Cost-based optimizer | Databricks on AWS [2022/9/9時点]の翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Spark SQLでは、クエリープランを改善するためにコストベースオプティマイザ(CBO)を使うことができます。これは、複数のjoinを伴うクエリーでは特に有効です。これが動作するには、テーブルとカラムの統計情報を収集し、最新の状態に保つことが重要となります。
統計情報の収集
CBOのメリットをフル活用するには、カラムの統計情報とテーブルの統計情報の両方を収集することが重要となります。統計情報はANALYZE TABLEコマンドを用いて収集することができます。
ティップス
統計情報を最新の状態に保つには、テーブル書き込み後にANALYZE TABLEコマンドを実行してください。
クエリープランの検証
クエリープランを検証する方法はいくつか存在します。
EXPLAINコマンド
プランが統計情報を使っているかどうかをチェックするには、SQLコマンドEXPLAINを使用します(Databricksランタイム7.x以降)。
統計情報がない場合、クエリープランが最適化されていない場合があります。
== Optimized Logical Plan ==
Aggregate [s_store_sk], [s_store_sk, count(1) AS count(1)L], Statistics(sizeInBytes=20.0 B, rowCount=1, hints=none)
+- Project [s_store_sk], Statistics(sizeInBytes=18.5 MB, rowCount=1.62E+6, hints=none)
+- Join Inner, (d_date_sk = ss_sold_date_sk), Statistics(sizeInBytes=30.8 MB, rowCount=1.62E+6, hints=none)
:- Project [ss_sold_date_sk, s_store_sk], Statistics(sizeInBytes=39.1 GB, rowCount=2.63E+9, hints=none)
: +- Join Inner, (s_store_sk = ss_store_sk), Statistics(sizeInBytes=48.9 GB, rowCount=2.63E+9, hints=none)
: :- Project [ss_store_sk, ss_sold_date_sk], Statistics(sizeInBytes=39.1 GB, rowCount=2.63E+9, hints=none)
: : +- Filter (isnotnull(ss_store_sk) && isnotnull(ss_sold_date_sk)), Statistics(sizeInBytes=39.1 GB, rowCount=2.63E+9, hints=none)
: : +- Relation[ss_store_sk,ss_sold_date_sk] parquet, Statistics(sizeInBytes=134.6 GB, rowCount=2.88E+9, hints=none)
: +- Project [s_store_sk], Statistics(sizeInBytes=11.7 KB, rowCount=1.00E+3, hints=none)
: +- Filter isnotnull(s_store_sk), Statistics(sizeInBytes=11.7 KB, rowCount=1.00E+3, hints=none)
: +- Relation[s_store_sk] parquet, Statistics(sizeInBytes=88.0 KB, rowCount=1.00E+3, hints=none)
+- Project [d_date_sk], Statistics(sizeInBytes=12.0 B, rowCount=1, hints=none)
+- Filter ((((isnotnull(d_year) && isnotnull(d_date)) && (d_year = 2000)) && (d_date = 2000-12-31)) && isnotnull(d_date_sk)), Statistics(sizeInBytes=38.0 B, rowCount=1, hints=none)
+- Relation[d_date_sk,d_date,d_year] parquet, Statistics(sizeInBytes=1786.7 KB, rowCount=7.30E+4, hints=none)
重要!
複数のjoinを持つクエリーでは特にrowCount統計情報が重要となります。rowCountが無いと、計算に必要な十分な情報が無いことを意味します(すなわち、いくつかの必要なカラムに統計情報がありません)。
Spark SQL UI
実行プランと統計情報の精度を確認するためにSpark SQL UIページを使用します。

推定値(estimate)の欠如
rows output: 2,451,005 est: N/Aのような行は、このオペレータは約2Mの行を生成しましたが、統計情報は利用できないことを意味しています。
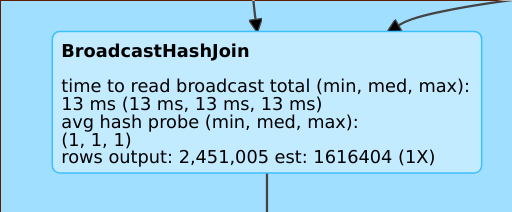
適切な推定値
output: 2,451,005 est: 1616404 (1X)の様な行は、このオペレータは約2Mの行を生成しましたが、推定値は1.6Mであり、推定のエラーファクターは1だったことを意味しています。

悪い推定値
output: 2,451,005 est: 2626656323の様な行は、このオペレータは約2Mの行を生成しましたが、推定値は2B行であり、推定のエラーファクターは1000であったことを意味しています。
コストベースオプティマイザの無効化
CBOはデフォルトで有効化されています。spark.sql.cbo.enabledフラグを変更することでCBOを無効化することができます。
spark.conf.set("spark.sql.cbo.enabled", false)