Koalas 1.0 Introduction, Overview and Quick How-to Guide - The Databricks Blogの翻訳です。
2020/6時点の記事です。
Koalasは、pandasを使っているデータサイエンティストがお使いのコードを大幅に変更することなしに、Apache SparkTM上で既存のビッグデータワークロードをスケールできるようにするために昨年(2019年)リリースされました。このSpark + AI Summit2020の場で、Koalas 1.0のリリースを発表しました。今やKoalasはpandasの全APIの80%を網羅しており、頻繁に使用されているpandas APIを実装しています。さらに、KoalasはApache Spark 3.0、Python 3.8、Sparkのアクセサー、新たな型ヒント、優れたインプレースのオペレーションをサポートしています。この記事では、1.0リリースにおける特筆すべき新機能、開発中の機能、現在のステータスをご説明します。
急速な成長、開発
オープンソースKoalasプロジェクトは急激に進化しました。立ち上げ時は、Koalasんびおけるpandas APIのカバレッジは約10%-20%でした。コミュニティによる弛まぬ開発、頻繁なリリースを通じて、pandas APIのカバレッジは急激に増加し、今では80%近くがKoalasでカバーされています。
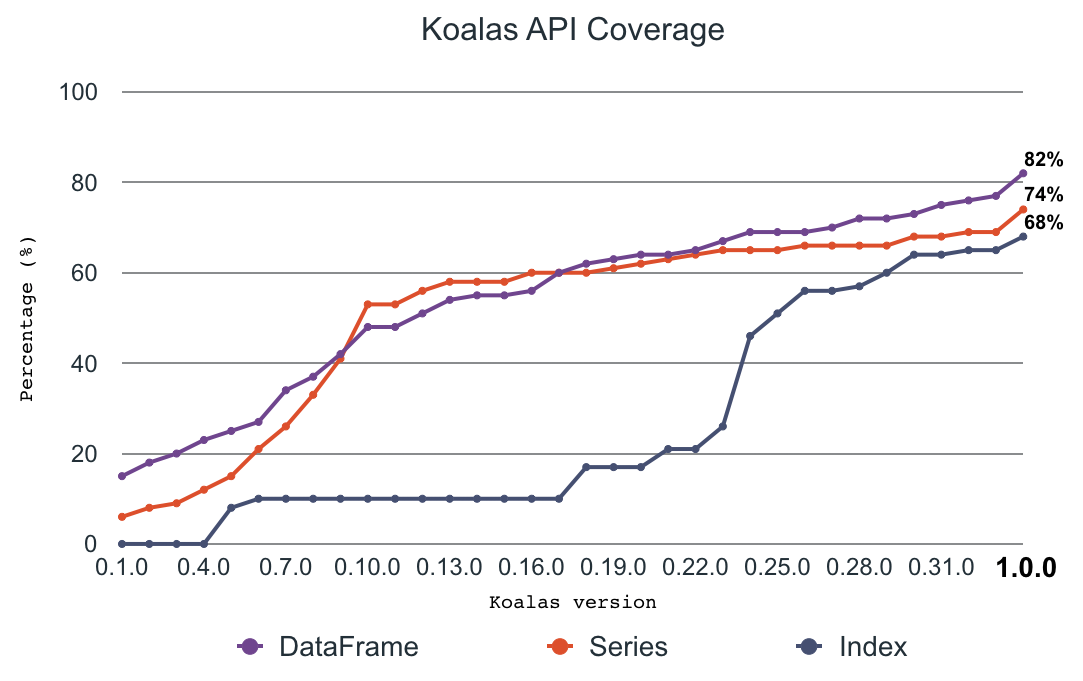
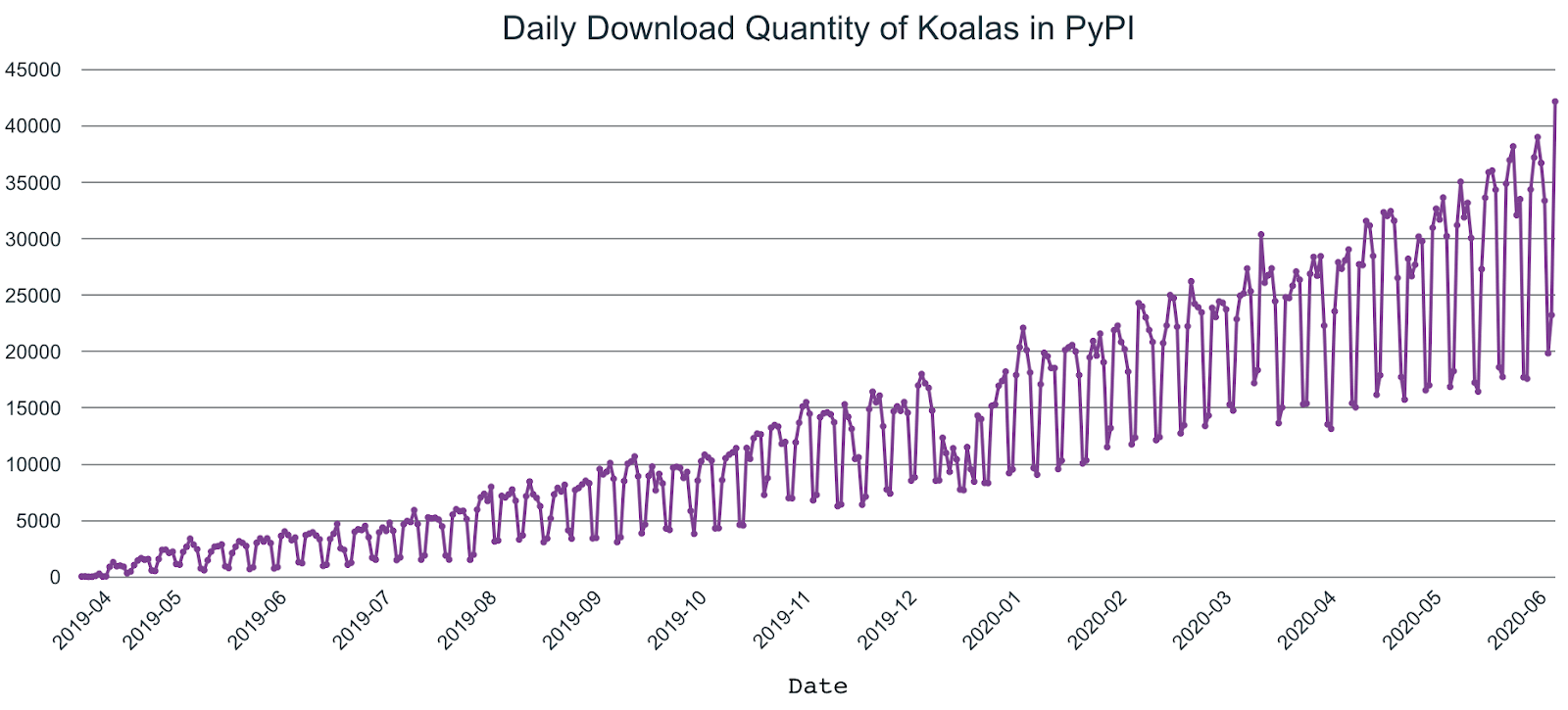
さらに、最初のアナウンス以降、Koalasのユーザーは急激に増加しており、PySparkダウンロードの1/5となっており、おおよそPySparkユーザーの20%がKoalasを使っていることが伺えます。
pandas APIカバレッジの拡大
Koalasは広く使われているAPI、プロット、グルーピング、ウィンドウ処理、I/O、変換などpandaの機能のほとんどを実装しています。
さらに、transform_batchやapply_batchのようなKoalas APIは直接pandas APIを活用しているので、Koalas 1.0.0においては、ほとんどのpandasのワークロードは最小限の変更でKoalasのワークロードに変換することができます。
Apache Spark 3.0、Python 3.8、pandas 1.0
Koalas 1.0.0はApache Spark 3.0をサポートしています。Koalasのユーザーは、ほとんど変更なしにSparkのバージョンを切り替えることができます。Apache Spark 3.0では3,400以上の修正が行われており、Koalasユーザーも多くのオンポーネントでこの修正の恩恵を受けることができます。ブログ記事、Introducing Apache Spark 3.0もご一読ください。
Apache Spark 3.0によって、Koalasは多くの改善がなされた最新のPython 3.8バージョンをサポートします。改善内容はPython 3.8.0のリリースノートで確認することができます。Koalasは、pandasと同様にデータフレームに対してネイティブのPythonコードを実行できるように数多くのAPIを公開しており、Python 3.8のサポートによってメリットを享受することができます。さらに、KoalasはPythonで重点的に開発が進んでいるPythonの型ヒントを積極的に活用しています。Koalasにおけるいくつかの型ヒントの機能は、最新のPythonバージョンでのみ利用できます。
Koalas 1.0.0のゴールの一つは、最新のpandasリリースを追跡し、pandas 1.0のAPIのほとんどをカバーするというものです。APIの変更、廃止に追従することに加え、APIのカバレッジは計測され、改善されています。Koalasでは、Koalasの依存関係として、最新のpansaバージョンをサポートしているので、最新のpandasバージョンを利用しているユーザーは容易にKoalasに移行することができます。
Sparkアクセサー
Koalasユーザーが既存のPySpark APIをより簡単に利用できるように、SparkアクセサーはKoalas 1.0.0で導入されました。例えば、以下のようにしてPySpark関数のapplyを実行することができます。
import databricks.koalas as ks
import pyspark.sql.functions as F
kss = ks.Series([1, 2, 3, 4])
kss.spark.apply(lambda s: F.collect_list(s))
Series.spark.transformを用いることで、KoalasのシリーズをPySparkのcolumnに変換することも可能です。
from databricks import koalas as ks
df = ks.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]})
df.a.spark.transform(lambda c: c + df.b.spark.column)
Sparkアクセサーで、データフレームのキャッシュのようなPySparkの機能を利用することができます。
from databricks import koalas as ks
df = ks.DataFrame([(.2, .3), (.0, .6), (.6, .0), (.2, .1)])
df = df.transform(lambda x: x + 1) # transform Koalas DataFrame
with df.spark.cache() as cached_df:
# Transformed Koalas DataFrame is cached,
# and it only requires to transform once even
# when you trigger multiple executions.
print(cached_df.count())
print(cached_df.to_pandas())
性能の改善
Koalas APIの多くは、内部でpandasのUDF(ユーザー定義関数)を活用しています。DataFrame.apply(func)やDataFrame.apply_batch(func)のような新たなpandasのUDFは、Koalasが性能を改善するために内部で利用するApache Spark 3.0で導入されました。
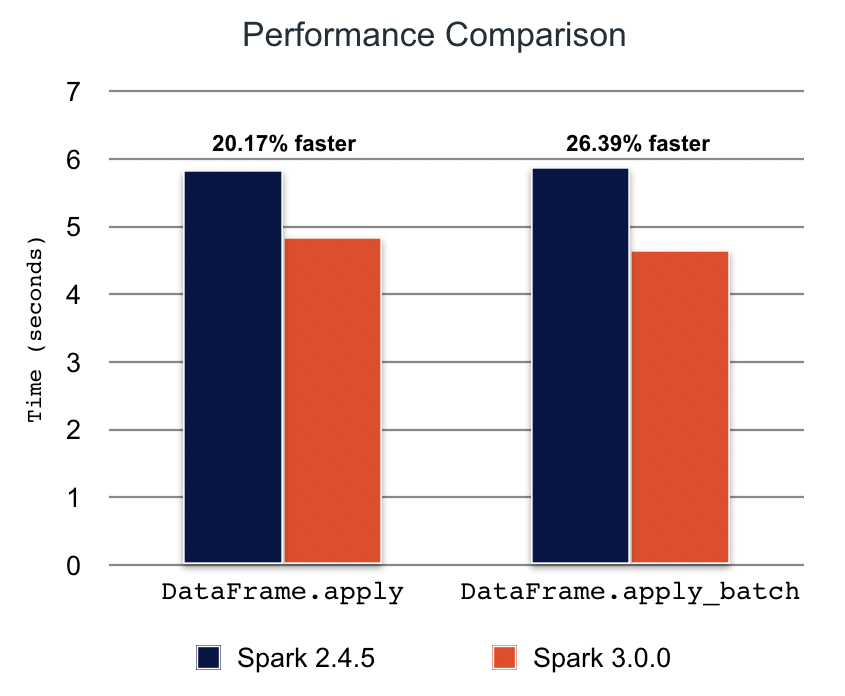
Spark 3.0.0とKoalas 1.0.0においては、ベンチマークで20%-25%の性能改善を確認しました。
型ヒントサポートの改善
Pythonネイティブ関数を実行するKoalas APIの多くは、実際にはpandasのインスタンスを受け取って返却します。以前は、型ヒントを返却するにはKoalasのインスタンを使う必要があり、以下のようにわかりにくいものになっていました。
def pandas_div(pdf) -> ks.DataFrame[float, float]:
# pdf is actually a pandas DataFrame.
return pdf[['B', 'C']] / pdf[['B', 'C']]
df = ks.DataFrame({'A': ['a', 'a', 'b'], 'B': [1, 2, 3], 'C': [4, 6, 5]})
df.groupby('A').apply(pandas_div)
Python 3.7以降およびKoalas 1.0.0においては、戻り値の型としてpandasインスタンスを使うこともできます。
def pandas_div(pdf) -> pd.DataFrame[float, float]:
return pdf[['B', 'C']] / pdf[['B', 'C']]
さらに、カラム名を型ヒントに指定できるように、実験的に新たな型タイプヒントが導入されています。
def pandas_div(pdf) -> pd.DataFrame['B': float, 'C': float]:
return pdf[['B', 'C']] / pdf[['B', 'C']]
また、ユーザーは戻り値の型ヒントに対して、実験的にpandasのdtypeインスタンスと、カラムのインデックスを指定することができます。
def pandas_div(pdf) -> pd.DataFrame[new_pdf.dtypes]:
return pdf[['B', 'C']] / pdf[['B', 'C']]
def pandas_div(pdf) -> pd.DataFrame[zip(new_pdf.columns, new_pdf.dtypes)]:
return pdf[['B', 'C']] / pdf[['B', 'C']]
プロットサポートの拡大
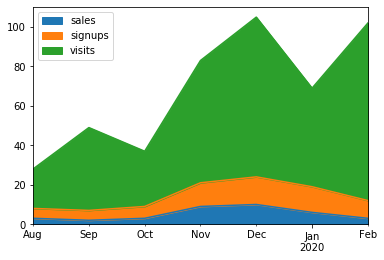
Koalasのプロット機能のAPIカバレッジは、Koalas 1.0.0で90%に到達しました。pandasで行っていたのと同じ方法で、Koalasでも容易に可視化を行うことができます。例えば、エリアチャートを描画するのに使っていたpandas APIと同じものを、Koalasデータフレームに対して使用することができます。
kdf = ks.DataFrame({
'sales': [3, 2, 3, 9, 10, 6, 3],
'signups': [5, 5, 6, 12, 14, 13, 9],
'visits': [20, 42, 28, 62, 81, 50, 90],
}, index=pd.date_range(start='2019/08/15', end='2020/03/09', freq='M'))
kdf.plot.area()
この例では、エリアチャートが描画され、売り上げの数のトレンド、サインアップ、訪問の時系列変化を確認することができます。
インプレースアップデートのサポート拡大
Koalas 1.0.0におけるシリーズのインプレースの更新は、データフレームが完全に可変であるかのように自然にデータフレームに対して適用されます。以前は、シリーズのインプレース更新のいくつかのケースでは、データフレームに変更が反映されませんでした。
例えば、Series.fillnaにおけるインプレースの更新は、データフレームも更新します。
kdf = ks.DataFrame({"x": [np.nan, 2, 3, 4, np.nan, 6]})
kser = kdf.x
kser.fillna(0, inplace=True)
さらに、シリーズを更新するためにアクセサーを使うこともでき、以下のように変更をデータフレームに反映させることができます。
kdf = ks.DataFrame({"x": [np.nan, 2, 3, 4, np.nan, 6]})
kser = kdf.x
kser.loc[2] = 30
kdf = ks.DataFrame({"x": [np.nan, 2, 3, 4, np.nan, 6]})
kser = kdf.x
kdf.loc[2, "x"] = 30
欠損値、NaN、NAサポートの改善
PySparkとpandasでは、欠損地の取り扱いにいくつか小さな違いがあります。例えば、PySparkにおいて欠損データは多くの場合Noneと表現されますが、pandasではNaNとなります。さらに、pandasでは実験的に新たにNAが導入されましたが、現在Koalasでは十分にサポートされていません。
他のケースのほとんどは今では修正されており、Koalasではこの問題に対応するために重点的に開発を進めています。例えば、Koalas 1.0.0ではSeries.fillnaはNaNを適切に取り扱えるようになっています。
Koalas 1.0を使ってみる
Koalasをインストールする方法はpipやcondaのようなパッケージマネージャを利用するなどいくつか存在します。手順はKoalasインストールガイドに記載されています。Databricksランタイムのユーザーであれば、こちらの手順に従うことでDatabricks上にライブラリをインストールすることができます。
多くのリソースを提供しているKoalasドキュメントのGetting Startedセクションもご覧になってください。
Koalasにトライするのを見送っていたのでしたら、まさに今が最適のタイミングです。Koalasは、今のワークロードをSparkでスケールできるように、より成熟したpandasの実装を提供します。大規模データがデータサイエンスプロジェクトのブロッカーになるべきではありません。Koalasはその手助けをするものです。