はじめに
Kaggleは、オンラインでデータサイエンス・機械学習のコンペをやっているサービスです。少し前からKaggleに参加するようになり、最近は日々Kaggleのコンペと格闘しているので、Kaggleコンペでの工夫を紹介しようと思います。
特徴量エンジニアリングとは?
今回は、最近取り組んでいるRiiid! Answer Correctness Predictionというコンペを題材に説明したいので、例もこちらのコンペから取ります。
Kaggleのコンペは、一般的に、学習用のデータを与えられ、それを元にモデルを学習させて、本番のデータでのスコアを競うというかたちになっています。また、コンペにかぎらず、機械学習の一般的な開発フローでは、何かしらの学習データをもとにモデルを学習させ、それを未来のデータに適用するというかたちになることが多いでしょう。
このコンペの学習データはtrain.csvというファイルです。約1億行の巨大なCSVファイルですが、カラム数はそれほど多くありません。以下にカラムの一覧を載せます。なお、内容はTOEICに関する教育用サービスのデータで、ユーザーが問題に正解できたかどうかを予測するという問題になっています。
| カラム名 | 説明 |
|---|---|
| row_id | 行ID |
| timestamp | 時間 |
| user_id | ユーザーID |
| content_id | 問題または講義のID |
| content_type_id | 行の種別。0なら問題、1なら講義 |
| task_container_id | 複数の問題をまとめるコンテナID |
| user_answer | ユーザーが選んだ答え |
| answered_correctly | 正解したか |
| prior_question_elapsed_time | ひとつ前の問題にかかった時間 |
| prior_question_had_explanation | ひとつ前の問題には説明があったか |
このうち"answered_correctly"が予測すべき変数です。本番で最終的に入力されるデータにはこのカラムが存在しないので、他の特徴を使って、この値がどうなるかを予測します。「特徴量」というのは、この予測に使うデータの種類のことです。
そして特徴量エンジニアリングというのは、単純に言えば、上のような、データの種類を増やすこと(件数を増やすのではなく、カラムの種類を増やすこと)と捉えて問題ありません。おそらくこれだけではイメージがわきにくいかもしれないので、いくつか簡単な例をあげてみましょう。
- 他のデータと結合する。例えば、content_idを使って、問題に関する情報を足すことができそうです(リレーショナルデータベースのジョインと同じようなイメージです)。実際、このコンペでは、train.csvの他に問題のマスターデータ(questions.csv)、講義のマスターデータ(lectures.csv)が与えられており、そちらのデータと結合させるのは有効そうです。
- 統計量を追加する。例えば、問題IDごとの平均正答率を出し、それと結合することもできそうです。
- 計算で変形する。例えば、このデータではtimestampがミリ秒単位になっていますが、1000で割って秒単位にしてしまっても良さそうです。あるいは、前の問題から次の問題までの時間間隔なども、有効な特徴になるかもしれません。
- 補完する。例えば、欠損値を何かしらの値で埋めたり、外れ値(極端に大きい値や小さい値)を除外することも重要です。
別の言い方をすれば、上にあげたカラムの多くは、それ単体では、ほとんど予測の役に立ちません。例えばユーザーIDや問題のIDの数字を見ても、そこからユーザーの正答率を予測することはできないでしょう。つまり、これらの値は、特徴量エンジニアリングによってその値を生かしてやらなければ、ほとんど意味もない値でしかないのです。
なぜ特徴量エンジニアリングするのか?
(1) 重要だから
機械学習において、特徴量エンジニアリング以外の部分、例えばモデルやアルゴリズムの選択、パラメーターのチューニングなどで結果が左右される部分は確かにあります。Kaggleなどのコンペでは、そこで勝敗が決まってくる部分もあるでしょう。が、実際には、性能の大半を決めているのは特徴量です。
よっぽど変なことをしなければ、現在一般的に使用されるようなモデルやアルゴリズムはどれもそこそこ優秀なので、そこでものすごく大きな差がつくことはないでしょう(おそらく)。
しかし特徴量が違えば結果は大きく変わってきます。例えば、正答率を大きく左右している変数があるのに、それを使わなければどんな優秀なアルゴリズムでもそこそこの結果しか出せませんし、逆に、簡単なアルゴリズムでも、スーパー特徴量があれば性能は大きく改善します。
(2) クリエイティブだから
特徴量エンジニアリングはアイデアを生かせる場面です。「こういう特徴が効いてるかも?」という素朴なアイデアを実装して、見込み通り性能があがればうれしいですよね。特にこのコンペのように内容がイメージしやすいものは、比較的アイデアを出しやすいかもしれません。
具体例
では早速、特徴量エンジニアリングの具体例を見てみましょう。特徴量エンジニアリングを思いつくパターンのうち、代表的なものを取り上げてみます(まだ開催中のコンペなので詳しいところはややぼかしています)。
1. ドメイン知識を活用する
データを見ているうちに、ふと重要なことを思い出しました。確かTOEICの問題って、前半がリスニングで、後半がリーディングだったはずです。
データを見るとpartという箇所があり、partは1-7のいずれかです。これはTOEICのパートに対応しているようなので、パート1からパート4までがリスニング、パート5からパート7までがリーディングです。リスニングが得意な人とリーディングが得意な人はわかれると思われるので、これは重要な情報かもしれません。この特徴を追加するのは非常に簡単です。
train_df.is_listening = train_df.part <= 4
が、試したところ、この特徴量をくわえても、私のモデルではそこまで性能が向上しませんでした。すでにパートの情報を学習に使っていたので、それだけで十分だったのかもしれません(使い方によってはまだ可能性はあるかもしれませんが)。
いずれにせよ、以上のように、課題に関する知識からアイデアが出ることは少なくありません。
2. 何とかしてこの特徴量を活用できないか?
データを見て、「何とかしてこれを使えないか?」というところから思いつくパターンも結構あります。
例えば、今回与えられた問題データ(questions.csv)にはtagという項目があります。下記のようなスペース区切りの文字列で、3個から5個程度のタグがついています。個々のタグの意味は伏せられていますが、問題のカテゴリのようなもののようです。
51 131 162 38
ただし、これは個数が不定というのもあって、使い方がかなり難しく、他の人の回答を見ても、これを使えている例はそれほど多くなさそうでした。
一方、データの紹介を見ると、「問題をクラスタリングするのに使える」といった趣旨が書かれています。それなら、ということでクラスタリングに活用してみましょう。
クラスタリングというのは、似たデータをグループに分ける手法です。不定個のタグだと扱いにくいので「似たタグがついたもの」をまとめて、20個程度のクラスタにわけてみます(クラスタリングのやり方はもう少し改善の余地がありそうですが、とりあえず単純な仕方でやってみます)。
from sklearn.cluster import KMeans
tags_q = questions_df["tags"].str.split(" ", n=10, expand=True)
tags_q.columns = [f"tag_{i}" for i in range(1, 7)]
category = [-1] + list(range(0, 188))
tags_q.fillna(-1, inplace=True)
for col in tag.columns:
tags_q[col] = pd.Categorical(tag[col].astype("int16"), categories=category)
tag_onehot_q = pd.get_dummies(tags_q)
kmeans = KMeans(20, random_state=0).fit(tag_onehot_q)
questions_df["tag_cluster"] = kmeans.labels_
train_df["tag_cluster"] = train_df.content_id.map(questions_df["tag_cluster"])
このクラスタを追加しただけではさほど性能は向上しませんでしたが、さらに一工夫をくわえ、「ユーザーが過去にそのクラスタの問題を解いた回数」という形にしてやると、性能向上が見られました。
3. 仮説を立てる
最も重要なのは、データから仮説を立て、「この特徴量が有効ではないか?」と推測することです。以下、この例もあげてみましょう。
これはデータを眺めていて気づいたのですが、おそらくこのサービスには、初級者用の問題と上級者用の問題があるのではないでしょうか。つまり、はじめたばかりのユーザーには簡単な問題を出し、慣れたユーザーにはより難しい問題を出しているのではないでしょうか。
そうなると、単に問題の難易度を見るだけではなく、「これは上級者向けの問題なのか?」というのを見た方が良さそうです。というのは、仮に難しい問題だったとしても、そもそも上級者にしか出題されない問題であれば、それによって正答率が上がるはずだからです。上級者向けの問題を初級者に出せば正答率は低くなり、初級者向けの問題を上級者に出せば正答率が高くなるという傾向もありそうです。
そこで、上級者向け問題かどうかの目安として以下のような特徴量を作ってみます。
- 問題を解いた時点でのユーザーの累積経過時間と、累積正答数を計算。
- 問題IDごとにユーザーの累積経過時間、累積正答数を平均。
累積経過時間、累積正答数の平均値が高いということは、ユーザーの学習コースの後半に出てくる問題(つまり上級者向けの問題)になるというわけです。そこで累積経過時間の平均値を問題別に集計し、分布を見てみると、下記のような偏りが見られます。中級向けと思われる問題が一番多いですが、平均経過時間が明らかに小さいものや、明らかに多いものも存在しているようです。
(x軸が平均経過時間、y軸は個数です)
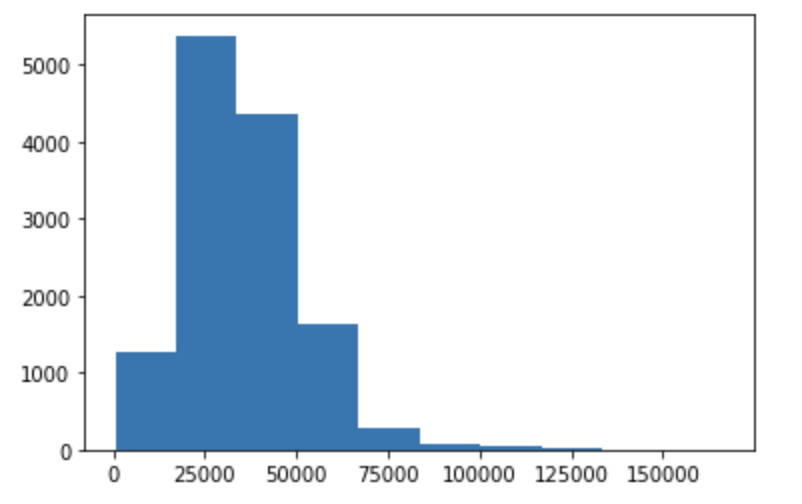
単にユーザーの平均経過時間の分布を反映している可能性もあるので念のためユーザーの平均経過時間の分布も出してみます。厳密な検証ではありませんが、分布を見ると、ユーザーの方は初級者がもっとも多いので、やはり問題の出現傾向に偏りがあるようです。
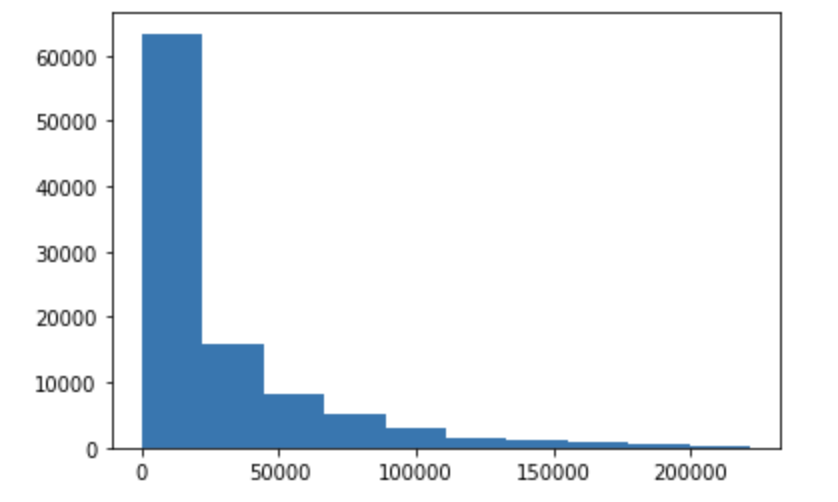
この仮説はある程度当っていたようで、この特徴量を追加することで性能向上が見られました。
まとめ
Kaggleコンペでの特徴量エンジニアリングの実例を紹介しました。興味をもった方はぜひ自分でもコンペにチャレンジするなどしてみてください。