How to Manage Model Ensembles With MLflow and AutoML - The Databricks Blogの翻訳です。
機械学習において、アンサンブルは単体のモデルよりも優れた予測能力を提供する複数モデルのコレクションを意味します。複数の機械学習アルゴリズムのアウトプットは、平均あるいは投票のプロセスを経て組み合わされ、与えられた入力に対して優れた予測性能を示します。
しかし、アンサンブル学習アプローチにはトレードオフが存在します。それぞれの予測を説明(モデルの解釈)することはさらに困難になります。さらに、このアプローチはエンジニアリングの複雑性を増加させ、アンサンブルモデルをライフサイクルを通じて、どのように管理するのかが明確ではないケースが頻発します。N個の異なるモデルを作成するという事実に加え、以下の様な管理に関する懸念がいくつかあります。
- 1つのモデルを変更した場合、アンサンブルのバージョン管理にどの様に影響するのか?
- アンサンブルのモデルドリフトをどの様に検知するのか?
- どのようにアンサンブルのアーティファクトをパッケージングし、リネージュを維持するのか?
この記事では、MLflowとDatabricks AutoMLによってサポートされるアンサンブルの作成、管理のプロセスをウォークスルーします。単一のモデルの作成、本格運用が困難であれば、アンサンブルに対して同じことをするのはさらに困難になります!Databricks AutoMLは全てのモデル作成の重荷を取り除くので、さらに少ない労力でアンサンブル を活用する機会を得ることができます。あるアーキテクチャタイプのトップN個のモデルを用いるというシンプルなスタッキング戦略によって、単一のベストモデルのパフォーマンスを上回ることができるかもしれません。
アンサンブル
いくつかのアルゴリズムは生来のアンサンブル(ランダムフォレスト、AdaBoost)であり、他のものは決定木や、ロジスティック、線形回帰の様な従来のアルゴリズムの組み合わせとなっています。これらは、ニューラルネットワークやディープラーニングのシナリオにも拡張されます。それぞれのアルゴリズムが、自身のモデリング手法を持っているので、データ、アンサンブルの関係性によって、制度を改善しつつも全体的なバリアンスとバイアスを削減することができます。
アンサンブル を構築する際に検討すべきいくつかの要素があります。
- データセットのサイズはどの程度か?
- いくつのモデルをアンサンブルに含めるのか?
- 個々のモデルはどの程度ばらばらなのか?
- どの様に複数バージョンのモデルを管理するのか?
- これらはパッケージにされるべきか?
- 異なるユースケースでモデルが再利用されるのか?
データの特性に大きなバリエーションがある場合、通常アンサンブルは優れたパフォーマンスを示します。様々な学習器のセットを持つことで、全体的な予測能力を改善します。しかし、どれだけモデルを追加してもパフォーマンスにインパクトが出なくなるプラトー地点が存在します。このため、アンサンブルを作成、管理するコストと追加のパフォーマンス改善のバランスを取ることが重要です。アンサンブルにおけるそれぞれのサブモデルには自身のライフサイクルがあります。あるものには、より強力な内部依存性があり、あるものはよりスタンドアローンとなっています。このため、柔軟に再利用、アップグレードできる様に、どのようにサブモデルがトレーニングされ、パッケージングされているのかを検討することが重要となります。
最もアンサンブル戦略からメリットを得ることができるいくつかのユースケースを見ていきましょう。
- 顧客の声データの分析
規制上のガイドラインに従って、苦情データは取り扱われる必要があります。これには、苦情の迅速かつ正確な分類と、是正するために人間による介入が必要となります。このデータには一般的な顧客の声も含まれています。いくつかの顧客の問い合わせには急いで回答する必要はないかもしれませんが、legalやregulatoryとラベルづけされたものに対しては、すぐに対応しなくてはなりません。これは、わずかな精度の改善でもビジネスへ大きなインパクトをもたらすので、アンサンブルの素晴らしいユースケース候補となります。
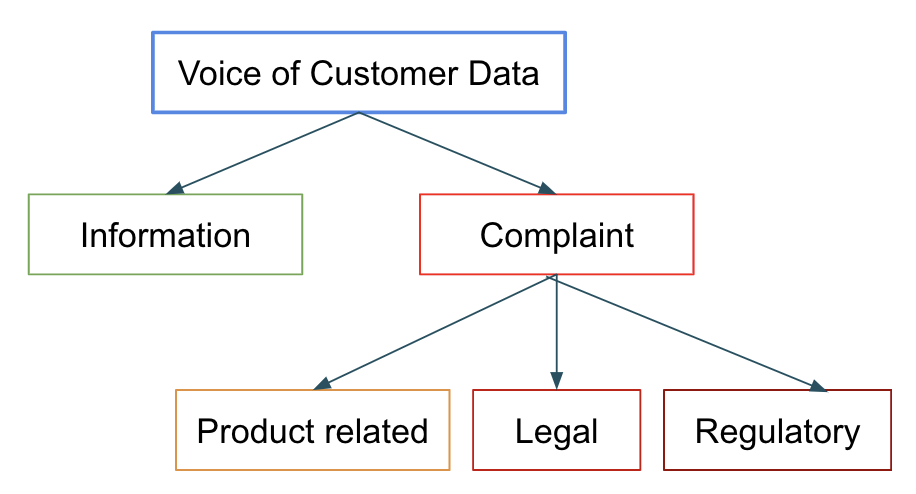
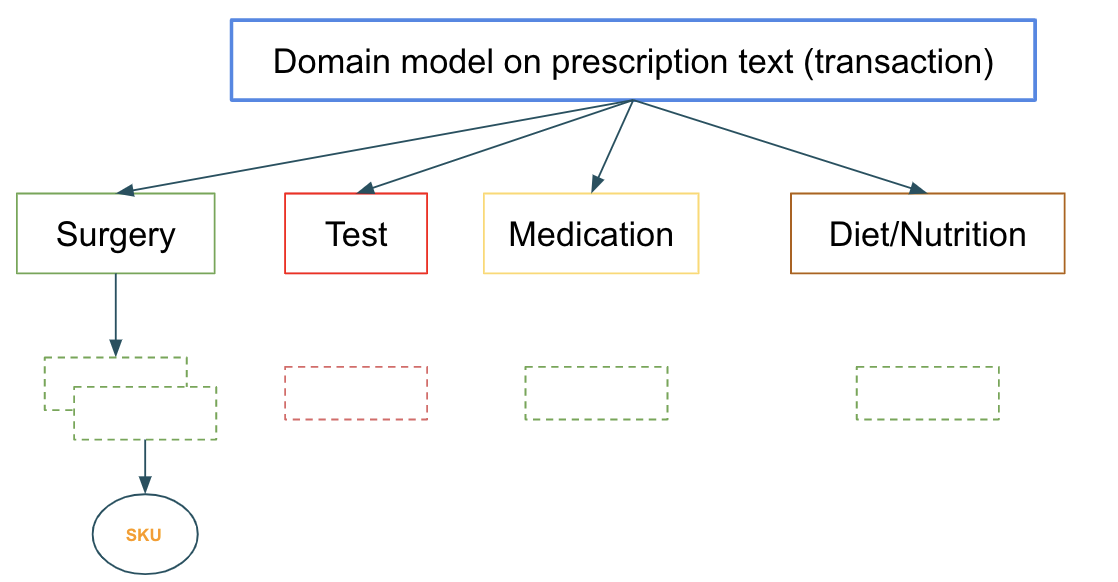
- 製品レコメンデーションのための複数分類シナリオにおけるベストフィットの探索
処方箋データは、適切なSKUのフィットを探索するために分析されます。それぞれのレイヤーのモデルは前段のレイヤーからデータを受け取り、分類を改善します。
モデルを作成しデプロイすると、モデルは管理されるべき動作し続けるアーティファクトとなります。アンサンブルと個々のサブモデルのバージョンと依存関係を管理する際に検討すべき課題がいくつか存在します。さらに、いくつかのステージ(環境)が存在し、次のステージにプロモーションするためには、モデルはそれぞれのステージで正常に動作しなくてはなりません。モデルがアンサンブルの一部になっている場合、問題はさらに悪化します。ユースケースごとに異なるバージョンが用いられている中で、異なるユースケースでモデルが共有されている場合には、また別のレベルの複雑性が生じます。このため、全てのユースケースにおいて、プロダクションから最新のバージョンを取得することが正しいことではないケースもあり得ます。
Databricks AutoML + MLflowでアンサンブル作成、管理をシンプルに
MLflowは、エンドツーエンドのモデル管理のためのオープンソース、かつスケーラブルなフレームワークです。再現可能なラン(トレーニング)を用いることで、アーティファクトの開発からデプロイメントまでの全体のMLOpsサイクルをサポートします。
MLの実践者は、モデルをスクラッチで作成することもできれば、DatabricksのAutoMLを活用することもできます。MLflowで記録されるあらゆるモデルのセットに対して、ベストなものを取得できるだけでなく、トップN個のモデルの組み合わせが、どれだけ優れたパフォーマンスを出すのかを確認することもできます。
Databricks AutoMLは、選択したデータセットを用いて迅速にプロトタイプを行える様に、機械学習を民主化するために完全に自動化された、ガラスボックスアプローチを採用したモデル開発ソリューションです。内部ではMLflowを活用しています。AutoMLはデータサイエンティストの2つのペインポイントを解決します。データセットによって得られる予測能力のクイックな検証と、そのまま使用する、あるいは改善していくことになるベースラインモデルの獲得です。その他にも以下の特徴があります。
- 探索的データ分析(EDA)ノートブックを含むデータの前処理
- 特徴量エンジニアリング、特徴量選択
- ハイパーパラメーターチューニングによる自動トレーニング、およびMLflowトラッキングによる個々のランのトラッキングにより、MLflowレジストリへのベストモデルの選択をサポート
モデルの最適パフォーマンスを追い求めるために、データチームが異なるアーキテクチャタイプのいくつかのモデルを生み出すために多大な時間と労力を費やすことはよくあることです。AutoMLを用いることで、モデル作成プロセス自体が自動で生成され、後段のモデル選択のプロセスをシンプルなものにします。
AutoMLは現在、回帰と分類をサポートしており、以下のフェーズから構成されています。
- 設定: データセット、問題の種類、予測すべきターゲットあるいはラベルのカラム、実験ランに対する評価・スコアリングのメトリック、停止条件(トライアルの数あるいはランの総実行時間)を指定します。
- トレーニング: エクスペリメントにおけるそれぞれのMLトレーニングのランは全て詳細(コード、パラメーター、メトリクス、モデル、アーティファクト)が記録されるので、後ほど検索および探索をお行うことができます。
- 評価: 後で検証、レジストリへの登録が行える様に、選択の評価基準に基づいて決定されるトップモデルがハイライトされます。ここで単体のベストモデル(チャンピオン)、あるいはトップモデルの組み合わせ(チャレンジャー)がベストモデルを上回る場合にはチャレンジャーを使用することができます。
次回解約するかもしれない顧客を予測するために用いられる、kaggleのtelcoデータセットで検証してみましょう。選択基準に基づいて、AutoMLは単体のベストモデルだけではなく、全てのタイプのモデルにおけるすべてのランの詳細を提供します。提案されたベストモデル(チャンピオン)と、それぞれのサブカテゴリにおけるトップモデル(チャレンジャー)をMLflowのモデルレジストリに登録するところからスタートします。
テストデータセットを用いて、こちらのノートブックでチャンピオンとチャレンジャーのパフォーマンスを比較します。アンサンブルの場合、最終的な分類には投票戦略が用いられます。アンサンブルのパフォーマンスが大幅に優れている場合には、アンサンブルが新たなチャンピオンモデルとなります。アンサンブルモデルを別々に使用するか、全体として使用するのかに関しては異なる意見が存在します。
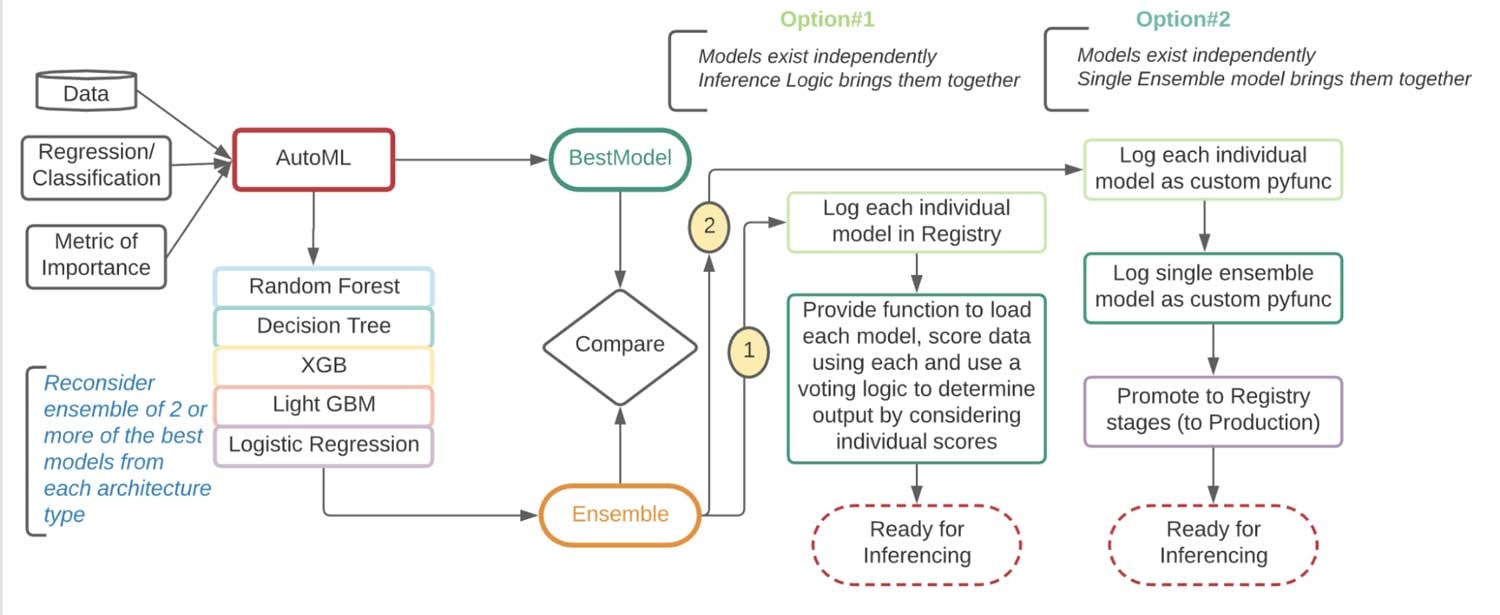
図: ベストアンサンブルを特定し、トラッキングサーバーに記録、レジストリに昇格させるフロー
| オプション#1 | オプション#2 |
|---|---|
|
|
この例では、個々のモデルを独立に記録し、MLflow上で単体のアンサンブルラッパーモデルとして取り扱うオプション#2を採用します。
アンサンブルは全ての独立したモデルを単一のpickleファイルとしてカプセル化します。これにより、アンサンブルを自身のライフサイクルを持つ一つのアーティファクトとしてデプロイすることができ、個々のモデルを分離し、それぞれが独立して進化していくことが可能となります。これは、dockerコンテナのシッピングや適切な個々のライブラリを組み合わせた後のuber jarと同様のものです。
ステップ#1: AutoMLエクスペリメントからそれぞれのアーキテクチャタイプの「ベスト」モデルを取得
filter_str = "params.classifier LIKE 'DecisionTree%'"
model = (client.search_runs(experiment_ids=experiment_id, filter_string=filter_str,
order_by=["metrics.val_f1_score DESC"]))[0]
best_runId = model.info.run_uuid
DecisionTree_model_uri = f"runs:/{best_runId}/model"
DecisionTree_model = mlflow.sklearn.load_model(DecisionTree_model_uri)
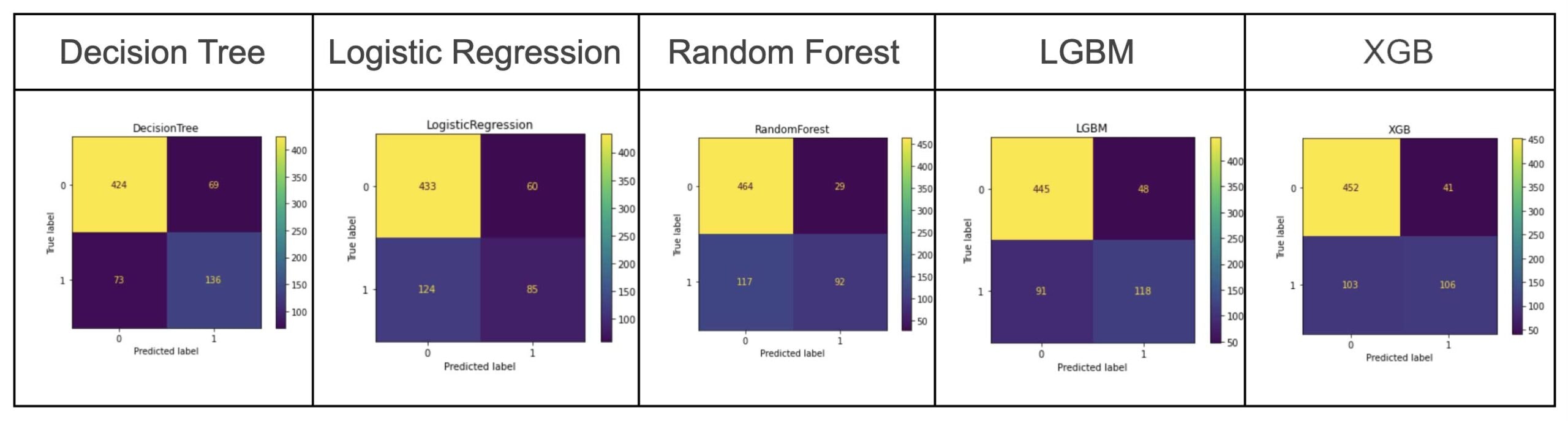
図: AutoMLで作成されたそれぞれのモデルのベストモデル(この例では、AutoMLはベストモデルとしてXGBを選択しました)
ステップ#2: ベストモデルをカプセル化するカスタムpyfuncモデルクラスの構築
これによって、アンサンブルに異なるモデルをpickleします。アンサンブルクラスに必要な関数は、__init__、load_context、decide、ensembleTopN、predictです。以降でこれらの詳細を説明します。
class Ensemble(mlflow.pyfunc.PythonModel):
def __init__(self, DecisionTree, RandomForest, LGBM, XGB):
self.DecisionTree = DecisionTree
self.RandomForest = RandomForest
self.LGBM = LGBM
self.XGB = XGB
ステップ#3: アンサンブルに対する予測関数の提供
あらゆるpyfuncモデルにおいてpredict関数は、新規データに対して推論を行う際に必要となる以下のパラダイム)に従う必要があります。
predict関数はデータをpandasデータフレームとして受け取り、別のpandasデータフレームを返却します。これによって、モデルはMLflowのモデルサービングやApache Spark™のUDF(ユーザー定義関数)やpandas関数と相互運用できる様になります。
# Input is pandas dataframe or series
def predict(self, context, model_input):
dt = self.DecisionTree.predict(model_input)
rf = self.RandomForest.predict(model_input)
lgbm = self.LGBM.predict(model_input)
xgb = self.XGB.predict(model_input)
ensemble = self.ensembleTopN( dt,rf,lgbm,xgb)
return pd.DataFrame({
"DecisionTreePredictions": dt,
"RandomForestPredictions": rf,
"LGBMPredictions": lgbm,
"XGBPredictions": xgb,
"Ensemble Predictions": ensemble
})
ステップ#4: 投票関数の提供
予測の中身は、いくつかのバリエーションが存在する投票アルゴリズムによって決定されます。多数決をおこなうシンプルなアプローチの例を示します。
# Helper function to decide based on the number of models provided
def decide(self, votes, num_scores):
# The output and return logic will need to change for multiclass as you need to return 0-N as result.
if votes >= int(num_scores/2) + 1:
return 1
else:
return 0
# Scores is a list of series of predictions from the other classifiers
def ensembleTopN(self, *scores):
# This line needs to change for creating votes for multi class.
votes = functools.reduce(lambda x, y: x+y, scores)
num_scores = len(scores)
decide_with_num_scores = functools.partial(decide, num_scores=num_scores)
decide_vec = np.vectorize(decide_with_num_scores)
# Since this is a binary classification return will be 0 or 1
return decide_vec(votes)
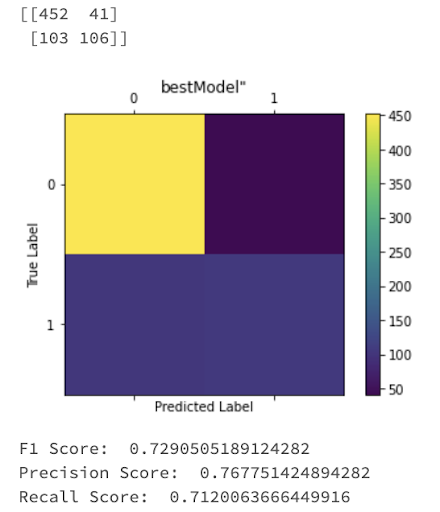
図: チャンピオンモデル
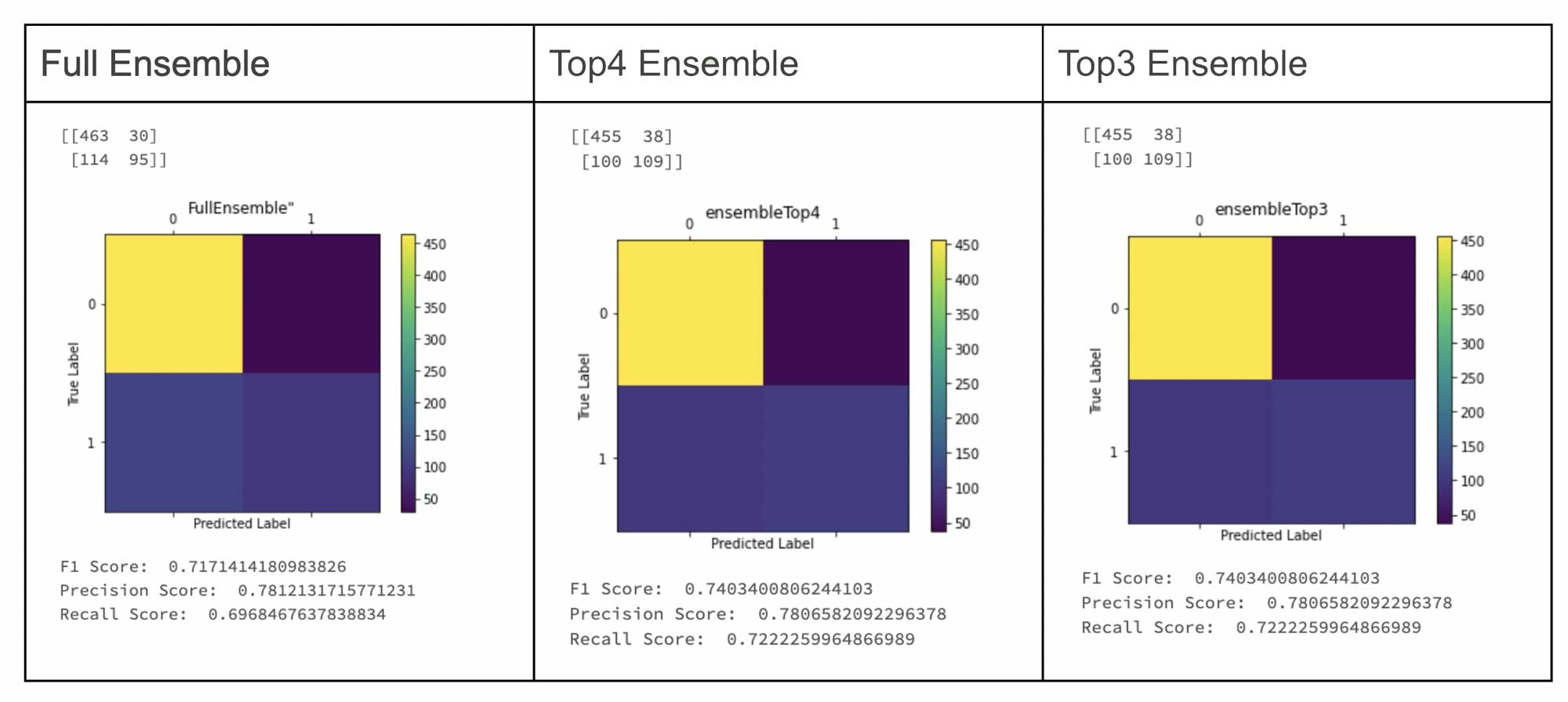
図: AutoMLで生成したチャンピオンモデルとアンサンブルのチャレンジャーの比較(この例では、Top4、Top3アンサンブルが明確な勝者となっています)
ステップ#5: MLflowを用いてモデルをカスタムpyfuncモデルとしてパッケージングおよび記録
カプセル化されたモデルをメンテナンスする必要があるという点に立ち返り、アンサンブルのランにおける親モデルのURIを保存するために、MLflowのトラッキングサーバーと、パラメーター/タグを使用します。
with mlflow.start_run() as ensemble_run:
mlflow.log_param("DecisionTree", DecisionTree_model_uri)
mlflow.log_param("RandomForest", RandomForest_model_uri)
mlflow.log_param("LGBM", LGBM_model_uri)
mlflow.log_param("XGB", XGB_model_uri)
mlflow.pyfunc.log_model("Ensemble", python_model=
Ensemble(DecisionTree_model, RandomForest_model, LGBM_model, XGB_model))
単一のアーティファクトしか存在しないため、このプロセスの管理、バージョン管理は非常に簡単なものとなります。パイプラインの何かがうまく動いていない場合、可動範囲が少ないので、モデルをレジストリに配置する前のデバッグ、検証は容易となります。このパラダイムは、予測器の前に必要となる全ての変換処理をカプセル化するsklearnパイプラインと同様のものです。最終的には、予測のためにたった一つのレジストリを管理するだけで済みます。
ステップ#6: スコアリング
これで、新規データに対するスコアリングの準備が整いました。
import mlflow
# Generate the run uri for the ensemble model from the previous run
single_ensemble_model = f'runs:/{ensemble_run.info.run_uuid}/Ensemble'
# Load model as a PyFuncModel.
loaded_model = mlflow.pyfunc.load_model(single_ensemble_model)
# Predict on a Pandas DataFrame.
import pandas as pd
import numpy as np
loaded_model.predict(X_test)
アンサンブルのニュアンス
複数のモデルが必ずしもアンサンブルを意味する訳ではありません!
異なる工場の異なるマシンから送信されるIoTデータのシナリオを考えてみましょう。それぞれの機会には異なるオペレーションのサイクルがあるので、全て一緒の起点とするのは誤りでしょう。モデルはマシンごとに構築される必要があります。入力データはマシンタイプごとにフィルタリングされ、適切なモデルが適用されます。ある方はこれをアンサンブルと呼ぶかもしれません。これは分割/統治のアプローチですが、データは単一のモデルでトレーニング、スコアリングされます。複数のモデルは精度を改善するために組み合わされてはいません。すなわち、これはアンサンブルのシナリオではなく、単にN個のモデルです。しかし、適切なサブモデルを生み出すために、入力データの特性に対して、上で議論した投票戦略を適用することは可能です。
まとめ
アンサンブル手法は、安定性を改善しつつも優れた精度を生み出すスーパーモデルを生成するために、適度なパフォーマンスを持つ相関の無い複数のモデルを組み合わせる階層型アプローチであり、大規模かつ多様なデータセットに対してしばしば分割・統治の戦略が用いられます。エンジニアリングの複雑性、管理可能性の増加に加え、Kaggleのコンテストでは人気のアプローチでありながらも、人々が時にはアンサンブルを本格運用を避けてしまう要因となりうる、精度と説明可能性のトレードオフが存在します。MLflowを活用したAutoMLは、背後のモデルの生成、管理をシンプルかつ自動的なものにするサポートをし、ML実践者がデータから価値を生み出すクエストで次の限界を超える手助けをします。