はじめに
Kaggle M5 Forecasting - Accuracy コンペ 59th (of 5558) の解法まとめ。
私の学習環境は少しメモリ積んだだけのごく普通のPC環境 メモリ16G,CPUのみ(intel i5-3470 3.2GHz)
モデルはLGBMの単体モデルで、アンサンブルも無しです。パラメータチューニングもしていません。
何か特別なことをしたわけではなく、「kaggleで勝つデータ分析の技術」に書いてある通りのことを愚直にやっただけです。
自分でも、こんなので競合ひしめくテーブルコンペに上位入賞する?と驚いている次第です。
非常にシンプルなモデルですので共有する価値があるのかなと思い今回のコンペでやったことの共有と、
これからKaggleなどのデータ分析コンペ参加しようとしている方に何かのお役に立てればと思い考えたこと、実際にやったことを記録として残します。
コンペの概要
Walmartの商品の28日先までの売り上げ予測を行います。
対象の店舗はカリフォルニア(CA),テキサス(TX)、ウィスコンシン(WI)から計10店舗。
評価指標は単純な実際の売り上げと予測のRMSEではなく、WRMSSEという特殊な評価指標を使います。
WRMSSEの特徴
- 日々の売り上げ変化が激しい場合は予測のエラーが小さくなり、変化があまりない場合は予測のエラーが大きくなる
- ビジネス的な観点から直近28日の売り上げが大きいほうが重みが加重される (売り上げが0が続いている商品の売り上げ予測を頑張って精度あげてもあまりスコアに寄与しない)
- 単純な商品毎の売り上げ予測の誤差だけではなく、12種類のグループの合計の実際の売り上げと予測の誤差も総合的に加味される (店舗売り上げ合計、商品カテゴリ売り上げ合計、等)
データの特徴
上述の通り10店舗、商品は食品、hobby、householdの3つのカテゴリで商品数は3049、過去の売り上げデータとして与えられているのは約5年分のデータ
特徴量として与えられているのは、日付、曜日、event日、商品の売価、アメリカローカルのSNAPという食品クーポンが使える日かどうか、
何の商品名か具体的な名前はわかりません(七面鳥はthanksgivingの時売れるよねとかピンポイントの補正が単純にできない)
与えられている特徴量としてのデータは少ないかな、、、(これで予測するのちょっと無理じゃね?周期的な特徴ぐらいしかわからなくね?)と、個人的には思いました
有用だった公開notebook
Back to (predict) the future - Interactive M5 EDA
まずデータの概要を把握するにあたり、このnotebookを読むところからはいりました。
M5 - custom validation
次に公開されている手頃なモデルを動かすところからStudyをはじめました。最初に動かしたのがこのモデルです。
比較的軽量のモデルなのだと思いますが、私の手元のPCでこのモデルで全ての商品の学習に8時間かかったので、うげってなりました。
M5 - Simple FE
元のデータがそのままだとかなり大きいサイズのデータとなるため、pickle形式で使いやすく圧縮したデータセットが公開されていました。
基本このpickle形式をベースに自分でカスタマイズした特徴量を追加しました。
M5 - WRMSSE Evaluation Dashboard
WRMSSEを理解するうえで非常に助けになりました。このnotebookを元に自分のモデルの予測データのWRMSSE算出を行って確認したのと、少し改造して提出するデータ(evaluation)の売り上げを可視化して確認を行いました。
ただ、このnotebookとは別にコンペサイトに公式のWRMSSEの算出方法のPDFが掲載されているので、しっかり読みこむ必要があったと思います。
その他、有志のかたが日本語でコンペ概要のnotebookを公開されていたので、読んで理解の助けになりました。ありがとうございます。
戦略とmilestone
まず個人的な背景として、2019年において、Kaggle Expertになるというざっくりとした目標をたてていました。
ただ、実際は場当たり的にコンペに参加して入賞近いモデルにちょっと工夫をくわえてsubmitしただけのものが天罰をくらってことごとく入賞圏外になったので、その反省として、今年は順位とかではなく、まず年に3回ぐらいコンペに参加して定期的な活動としてもう少ししっかり取り組む、コンペから学ぶことが習慣化されているというところで、順位目標ではなく、ちゃんと参加した回数とそこから何かを得て自分のものとできたかを目標としました。
今回のコンペの戦略案として最初に大きく以下の戦略を考えました。
- 過去の類似コンペを勉強
- シンプルで本質的な特徴量の知見を得る、単独でもよい性能を誇るモデルの追求
- 公開notebookで入賞に近いモデル + 改善できる余地(特定のカテゴリの分布が変、外れ値が多い)のある予測を探して特化したモデルの予測で入れ替え (結局それやるんかい、、、いやまあ最後の手段ね)
この戦略を元に以下のmilestoneを設定しました。(実際には全部できたわけではなく、半分ぐらいしかできてないです)
-
過去類似コンペ調査 recruite restaurant
-
過去類似コンペ調査 Favorita Grocery Sales Forecasting (1st place)
-
過去類似コンペ調査 InstantMarketBasektAnalys
-
ゴールデンウイーク短期集中Handson(かける時間を決めて、データ理解、ミニマルデータセット作成、特徴量選定、特徴量評価用baseline作成、モデル作成、1st submission作成、ふりかえり実施)
-
データ統計/分布調査理解(全カラムの統計量、uniquness、top10、商品の相関、地域の相関、日にちの相関、、)
-
外れ値調査 (特定の商品、特定の日にち、)
-
trainとtestでデータがどれくらいデータが共通しているか調査
-
単独でシンプルで性能のよいモデルを作る
-
追加特徴量調査
-
predict精度検証 店舗/商品毎の外し度の数値化、可視化
-
28日分の予測個別モデル作成
-
ルールベースの欠品予測の作成 (sales=0埋めの後処理作成)
-
1カ月前上位baseline調査(主に改善できそうなところの目星をつける)
-
1週間前上位baseline調査(主に改善できそうなところの目星をつける)
-
discussion/notebookを定期的に見て、取り入れられそうなアイデアは試す、取り入れる、改善活動
特徴量
M5 - Custom features
この特徴量は使いませんでした。
M5 - Simple FE
ここに以下の特徴量を追加しました。
- 休前日
- 休日の翌日
- 予測対象日から28日前までの売り上げ(lag特徴量)
- 予測対象日から7日、14日、30日、60日の売り上げのsum,min,max,mean
- 予測対象日から7日おきに遡って4週間の売り上げの平均 (曜日の傾向をとらえる)
- 予測対象日から7日おきに遡って8週間の売り上げの平均 (曜日の傾向をとらえる)
- 予測対象日から7日おきに遡って12週間の売り上げの平均 (曜日の傾向をとらえる)
log1pは使っていません
え?これだけ?・・・です。
特徴量の寄与度としてmaxが効いているのが不思議な感じです
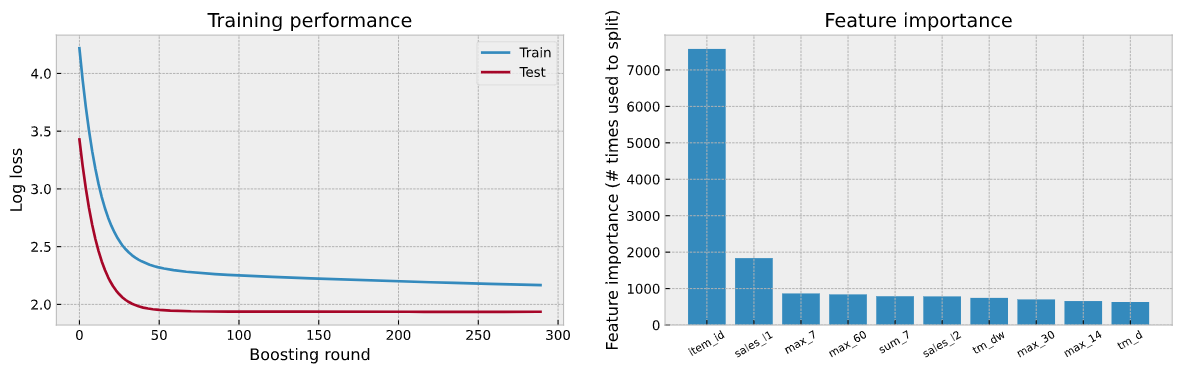
データとモデル
メモリにのらないという安直な理由で、3月~6月のデータと、2016年のデータのみを学習データとしています。
これまたメモリにのらないという理由で、食品、hobby、householdのデータに分割してモデル学習しています。
また、モデルは予測日付毎28日分、さらに食品、hobby、householdで、28x3=84モデル作成しています。
最終的に提出するための学習データとしては、直前までのすべてのデータを使っています。
個別改善対応
漸次的な売り上げ増加対応
売り場面積の増床や人口の増加等の影響か、マクロ的な売り上げは少しづつ増えていくので、どこかのdiscussionに最終的な予測に1.02~1.05掛けると良いよと書いてあった。
私のモデルの特徴量はlag特徴量が主体なので、これあんまりやっても意味なさそうなので、念のため、実際に提出する売り上げ予測を過去のデータとつなげて可視化してみても、特に補正が必要なさそうだったのでやらず。
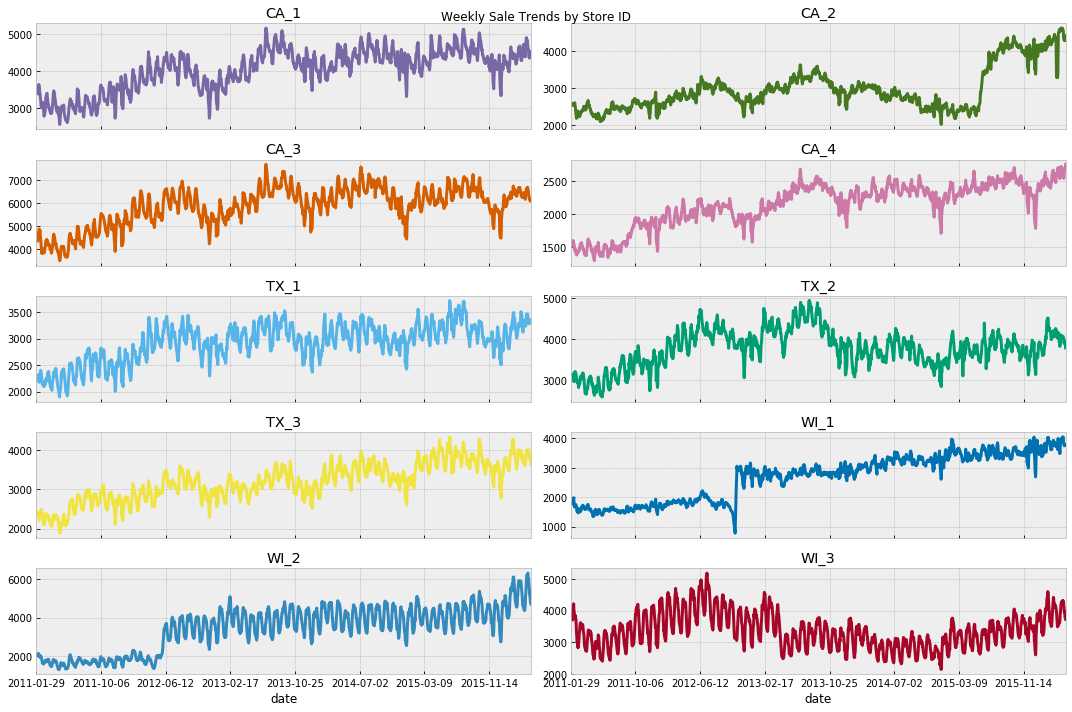
提出した売り上げ予測
TX 洪水情報
気象データを特徴量として追加する是非について議論されていました。(予測する期間を含む外部データは使ってはいけないレギュレーションがあります)
5/22-6/25にTexasで洪水(Severe Storms And Flooding)がおきていて、予測する期間は5/23-6/19で、5/22時点で判明している事象は使っていいよねという話を誰か書いてました。
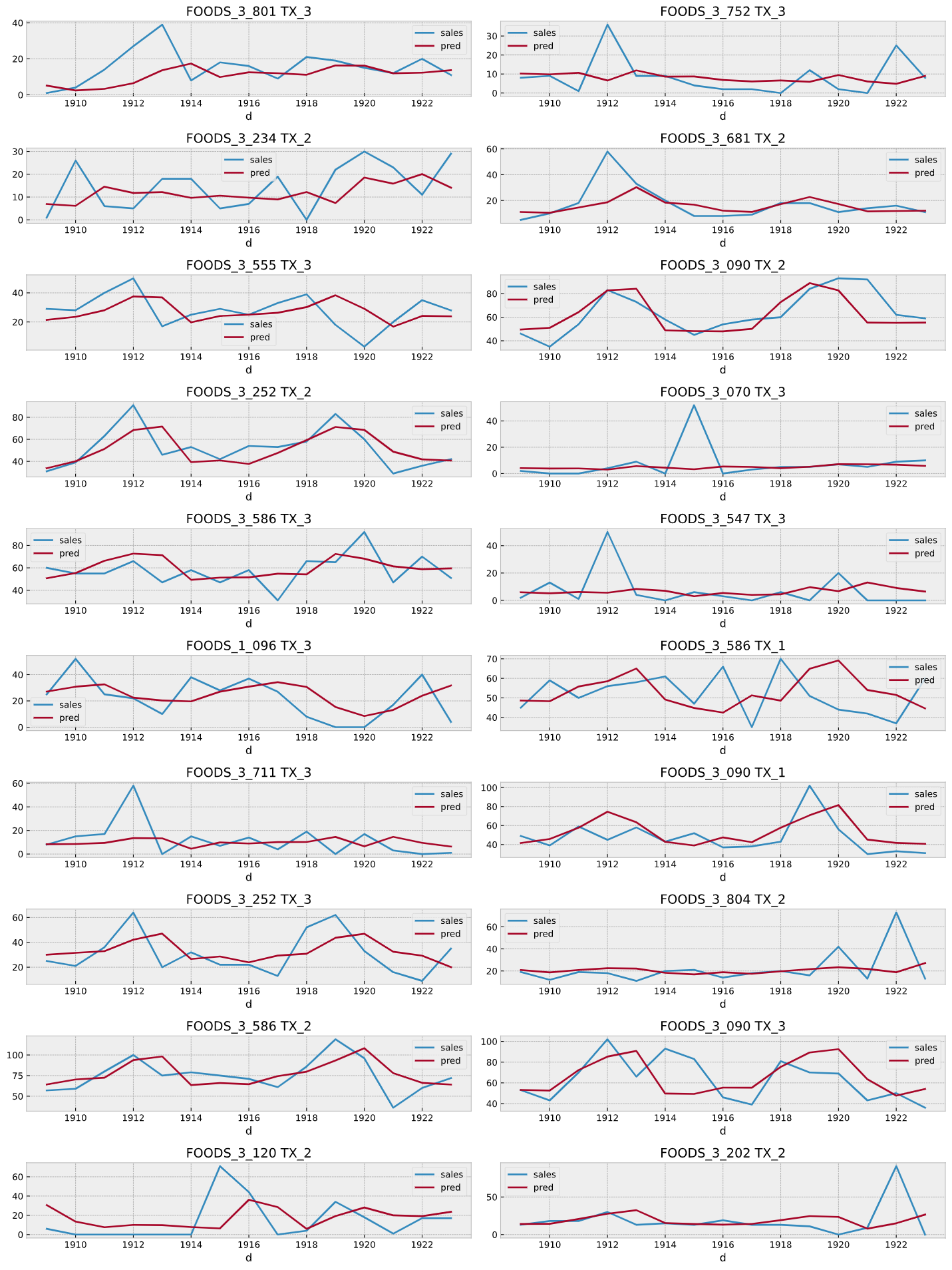
4/17-5/1(d1909-1923)も同じくTexasで洪水情報が出ていたので、4/17-5/1のTexasのデータを除外して学習したのち、4/17-5/1のTexasのデータを予測し、実際の売り上げとRMSEをとって誤差の大きいものを可視化してにらめっこしましたが、洪水の影響と思しきものはみられなかったので、この予測対象のTexasの3店舗は洪水とは無縁の立地の良い場所なのだろうと割り切り、洪水情報を特徴量に加えることはしませんでしした。
4/17-5/1のTexasのデータのうち予測誤差の大きいもの
欠品予想
欠品しているものはそもそも売り上げ0だよねということで、10店舗全部、または9店舗で予測前日時点で売り上げ0が続いている商品を抽出するルールベースの処理を作成しました。
ただ、WRMSSEの特徴として売り上げが0が続いているものは重みが軽くなり、やみくもに売り上げ0を適用してもスコアさがったのと、実際にどの時点まで欠品しているかを予測はできないので、切り札にはできませんでした。
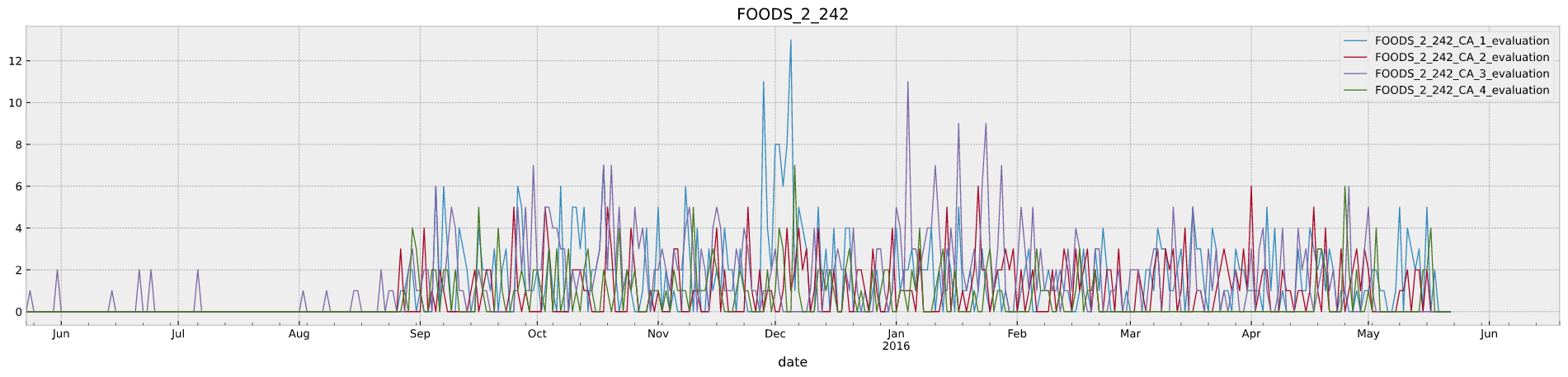
いくつか欠品臭そうなのがありましたが、FOODS_2_242は欠品と判断して、sales=0埋めしてsubmission作成しました。
この後処理でscoreは 0.58026 -> 0.57987 と若干改善したようです。
ふりかえりと感想
本当にやったことはこれだけです。初めに書いた通り、モデルはLGBMの単体モデルで、アンサンブルも無しです。パラメータチューニングもしていません。
外れ値除去もしてませんし、その他データの前処理もしてないです。
機械学習コンペって、ある意味運ゲー的なところがあって麻雀に例えらえますが、あがったら、対対三暗刻じゃなくて、おい、それ四暗刻や、これやから素人はーっ!え、なんか手配シンプルやったんですー、みたいな感じになってますね。ごめんなさい。
よかったこと
- シンプルなモデルにできたこと。
- 早い段階でまとまって時間をとったこと。
GWに2日会社休んで、家族には仕事している体で、実際には2日まるまるコンペのstudyにあてました。ざっくりしたデータ分析から、モデルを学習させて、1st submissionまでを一通りやってしまおう、というのを目標にしましたが、学習に8時間かかることが判明したため、1st submissionまではいきませんでした。
ただ、まとまって時間をとってコンペの理解にあてることの大事さを痛感しました。GW、夏休み、正月近辺はチャンスですね。思い返せば2年前に初入賞した時もGWにがっつりPCで学習させていましたし。 - 時系列予測の分野で、データ分析から、使いやすいデータセットの作成、ミニマルデータセットの切り出しとbaselineの作成、学習、予測の可視化 まで薄いところはあるが一通りの自分なりの知見を蓄えることができた
- 「kaggleで勝つデータ分析の技術」の通りやってもみんながやっているから勝てない、、、となる前に、何とか本の効果が効いてるうちに入賞することができた
- 何はともあれ、これでKaggle Expert牧場へ入牧です。
改善したいこと/次に取り組みたいこと
- とにかくメモリが足りなくなってPCが固まる。PC固まるたびにメンタルじわりやられる。もっと評価を早くまわすための、ミニマルセットをうまく作るスキルをみがかないと。
- さらに何を特徴量追加していいのかわからない。もっと幅広く勉強というかステップアップが必要と実感
- 学習データとしてどの期間を使うかは、今回のように勘とえいやじゃなくて、なぜその期間を使うのか理由を説明できるように。testデータセットの期間の特徴をよくとらまえたものを学習データとして使うようにする。
- DFT(離散フーリエ変換)とか、そもそもどういうものかしっかり理解して、周期傾向をつかむ特徴量としてうまく使えるか判断できるようになりたい・・・
その他
こんな内容で良ければ、せっかくなのでどこかでLTで10分ぐらいさらーっとお話してみたい気がしています。
会社外で話したことがないので、修行がてら経験を積んでみたいです。
自分でも場がないか探してみようかとは思いますが、需要あればお気軽にお声がけください~(^^/