はじめに
この記事は、Stable DiffusionのClassifier Free Guidance(以下、CFG)の簡単な仕組みの説明記事です。
対象読者
- Stable Diffusionで普段あまりよくわからず設定しているCFG Scaleが何なのか理解を深めたい人(AI絵師)
- CFGまわりの実装を見て良くわからなくて疑問に思っている人
- Stable Diffusionの大まかな仕組み(UNetやVAE、ノイズを予測して徐々にノイズを除去していくdiffusion process)は知っている前提
CFG 概要
CFG Scale はプロンプトの規制力を表現している。数値を大きくすれば、プロンプトを無視した出力が減るが、出力画像がおかしくなることも多い。
上げれば上げるほどプロンプトの影響が強くなる。下げれば下げるほど絵がぼやけるが、全体の絵幅が自由度広がる。
一般にプロンプトが長すぎて上手く出力されないときは CFG Scale を下げた方が良いとされている。
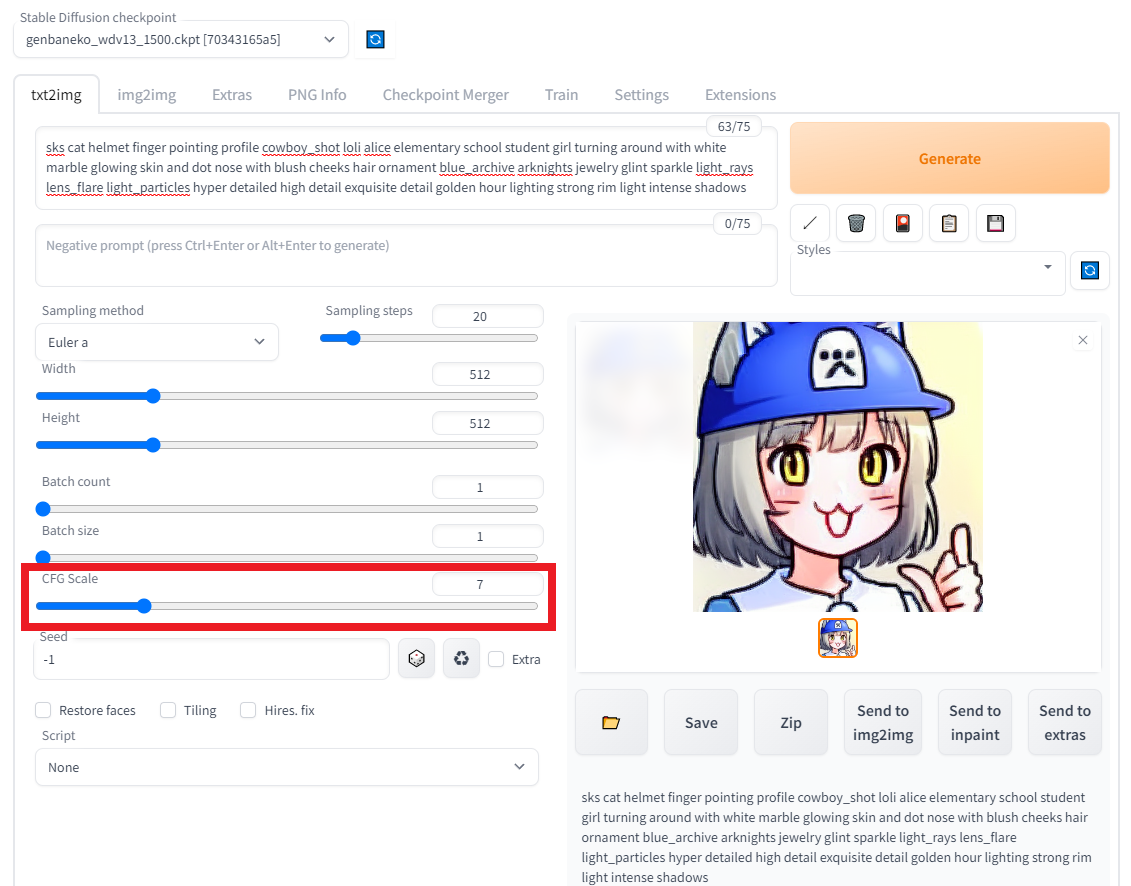
Stable Diffusion webui画面では以下赤枠で指定し、default値は7。
CFG の簡単な仕組みの説明
Stable Diffusion のモデル概要図

[2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models より引用
この図だけ見るとUNetにはVAEのDecoderで圧縮したLatent情報が $ Z_T $ として入ってくるように見える。
diffuserの実装のコードを見ると、実際には以下の通りdo_classifier_free_guidanceが真、つまりCFGを使う基本全てのケースにおいてtorch.cat([latents] * 2)とlatentsの配列を複製合体して2倍のサイズにしたのちにUNetに突っ込んでいる。
# 7. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py#L602-L624 該当コード部分
そして、UNetからの出力はnoise_pred_uncond, noise_pred_textの二つに分割して、この二つの差分にCFG Scaleを掛けたものを足した値を除去すべきノイズとして予測している。
ぱっと見ただけだと一体何をしているのかがわからない。CFGの仕組みの理解が必要なのだが、辿りついたこちらの説明が絵一枚でまとまっていてとてもわかりやすい!
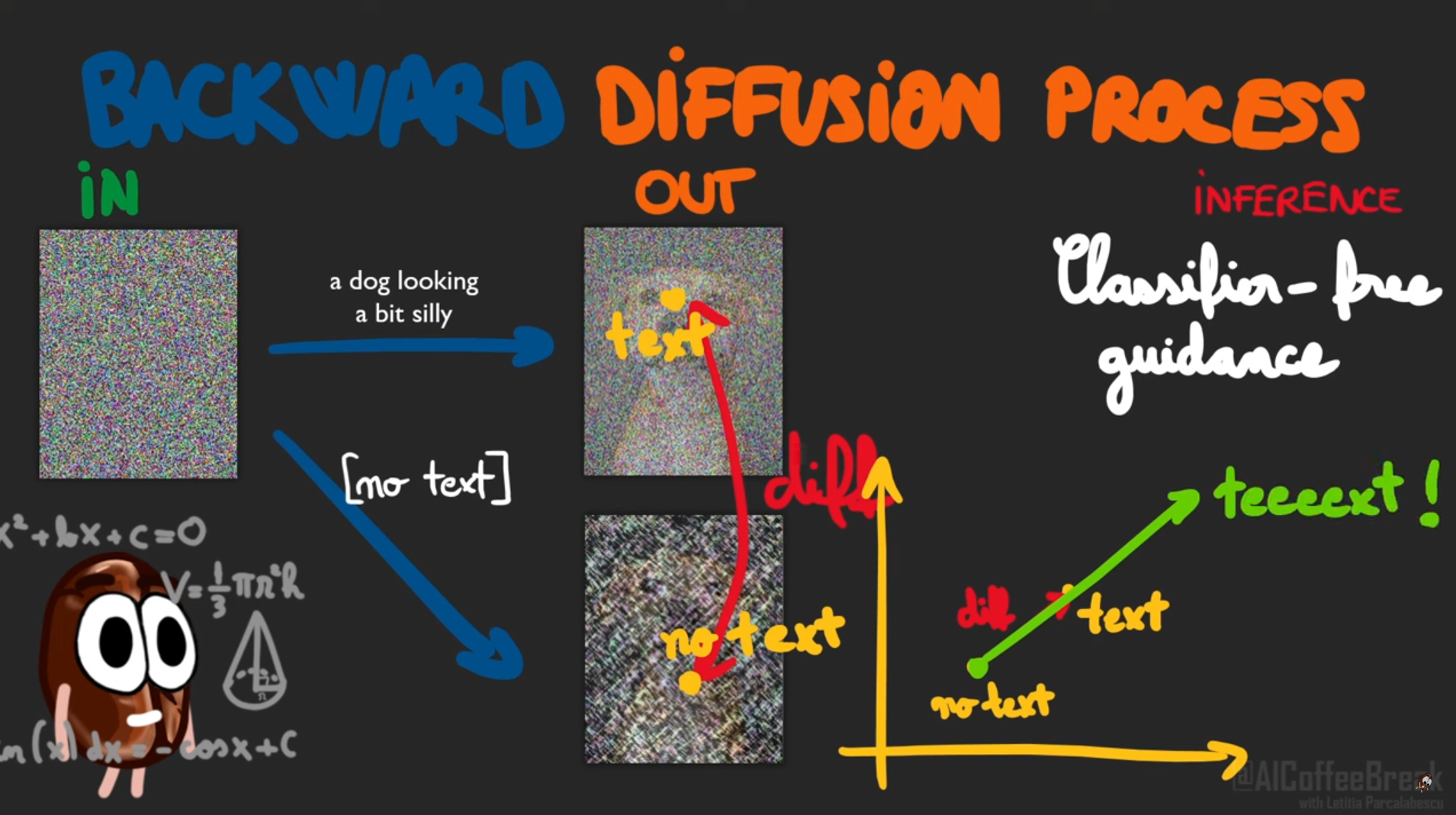
Diffusion models explained. How does OpenAI's GLIDE work? - YouTube より引用
つまり、promptを入力したUNetの出力と、promptを入力しないUNetの出力、二つのUNetの出力から差分をpromptを強調する方向のベクトルとして算出し、CFG Scaleを乗算してよりそのベクトル方向に強めることにより、プロンプトの規制力を表現して、上げれば上げるほどプロンプトの影響が強くなる仕組みを実現している。
様々な CFG での出力例
最後にCFGの値を変えて画像を生成してみて、どう変化するかを確認。

使用したモデルは sd-dreambooth-library/gemba-cat · Hugging Face
終わりに
でも、結局、何故CFGの値が7あたりが良いのかが良くわからないです。やっぱりいろんな人が言ってるようにここはweirdです。
結局、文字通り「CFG、ちょっとだけわかる」状態にしかなってないです。
ここからは雑談です。使用モデルは、dreamboothが出たばかりのころにWD1.3ベースでお試しで現場猫を学習させて使う機会がなく放置していたモデルです。やっと、陽の目をみました(使ってあげて供養)。しかし、もはやこのクオリティじゃまるで戦えないぐらい3カ月で世界は進化してしまいました。本当に進化早いですね!
またね
