Databricks Runtime 13.1 (Beta)が公開されました。
新機能と改善点
-
構造化ストリーミングワークロードにおけるステートフルオペレーションの高度なサポート
複数のステートフルオペレーションを連鎖できるようになり、ウィンドウ集計のようなオペレーションのアウトプットを、joinのような別のステートフルオペレーションに入力できるようになりました。 -
構造化ストリーミングにおけるPub/Subサポート
構造化ストリーミングでGoogle Pub/Subをサブスクライブできるビルトインコネクターを利用できるようになりました。 -
構造化ストリーミングにおけるウォーターマーク内での重複排除
構造化ストリーミングで重複したレコードを削除するために、指定されたウォーターマークの閾値と組み合わせて、dropDuplicatesWithinWatermarkを使用できるようになりました。 -
Kinesisデータソースでavailable nowトリガーがサポートされました
構造化ストリーミングのインクリメンタルバッチとして、Kinesisからのレコードを処理する際にTrigger.AvailableNowを使用できるようになりました。 -
トランケーテッドパーティションカラムを持つIcebergテーブルのDeltaへの変換をサポート
int、long、stringのトランケーテッドカラムで定義されたパーティションを持つIcebergテーブルにCLONEやCONVERT TO DELTAを使用できるようになりました。 -
START VERSIONの削除
ALTER SHAREでSTART VERSIONは非推奨になりました。 -
Pythonで新たなH3エクスプレッションが利用可能に
Pythonでh3_coverash3やh3_coverash3stringエクスプレッションを使用できるようになりました。
SQL関数の追加
-
array_prepend(array, elem):
elemが前に追加されたarrayが返却されます。 -
try_aes_decrypt(expr, key [, mode [, padding]]): AES暗号化を用いて生成されたバイナリーを復号化し、エラーがあった場合には
NULLを返却します。 - sql_keywords(): Databricks SQLのキーワードの一覧を返却します。
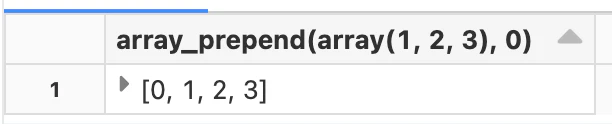
array_prepend(array, elem)
SQL
SELECT array_prepend(array(1, 2, 3), 0);
配列の先頭に0が追加されました。
try_aes_decrypt(expr, key [, mode [, padding]])
最初にAESで暗号化します。
SQL
SELECT base64(aes_encrypt('Spark', 'abcdefghijklmnop'));
R763N8E99TwxGlt8MFIMQrX7foEv8D4rk7mYPn46rKhn
これを復号化します。
SQL
SELECT cast(try_aes_decrypt(unbase64('R763N8E99TwxGlt8MFIMQrX7foEv8D4rk7mYPn46rKhn'),
'abcdefghijklmnop') AS STRING);
複合化されました。
Spark
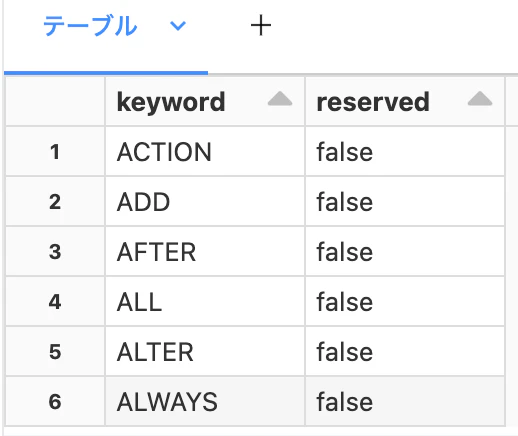
sql_keywords()
SQL
SELECT * FROM sql_keywords() LIMIT 10
キーワードがkeyword、予約語であるかどうかを示すreservedが返ってきます。予約語になるかどうかは実行時のモードによります。詳細はこちら。