Best Practices for Realtime Feature Computation on Databricks - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
様々な業界やアプリケーションにおいて機械学習の利用は進んでおり、機械学習パイプラインもまた洗練されてきています。我々の多くのお客様は、事前に予測結果を生成するためにバッチを利用しなくなっており、代わりにリアルタイムの予測を行うようになっています。この文脈で生じる一般的な疑問は「どうすればモデルにユーザーの最新のアクションを考慮した予測を行わせることができるのか?」ということでしょう。多くのモデルにおいては、これがリアルタイムアーキテクチャに切り替えることで得られる偉大なビジネス価値を実現するための鍵となります。例えば、顧客が現在参照している製品をベースとした製品レコメンデーションモデルは、静的なモデルよりも定性的に優れていると言えます。
本書では、Databricks Feature StoreとMLflowを用いた最新かつ高精度なデータによる、リアルタイムモデルを提供するための最も効果的なアーキテクチャを検証します。また、これらの技術を説明するためのサンプルも提供します。
システムモデリングのコアとなる特徴量エンジニアリング
データサイエンティストがモデルを構築する際、複雑なシステムの挙動や成果を予測することができるシグナルを探していることにんります。MLモデルに入力されるデータシグナルは特徴量と呼ばれます。通常、ライブかつリアルタイムでデータソースから到着する生のシグナルと、集計された時系列の特徴量の両方は、将来の挙動に対する予測器となり得ます。データサイエンティストはレイクハウスで既存の集計された特徴量を見つけ出し、別の機械学習プロジェクトで再利用したいと考えています。
生の入力データからこれらの集計値を計算する際、データエンジニアは様々な相互干渉しあう次元においてトレードオフを行う必要があります:計算処理の複雑度、入力データのサイズ、モデル予測に対するそれぞれのシグナルに対する鮮度の要件や重要度、オンラインシステムで予測されるレーテンシー、特徴量計算処理やモデルスコアリングのコストなどです。これらそれぞれが、特徴量計算パイプラインのアーキテクチャやモデルスコアリングに対して重要な示唆をもたらします。これらの中で最も重要なドライバーの一つは、データの鮮度とモデルの予測結果の精度に対してそれぞれのシグナルがどのような影響を及ぼすかです。
データの鮮度は、新たなイベントが計算パイプラインで利用できるようになった時間と、バッチストレージで計算された特徴量がアップデートされた時間、あるいは、オンラインのモデル推論で特徴量が利用できるようになった時間から計測することができます。言い換えると、予測でどれだけ古い特徴量が使用されているのかを決定することになります。データ鮮度の要件は、特徴量の値がどれだけクイックに変化するのか、特徴量は迅速に変化するのかゆっくり変化するのかを表現することになります。
データエンジニアが特徴量計算に対して意思決定を行う際に、データ鮮度がどのように影響を及ぼすのかを考えてみましょう。大きく、選択するアーキテクチャは3つ存在します:バッチ、ストリーミング、オンデマンドであり、複雑度やコストの面で異違いが出てきます。
特徴量エンジニアリングの計算処理アーキテクチャ
(SparkやPhoton)のようなバッチ計算フレームワークは、変化がゆっくりな特徴量や、通常は大規模なデータに対する複雑な計算処理を必要とする特徴量の計算を効率的に行うことができます。このアーキテクチャによって、特徴量を事前計算するためにパイプラインが起動され、オフラインのテーブルで永続化されます。リアルタイムのモデルスコアリングにおいては、低レーテンシーのアクセスを提供するためにオンラインストアで公開することができます。このタイプの特徴量は、モデルパフォーマンスに対するデータ鮮度の影響が低い場合に使用することができます。一般的な例には、顧客の生涯を通じての総購買量や商品の人気の時系列変化を用いた商品レコメンデーションシステムで、時系列の特定のメトリックを集計する統計的な特徴量が含まれます。
現実世界で急速に変化する値の特徴量においては、データの鮮度がより問題となります。特徴量はすぐに古くなり、モデル予測の精度は急激に劣化します。データサイエンティストは、モデルスコアリングの際に最新のシグナルから特徴量が計算されるオンライン計算処理を好みます。通常これらは、よりシンプルな計算処理を使用し、より小規模な生の入力データを使用します。オンデマンド計算処理を用いる別のシナリオは、モデルスコアリングで特徴量を実際に使用するよりも高い頻度で特徴量の値が変化するというケースです。大量なオブジェクトに対してこのような特徴量を頻繁に再計算することは、すぐに非効率的かつ高コストとなってしまいます。例えば、前述したユーザーの製品参照履歴においては、ユーザーの嗜好と過去1分間で参照したアイテムのエンべディング間のコサイン類似度、当該セッションでディスカウントされたアイテムの割合はすべてオンデマンドでの計算される特徴量がベストとなる例となります。
また、これらの極端な例の間に当てはまる特徴量も存在します。特徴量によっては、より大規模な計算処理や、低レイテンシーによるオンデマンド計算によってなされるよりも、高いスループットのストリームデータを用いることがあり、バッチアーキテクチャで対応できるよりも高速に値が変化することもあります。これらのニアリアルタイムの特徴量は、バッチアーキテクチャと同様に特徴量の値を非同期的に事前計算しますが、データのストリームを連続的に処理するストリーミングアーキテクチャを用いて計算するのがベストとなります。
計算処理アーキテクチャの選定
計算処理アーキテクチャを選択する際の良いスタート地点はデータ鮮度の要件となります。よりシンプルなケースにおいては、データ鮮度の要件は厳密なものではなく、バッチやストリーミングアーキテクチャが最初の選択肢となります。これらは実装が容易で、大規模な計算処理要件に対応でき、低レーテンシーで予測結果を提供することができます。より高度なケースにおいて、ユーザーの挙動や外部イベントにクイックに反応できるモデルを構築する必要がある際、データ鮮度の要件はより厳密となり、これらの要件に対応するためにはオンデマンドアーキテクチャがより適切なものとなります。
ここまでで汎用的なガイダンスを確立したので、特定のサンプルで説明を行い、異なるタイプの特徴量の計算処理に対するすべての3つのアーキテクチャを実装するために、どのようにDatabricks Feature StoreとMLflowを活用するのかを見ていきましょう。
サンプル: 旅行レコメンデーションのランキングモデル
旅行をレコメンデーションするウェブサイトでレコメンデーションモデルを構築しようとしているものとしましょう。あなたのウェブサイトでユーザーの方が購入する可能性の高い休日の旅行先がマッチするように、ランキングモデルのレコメンデーションの品質を改善するためにリアルタイムの特徴量を活用したいと考えています。
旅行レコメンデーションランキングモデルにおいて、ユーザーにレコメンドされるベストな旅行先を予測したいものとします。我々のレイクハウスには以下のタイプのデータがあるものとします。
-
旅行場所のデータ - これはウェブサイトが休日パッケージとして提示する目的地の静的なデータセットです。目的地の場所のデータセットは、
destination_latitudeとdestination_longitudeから構成されています。このデータセットは、新たな目的地が追加された際にのみ変更されます。 - 旅行先の人気に関するデータ - ウェブサイトでは、インプレッション数やインプレッションに対するクリックや購入をベースとしたウェブサイトの利用ログから人気に関する情報を収集しています。
- 旅行先の空き状況のデータ - ユーザーが部屋を予約すると、目的地の空き状況と価格が影響を受けます。価格と空き状況は、ユーザーの旅行先の予約における大きなドライバーであるので、数分オーダーでこの最新のデータを維持したいと考えます。
- ユーザーの嗜好 - 何人かのユーザーは現在の地点に近い場所を予約することを好み、何人かのユーザーはグローバルや遠隔地への旅行を好みます。予約時にのみユーザーの位置は特定されます。
それぞれのデータセットのデータ鮮度の要件を用いて、適切な計算処理アーキテクチャを選択しましょう。
-
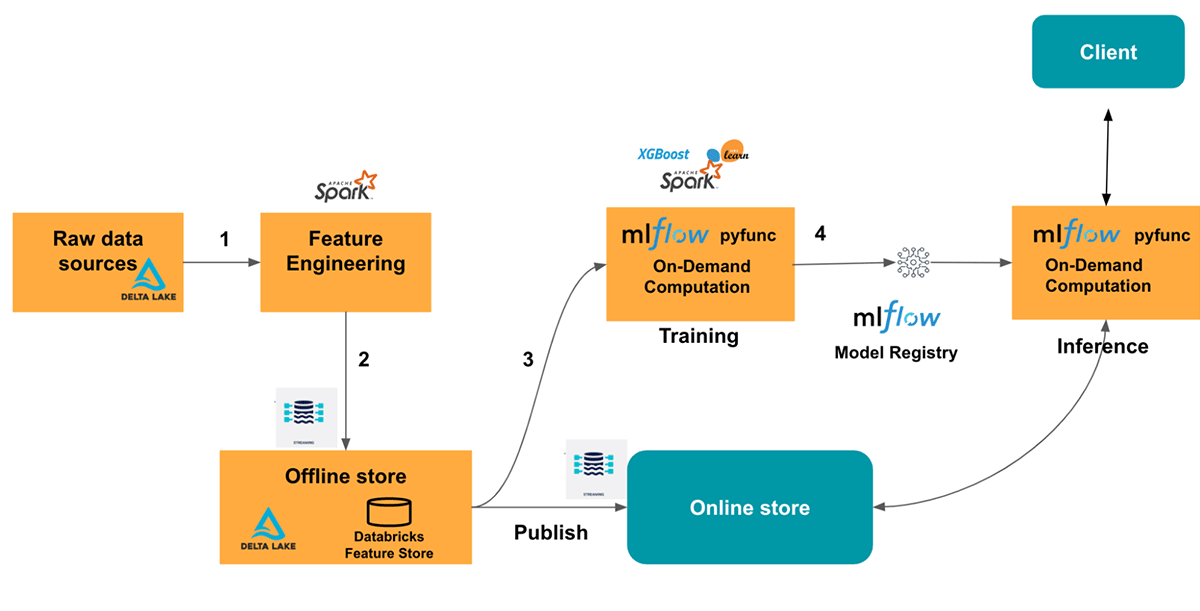
バッチアーキテクチャ - 数時間、数日の更新頻度が許容できるタイプのすべてのデータにおいては、SparkとFeature Storeの
write_tableAPIを用いた計算処理を使用し、オンラインストアにデータを公開します。これは、旅行場所のデータと旅行先の人気に関するデータに適用されます。Pythonfs.write_table( name="travel_recommendations.location_features", df=destination_location_df) fs.publish_table("travel_recommendations.location_features", destination_location_online_store_spec) -
ストリーミングアーキテクチャ - データ鮮度が数分であるデータに関しては、オフラインストアの特徴量テーブルに書き込み、オンラインストアに公開するためにSparkの構造化ストリーミングを使用します。これは
旅行先の空き状況のデータに適用されます。Databricksではバッチ処理をストリーミング処理に切り替えるのは、二者間で一貫性のあるAPIを提供しているのでわかりやすいものとなっています。サンプルで説明しているように、コードはほとんど変わっていません。特徴量計算でストリーミングのデータソースを使う必要があるだけで、オンラインストアに特徴量を公開するにはstreaming = Trueを設定するだけです。Pythondestination_availability_df = spark.readStream.format("kafka").load() fs.write_table( name="travel_recommendations.availability_features", df=destination_availability_df, mode="merge") fs.publish_table("travel_recommendations.availability_features", destination_availability_online_store_spec, streaming = True) -
オンデマンドアーキテクチャ - ユーザーの位置のように推論時にのみ計算可能な特徴量に関しては、効果的なデータ鮮度要件は「即座に」であり、オンデマンドでのみこれらを計算することができます。これらの特徴量に対しては、オンデマンドアーキテクチャを採用します。これは
ユーザーの嗜好特徴量、ユーザーの位置と目的地の位置の間の距離に適用されます。Python# Wrap the model with on-demand feature computation layer class OnDemandComputationModelWrapper(mlflow.pyfunc.PythonModel): def predict(self, context, model_input): new_model_input = self._compute_ondemand_features(model_input) return self.model.predict(new_model_input) ...
オンデマンド特徴量計算処理アーキテクチャ
我々は、ユーザーの場所のような文脈のデータを用いてオンデマンドの特徴量を計算したいと考えます。しかし、トレーニングやサービングでオンデマンドの特徴量を計算した場合、オンライン/オフラインの偏りを引き起こすことがあります。この問題を回避するために、トレーニングと推論でオンデマンドの特徴量計算処理が全く同じであることを確実にする必要があります。これを達成するために、MLflowのpyfuncモデルを活用します。Pyfuncモデルによって、カスタム前処理ロジックを持つモデルの予測/トレーニングステップをラッピングすることができます。モデルのトレーニングよ予測の両方で同じ特徴量計算処理コードをを再利用することができます。これによって、オフラインとオンラインの偏りの削減の役に立ちます。
トレーニングと推論における特徴量計算処理コードの共有
このサンプルでは、LightGBMモデルをトレーニングしたいと考えています。しかし、オンラインのモデルサービングとオフラインのモデルトレーニングで確実に同じ特徴量計算処理が用いられるようにするために、カスタムの前処理ステップを追加するためにトレーニングされたモデルの上でMLflowのpyfuncラッパーを使用します。このpyfuncラッパーはトレーニングの際と推論の際に呼び出される前処理としてオンデマンド計算ステップを追加します。これによって、オフラインのトレーニングとオンラインの推論でオンデマンド特徴量の計算処理コードが共有され、オフラインとオンラインの偏りを削減します。オンデマンド特徴量の変換処理コードを共有する共通の場所なしには、トレーニングのコードでは、推論の際とは異なるコードを使うことになってしまう可能性が高く、モデルパフォーマンス問題のデバッグが困難となってしまいます。コードを見てみると、model.fit()とmodel.predict()で同じ_compute_ondemand_featuresを呼び出していることがわかります。
# On-demand feature computation model wrapper
class OnDemandComputationModelWrapper(mlflow.pyfunc.PythonModel):
def fit(self, X_train: pd.DataFrame, y_train: pd.DataFrame):
new_model_input = self._compute_ondemand_features(X_train)
self.model = lgb.train(
lgb.Dataset(new_model_input, label=y_train.values),
5)
def predict(self, context, model_input):
new_model_input = self._compute_ondemand_features(model_input)
return self.model.predict(new_model_input)
def _compute_ondemand_features(self, model_input: pd.DataFrame)->pd.DataFrame:
loc_cols = ["user_longitude","user_latitude","longitude","latitude"]
model_input["distance"] = model_input[loc_cols].apply(lambda x: my_distance((x[0], x[1]), (x[2], x[3])), axis=1)
return model_input
プロダクションへのデプロイメント
Databricksモデルサービングにモデルをデプロイしましょう。Feature Storeで記録されたモデルにはリネージ情報が含まれているので、モデルのデプロイメントでは、自動で特徴量の検索に必要なオンラインストアを解決します。サービングされるモデルは自動でuser_idとdestination_idから特徴量を検索(AWS|Azure)するので、アプリケーションのロジックをシンプルに保つことができます。さらに、MLflowのpyfuncを用いてユーザーと目的地の間の距離のようなオンデマンド特徴量を計算することで、レコメンデーションをより適切なものにすることができます。モデルに対する入力リクエストの一部として、user_latitudeやuser_longitudeのようなリアルタイム特徴量を引き渡します。MLflowモデルの前処理では、入力データを距離として特徴量を生成します。このように、ベストな旅行先を予測する際、モデルはユーザーの現在位置のような文脈の特徴量を考慮することができます。
それでは、予測リクエストを行ってみましょう。二人の顧客に対してレコメンデーションを行います。一方はニューヨークにいて、過去の予約に基づいた短距離の旅行を好んでおり(user_id=4)、もう一方はカリフォルニアにいて、長距離の旅行を好んでいます(user_id=39)。モデルは以下のレコメンデーションを生成します。
{
"dataframe_records": [
# Users in New York, see high scores for Florida
{"user_id": 4, "booking_date": "2022-12-23", "destination_id": 16, "user_latitude": 40.71277, "user_longitude": -74.005974},
# Users in California, see high scores for Hawaii
{"user_id": 39, "booking_date": "2022-12-23", "destination_id": 1, "user_latitude": 37.77493, "user_longitude": -122.41942}
]
}
# Result with predictions greater than 0.2 indicate high likelihood
# of purchase
{'predictions': [0.4854248407420413, 0.49863922456395]}
ニューヨークのユーザーに対して最も高いスコアを示したのはフロリダ(destination_id=16)であり、カリフォルニアのユーザーに対してはハワイ(destination_id=1)を提案していることがわかります。また、我々のモデルはユーザーの現在位置を考慮し、レコメンデーションの適切性を改善するために活用しています。
ノートブック
上述したサンプルを説明しているノートブックはこちらから参照ください。
リアルタイム特徴量計算処理を使い始める
ご自身の問題がリアルタイムの特徴量計算を必要しているかどうかを特定し、答えがイエスであるのであれば、どのようなタイプのデータ、データ鮮度、レーテンシーの要件があるのかを明らかにしましょう。
- データ鮮度の要件に基づいて、ご自身のデータをバッチ、ストリーミング、オンデマンド計算アーキテクチャにマッピングしましょう。
- オフラインストアとオンラインストアに対して計算結果をストリーミングするために、Spark構造化ストリーミングを活用しましょう。
- MLflow pyfuncを用いてオンデマンド計算処理を活用しましょう。
- モデルに対する低レーテンシー予測を行うために、Databricksサーバレスリアルタイム推論機能を活用しましょう。
謝辞
原文をご覧ください。