LangMem SDK for agent long-term memoryの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
長期記憶を通じてあなたのエージェントが学習、改善する助けとなるライブラリであるLangMem SDKを本日リリースします。
会話からの情報の抽出、プロンプトの更新を通じたエージェントの挙動の最適化、挙動、事実、イベントに関する長期記憶を保持するためのツールを提供します。
任意のストレージシステムは、エージェントフレームワークでコアAPIを使うことができ、LangGraphの長期記憶レイヤーとネイティブに連携します。また、無料で追加の長期記憶を提供するマネージドサービスをローンチします。プロダクションでの活用に興味があるのであればこちらからサインアップしてください。
我々のゴールは、時間と共によりスマート、パーソナライズされるAI体験を誰でも容易に構築できるようにすることです。この取り組みはホストされたLangMemの以前のアルファサービスと、LangGraphの永続化長期記憶レイヤーをベースにしています。
インストールするには、以下を実行するだけです:
pip install -U langmem
クイックリンク
オンメモリー、適応型エージェント
エージェントは学習のためにメモリーを使いますが、メモリーが構成、格納、更新、取得される方法は、エージェントが理解するためや実行するために学習する物事のタイプにインパクトを与えます。LangChainにおいて我々は、初めにエージェントが学習できるようにする必要がある能力を特定し、それらを特定のメモリータイプやアプローチにマッピングし、エージェントにそれのみを実装することが有用であることを発見しました。メモリーを追加する前に、我々は以下を検討すべきです:
- どのような挙動を学習すべきか(ユーザーによる指示)、あるいは事前に定義すべきか?
- どのようなタイプの知識や事実を追跡すべきか?
- どのような条件でメモリーを呼び起こすべきか?
ある程度のオーバーラップはあるかもしれませんが、適応型エージェントを構築する際にそれぞれのメモリータイプは個別の機能を提供します。
| メモリータイプ | 目的 | エージェントの例 | 人間の例 | 典型的なストレージパターン |
|---|---|---|---|---|
| セマンティック | 事実&知識 | ユーザーの嗜好、知識の三つ組 | Pythonがプログラミング言語であることを知っている | プロファイルまたはコレクション |
| エピソード型 | 過去の経験 | Few-shotの例、過去の会話の要約 | 働き始めた最初の日を思い出す | コレクション |
| 手続き型 | システムの挙動 | コアのパーソナリティ、レスポンスのパターン | 自転車の乗り方を知っている | プロンプトルールまたはコレクション |
それでは、上の質問を再度見てみましょう:
-
どのような挙動を学習すべきか(ユーザーによる指示)、あるいは事前に定義すべきか? あなたのエージェントの挙動のある側面はフィードバックや体験に基づいて適応する必要があり、その他の部分は一貫性を保つ必要があるかもしれません。これは、挙動パターンを進化させる 手続き型メモリー(procedural memory) を必要するのか、あるいは固定のプロンプトルールで十分であるかのガイドとなります。これは、学習された挙動がユーザーとのやり取りを通じて形成されるので、OpenAIの「コマンドのチェーン」の概念と類似したものとなります。
-
どのようなタイプの知識や事実を追跡すべきか? さまざまなユースケースで、さまざまなタイプの知識の永続化を必要とします。ユーザーやドメインに関する事実を保持するためのセマンティックメモリーや成功したやり取りから学習するための一時的メモリー(episodic memory) 、その両方の組み合わせを必要とするかもしれません。
-
どのような条件でメモリーを呼び起こすべきか? いくつかのメモリー(コアの手続き型メモリー)はデータ独立です。それらはプロンプトに常に存在します。いくつかはデータ依存であり、セマンティック類似度に基づいて呼び出されることがあります。その他のものはアプリケーションの文脈、類似度、時間などの組み合わせに基づいて呼び出されます。
関係する懸念点は、メモリーのプライバシーです。LangMemでは、すべてのメモリーには名前空間が与えられます。最も一般的な名前空間では、ユーザーのメモリーのクロスオーバーを避けるために
use_idを含めることになります。一般的に、メモリーは特定のアプリのルート、個別のユーザー、チーム間での共有にスコープされることになり、そうでない場合にはエージェントはすべてのユーザーにおけるコアの手続きを学習することになります。
これらすべてのメモリータイプは、個別の会話の外での想起に対応することを意図しています。特定の会話におけるメモリーやスレッドはすでに、あなたのエージェントの「短期」、「稼働中」メモリーシステムとして動作するLangGraphのチェックポインティング(モデルの有効なコンテキストウィンドウの外には拡張しません)を用いることで合理的に対応されています。
また、これはいくつかの観点で標準的なRAGとは異なることに注意してください。一つは情報が獲得される方法です: オフラインのデータ取り込みではなくインタラクションを通じて獲得されます。もう一つは、優先度がつけられる情報のタイプにあります。以下で、メモリータイプの詳細を共有します。
セマンティックメモリー: 事実
セマンティックメモリーは、キーとなる事実(とのそれらの関係性)とエージェントのレスポンスの基盤となるその他の情報を格納します。これによって、あなたのエージェントはモデル自身には「事前トレーニング」されない重要な詳細情報や、Web検索や汎用的なリトリーバではアクセスできない情報を記憶することができます。

コード
from langmem import create_memory_manager
manager = create_memory_manager(
"anthropic:claude-3-5-sonnet-latest",
instructions="Extract user preferences and facts",
enable_inserts=True
)
# Process conversation to extract facts
conversation = [
{"role": "user", "content": "Alice manages the ML team and mentors Bob, who is also on the team."}
]
memories = manager.invoke({"messages": conversation})
# Extract and store new knowledge
conversation2 = [
{"role": "user", "content": "Bob now leads the ML team and the NLP project."}
]
update = manager.invoke({"messages": conversation2, "existing": memories})
memories = [
ExtractedMemory(
id="27e96a9d-8e53-4031-865e-5ec50c1f7ad5",
content=Memory(
content="Alice manages the ML team and mentors Bob, who is also on the team."
),
),
ExtractedMemory(
id="e2f6b646-cdf1-4be1-bb40-0fd91d25d00f",
content=Memory(
content="Bob now leads the ML team and the NLP project."
),
),
]
我々の経験では、エンジニアが初めに(あるいはたぶん、短期の「会話履歴」メモリーの後に)メモリーレイヤーを探索、追加する際に質問、想像する最も一般的な形態の「メモリー」はセマンティックメモリーです。
また、これは従来のRAGシステムと(議論の余地はありますが)最もオーバーラップするものです。他のストア(文書サイト、コードベースなど)で知識が利用でき、そのストアが(やり取り自身ではなく)信頼できる唯一の情報源(single source of truth)である場合、あなたのエージェントは知識コーパスに直接検索を行うことでうまく動作する場合があります。あるいは、知識をセマンティックメモリーシステムに連携するために、定期的にそのような知識を取り込むことができます。知識が(ユーザーに関する)パーソナライゼーションに関するものや、生のマテリアルでは見つからない概念的な関係性である場合には、セマンティックメモリーがあなたにとって完璧なものとなります。
手続き型メモリー: 挙動の進化
手続き型メモリーは、タスクをどのように実行するのかに関して身についた知識を表現します。汎用的なスキル、ルール、挙動にフォーカスしている一時的メモリーとは異なるものです。AIエージェントにおいて、手続き型メモリーはエージェント機能を全体的に決定づけるモデルの重み、エージェントのコード、エージェントのプロンプトの組み合わせに対して保存されます。LangMemでは、エージェントのプロンプトで更新された指示として、学習された手続きを保存することにフォーカスしています。
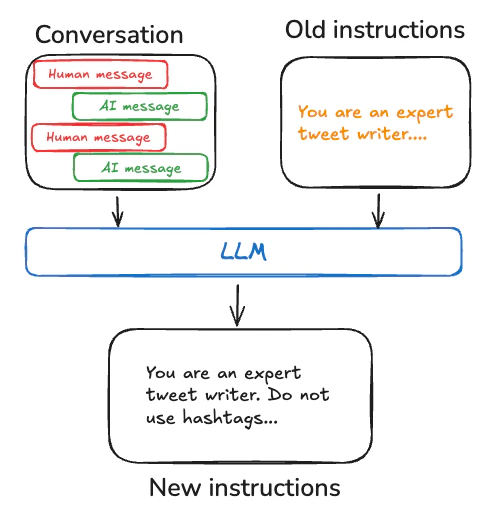
コード
from langmem import create_prompt_optimizer
trajectories = [
(
[
{"role": "user", "content": "Tell me about Mars"},
{"role": "assistant", "content": "Mars is the fourth planet..."},
{"role": "user", "content": "I wanted more about its moons"},
],
{"score": 0.5, "comment": "Missed key information about moons"}
)
]
optimizer = create_prompt_optimizer(
"anthropic:claude-3-5-sonnet-latest",
kind="metaprompt",
config={"max_reflection_steps": 3}
)
improved_prompt = optimizer.invoke({
"trajectories": trajectories,
"prompt": "You are a planetary science expert"
})
"""
You are a helpful assistant..
If the user asks about astronomy, explain topics clearly using real-world examples and current scientific data.
Use visual references when helpful and adapt to the user's knowledge level.
Balance practical observational astronomy with theoretical concepts, providing either viewing advice or technical explanations based on user needs.
"""
オプティマイザーには、成功したインタラクションと成功しなかったインタラクションのパターンを特定するプロンプトが示され、効果的な挙動を強化するようにシステムプロンプトを更新します。これによって、エージェントのコアの指示が観測されたパフォーマンスに基づいて進化するフィードバックが形成されます。
我々のプロンプト最適化の取り組みによって、LangMemは会話を研究するための振り返りとさらなる「思考」を用い、更新を提案するメタプロンプトを用いるmetaprompt、作業を明示的に個別の批評ステップに分割し、それぞれのタスクをさらにシンプルにするためのプロンプト提案を行うgradient、上で述べたことを単一のステップでトライしようとするシンプルなprompt_memoryアルゴリズムを含む、プロンプト更新提案の生成のための複数のアルゴリズムを提供します。
一時的メモリー: イベントと体験
一時的メモリーは、過去のやり取りの記憶を格納します。これは、特定の体験を呼び起こすことにフォーカスしている手続き型メモリーとは異なります。一般的な知識ではなく過去のイベントにフォーカスしているセマンティックメモリーとは異なり、回答が「何」であるのかではなく、エージェントが特定の問題を「どのように」解決するのかを回答します。これは、多くの場合few-shotの例の形をとり、それぞれの例は長期にわたる長いやり取りから蒸留されます。LangMemは一時的メモリーに特化したユーティリティはまだサポートしていません。
すぐに試しましょう
LangMemを用いてカスタムメモリーシステムを実装する方法を示したさらなる例についてはドキュメントをチェックしてください。以下のガイドを含んでいます:
- 自身のメモリーをアクティブに管理するエージェントの作成
- エージェント間でのメモリーの共有
- ユーザーやチームごとに情報を整理するための名前空間メモリー
- お使いのカスタムフレームワークへのLangMemのインテグレーション
あなたのチームでエージェントにパーソナライゼーションや長期学習を追加したいのであれば、こちらのフォームを提出してください。
チームにjoin
我々は適応型エージェントのための世界最高のランタイムを構築するエンジニアをリクルートしています。設計や開発に興味があるのであれば、こちらのオープンポジションをチェックしてください。