はじめに
簡単なゲーム実況AIを作ってみたのでチュートリアル記事として記事化しました。
(と言ってもいろいろつないだだけで大したことはやってません)
人間ではなく中身がAIのyoutuber/vtuberをAITuberと呼ぶそうなので以下、一応AITuberと呼びます。
作ったAITuberプロトタイプのデモ動画を作ったので、言葉で説明するより先にそちらを見てもらうと、何がチュートリアルで作れるのかイメージしやすいと思います。

動画は時間がかかるので見ないという人向けには、こんなの作れないかなと思って一番最初に作りはじめる前に検討で作ったモックイメージ動画(20秒)だけ見るでも良いと思います。
ゲーム実況AITuberのモックイメージをymm4liteで作ってみました。イメージだけなのでAI使ってないです。裏側でrinnaのマルチモーダルチャットモデル使う形で、簡単なものだったら実装できそうな気はするんですよね。(しゃちくさんのずんだもんlive2dモデル、クオリティ高くてすごいです) pic.twitter.com/8RK9fOgwi1
— inada (@dev_inada) August 1, 2023
ゴール
上記で記載したリアルタイムで簡単なゲーム実況をするAITuberが作れるようになります。
デモ動画とは見た目が違ったり、カメラやVRM等の依存部分を除外した部分がありますが、基本的にはこのプロトタイプ動画の機能が動きます(プロトタイプと違う点は以下の記事の範囲に記載)。
記事のスコープ
想定対象読者
- 自分のローカルPCで動作するAITuber/ゲーム実況AITuberの制作に興味がある人
- マルチモーダルに興味があるので、少し手を動かして理解を深めたい人
- gitやpython、pythonのvirtual環境構築(pyenv, venv) 、cudaのセットアップの知識は必要です。このあたりはググったりジピったりすれば何とかなると思います
この記事の範囲/対象外
- ゲームは人間がプレイする前提で、AITuberはゲームのプレイはしません
- 表情はVRMモデルに依存するところが多いので標準(preset)の表情に限定し、最初は機能をオフにしてあります
- LLM学習/finetuneはこの記事の対象外(対象外といいつつLoRAにも簡単に対応できるようにしてあります。学習手順自体も簡単で記事リンクは最後に載せてあります)
- 実際の配信にはcapture deviceとの接続や、動画の重畳ツール(obs studio等)の使い方の知識が別途必要です
- camera capture (個人の環境に依存する部分なので対象外)
- obs (配信動画作成はその道の専門家がいっぱいいらっしゃって、良い記事や動画があるのでここでは扱いません)
前提(動作環境)
- この記事ではrinna株式会社様が公開しているrinna/bilingual-gpt-neox-4bを使用します。
- VRAM12GB以上のグラボ搭載のローカルPC
- メモリは16G以上(で多分大丈夫)
- 動作確認環境
- ubuntu環境(wsl可) (windows環境ではこの手順では動かないところがあります。windowsで動かすやり方はググったりジピったりして頑張るといけるとは思います)
- python 3.10.8
- cuda 11.8
簡単な仕組みの説明
動画から定期的に画像を抽出し、画像の状況説明をマルチモーダルモデルにさせてアバターにしゃべらせているだけです。
システム構成
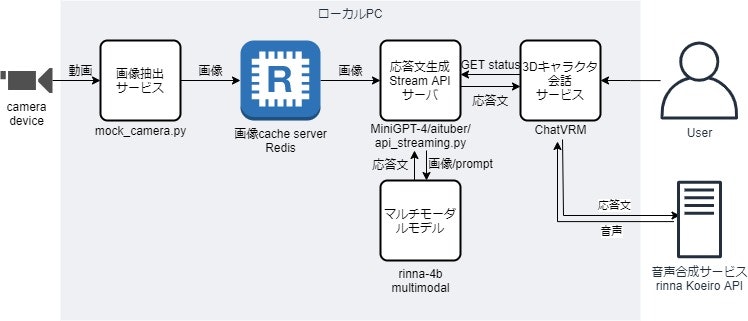
ChatGPTは使わず、音声合成(TTS)以外は全てローカルで処理 (音声合成のみkoeiro APIを使用)
構成要素
- カメラから画像を抽出する簡単なプログラム
- 画像に写っているものを認識して応答文を返すAI(マルチモーダルモデル)
- 3Dキャラクター会話UI (キャラクターリップシンク/音声認識/音声合成)
マルチモーダルモデルの背景知識
この節は読み飛ばしても良いです。
rinna-4b マルチモーダルモデルは、BLIP2、Mini-GPT4というマルチモーダルモデルが元になっている。
MiniGPT-4のモデル構造 (https://arxiv.org/abs/2304.10592)
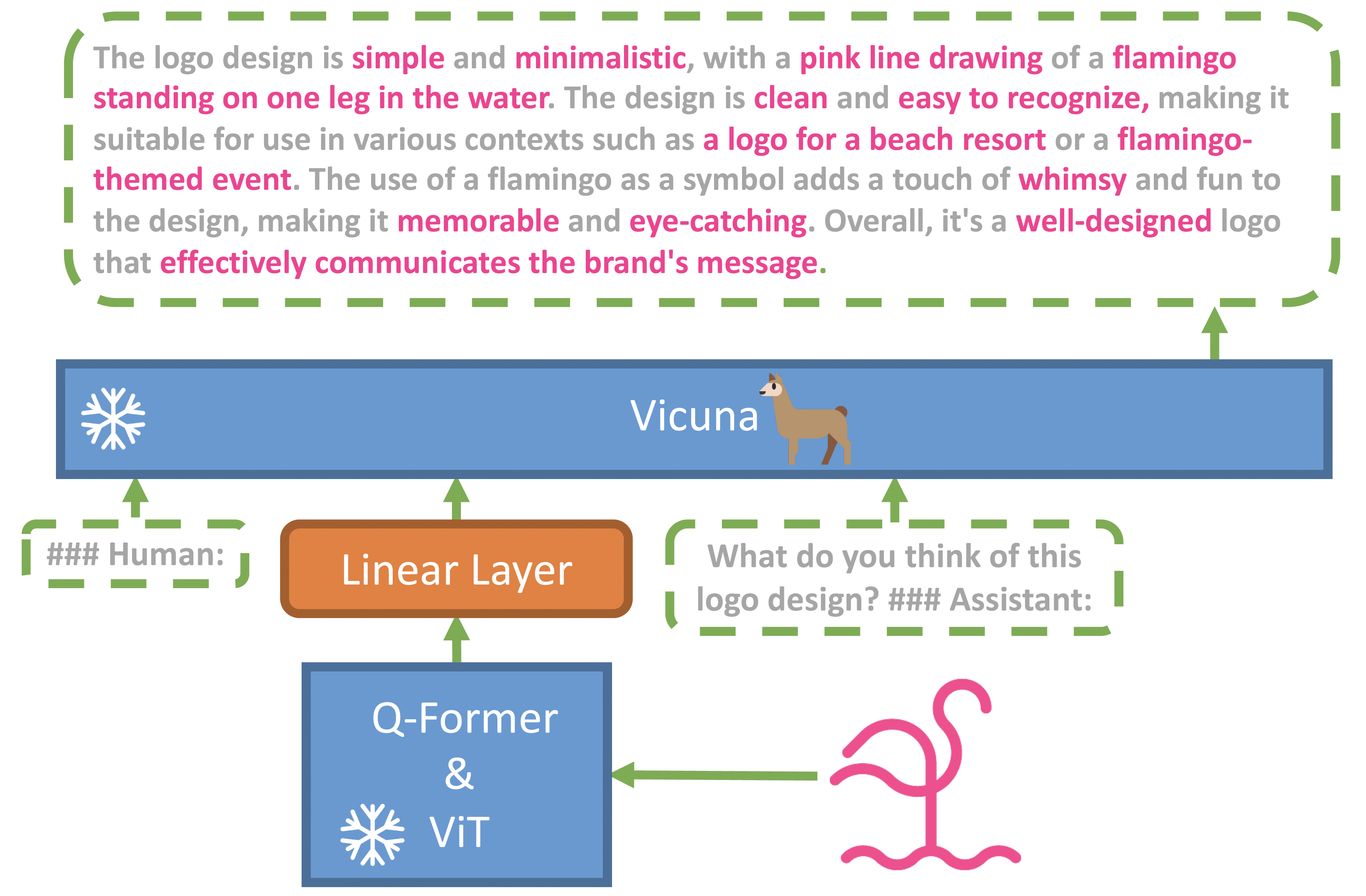
| モジュール | 簡単な説明 |
|---|---|
| ViT | transformerベースの画像認識モデル |
| Q-Former | 画像の特徴量をLLMの入力特徴量に変換するモデル |
| LLM | 大規模言語モデル |
| モデル | 構成 |
|---|---|
| BLIP2 | ViT + Q-Former + LLM(FlanT5 or OPT) |
| Mini-GPT4 | ViT + Q-Former + LLM(Vicuna) |
| rinna-4b マルチモーダルモデル | ViT + Q-Former + LLM(rinna/bilingual-gpt-neox-4b) |
この構成のマルチモーダルモデルは、いずれもViTとLLMの重みは固定してQ-Formerのみ学習。
Q-Formerが画像の特徴を直接各々のLLMが理解できるようにしている。
(でいいのかな?)
さらに理解を深めたい場合は、まずはrinnaさんのブログのこの記事を読み込むのが良いです。
Japanese MiniGPT-4: rinna 3.6bとBLIP-2を組み合わせてマルチモーダルチャットのモデルを作る
手順
概要
- 必要モジュールのインストール
- webuiを起動してモデルが動くことを確認する
- 簡単なAITuberを動かす
- 画像キャッシュ用サーバを起動する
- 画像を見て応答文生成を行うStreaming APIサーバを起動する
- 動画streamを画像キャッシュサーバに接続
- AITuberのアバターをChatVRMで起動する
必要モジュールのインストール
git clone https://github.com/takaaki-inada/rinna-4b-multimodal-hello-aituber.git
cd rinna-4b-multimodal-hello-aituber
python -m venv .venv
source .venv/bin/activate # windows環境だと既にここから手順違います
pip install --upgrade pip setuptools
pip install -r MiniGPT-4/aituber/requirements.txt
wget -O MiniGPT-4/checkpoint.pth https://huggingface.co/rinna/bilingual-gpt-neox-4b-minigpt4/resolve/main/checkpoint.pth
sudo apt install redis-server
表情をつける場合に必要なモジュールをインストールする手順
ここは参考程度に記載。このインストール手順は環境依存するため、あくまで自力でお試しが出来る人向け(表情機能は最初はオフ状態)。この手順はスキップでOK。
sudo apt install mecab libmecab-dev mecab-ipadic-utf8
pip install mecab-python3
pip install pymlask
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
cd mecab-ipadic-neologd
./bin/install-mecab-ipadic-neologd -n -y
cd ..
webuiを起動してモデルが動くことを確認する
セットアップがうまく出来たか確認のために初回だけ実行する手順(モデルを微調整した場合の確認等にも利用でき便利)
cd MiniGPT-4
python aituber/app_streaming.py
webuiを起動。画像をUploadし、画像の質問をしてそれらしい答えが返ってくればOK。
簡単なAITuberを動かす
画像キャッシュ用サーバを起動する
sudo systemctl start redis-server
# # wsl環境でsystemctlを入れてない場合は、上記に代えて単純にコマンドライン起動でもOK
# redis-server
# # docker派の人は、上記に代えて以下でもOK
# docker run -p 6379:6379 -it redis/redis-stack:latest
画像を見て応答文生成を行うStreaming APIサーバを起動する
# ルートディレクトリにいる場合の手順
cd MiniGPT-4
uvicorn aituber.api_streaming:app --reload --port 8000 --workers 1 --ws-max-size 1
動画streamを画像キャッシュサーバに接続
videoまわりは製品や動かすPC環境にもよるため、ここでは単純に動画ファイルを再生して画像キャッシュサーバにプールする簡単なプログラムを実行
# ルートディレクトリで実行
python mock_camera.py
AITuberのアバターをChatVRMで起動する
# ルートディレクトリにいる場合の手順
cd ChatVRM
npm install
npm run dev
koeiro APIキーを取得して入力すると、アバターと見た目は異なりますがサンプル動画ファイルの実況が始まります。
videocaptureデバイスにつないで画像抽出サービスのプログラムをvideocapture入力に書き換え、obs studio等でゲーム画面とChatVRMの画面を重畳すると以下のようなリアルタイムゲーム実況画面が作れます。
ゲーム実況ずんだもんAITuberプロトv0.1(簡易表情実装)
— inada (@dev_inada) August 13, 2023
ゼルダの伝説で楽団員を川向うに運ぶ仕事が雑すぎるリンク#rinna4b #LMM #マルチモーダル #AITuber #ずんだもん pic.twitter.com/8vOUxi6Ivk
自力でお試しできる人向け
表情
機能自体は以下でオン。mecabのセットアップが完了している必要がある。使うVRMモデルが表情をどう実装しているかに強く依存。
また、ChatVRMの実装がkoeiroの音声APIを実行してないと(実行エラーだと)VRMの表情の設定を行わない(と思われる)
MiniGPT-4/aituber/app_streaming.py
26行目
is_use_expression = True
LLM学習
LLM部分を学習させる手順は前回の記事「ローカルで動く大規模言語モデル(Rinna-3.6B)を使ってあなただけのAIパートナーを作ろう - Qiita」とほぼ同じ。Rinna-3.6Bではなくrinna/bilingual-gpt-neox-4bでLoRAを作る。自力でお試しが出来る人なら簡単に出来るハズ。
出来たLoRAを適用する (パスを指定するだけ)
MiniGPT-4/aituber/app_streaming.py
46行目
model = CustomizedMiniGPT4(gpt_neox_model="rinna/bilingual-gpt-neox-4b", low_resource=True, lora_model="ここにLoRAのパスを書く")
おわりに
- マルチモーダルはまだこれからどんどん発展していく分野
- 画像と言語モデルの組み合わせになって大きなモデルになるので、おうちのPCでマルチモーダルモデルが動くのは感慨深い
- やってみて感じた課題
- AIがしゃべってる間に状況は刻一刻と変わっているので、どうしても無理はある。
- AIが自分の知らないゲームや小説等の話を話し始めて、全然興味がなくて話がつまらない時がある。
- 画像の認識能力もそれ程悪くはないけど、まだまだこれから。
- 素のrinna-4bは一度話した会話の内容をシステムが繰り返す傾向があるように思う。会話内容に対して質問しても、全然後からした質問に答えてくれないことがある。これはAIに無視されているような印象を受けるのでユーザ体験的に苦しい(ここは、ちゃんとしたデータでしっかりとしたinstruct tuningを試してみたい)。
- おもしろいと思える実況は1時間のうち1分か2分程度で、まだまだ打率が低い。
- 刻一刻と状況を把握し、番組的に面白いことを考えて言える人間の能力は、改めてすごいと思った
- 画像認識の能力向上は必須だけど、これに加えて、複数フレームからのmotion認識, tracking 等組み合わせていくと認識能力高くなっていって、お?すごくないって言えるところまでいける・・・かも?
参考リンク
モデル
技術詳細
MiniGPT-4論文
Japanese MiniGPT-4: rinna 3.6bとBLIP-2を組み合わせてマルチモーダルチャットのモデルを作る
LLM学習
ローカルで動く大規模言語モデル(Rinna-3.6B)を使ってあなただけのAIパートナーを作ろう - Qiita
ずんだもん
東北ずん子・ずんだもんPJ 公式HP
ずんだもん(人型)公式MMDモデル、VRM、VRChatアバター - 東北ずん子ショップ【公式】 - BOOTH
【ぬるぬる動くずんだもん】立ち絵に使えるLive2D / Vtuberモデル / しゃちく さんのイラスト - ニコニコ静画 (イラスト)