Databricks Labsで公開されていました。
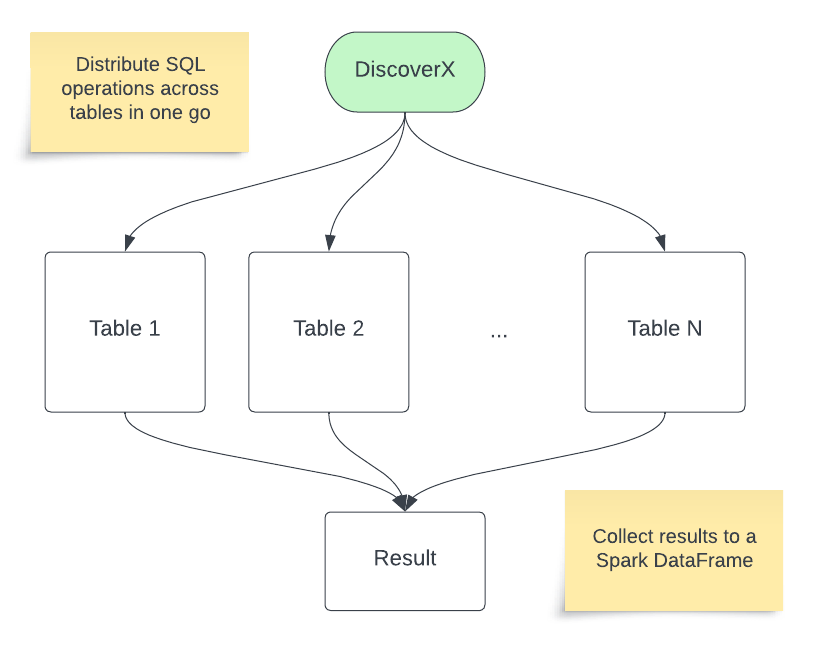
DiscoverXを用いることで、複数テーブルに対するスキャンやSQLの適用を一度に行うことができます。
注意
上のリンク先にも記載されているように、/databrickslabsのgithubアカウントで提供されているものは探索目的のためのものであり、DatabricksによるSLAを提供するものではありません。問題を発見した場合には、GitHubのIssueとして報告してください。
要件
- Databricksワークスペース
- Unity Catalogサポート
オペレーションの例
複数テーブルに対して同時にオペレーションが適用されます。
-
メンテナンス
- 全テーブルのVACUUM (サンプルノートブック)
- 特定のカラムを持つテーブルに対してz-orderを用いたOPTIMIZE
- 大量の小さなファイルを持つテーブルの検知 (サンプルノートブック)
- ある期間でテーブルごとに書き込まれたデータ量の可視化
- ガバナンス
-
意味論に基づく分類
- 意味論のタイプによるカラムに対する意味論的分類: メール、電話番号、IPアドレスなど
- 意味論タイプによるデータの選択
- 意味論タイプによるデータの削除
- カスタム
ウォークスルー
%pip install dbl-discoverx
from discoverx import DX
dx = DX()
Welcomeメッセージが表示されます。
上のdx.scan(from_tables="*.*.*")を実行すると、Unity Catalogメタストアの全カタログ、データベース、テーブルをスキャンするので、対象を絞ります。
dx.scan(from_tables="takaakiyayoi_catalog.default.taka_qiita")
上の例では1つのテーブルのみを対象にしていますが、ワイルドカード(*)を使えば複数のテーブルを同時にスキャンすることができます。
こちらに説明があるように、scanは意味論に基づく分類を行うために、ルールで定義された正規表現を用いてレイクハウスをスキャンします。
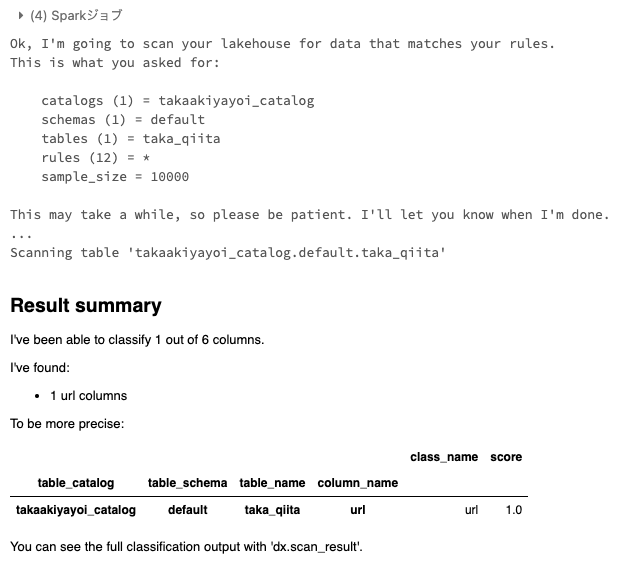
結果から、一つの列がURLであると識別されたことがわかります。
なお、ビルトインのルールを確認することができます。クレジットカード番号、メールアドレス、IPアドレスなど。
dx.display_rules()

複数のテーブルに任意のSQLを同時に適用することもできます。
dx.from_tables("takaakiyayoi_catalog.covid.covid*")\
.apply_sql("SELECT to_json(struct(*)) AS row FROM {full_table_name} LIMIT 1")\
.execute()

あとでPIIの特定もトライしてみます。