Introducing Built-in Image Data Source in Apache Spark 2.4 - The Databricks Blogの翻訳です。
はじめに
画像分類、物体検知におけるディープラーニングフレームワークの発展に伴い、Apache Sparkにおける標準的な画像処理への要望が高まっています。異なる画像フォーマット(jpeg/pngなど)、サイズ、カラースキーマを取り扱う必要があること、正確性を確認するのが困難(エラーを出すことなしに処理に失敗する)であることなど画像処理には固有の課題があります。
画像データソースを用いることで、特定の画像表現を抽象化し、コーディングしやすい標準的な画像表現を提供することで、上記の課題を解決します。
Apache Spark 2.3では、元々はMMLSparkライブラリで提供されていたImageSchema.readImages API(MicrosoftのApache Sparkの画像データサポートに関する記事を参照ください)をサポートしました。Apache Spark 2.4では、ビルトインのデータソースとなったので、より使いやすくなっています。画像データソースを用いることで、ディレクトリから画像を読み込み、単一の画像カラムを持つデータフレームを作成することができます。
この記事では、画像データソースがどのようなものか、Databricksレイクハウスプラットフォームにおけるディープラーニングのパイプラインでどのように使うのかを説明します。
画像のインポート
画像データソースを用いて、どのように画像をSparkに画像を読み込むのかを見ていきましょう。PySparkでは、以下のように画像をインポートできます。
Python
image_df = spark.read.format("image").load("/path/to/images")
Scala、Java、Rでも同様のAPIを提供しています。
画像データソースを用いることで、ネストされたディレクトリ構造(例えば、/path/to/dir/**のようなパス)をインポートすることができます。特定の画像に対しては、パーティションディレクトリ(/path/to/dir/date=2018-01-02/category=automobileのようなパス)のパスを指定することで、パーティションディスカバリーを使用することもできます。
画像のスキーマ
画像は"image"という列を持つデータフレームに読み込まれます。"image"は以下のフィールドを持つstruct型のカラムとなります。
image: struct containing all the image data
| |-- origin: string representing the source URI
| |-- height: integer, image height in pixels
| |-- width: integer, image width in pixels
| |-- nChannels: integer, number of color channels
| |-- mode: integer, OpenCV type
| |-- data: binary, the actual image
多くのフィールドは自明ですが、いくつかのフィールドには説明が必要かと思います。
nChannels: カラーチャンネルの数。典型的な値はグレースケールの画像場合は1、RGBのようなカラーイメージは3、アルファチャネルを持つカラーイメージは4となります。
Mode: データフィールドを解釈するための整数値の情報を提供します。格納されているデータのデータ型とチャンネルオーダーを保持しています。フィールドの値は、以下のOpenCVタイプにマッピングされることを期待されます(強制はされません)。OpenCVタイプは1、2、3、4のチャネル、画素値に対するいくつかのデータタイプを定義します。
OpenCVの値(データタイプ x チャンネルの数)に対するタイプのマッピングは以下の通りとなります。
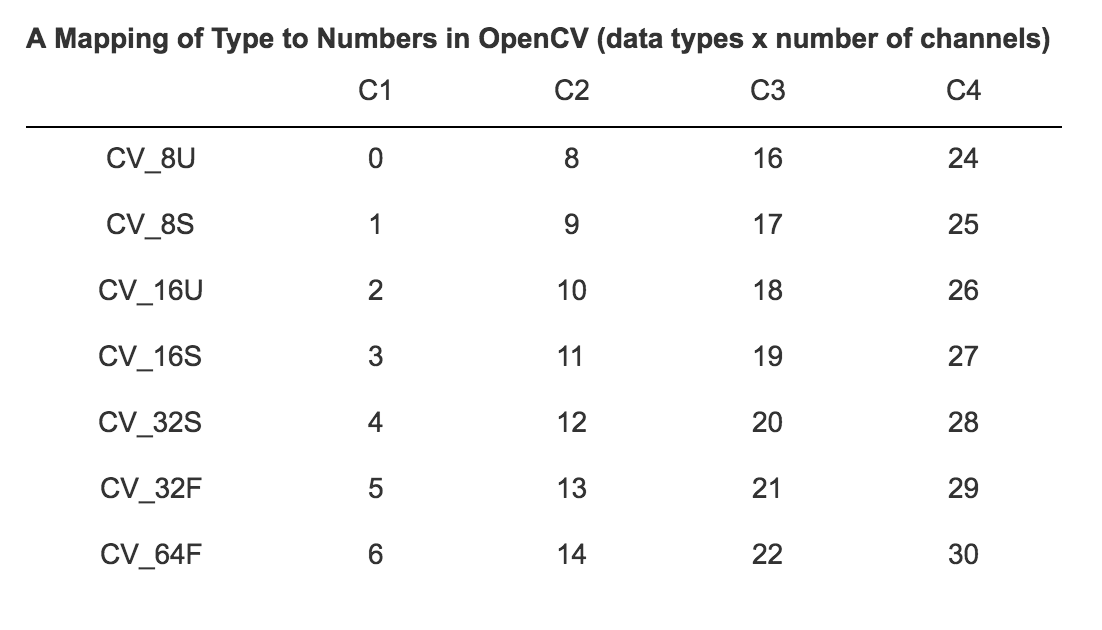
data: バイナリー形式で格納された画像データです。画像データは、次元の形状(height, width, nChannels)の3次元の配列、modeで指定されるt型の配列値となります。配列は行優先(row-major)で格納されます。
Row- and column-major order - Wikipedia
チャンネルのオーダー
チャンネルのオーダーは色が格納される順序を指定します。例えば、赤、青、緑から構成される典型的な3チャンネルの画像の場合、取りうる順序は6種類あります。多くのライブラリはRGBやBGRを使用します。3(あるいは4)チャンネルのOpenCVタイプは、BGR(A)の順序であることが期待されます。
コードサンプル
ディープラーニングパイプラインを用いることで、画像を用いた機械学習に容易に着手できます。バージョン0.4以降では、ディープラーニングパイプラインプロジェクトで定義された以前の画像スキーマは、上述した画像フォーマットとしての画像スキーまで置き換えられています。
このPythonの例では、カスタムの画像分類器を構築するのに転移学習を使用します。
Python
# path to your image source directory
sample_img_dir = ...
# Read image data using new image scheme
image_df = spark.read.format("image").load(sample_img_dir)
# Databricks display includes built-in image display support
display(image_df)
# Split training and test datasets
train_df, test_df = image_df.randomSplit([0.6, 0.4])
# train logistic regression on features generated by InceptionV3:
featurizer = DeepImageFeaturizer(inputCol="image", outputCol="features", modelName="InceptionV3")
# Build logistic regression transform
lr = LogisticRegression(maxIter=20, regParam=0.05, elasticNetParam=0.3, labelCol="label")
# Build ML pipeline
p = Pipeline(stages=[featurizer, lr])
# Build our model
p_model = p.fit(train_df)
# Run our model against test dataset
tested_df = p_model.transform(test_df)
# Evaluate our model
evaluator = MulticlassClassificationEvaluator(metricName="accuracy")
print("Test set accuracy = " + str(evaluator.evaluate(tested_df.select("prediction", "label"))))
注意: (ディープラーニングパイプラインの方向け)新たな画像スキーマではカラーチャンネルのオーダーがBGRからRGBへと変更になっています。混乱を避けるために、内部的なAPIのいくつかはオーダーを明示的に指定することを要求します。
次のステップ
df.sampleを用いてデータフレームからサンプリングすることが有効なケースがありますが、サンプリングは最適化されていません。これを改善するためには、毎回画像ファイルを読み込まないように、画像データソースにサンプリングオペレーターをプッシュダウンする必要があります。この機能はデータソースV2でサポート予定です。
その他、画像処理に関する新たな機能は、DatabricksおよびApache Sparkでリリースされる予定ですので楽しみにしていてください。
参考情報
- Image - Azure Databricks - Workspace | Microsoft Docs
- Image | Databricks on AWS
- Databricksランタイム 5.0 ML以降で、サンプルノートブックを試す。
- ディープラーニングパイプラインを学ぶ。
- GitHubのディープラーニングパイプラインのサンプルを試す。