こちらの続きです。
ログの確認
約1日待ってから以下のコマンドをローカルマシンから実行してステータスを確認します。
curl -X GET -u <Databricksアカウントオーナーのメールアドレス>:<パスワード> \
'https://accounts.cloud.databricks.com/api/2.0/accounts/<DatabricksアカウントID>/log-delivery' | jq
statusがSUCCEEDEDになっていれば、ログのデリバリーに成功したことになります。

AWSコンソールでも確認してみるとcsvファイルが生成されていることがわかります。
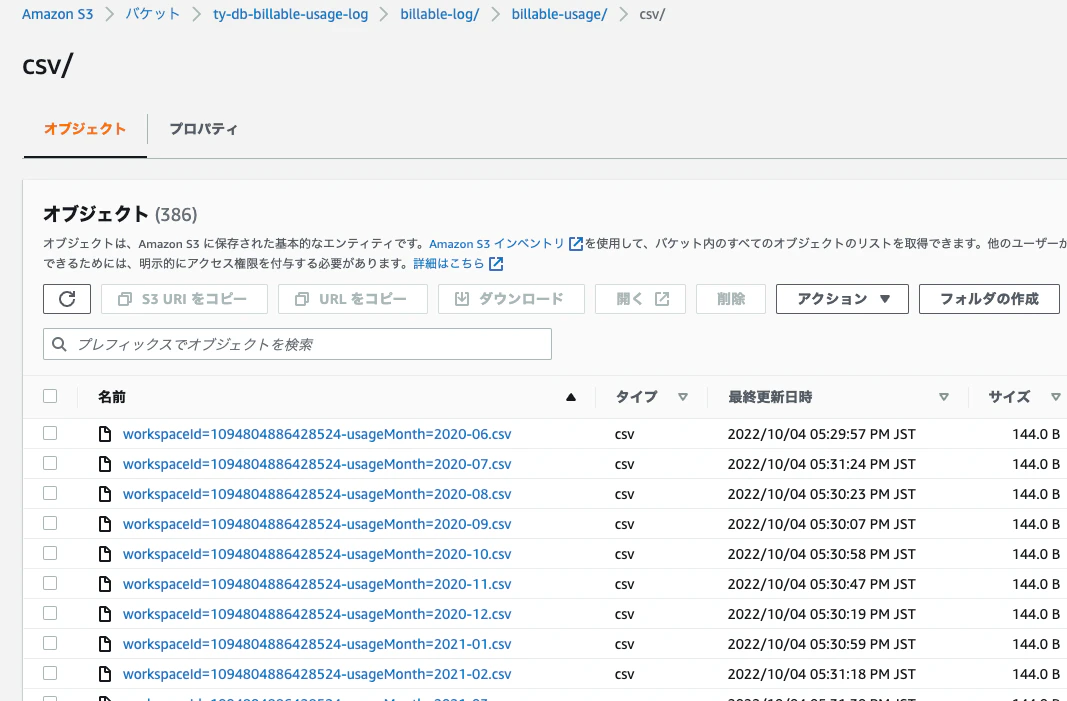
課金利用ログへのアクセス設定
分析にはDatabricksノートブックを使いますが、上のログにアクセスできる様に設定を行う必要があります。以下のステップを実行するには、Databricksのデプロイに使用したIAMロールのポリシーの変更も必要になるので確認しておきます。
このIAMロールはアカウントコンソールの以下の画面で確認できます。
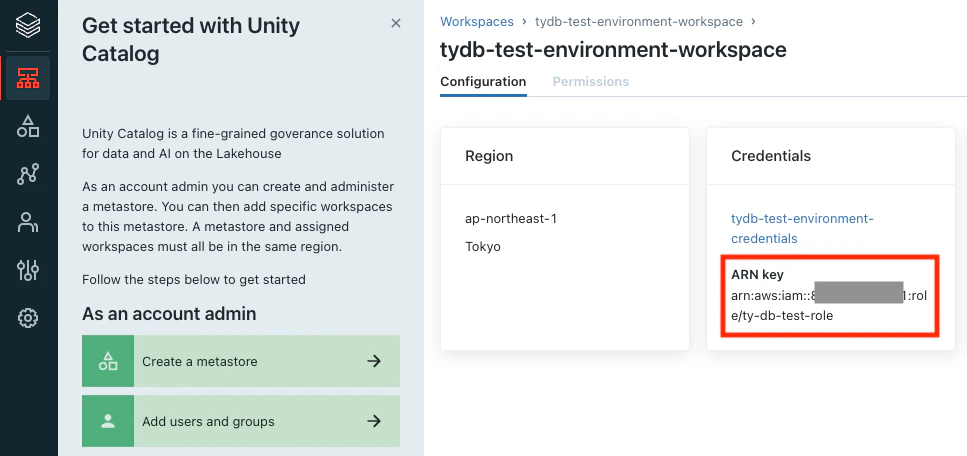
こちらの手順に従ってインスタンスプロファイルを作成します。
IAMロールの作成
AWSコンソールでIAMにアクセスして、ここではbillable-log-access-roleというロールを作成します。
このロールが課金利用ログが格納されているバケットにアクセスできる様に以下のポリシーをアタッチします。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::/ty-db-billable-log"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::/ty-db-billable-log/*"
]
}
]
}
作成したIAMロールのインスタンスプロファイルのARNをメモしておきます。

バケットポリシーの設定
前のステップで作成した課金利用ログを格納しているS3バケットに上のロールがアクセスできる様に、以下のバケットポリシーを追加します。
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<DatabricksをデプロイしたAWSアカウントID>:role/billable-log-access-role"
},
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::ty-db-billable-usage-log"
},
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<DatabricksをデプロイしたAWSアカウントID>:role/billable-log-access-role"
},
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObjectAcl"
],
"Resource": "arn:aws:s3:::ty-db-billable-usage-log/*"
}
PassRoleの設定
Databricksのデプロイに使用したIAMロールで、上のbillable-log-access-roleロールを利用できる様にPassRoleを許可します。
Databricksのデプロイに使用したIAMロールに以下のポリシーを追加します。
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::<DatabricksをデプロイしたAWSアカウントID>:role/billable-log-access-role"
}
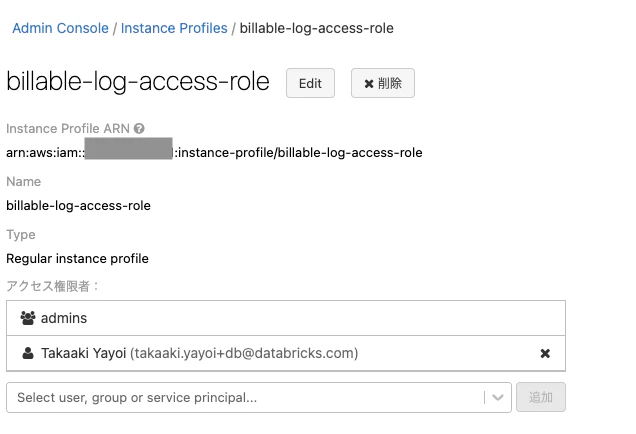
インスタンスプロファイルの作成
Databricksの管理コンソールにアクセスし、Instance profilesタブをクリックしインスタンスプロファイルを作成します。
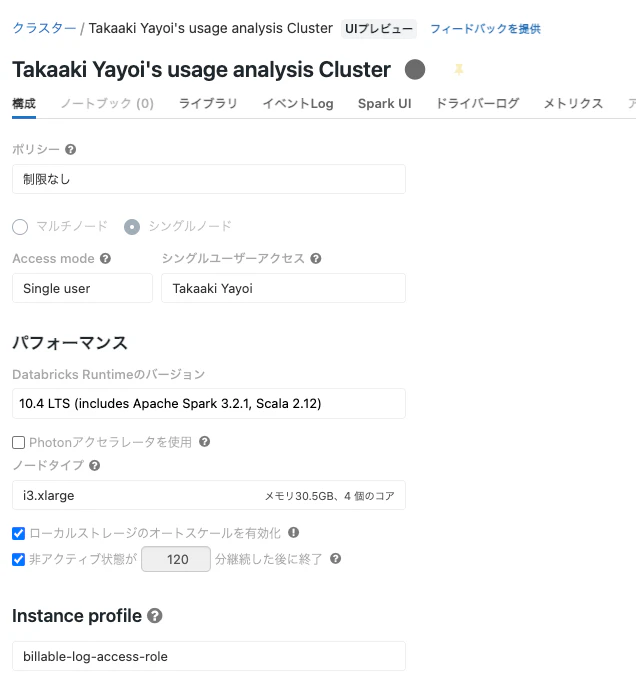
Databricksクラスターを作成し、インスタンスプロファイルをアタッチして起動します。
課金利用ログを分析する
分析ようノートブックの翻訳版はこちらです。
ログを格納しているパスを指定します。
usagefilePath = "s3a://ty-db-billable-usage-log/billable-log/billable-usage/csv/"
アクセスできることを確認します。ACCESS DENIEDが出る場合には、上のインスタンスプロファイルに関連する設定を確認してください。
dbutils.fs.ls("s3a://ty-db-billable-usage-log/")
スキーマを指定してデータを読み込み、一時テーブルで参照できる様にします。
from pyspark.sql.types import *
from pyspark.sql.functions import *
from pyspark.sql.window import Window
import pyspark.sql.functions as func
# 利用量のスキーマ
usageSchema = StructType([
StructField("workspaceId", StringType(), False),
StructField("timestamp", DateType(), False),
StructField("clusterId", StringType(), False),
StructField("clusterName", StringType(), False),
StructField("clusterNodeType", StringType(), False),
StructField("clusterOwnerUserId", StringType(), False),
StructField("clusterCustomTags", StringType(), False),
StructField("sku", StringType(), False),
StructField("dbus", FloatType(), False),
StructField("machineHours", FloatType(), False),
StructField("clusterOwnerUserName", StringType(), False),
StructField("tags", StringType(), False)
])
# 利用量のデータフレームを作成してキャッシュ
df = (spark.read
.option("header", "true")
.option("escape", "\"")
.schema(usageSchema)
.csv(usagefilePath)
)
usageDF = (df.select("workspaceId",
"timestamp",
"clusterId",
"clusterName",
"clusterNodeType",
"clusterOwnerUserId",
"clusterCustomTags",
when(col("sku") == "STANDARD_INTERACTIVE_OPSEC", "All Purpose Compute")
.when(col("sku") == "STANDARD_AUTOMATED_NON_OPSEC", "Jobs Compute")
.when(col("sku") == "STANDARD_INTERACTIVE_NON_OPSEC", "All Purpose Compute")
.when(col("sku") == "LIGHT_AUTOMATED_NON_OPSEC", "Jobs Compute Light")
.when(col("sku") == "STANDARD_AUTOMATED_OPSEC", "Jobs Compute")
.when(col("sku") == "LIGHT_AUTOMATED_OPSEC", "Jobs Compute Light")
.when(col("sku") == "STANDARD_ALL_PURPOSE_COMPUTE", "All Purpose Compute")
.when(col("sku") == "STANDARD_JOBS_COMPUTE", "Jobs Compute")
.when(col("sku") == "STANDARD_JOBS_LIGHT_COMPUTE", "Jobs Compute Light")
.when(col("sku") == "PREMIUM_ALL_PURPOSE_COMPUTE", "All Purpose Compute")
.when(col("sku") == "PREMIUM_JOBS_COMPUTE", "Jobs Compute")
.when(col("sku") == "PREMIUM_JOBS_LIGHT_COMPUTE", "Jobs Compute Light")
.when(col("sku") == "ENTERPRISE_ALL_PURPOSE_COMPUTE", "All Purpose Compute")
.when(col("sku") == "ENTERPRISE_JOBS_COMPUTE", "Jobs Compute")
.when(col("sku") == "ENTERPRISE_JOBS_LIGHT_COMPUTE", "Jobs Compute Light")
.otherwise(col("sku")).alias("sku"),
"dbus",
"machineHours",
"clusterOwnerUserName",
"tags")
.withColumn("tags", when(col("tags").isNotNull(), col("tags")).otherwise(col("clusterCustomTags")))
.withColumn("tags", from_json("tags", MapType(StringType(), StringType())).alias("tags"))
.drop("userId")
.cache()
)
# SQLコマンドを使うために一時テーブルを作成
usageDF.createOrReplaceTempView("usage")
動的にフィルタリングできるようにウィジェットを作成します。
# 動的にフィルタリングできる様にウィジェットを作成
import datetime
dbutils.widgets.removeAll()
# 日付ウィンドウのフィルター
now = datetime.datetime.now()
dbutils.widgets.text("Date - End", now.strftime("%Y-%m-%d"))
dbutils.widgets.text("Date - Beginning", now.strftime("%Y-%m-%d"))
# SKU価格。お客様のアカウントごとに固有な値を入力できる様にテキストウィジェットを作成
skus = spark.sql("select distinct(sku) from usage").rdd.map(lambda row : row[0]).collect()
for sku in skus: # お客様固有のSKUのテキストボックスを表示
dbutils.widgets.text("SKU Price - " + sku, ".00")
# 時系列グラフにおける時間単位
dbutils.widgets.dropdown("Time Unit", "Day", ["Day", "Month"])
timeUnit = "Time"
# コミットの金額
dbutils.widgets.text("Commit Dollars", "00.00")
commit = getArgument("Commit Dollars")
# タグのキー
tags = spark.sql("select distinct(explode(map_keys(tags))) from usage").rdd.map(lambda row : row[0]).collect()
if len(tags) > 0:
defaultTag = tags[0]
dbutils.widgets.dropdown("Tag Key", str(defaultTag), [str(x) for x in tags])
# 利用量のタイプ
dbutils.widgets.dropdown("Usage", "Spend", ["Spend", "DBUs", "Cumulative Spend", "Cumulative DBUs"])
ノートブックの上部にウィジェットが表示されます。

分析するためのデータフレームを準備します。
# SKU名とレートからデータフレームを作成。これは、費用を得るために利用量データフレームとjoinされます。
skuVals = [str(sku) for sku in skus]
wigVals = [getArgument("SKU Price - " + sku) for sku in skus]
skuZip = list(zip(skuVals, wigVals)) # RDDに並列化するために、それぞれのSKUと対応するレートごとのリストオブジェクトを作成します。
skuRdd = sc.parallelize(skuZip) # RDDの作成
skuSchema = StructType([
StructField("sku", StringType(), True),
StructField("rate", StringType(), True)])
skuDF = spark.createDataFrame(skuRdd, skuSchema) # データフレームの作成
timeUnitFormat = "yyyy-MM-dd" if getArgument("Time Unit") == "Day" else "yyyy-MM"
# それぞれの期間、コミット、SKU、タグの値ごとの費用、DBU、累積費用、累積DBUを含む大規模なデータフレーム
globalDF = (usageDF
.filter(usageDF.timestamp.between(getArgument("Date - Beginning"), getArgument("Date - End")))
.join(skuDF, "Sku")
.withColumn("Spend", usageDF["dbus"] * skuDF["rate"])
.withColumn("Commit", lit(getArgument("Commit Dollars")))
.withColumn("Tag", usageDF["tags." + getArgument("Tag Key")])
.select(date_format("timestamp", timeUnitFormat).alias(timeUnit), "Spend", "dbus", "Sku", "Commit", "Tag")
.groupBy(timeUnit, "Commit", "Sku", "Tag")
.sum("Spend", "dbus")
.withColumnRenamed("sum(dbus)", "DBUs")
.withColumnRenamed("sum(Spend)", "Spend")
.orderBy(timeUnit)
)
# 単一のコミット、SKU、タグの値に対応する小規模なデータフレームを作成し、費用、DBUにタウする累積値を計算する関数
def usageBy(columnName):
# 累積費用/DBUを得るためのウィンドウ関数
cumulativeUsage = Window \
.orderBy(timeUnit) \
.partitionBy(columnName) \
.rowsBetween(Window.unboundedPreceding, 0)
# 指定されたカラムの値に対して当該期間にデータがない場合に行を持たないのではなく、
# ゼロの費用、DBUの値を持つ行を追加し、適切な集約処理に加算します。
# グラフは累積値をゼロとして解釈しないためです。
zeros = globalDF.select(columnName).distinct().withColumn("Spend", lit(0)).withColumn("DBUs", lit(0))
zerosByTime = globalDF.select(timeUnit).distinct().crossJoin(zeros)
return (globalDF
.select(timeUnit, columnName, "Spend", "DBUs")
.union(zerosByTime)
.groupBy(timeUnit, columnName)
.sum("Spend", "DBUs")
.withColumnRenamed("sum(DBUs)", "DBUs")
.withColumnRenamed("sum(Spend)", "Spend")
.withColumn("Cumulative Spend", func.sum(func.col("Spend")).over(cumulativeUsage))
.withColumn("Cumulative DBUs", func.sum(func.col("DBUs")).over(cumulativeUsage))
.select(timeUnit, columnName, getArgument("Usage"))
.withColumnRenamed(getArgument("Usage"), "Usage")
.orderBy(timeUnit)
)
display(globalDF)
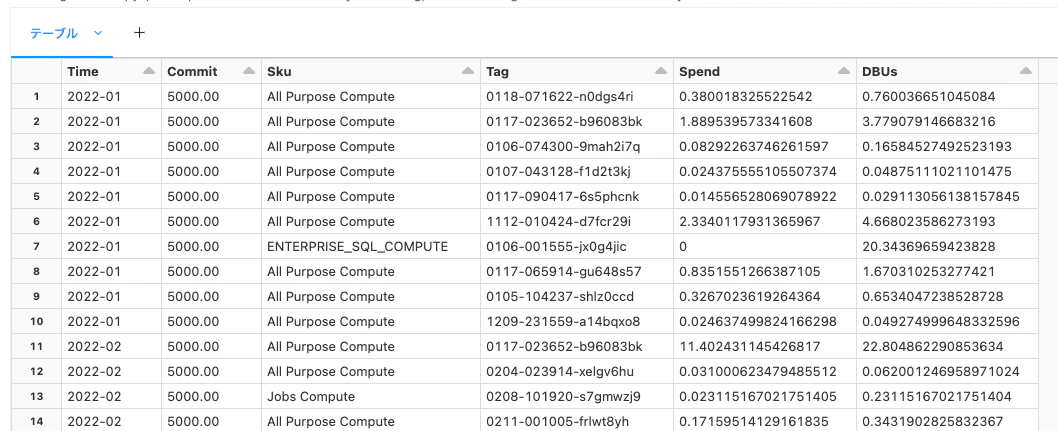
以下のレポートを生成します。
- 利用量の時系列変化
- SKUごとの利用量の時系列変化
- 選択されたタグごとの利用量
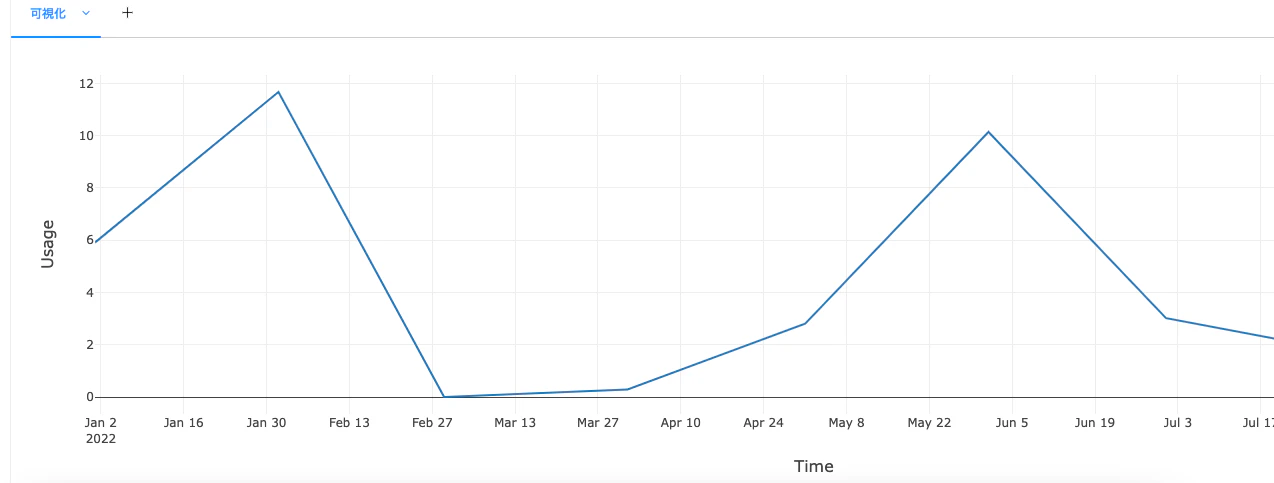
利用量の時系列変化
display(usageBy("Commit"))
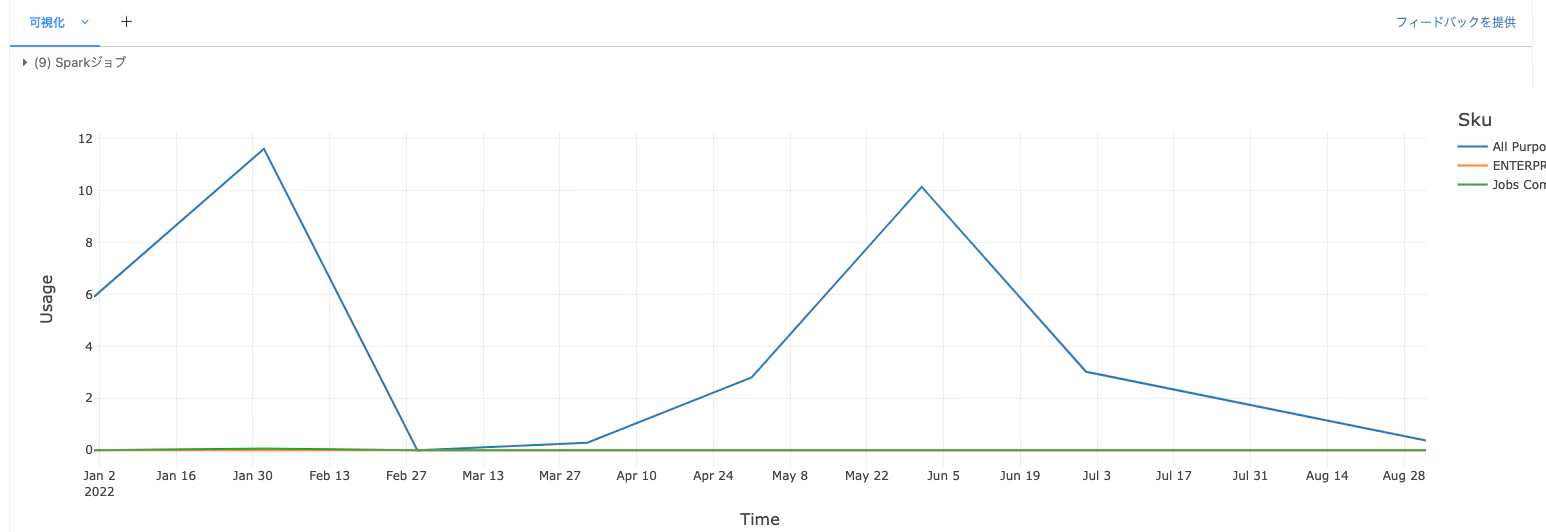
SKUごとの利用量の時系列変化
display(usageBy("Sku"))
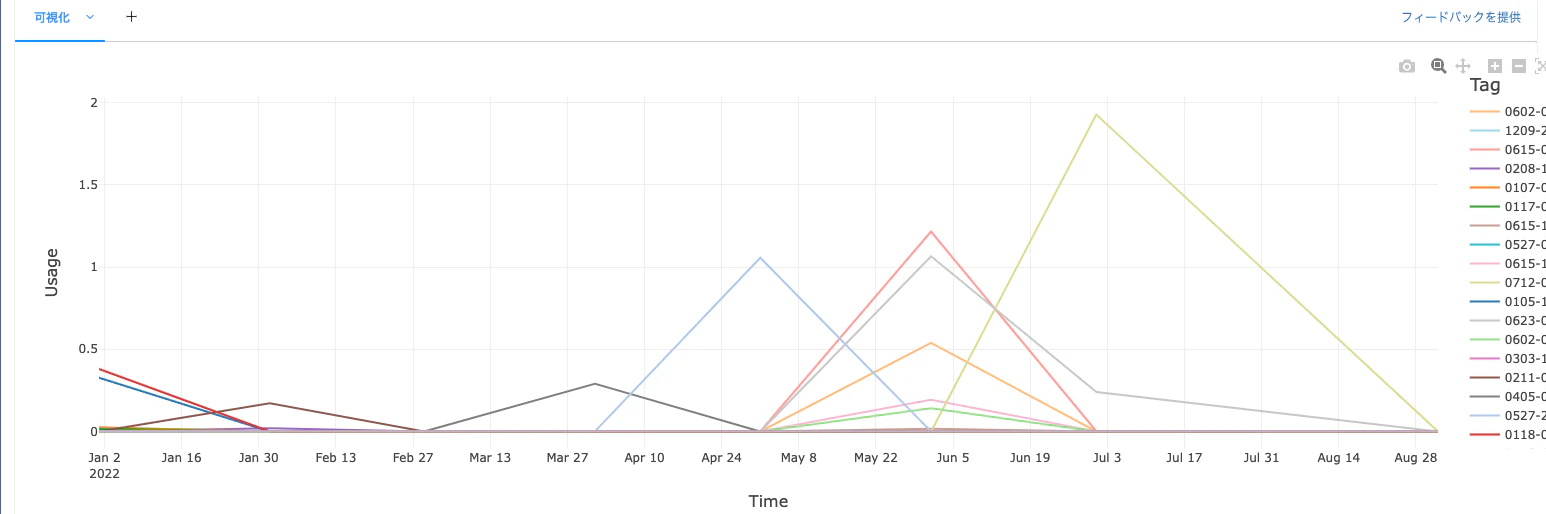
タグごとの利用量の時系列変化
以下の例では、クラスターIDごとにグルーピングしています。カスタムタグをクラスターに付与することができるので、プロジェクト単位で集計するということも可能です。
display(usageBy("Tag"))
こちらのノートブックはサンプルですので、本格的なダッシュボードを構成したいという場合には、こちらのノートブックのデータ処理ロジックをジョブ化し、Databricks SQLのダッシュボードなどからアクセするということをご検討ください。