなどの下回りの変革も必要になる
前提条件
- Snowparkのバージョンは1.0を使用
- Jupyter Notebookを使用
- Python UDFからステージ上にあるファイルオブジェクトを取得するため、Private Preview(PrPr)を使用している
- 必要な場合、営業の人にお声掛けください
ディレクトリ構成
├── helper_functions
│ └── snowpark_image_plotting.py
├── image_classification.ipynb
├── images
│ ├── bird1.jpeg
│ ├── bird2.jpeg
│ ├── bird3.jpeg
│ ├── cat1.jpeg
│ ├── cat2.jpeg
│ ├── cat3.jpeg
│ ├── dog1.jpeg
│ ├── dog2.jpeg
│ └── dog3.jpeg
└── snowflake_connection.json
詳細
まず処理の大まかな流れは以下となっている。
- 環境設定
- Snowflakeへの接続
- ローカルにあるファイル群を内部ステージにアップロード
- Snowpark APIを通じて、画像分類モデルをPython UDFとして登録
- UDFを実行し、Snowflake上で画像分類を実施
なお、記事が長くなってしまうため、「1.環境設定」や「2.Snowflakeへの接続」に関する詳細な説明は割愛する。これらに関する詳細情報として参考を記載しているため、こちらを参照することとする。
1. 環境設定
condaなどを使用し、必要なパッケージをインストールする。参考として、こちらを掲載しておく。なお、環境設定において注意すべき点として、いくつかのライブラリのバージョンには気をつけて頂きたい。具体的には、以下の通りである。理由として、UDFで登録する際にSnowflake側の環境とローカルの環境でのバージョンを一致させるためである。
%pip install pillow==9.2.0 torch==1.8.1, transformers==4.14.1, cachetools==4.2.2
2. Snowflakeへの接続
参考として、こちらを掲載しておく。snowflake_connection.json に接続に必要な情報を記載している。また、helper_functionsフォルダ下にあるsnowpark_image_plotting.pyのコードは記載するため、実行する際にはご自身の環境にコピーして頂きたい。
###############################
## Preparing our environment ##
###############################
import json
from glob import glob
from PIL import Image, ImageFile
import pandas as pd
from cachetools import cached
from snowflake.snowpark.session import Session
import snowflake.snowpark.functions as F
import snowflake.snowpark.types as T
from snowflake.snowpark.functions import udf
from helper_functions.snowpark_image_plotting import show_images_from_df, show_classifications_from_df
# Reading Snowflake Connection Details
snowflake_connection_cfg = json.loads(open('./snowflake_connection.json').read())
# Creating Snowpark Session
session = Session.builder.configs(snowflake_connection_cfg).create()
import pandas as pd
import matplotlib.pyplot as plt
from skimage import io
from skimage.transform import resize
from textwrap import wrap
import numpy as np
import snowflake.snowpark.functions as F
def show_images_from_df(df, url='RELATIVE_PATH', stage='@', title='RELATIVE_PATH', ncol=2, max_images=10, resize_shape=None, figsize=None):
df = df.with_column('PRESIGNED_URL', F.call_builtin('GET_PRESIGNED_URL', stage, F.col(url)))
df = df.sample(n=max_images).toPandas()
# Create a Presigned-URL for image-retrieval
nimages = len(df)
if nimages > ncol:
nrow = nimages // ncol + 1
else:
nrow = 1
ncol = nimages
if figsize is None:
figsize = (16, 16 // ncol * nrow)
fig = plt.figure(figsize=figsize)
for i in range(nimages):
image = io.imread(df['PRESIGNED_URL'][i])
if resize_shape is not None:
image = resize(image, resize_shape)
if title is not None:
label = df[title][i]
else:
label = 'N/A'
ax = fig.add_subplot(nrow, ncol, i + 1)
ax.set_title('{}'.format(label))
plt.imshow(image)
plt.xticks([]), plt.yticks([])
plt.show()
def show_classifications_from_df(df, url='RELATIVE_PATH', stage='@', title='RELATIVE_PATH', classifications='CLASSIFICATIONS', max_images=10, resize_shape=(200,200)):
df = df.with_column('PRESIGNED_URL', F.call_builtin('GET_PRESIGNED_URL', stage, F.col(url)))
df = df.select(list(set([url, title, classifications, 'PRESIGNED_URL']))).sample(n=max_images).toPandas()
nimages = len(df)
for i in range(nimages):
image = io.imread(df['PRESIGNED_URL'][i])
if resize_shape is not None:
image = resize(image, resize_shape)
if title is not None:
label = df[title][i]
else:
label = 'N/A'
fig = plt.figure(figsize=(12, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax1.set_title('{}'.format(label))
ax1.imshow(image)
ax1.axis('off')
ax2 = fig.add_subplot(1, 2, 2)
labels = pd.DataFrame(eval(df['CLASSIFICATIONS'][i]))['label'].tolist()
labels = [ '\n'.join(wrap(l, 40)) for l in labels ]
scores = pd.DataFrame(eval(df['CLASSIFICATIONS'][i]))['score'].tolist()
y_pos = (0.2 + np.arange(len(labels))) / (1 + len(labels))
width = 0.8 / (1 + len(labels))
colors = ['blue', 'green', 'yellow', 'orange', 'red']
for i in range(len(labels)):
ax2.barh(y_pos[i], scores[i], width, align='center',
color=colors[i], ecolor='black')
ax2.text(scores[i] + 0.01, y_pos[i], '{:.2%}'.format(scores[i]))
ax2.set_yticks(y_pos)
ax2.set_yticklabels(labels)
ax2.set_xlabel('Probability')
ax2.set_xticks([0, 0.25, 0.5, 0.75, 1])
ax2.set_xticklabels(['0%', '25%', '50%', '75%', '100%'])
ax2.set_title('Predicted Probability')
fig.subplots_adjust(left=None, bottom=None, right=1.5, top=None, wspace=None, hspace=None)
3. ローカルにあるファイル群を内部ステージにアップロード
まず、画像データをアップロード, UDFや画像分類モデルを登録するためのステージを用意する
# Create a stage for Images
session.sql("CREATE or REPLACE STAGE IMAGES directory = (enable = true auto_refresh = false) ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE')").collect()
# Create a stage for Functions
session.sql('CREATE or REPLACE STAGE FUNCTIONS').collect()
# Create a stage for Models
session.sql('CREATE or REPLACE STAGE MODELS').collect()
その後にputメソッドを使用して、ローカルにあるファイル群をSnowflakeの内部ステージにアップロードする。
# Upload sample images
for image_file in glob('images/*'):
session.file.put(image_file, '@IMAGES', auto_compress=False)
# Refresh stage
session.sql('ALTER STAGE IMAGES REFRESH').collect()
その、ディレクトリテーブルに対してクエリを掛け、画像データがアップロードされていることを確認する。結果の画像ファイルも貼っておく。
# Let's create a Snowpark DataFrame for our Directory Table
snowpark_df = session.sql("""SELECT * FROM DIRECTORY(@IMAGES)""") # -> DIRECTORY TABLE NOT YET IN SNOWPARK-API
print(f'Number of images:{snowpark_df.count()}')
snowpark_df.limit(5).show()

最後にhelper_functions下にあるメソッドを使い、内部ステージ上にある画像ファイルを取得し、Jupyter Notebook上に表示する。実際の画像データの取得にはPresigned URLを使用している。
show_images_from_df(snowpark_df, url='RELATIVE_PATH', stage='@IMAGES', title='RELATIVE_PATH', max_images=8, ncol=4, resize_shape=(200,200))

4. Snowpark APIを通じて、画像分類モデルをPython UDFとして登録
モデルをUDFに登録する前にローカルで画像分類モデルを構築する。今回使用するのはtransformersというhuggingfaceが公開している機械学習、特に自然言語処理を主とした深層学習向けのライブラリである。(このライブラリが凄い・・・)
pipeline() メソッドにある通り、入力の画像サイズを224x224に変換後に画像分類モデルを作成するパイプラインを組んだ上で、save_pretrained() メソッドを使用し、モデルファイルをローカルに保存している。その後に、モデル情報をSnowflakeの内部ステージにアップロードしている。
# Get an Image Classification model
from transformers import pipeline
image_classification_pipeline = pipeline("image-classification", "google/vit-base-patch16-224")
# Save model
image_classification_pipeline.save_pretrained('model/')
# Upload model-files to Snowflake
for model_file in glob('model/*'):
print(model_file)
try:
session.file.put(model_file, '@MODELS', auto_compress=False)
except:
None
必要なモデルを内部ステージにアップロード後、画像分類タスクをUDFとして登録する。2022/12現在において、UDFが動くSecure Sandboxと言われる環境から内部ステージにあるファイルにアクセスするためにプレビュー機能を有効化する必要がある。仮に有効化されていない場合、コードにある _snowflakeというライブラリがないとエラーが返ってくる。
@cached(cache={})
def f_load_transformer_model(import_dir: str)-> object:
from transformers import pipeline
transformer_pipeline = pipeline('image-classification', import_dir, import_dir)
return transformer_pipeline
@udf(name="classify_image",
is_permanent=True,
stage_location='@FUNCTIONS',
replace=True,
session=session,
packages=['pillow','pytorch==1.8.1','transformers==4.14.1','cachetools==4.2.2'],
imports=['@MODELS/config.json','@MODELS/preprocessor_config.json','@MODELS/pytorch_model.bin'])
def f_score_transformer_model(datafile: str) -> T.Variant:
import os
import sys
import io
import _snowflake ## PrPrの有効化が必要である
IMPORT_DIRECTORY_NAME = "snowflake_import_directory"
import_dir = sys._xoptions[IMPORT_DIRECTORY_NAME]
pipeline = f_load_transformer_model(import_dir)
# Dynamic File Access in UDFs
img = Image.open(io.BytesIO(_snowflake.open(datafile).read()))
output = pipeline(img)
return output
5. Snowflake上で画像分類タスクを実施
最後に登録したUDFを使い、内部ステージにある画像データを対象に画像分類タスクを実行する。具体的にはデュレクトリテーブルにあるFILE_URLを引数として、登録したUDFのf_score_transformer_model に渡している。その結果、最終列にCLASSIFICATIONS というVariant列に値がJson形式の値が入っていることを確認することができる。
なお、予測確率を計算していた時間は10-20秒程度と個人的には少し長い印象にあるが、今回使用しているウェアハウスのサイズがXSmallと小さいことが影響している。また、現在のSnowpark Optimized Warehouseなど下回りのインスタンスなど新たなインスタンスの出現に期待したい。
# Classify the images and gather the predictions
snowpark_df = snowpark_df.with_column('CLASSIFICATIONS', f_score_transformer_model("FILE_URL"))
snowpark_df.toPandas().head()

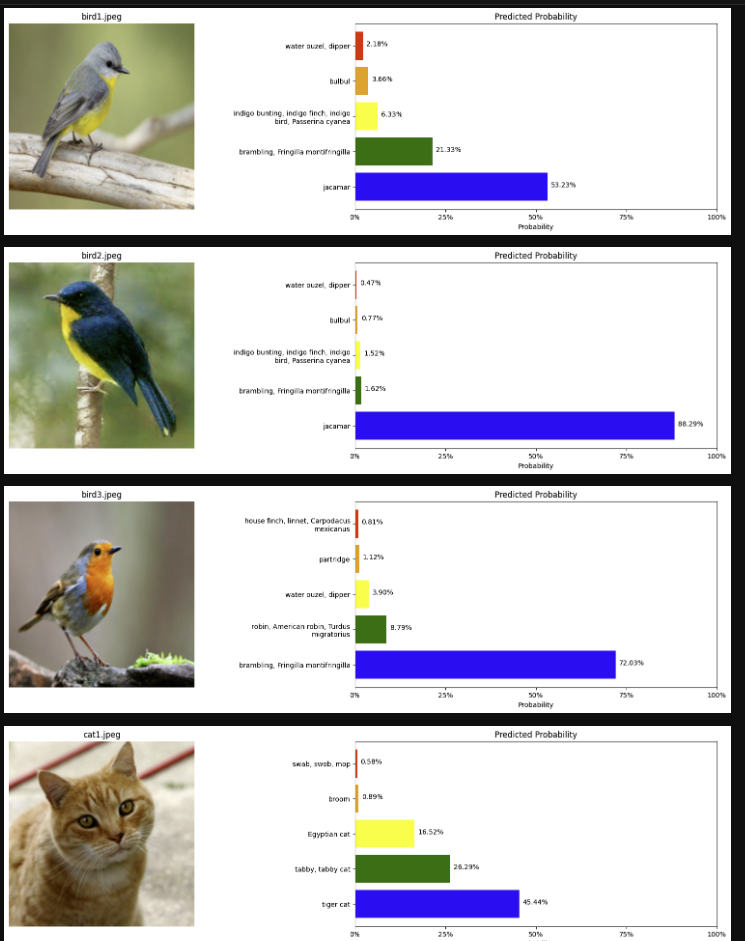
また、最後に登録した画像と共に各分類タグの予測確率を載せたバーグラフをJupyter Notebook上に表示する。
# Display a sample of images
show_classifications_from_df(snowpark_df, url='RELATIVE_PATH', stage='@IMAGES', title='RELATIVE_PATH', max_images=8, resize_shape=(200,200))
まとめ
今回の例では画像データであったが、それ以外にもステージ上にある非構造データを含むファイルオブジェクトをSnowflakeをウェアハウスを使用し、処理することが可能となっていた。Snowflakeのウェアハウスから内部ステージへの通信が可能とする機能は現在Private Preview中ではあるが、この機能が今後はもっと充実化していくはずである。そうすれば、現在のデータレイクとデータウェアハウスを統合的に管理はできることに加え、SnowflakeというIFからテーブルとファイルオブジェクトの両方を統一的に処理ができるようになっていくはずである。