こちらのノートブックギャラリーのStreaming applications for sensor dataをウォークスルーした内容です。
ノートブックの翻訳版はこちらとなります。
フェイクセンサーデータの生成
100レコードから構成される100ファイルのデータを生成します。
%scala
// --- データを生成するパスを設定・適宜変更してください ---
val path = "/tmp/takaakiyayoidatabrickscom/Streaming/sdevices/"
dbutils.fs.mkdirs(path)
val numFiles = 100
val numDataPerFile = 100
import scala.util.Random
val deviceTypes = Seq("SensorTypeA", "SensorTypeB", "SensorTypeC", "SensorTypeD")
val startTime = System.currentTimeMillis
dbutils.fs.rm(path, true)
(1 to numFiles).par.foreach { fileId =>
val file = s"$path/file-$fileId.json"
val data = (1 to numDataPerFile).map { x =>
val timestamp = new java.sql.Timestamp(startTime + (fileId * 60000) + (Random.nextInt() % 10000))
val deviceId = Random.nextInt(100)
val deviceType = deviceTypes(Random.nextInt(deviceTypes.size))
val signalStrength = math.abs(Random.nextDouble % 100)
s"""{"timestamp":"$timestamp","deviceId":$deviceId,"deviceType":"$deviceType","signalStrength":$signalStrength}"""
}.mkString("\n")
dbutils.fs.put(file, data)
}
dbutils.fs.head(dbutils.fs.ls(s"$path/file-1.json").head.path)
ストリーミングセンサーデータの処理
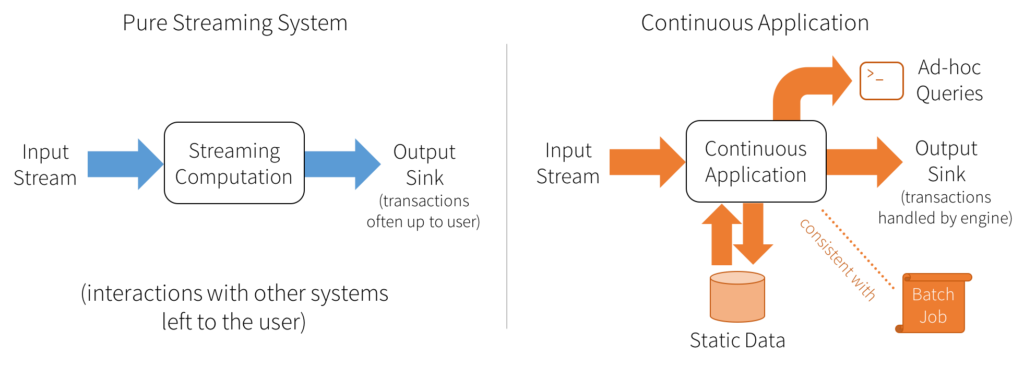
エンドツーエンドの連続アプリケーションを構築する目的においては、構造化ストリーミングはパワフルな機能となります。ハイレベルにおいては、以下の機能を提供します:
- データのすべてのレコードはプレフィックス(パーティション)に保持され、順序を守って処理・カウントされるので、出力テーブルは常に一貫性があります
- 耐障害性は、出力シンクとのやり取りを含み、構造化ストリーミングによって全体的に取り扱われます。
- 遅延データ、順序を守らないデータを取り扱う能力
1-ソース
入力データソースを「入力テーブル」と考えましょう。ストリームに到着するすべてのデータアイテムは、入力テーブルに追加される新たな行なようなものとなります。
2-連続処理 & クエリー
次に、開発者は出力シンクに書き込まれる最終の結果テーブルを計算するために、静的なテーブルであるかのように、このソース、あるいは入力テーブルに対するクエリーを定義します。Sparkはこのバッチのようなクエリーをストリーミング実行プランに自動で変換します。これはインクリメンタル化とよばれるものです: Sparkは、レコードが到着するたびに結果をアップデートするために、どのような状態を維持する必要があるのかを特定します。最後に、開発者はいつ結果をアップデートするのかをコントロールするためのトリガーを指定します。トリガーが実行されるたびに、Sparkは新規データ(入力テーブルの新規行)をチェックし、結果をインクリメンタルにアップデートを行います。

3-シンク
このモデルの最後の部分は、出力モードとなります。結果テーブルがアップデートされる都度、開発者はS3、HDFS、データベースのような外部システムに対する変更を書き込みを行いたいと考えます。通常、出力をインクリメンタルに書き込みたいと考えます。このためには、構造化ストリーミングでは3つの出力モードを提供します:
- Append: 最後のトリガー以降に結果テーブルに追加された新規行のみが、外部ストレージに書き込まれます。
- Complete: 集計のようにアップデートされた結果テーブル全体が外部ストレージに書き込まれます。
- Update: 最後のトリガー以降に結果テーブル更新された行のみが、外部ストレージ上で変更されます。

PySpark構造化ストリーミングAPIを用いた連続処理アプリケーションのサンプル
出力、チェックポイント、不正レコードのためのファイルパスをセットアップします。
# Cmd3の4行目のパスから /sdevices/ を除外してください
base_path = "/tmp/takaakiyayoidatabrickscom/Streaming"
output_path = f"{base_path}/out/iot-stream/"
checkpoint_path = f"{base_path}/out/iot-stream-checkpoint"
#
# チェックポイントパスの作成
#
dbutils.fs.rm(checkpoint_path,True) # チェックポイントの上書き
dbutils.fs.mkdirs(checkpoint_path)
#
#
bad_records_path = f"{base_path}/badRecordsPath/streaming-sensor/"
dbutils.fs.rm(bad_records_path, True) # ディレクトリを空に
dbutils.fs.mkdirs(bad_records_path)
センサーからのデータはのどうなものでしょうか?
sensor_path = f"{base_path}/sdevices/"
sensor_file_name= sensor_path + "file-1.json"
dbutils.fs.head(sensor_file_name, 233)

入力ストリームと出力ストリームのスキーマを定義
良いベストプラクティスはパフォーマンス上の理由からSparkにスキーマを推定させるのではなく、スキーマを定義するというものです。スキーマが無い場合、Sparkはいくつかのジョブを起動します: ヘッダーを読み込むためのジョブ、データが合致するようにスキーマを検証するためにパーティションの一部を読み込むジョブです。
問題があれば即座にエラーを発生させ、欠損値やデータ型のミスマッチがあった際に、許容するか、NaNやnullで置き換えるように、スキーマを設定するオプションが存在しています。
from pyspark.sql.functions import *
from pyspark.sql.types import *
# オリジナルの入力スキーマ
jsonSchema = (
StructType()
.add("timestamp", TimestampType()) # ソースのイベント時間
.add("deviceId", LongType())
.add("deviceType", StringType())
.add("signalStrength", DoubleType())
)
# いくつかのETL(変換およびカラムの追加)を行うのでカラムを追加してスキーマを変更します。
# この変換データは、処理やレポート生成に使用できるようにSQLテーブルを作成元としてのParquetファイルに格納されます。
parquetSchema = (
StructType()
.add("timestamp", TimestampType()) # ソースのイベント時間
.add("deviceId", LongType())
.add("deviceType", StringType())
.add("signalStrength", DoubleType())
.add("INPUT_FILE_NAME", StringType()) # このデータアイテムを読み込んだファイル名
.add("PROCESSED_TIME", TimestampType())) # 処理中のエグゼキューターの時間
オブジェクトストアソースからのストリームの読み込み
このケースでは、ファイルから一度に読み込むことでKafkaライブストリームをシミュレートします。しかし、これをApache Kafkaのトピックにすることもできます。
注意
チュートリアルのために意図的に処理を遅くしています。
inputDF = ( spark
.readStream
.schema(jsonSchema)
.option("maxFilesPerTrigger", 1) # チュートリアルのために処理を遅くしています
.option("badRecordsPath", bad_records_path) # いかなる不正レコードはこちらに格納されます
.json(sensor_path) # ソース
.withColumn("INPUT_FILE_NAME", input_file_name()) # ファイルパスを保持
.withColumn("PROCESSED_TIME", current_timestamp()) # 処理時刻のタイムスタンプを追加
.withWatermark("PROCESSED_TIME", "1 minute") # オプション: 順序が遅れたデータに対するウィンドウ
)
Parquetファイルシンクへのストリームの書き込み
query = (inputDF
.writeStream
.format("parquet") # 後段処理あるいは必要に応じてバッチクエリーのために保存を行うシンク
.option("path", output_path)
.option("checkpointLocation", checkpoint_path) # 障害復旧のためのチェックポイントの追加
.outputMode("append")
.queryName("devices") # オプションとして、クエリーを実行する際に指定するクエリー名を指定
.trigger(processingTime='5 seconds')
.start()
)
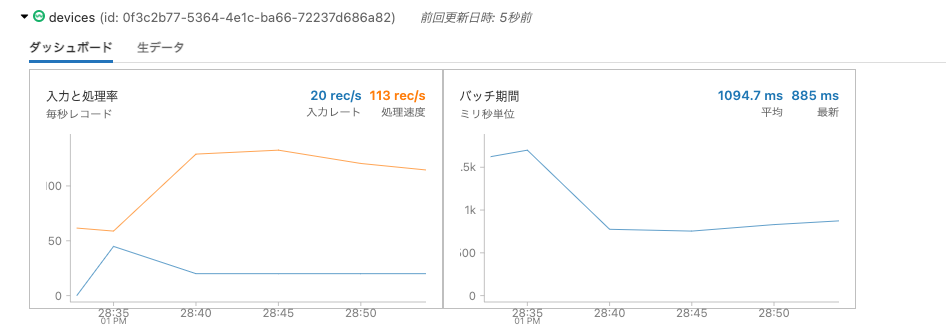
ストリーミングクエリーが起動し、専用のダッシュボードで処理の進捗を確認することができます。
クイックにSQLクエリーを実行できるように入力ストリームから一時テーブルを作成
inputDF.createOrReplaceTempView("parquet_sensors")
入力ストリームから作成された一時テーブルに対してクエリーを実行
%sql select * from parquet_sensors where deviceType = 'SensorTypeD' or deviceType = 'SensorTypeA'
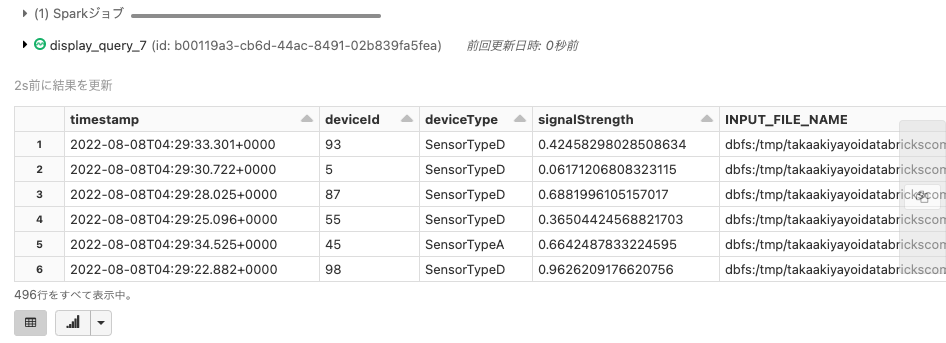
これらのクエリーはストリーミングクエリーとなりますので、逐次内容は更新されていきます。
入力ストリームから保存されたParquetファイルに対して追加の処理を行い、クエリーを実行
spark.conf.set("spark.sql.shuffle.partitions", "1") # 優れたクエリー性能のためにシャッフルサイズを小さく維持
devices = (spark.readStream
.schema(parquetSchema)
.format("parquet")
.option("maxFilesPerTrigger", 1) # デモのために遅くしています
.load(output_path)
.withWatermark("PROCESSED_TIME", "1 minute") # 順序を守らないデータに対するウィンドウ
)
# より複雑な集計クエリーを行うために一時テーブルを作成
devices.createOrReplaceTempView("sensors")
以降でもストリーミングクエリーも実行していきます。
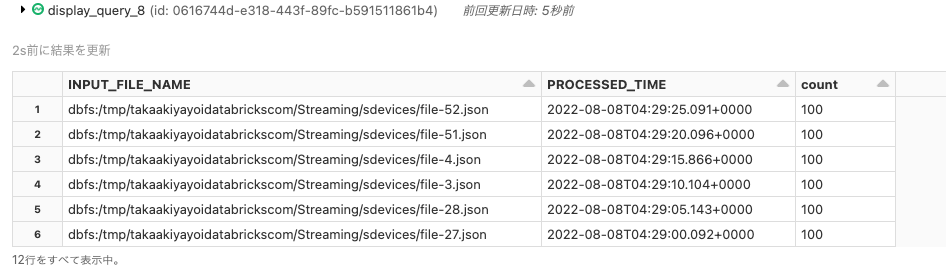
何ファイルが処理されましたか?
display(
devices.
select("INPUT_FILE_NAME", "PROCESSED_TIME")
.groupBy("INPUT_FILE_NAME", "PROCESSED_TIME")
.count()
.orderBy("PROCESSED_TIME", ascending=False)
)
どれだけのデータが通過しましたか?
%sql select count(*) from sensors

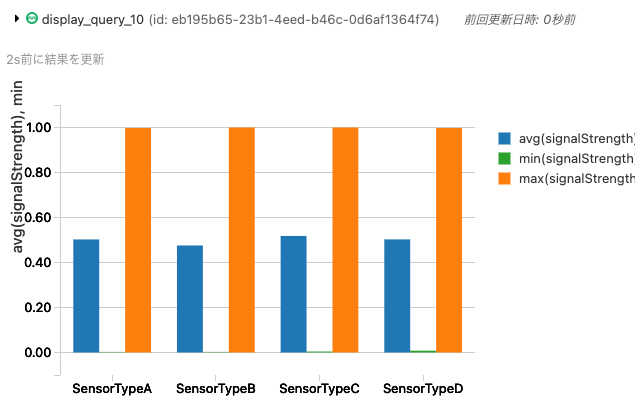
それぞれのセンサータイプにおける強度の最小値、最大値、平均値はどのようになっていますか?
Spark SQLの関数であるmin()、max()、avg()を使います。
注意
Pythonノートブックで%sqlマジックコマンドを使うことでSQLを使うことができます。
%sql
select count(*), deviceType, min(signalStrength), max(signalStrength), avg(signalStrength)
from sensors
group by deviceType
order by deviceType asc
デバイスと5秒ウィンドウごとのシグナルのカウントを集計するストリームを作成してみましょう
注意
これはタンブリングウィンドウであり、スライディングウィンドウではありません。サイズは5秒です。
例えば、サイズ5の日、時間、分のタンブリングウィンドウは以下のようになります。
[(00:00 - 00:05), (00:05: 00:10), (00:10: 00:15)]
イベントは、これらのタンブリングウィンドウのいずれかに属することになります。
(devices
.groupBy(
window("timestamp", "5 seconds"),
"deviceId"
)
.count()
.createOrReplaceTempView("sensor_counts")) # データフレームを用いて一時ビューを作成
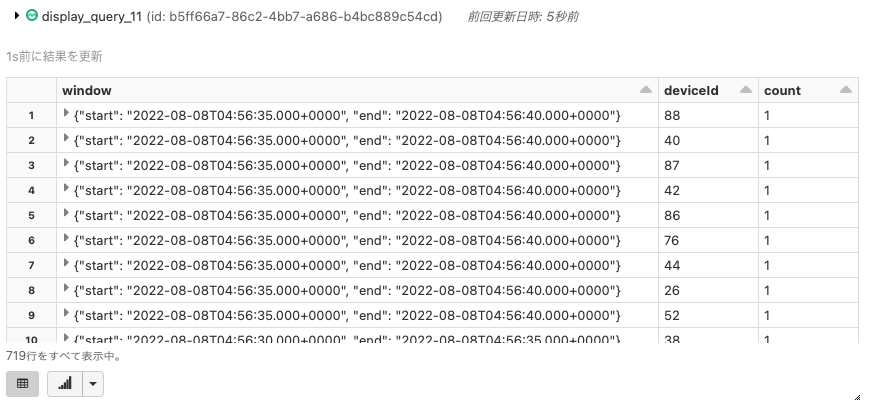
これらの5秒ウィンドウにおいて、どのデバイスがシグナルのロスを経験しているのか?
%sql select * from sensor_counts where count < 5 order by window.start desc
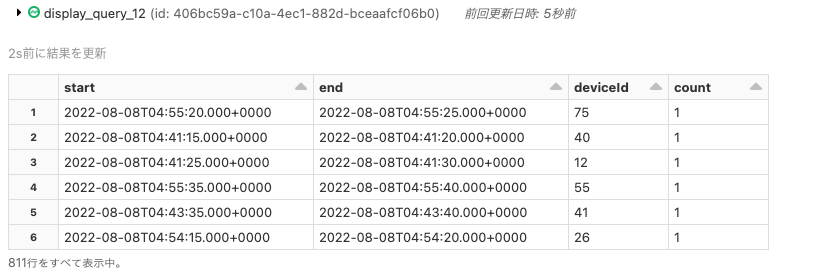
シグナルを送信していないダウンしている可能性があるセンサーのアラートの送信
一時テーブルsensor_countsからデータフレームを作成しましょう。
lost_sensor_signals = (spark.table("sensor_counts")
.filter(col("count") < 5)
.select("window.start", "window.end", "deviceId", "count")
)
# データフレームの表示
display(lost_sensor_signals)
ワーカーのログに書き込むために、foreachメカニズムを活用
これは、モニタリングの目的で使用することができます。別のジョブがアラートのためにログをスキャンし、Kafkaのトピックに公開するジョブや、Gangliaにポストすることができます。利用できるKafkaサーバーや、REST API経由で利用できるGangliaサービスがあるのであればトライしてみるといい練習になります。
def processRow(row):
# 今時点ではログファイルに書き込みを行いますが、このロジックは容易にKafkaのトピックや、GangliaやPagerDutyのようなモニタリング、ページングサービスにアラートを発行するように拡張することができます
print("ALERT from Sensors: Between {} and {}, device {} reported only {} times".format(row.start, row.end, row.deviceId, row[3]))
(lost_sensor_signals
.writeStream
.outputMode("complete") # モニタリングのためにKafkaの"alerts"トピックにすることもできます
.foreach(processRow)
.start()
)
こちらが書き出された結果のサンプルとなります。

データのクリーンアップ
稼働中のすべてのクエリーを取得
sqm = spark.streams
[q.name for q in sqm.active]

ストリームの停止
[q.stop() for q in sqm.active]